






JVM
0. Java与JVM简介
jvm可以解释运行任何语言的字节码(前提是你要符合jvm规范)
你的朋友就可以拿着.class文件和自己机子上的jre运行你的代码了

我们编写好的.java文件完整流程:
.java文件经过前端编译器(javac)生成字节码文件.class文件,javac是JDK中的
JDK = JRE + 编译字节码文件过程(生成class文件)
JRE = java各种API (jre中的lib目录下的内容)+ JVM(jre中的bin目录下的内容)
jvm是程序虚拟机,跟硬件没有交互,是在操作系统之上
总结:
JDK(开发包)包含JRE(运行环境),而JRE包含JVM(虚拟机)
JRE只能运行class文件而没有编译的功能
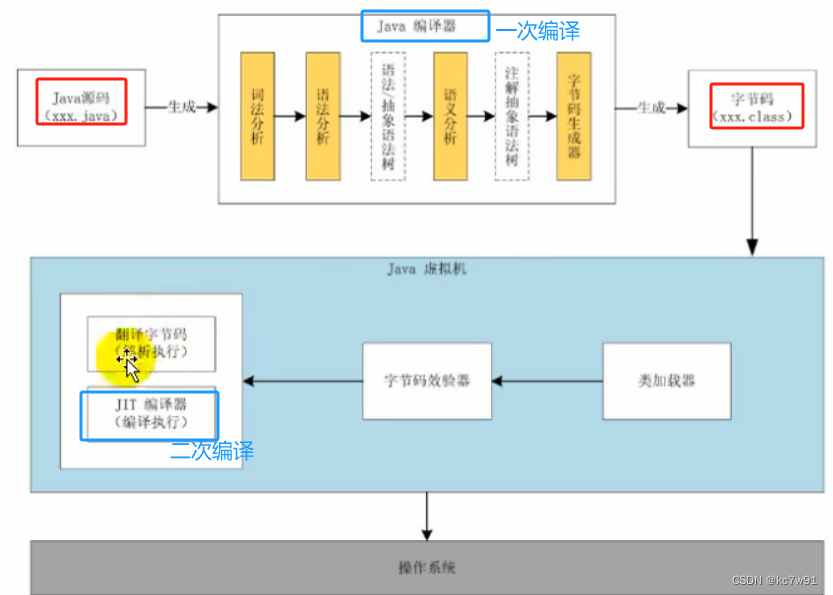
因此JVM就是用来处理javac编译好的字节码文件的
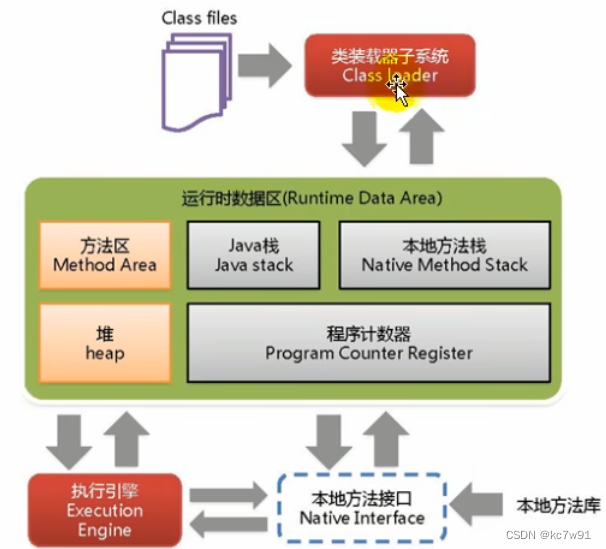
JVM整体结构(HotSpot虚拟机)要求会画:
java的指令是基于栈设计的
1. JVM生命周期
基于寄存器的指令结构
2. 类加载器子系统 / 类加载过程
讲的是这个部分:
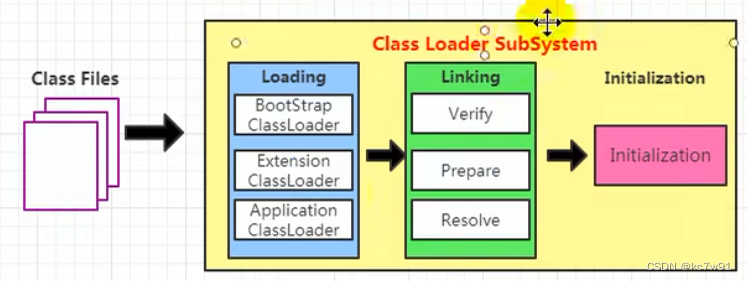
首先链接(验证–准备【变量初始化为0】–解析),然后根据代码中的用户定义初始化


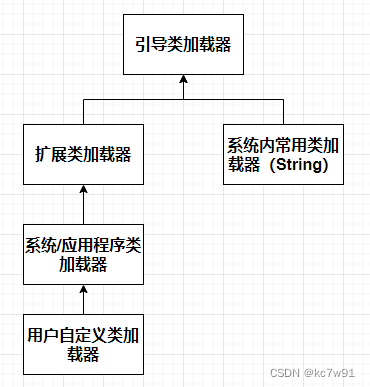
上下两图相同,bootstrap是由c/c++写的,在Java程序中获取不到
系统类加载器也叫应用程序加载器(sys/app)
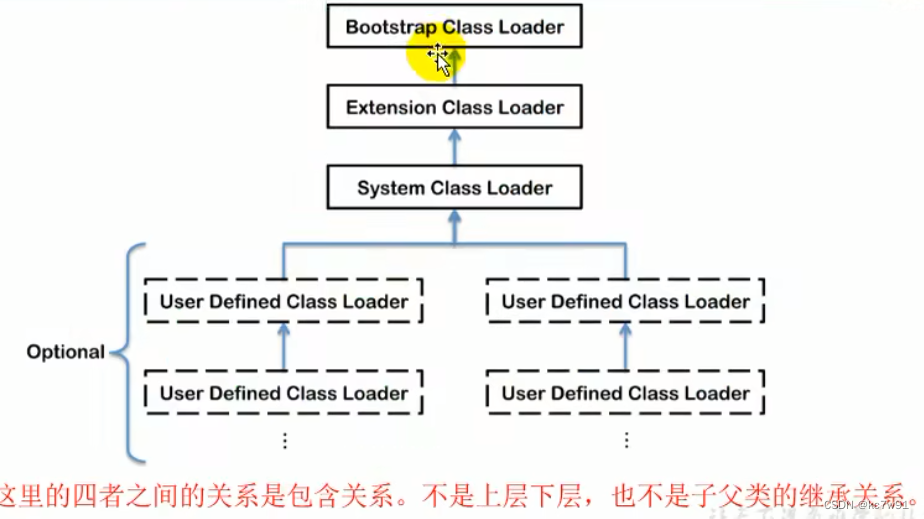
双亲委派机制
也实现了沙箱安全
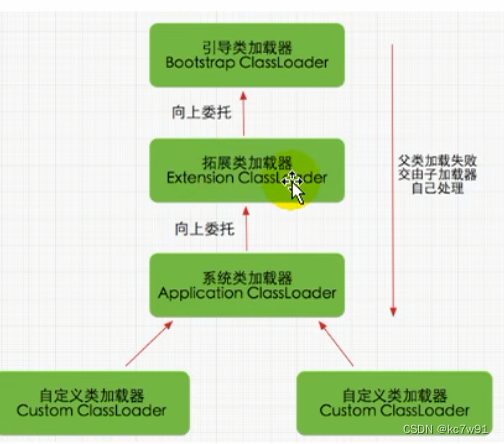
类加载器也有类似“类”的集成模式,一个类想要调用class loader把自己导进来时,类加载器会层层向上问“父”加载器,看有没有上层领导要做。都没人做则层层下传回来

判断两个类是否相同:包名类名一致+加载类相同
3 JVM的运行时数据区
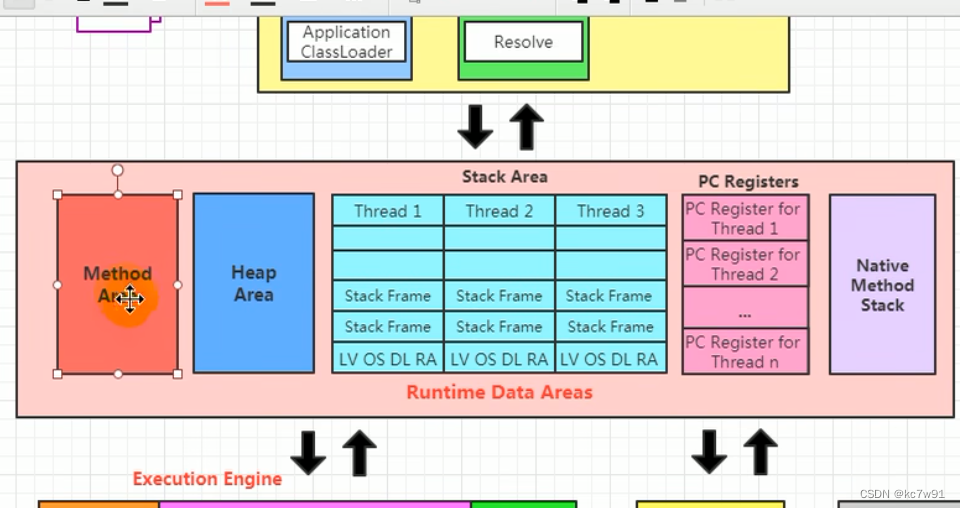
3.1 PC寄存器
pc寄存器是线程私有的,记录了当前程序执行到了哪条指令(即,每个线程都有自己的栈)
3.2 虚拟机栈
栈解决程序运行时的问题(程序如何执行),堆解决数据存储的问题(数据放在哪)
堆空间比较大,栈所占空间比较小
对于栈来说,不存在垃圾回收,只有溢出
栈中的基本单位叫栈帧
一个栈帧对应一个方法,栈帧内部结构:
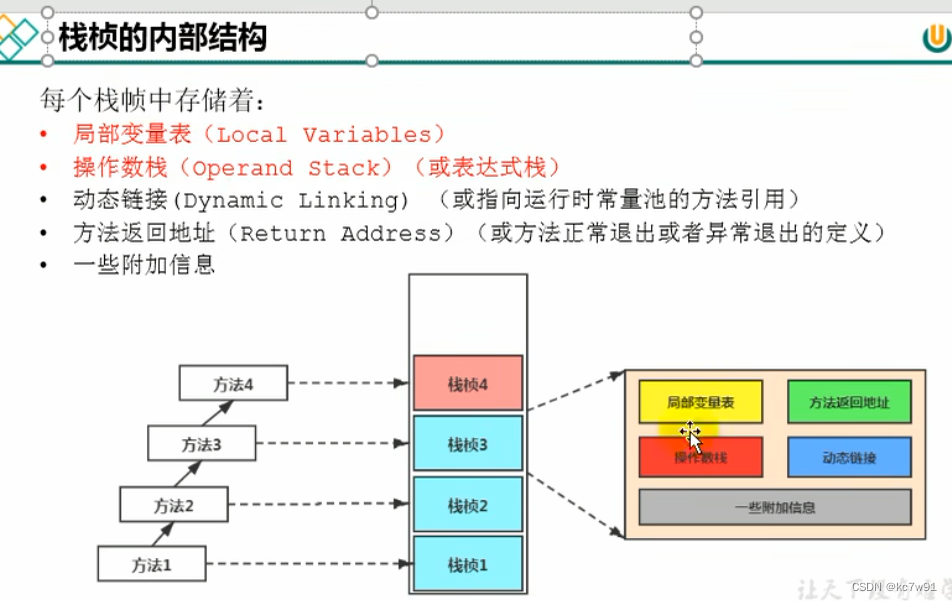
局部变量表的大小在编译的时候就确定
补充1: Java是一种静态语言,与python相比,变量的类型在编译时就确定,python中一个变量的类型是随着具体的运行代码而变化的(比如从double变成int)。而Java8之后引入了lambda表达式,使得有点像
补充2: 函数式接口(一般在这个接口前使用@FunctionalInterface注解,让敲代码的人意识到他是一个函数式接口),指接口中只有一个抽象函数
(1)这个函数式接口的实现可以通过匿名内部类
interface MyInterface {
void doSomething();
}
public class Main {
public static void main(String[] args) {
MyInterface myInterface = new MyInterface() {
@Override
public void doSomething() {
System.out.println("Doing something...");
}
};
myInterface.doSomething(); // 输出:Doing something...
}
}
(2)Java8后新增了lambda表达式(是一种动态语言支持),也可以使用lambda表达式实现函数式接口
interface MyFunctionalInterface {
void doSomething();
}
public class Main {
public static void main(String[] args) {
MyFunctionalInterface myFunctionalInterface = () -> {
System.out.println("Doing something...");
};
myFunctionalInterface.doSomething(); // 输出:Doing something...
}
}
3.3 本地方法与本地方法栈
标记本地方法,用其它语言实现的
与操作系统部分功能交互(调用c/c++)
本地方法栈用于承接管理本地方法
脱离了JVM
3.4 堆

一个JVM对应一个进程,一个进程对应一个堆,进程里的所有线程共享堆,也可以划分出线程私有堆部分
数组和对象(基本)只会放在堆里,栈帧中的局部变量表里存储数组或对象时,存储的只是他们在堆中的引用,实际上的数组或对象存放在堆里
堆中的对象通过GC回收
3.4.1 堆的分区
堆空间中分成了很多代(区)
jkd7到8中,堆分区的变化:
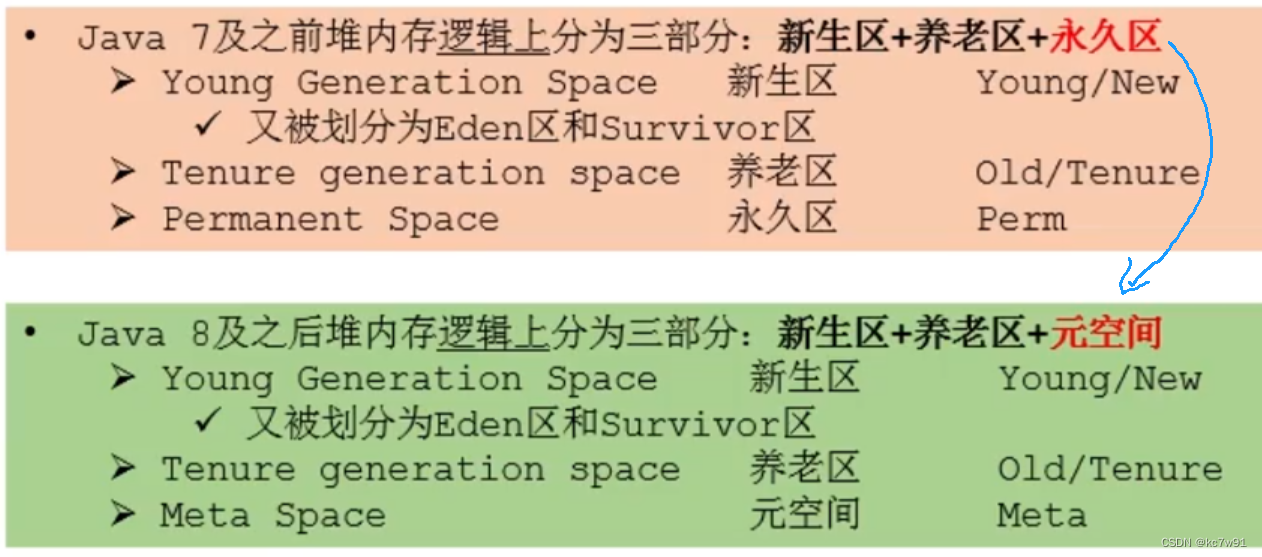
通过-Xms(设置堆空间初始大小)/-Xmx(设置堆空间最大大小)【一般他俩设为同一个值】时,设置的是新生区+养老区的大小
新生区=伊甸园区+幸存者0区(from)+幸存者1区(to)(两个幸存者二选一),谁空谁是to区
伊甸园区满了会触发YGC/Minor GC垃圾回收机制,机制来了会把伊甸园区+幸存者区一起回收
80%的对象在伊甸园区就寄了
流程:
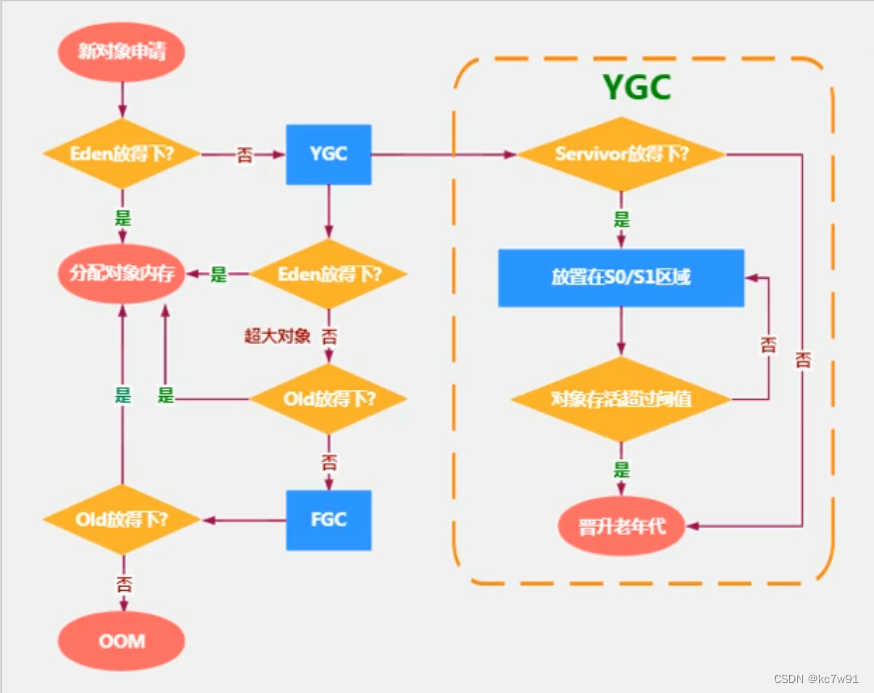
在JVM(Java虚拟机)的垃圾回收机制中,伊甸园区(Eden)、幸存者0区(Survivor 0, S0)和幸存者1区(Survivor 1, S1)是新生代(Young Generation)的组成部分。在对象的生命周期中,它们之间的交互起到了关键作用。以下是它们之间交互的概述:
- 当一个新对象被创建时,它首先会被分配到伊甸园区(Eden)。
- 在伊甸园区发生一个名为"Minor GC"的垃圾回收过程时,JVM会查找并清理那些不再被引用或已经被丢弃的对象。在这个过程中,仍然存活的对象会被移到S0区域。
- 在S0区发生下一次Minor GC时,之前从伊甸园区转移到S0区的存活对象和当时在S0区的存活对象都会被移到S1区。与此同时,S0区的其他对象(不再使用的对象)将被回收。
- 在随后的Minor GC过程中,对象可能会在S0和S1区之间来回移动。每次移动时,对象的年龄会增加。当对象达到某个特定年龄阈值时(可配置),它们会被提升到老年代(Old Generation)区域。
这样的设计有助于实现在新生代中的有效垃圾收集。新生代中,绝大部分对象的生命周期比较短,只有少数对象能够存活长时间。通过这个交互和晋升机制,在新生代中更容易快速地回收垃圾对象。
GC分类:
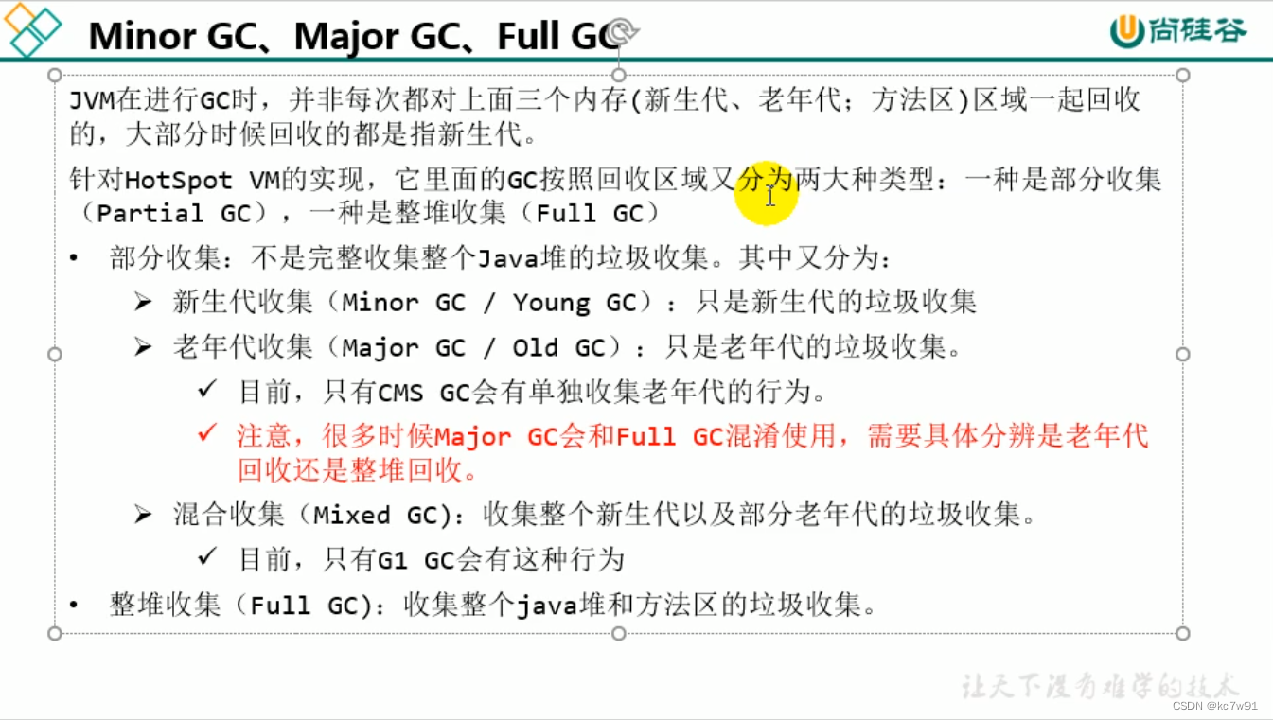
大部分发生在新生代回收
分代的作用:不同对象的周期不同,数据库连接池存在的时间就比较长
大对象直接放到老年区
空间分配优化策略:

3.4.2 TLAB
因为堆空间是很多线程共同可以访问的,容易出现资源冲突,因此TLAB:在伊甸园区为每个线程开辟了独立的空间
3.4.3 堆空间设置参数总结

写在这里:

3.4.4 逃逸及优化
判断是否发生逃逸:看函数中new出来的对象实体是否可能在方法外被调用
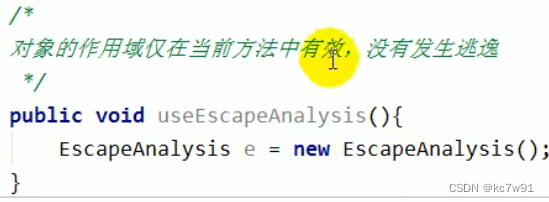
如果没有发生逃逸,则可以进行优化:堆分配–>栈分配,避免GC
辨析:堆里存new出来的对象,栈里存放函数调用,每个函数对应一个栈帧,栈帧里面有每个函数中涉及到的常量以及指向堆中对象的引用。
因此衍生出一种优化方式,对于里面全是常量的对象,把它拆成这些常量,打散了存储在栈帧的数据区中
触发这些优化都要追加相应的指令:
3.5 方法区
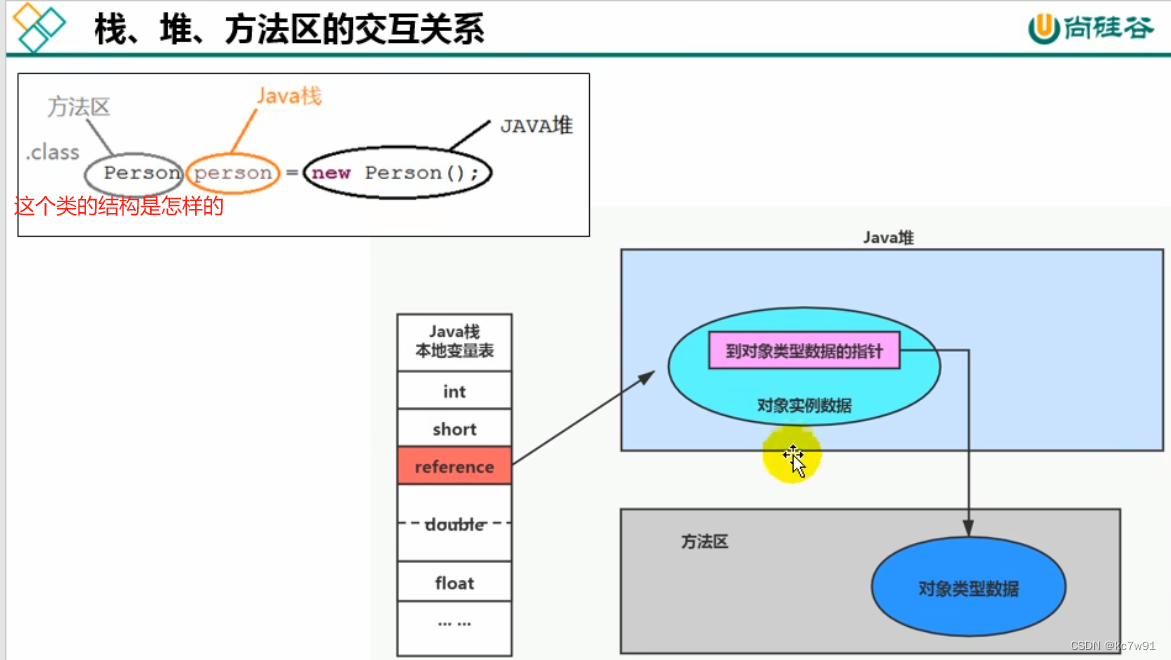
运行时数据区三大件:栈、堆、方法区(主要放的是类的基本信息)
栈是线程私有的,堆和方法区是线程共享的
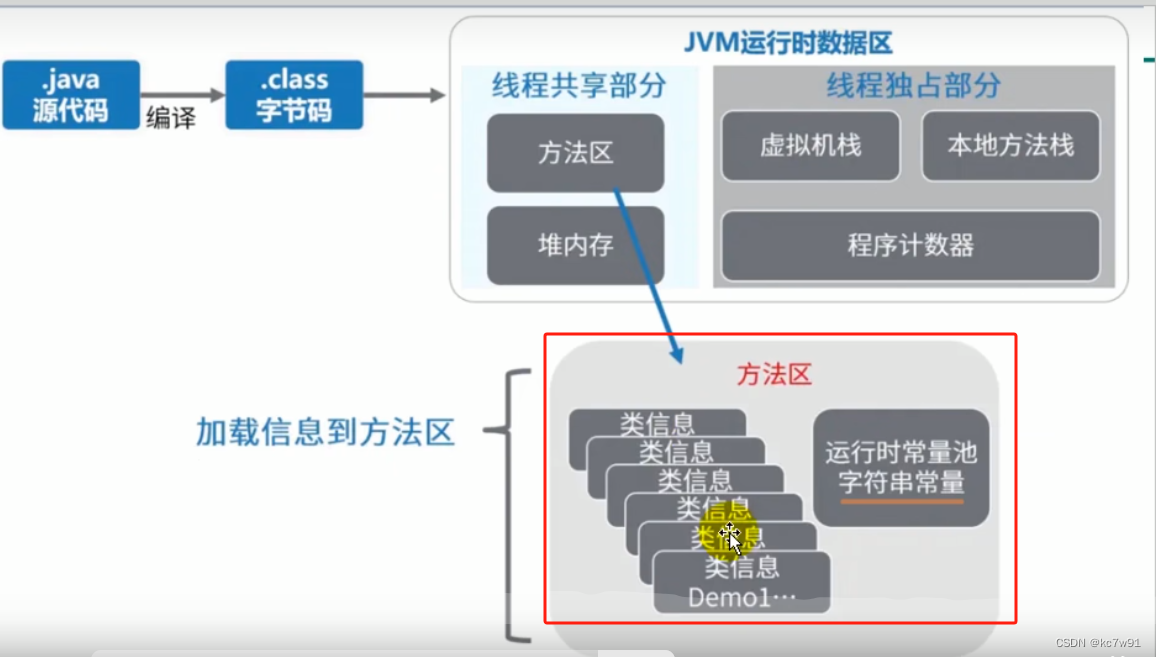
方法区在jdk7以前叫永久代,8及以后叫元空间(metaspace),用的不是虚拟机内存,而是机器内存
3.5.1 方法区里放什么?
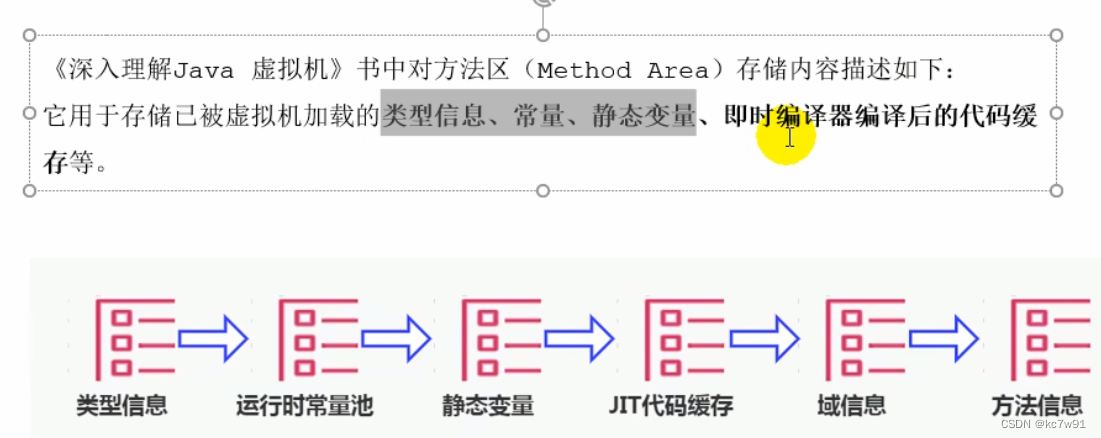
类、枚举类、注解、接口+运行时(的)常量池(hotspot虚拟机中把字符串常量页放在方法区里):
存储类型信息(父类有谁,实现了哪些接口):
也记录了这个类的加载器是谁(Class Loader)

变量:

方法:
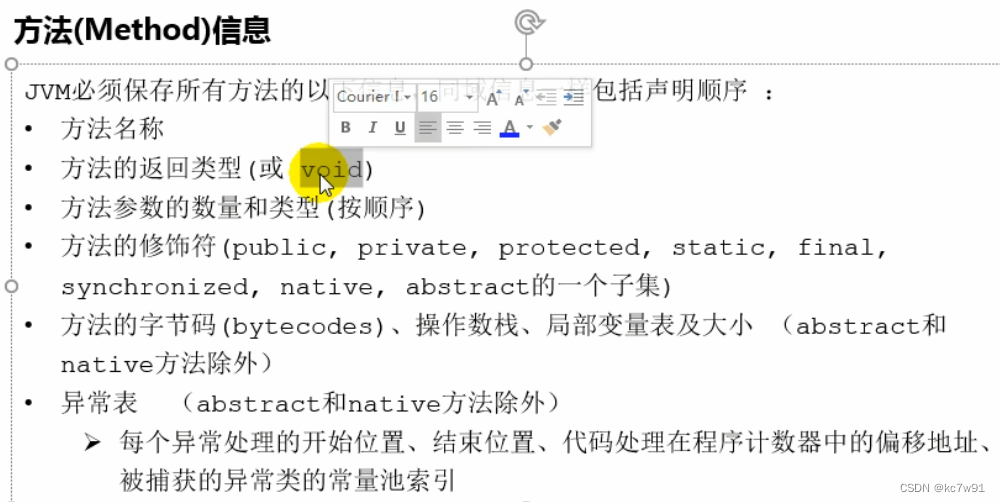
(1).class字节码文件中的常量池:
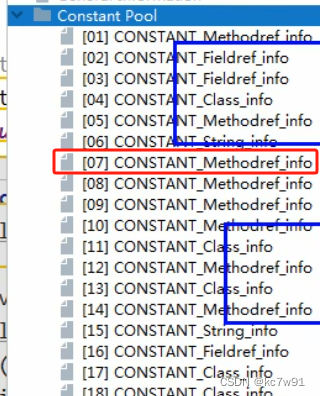
使用常量池时直接#7,常量池里有什么?(this指针也在常量池中)

(2)方法区中的运行时常量池:
就是把字节码文件中常量池中的部分通过类加载器加载进来
JVM为每个类/接口都维护一个常量池

字符串常量池String Table、静态变量存放在堆中
3.5.2 方法区的垃圾回收
可回收可不回收
回收的话,主要回收:常量池中废弃的常量+不再使用的类(这个触发条件比较苛刻)
3.6 运行时数据区总结
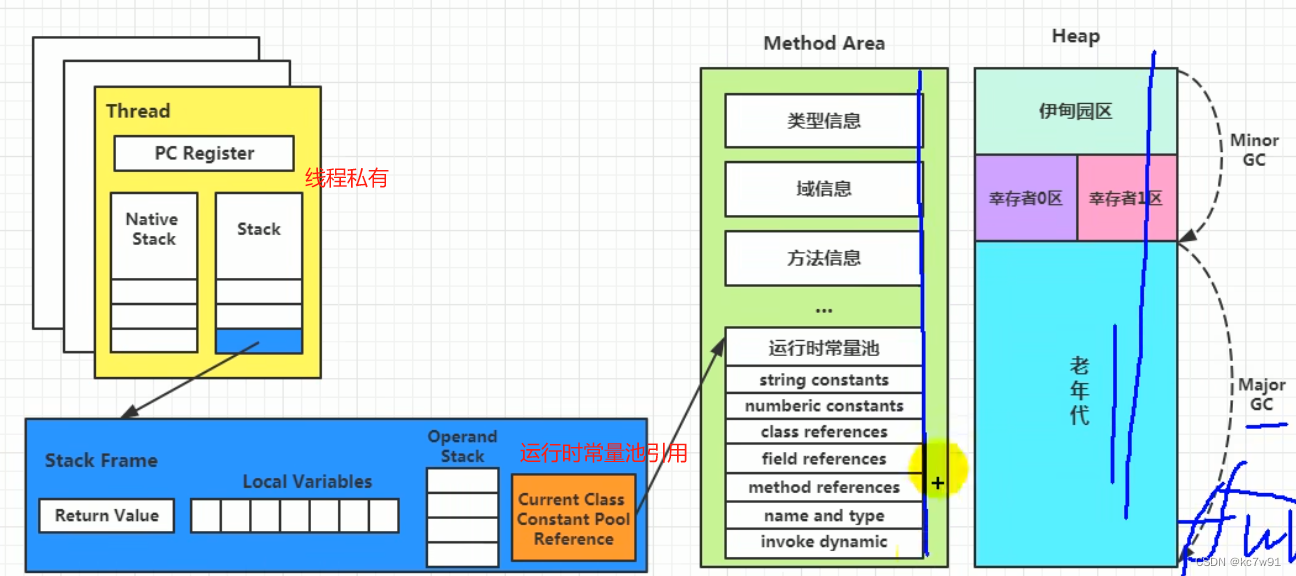
总结:new出来的对象存放在堆,这个对象的类的信息存储在方法区
extra 第三章知识串讲:对象的内存结构是怎样的
E.1 对象的六种创建方式
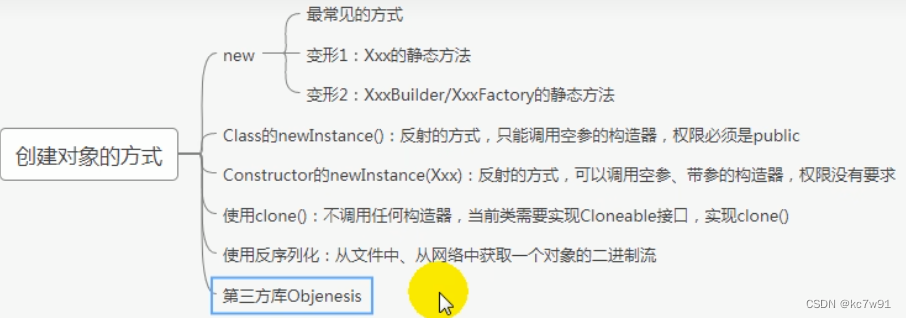
补充:序列化:跨进程进行数据传输,将对象转为字节流,方便网络传输,反序列化就是恢复
E.2 对象的六个步骤
- 加载对象所属类

- 剩下几个步骤
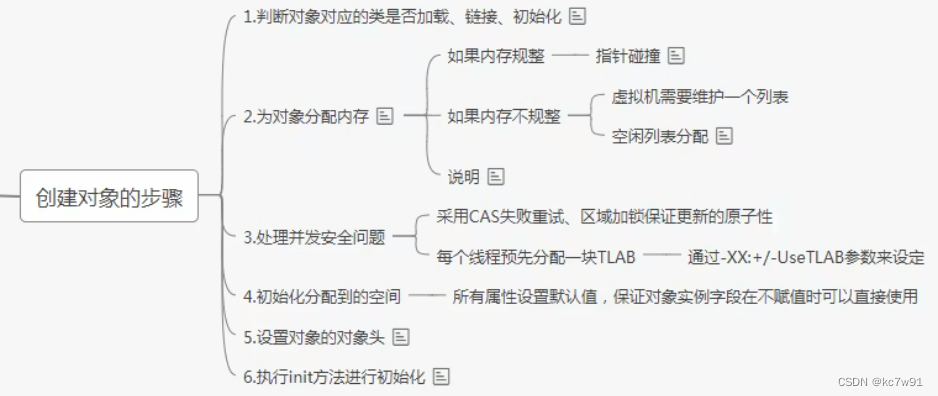
其中5涉及到的对象头,类似方法区(元空间)的信息
步骤6中的初始化是显式初始化+代码块初始化+构造器初始化,不同于步骤4中的默认初始化
E.3 对象的内存布局(在堆中的结构)
对象头+实例数据+填充
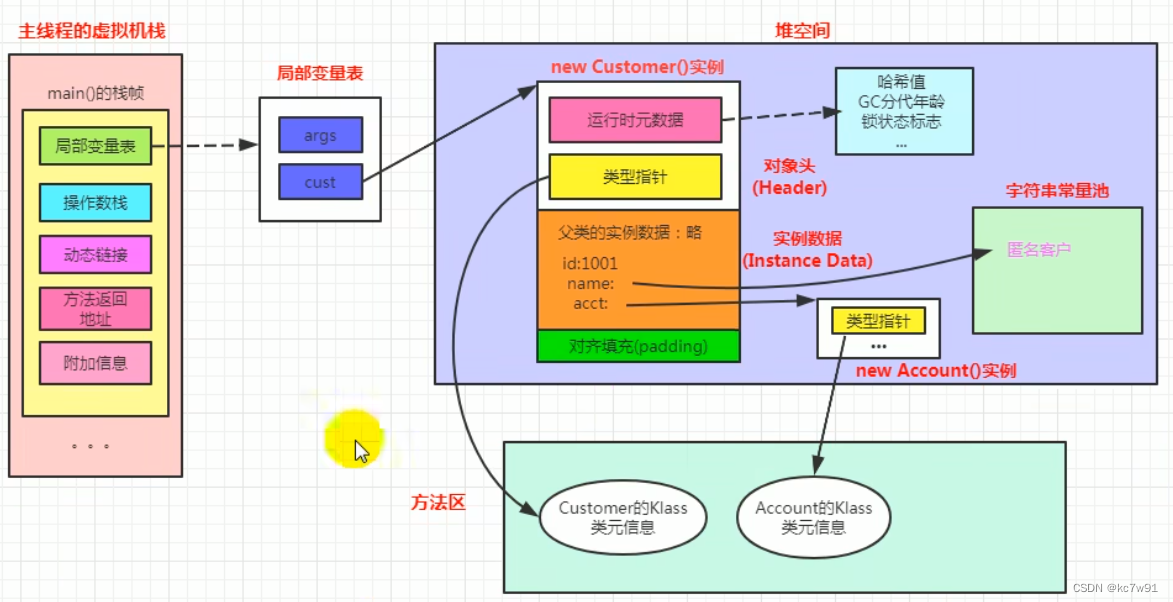
E.4 对象的访问方式
- 句柄访问
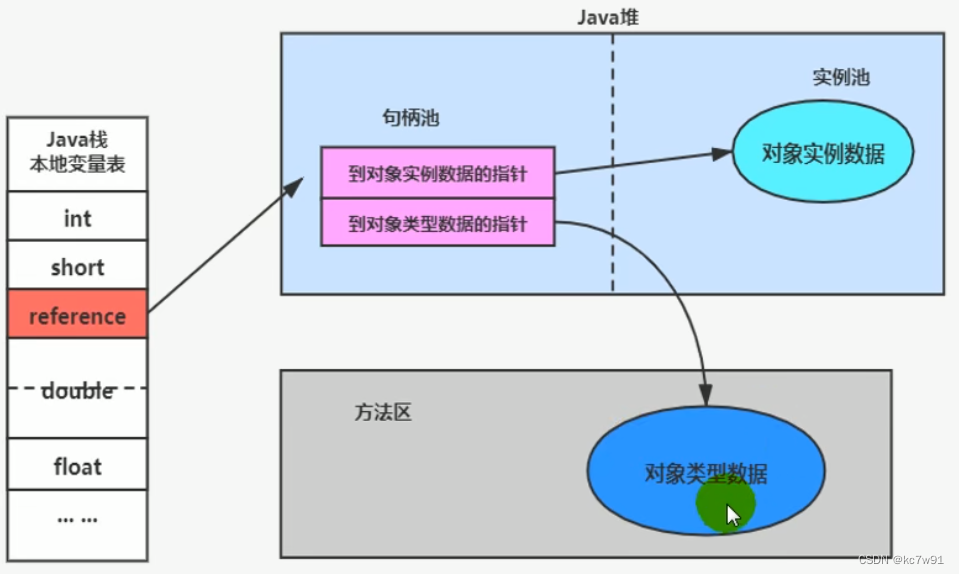
2. 直接指针(hotspot)

4 执行引擎
负责把字节码指令翻译为机器指令
解释+编译(JIT,后端编译器)
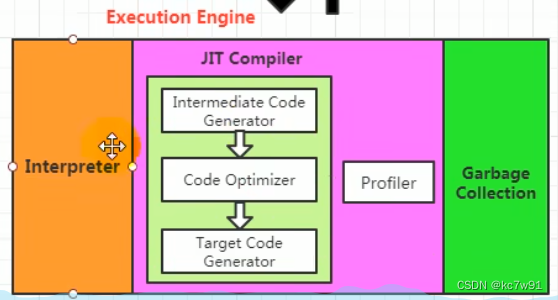
解释器(低效)与编译器,可以二选一进行解释字节码:
也因此Java被称为半解释型半编译型语言
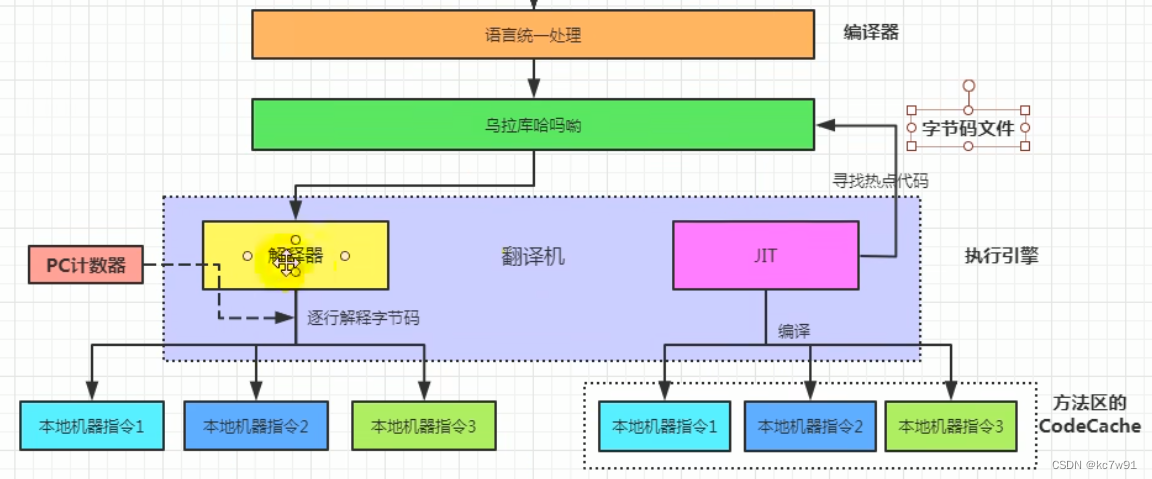
二者使用衡量:

热点代码用JIT。如何判断是否为热点代码?(1)方法计数器(方法执行了几次)(2)回边计数器(循环执行了几次)
JIT里面有两个编译器C1(client)/C2(server 默认)

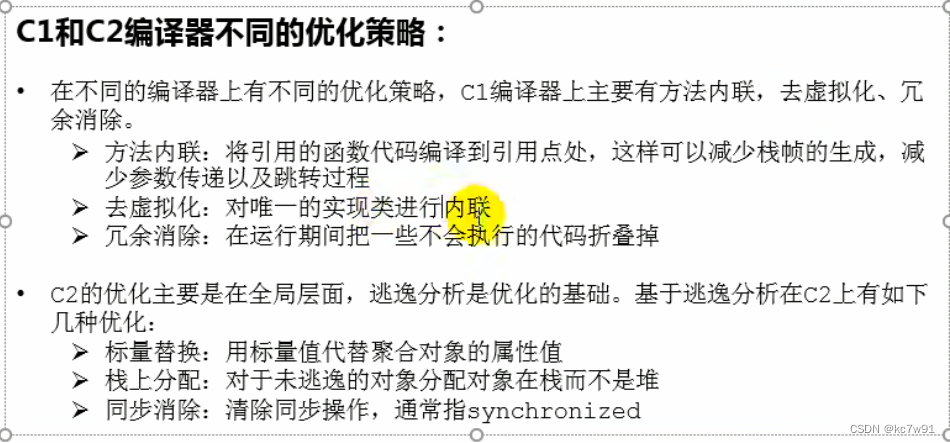
5 String Table
String在jdk9之后,底层实现从char[](一个char占用两个字节16bit)变成了byte[](节约了一些空间)
String是堆空间的主要存储部分(放在堆里), 大部分存的是拉丁文(一字节就存得下),因此用1byte就能存储,还用char[]的话浪费空间
5.1 String基本特征:不可变性
字符串常量池中的String具有不可变性,一旦堆原字符串进行修改,则将在字符串常量池中开辟新的字符串常量
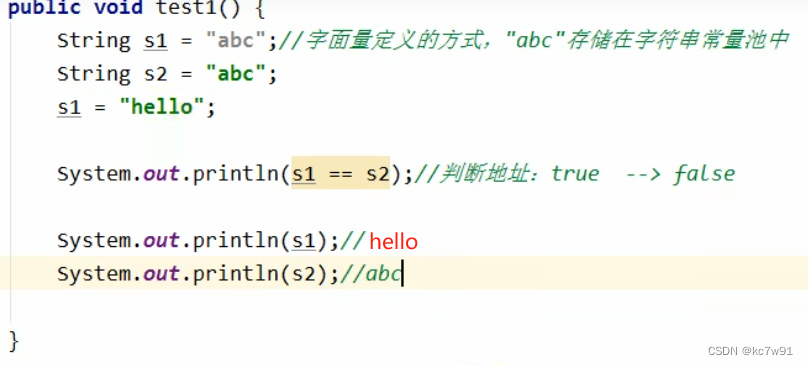
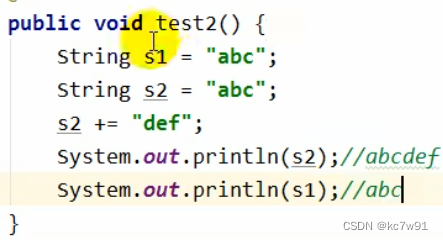

string table本质是笃定大小的hashtable(本质数组+链表)

intern方法:

5.2 String内存结构分配(拼接操作)
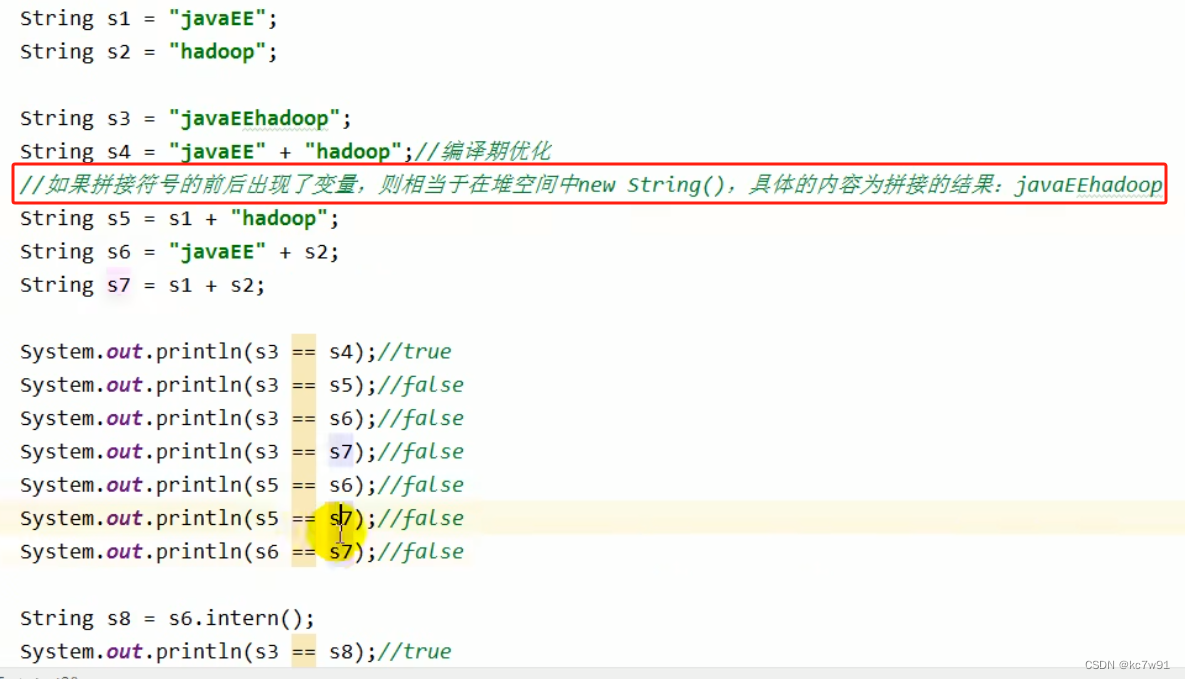


final修饰变为常量:
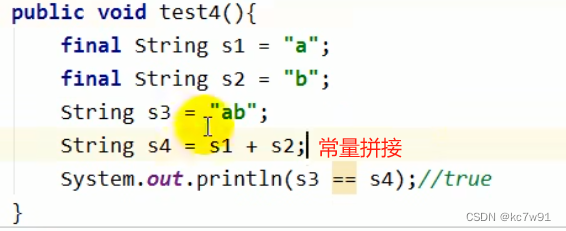

5.3 intern方法
去字符串常量池里找是否存在某个字符串,存在则返回地址,不存在则创建后返回:


常见面试题(如何验证?看字节码):
(1)问题一


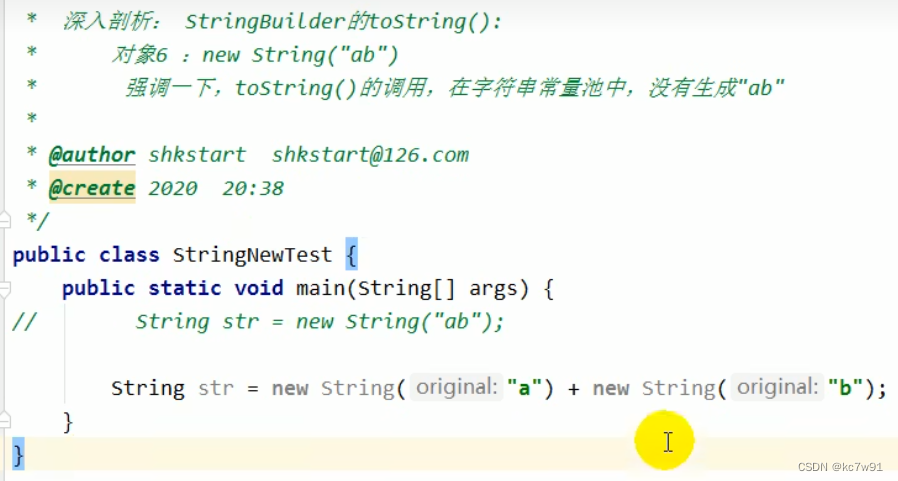
(2)问题二

解释:


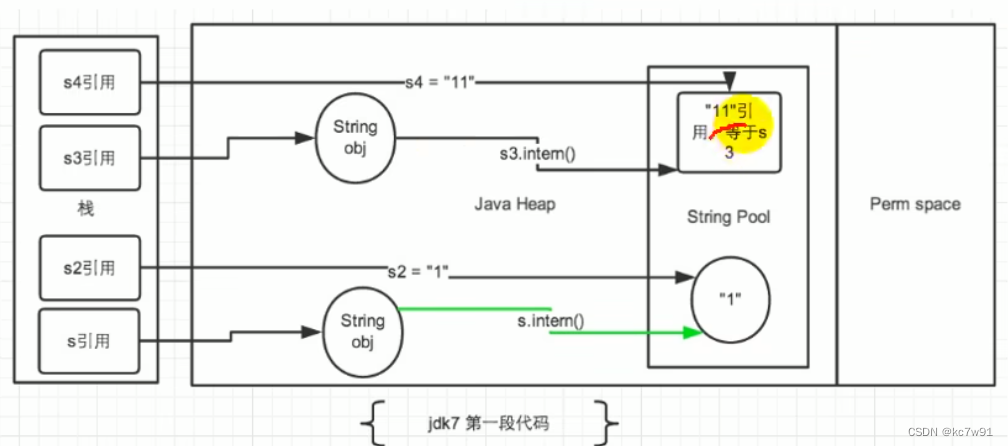
不好理解
总结:

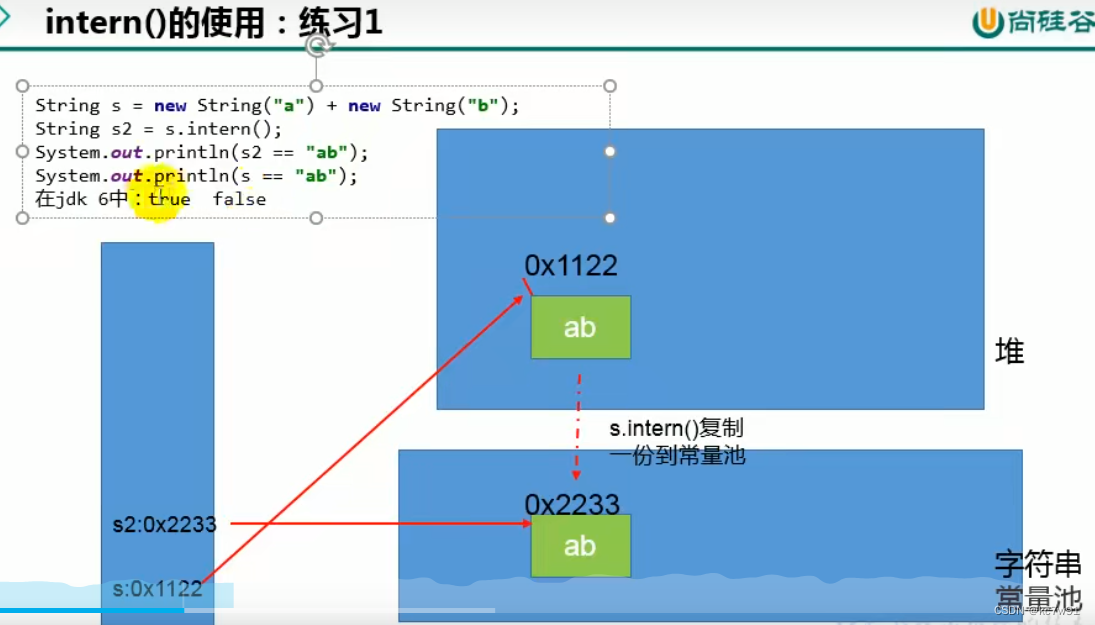
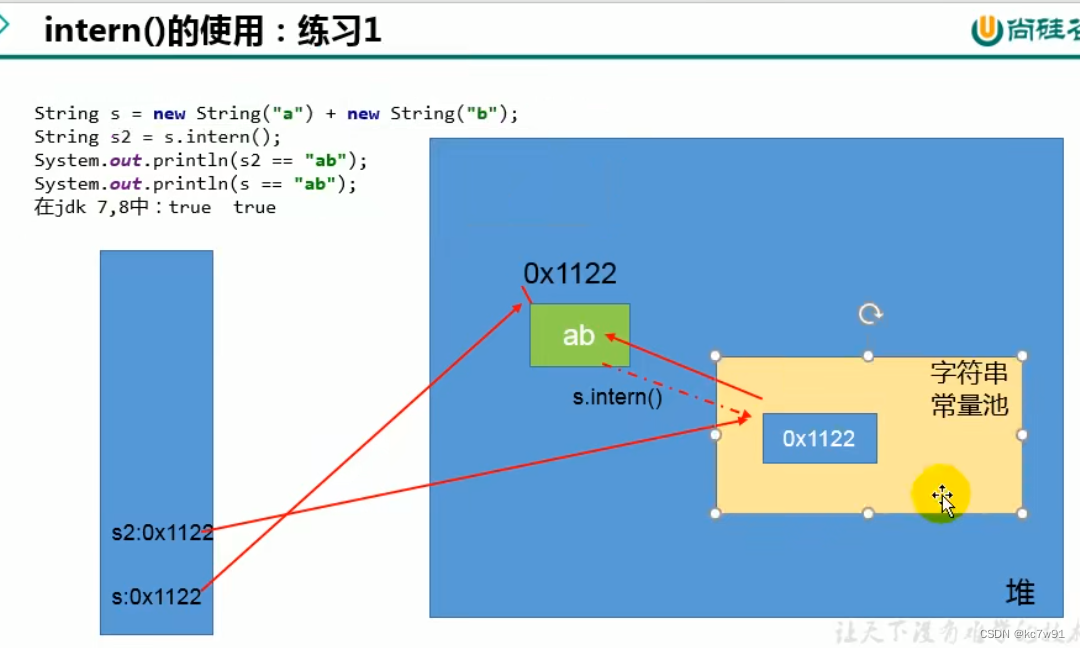
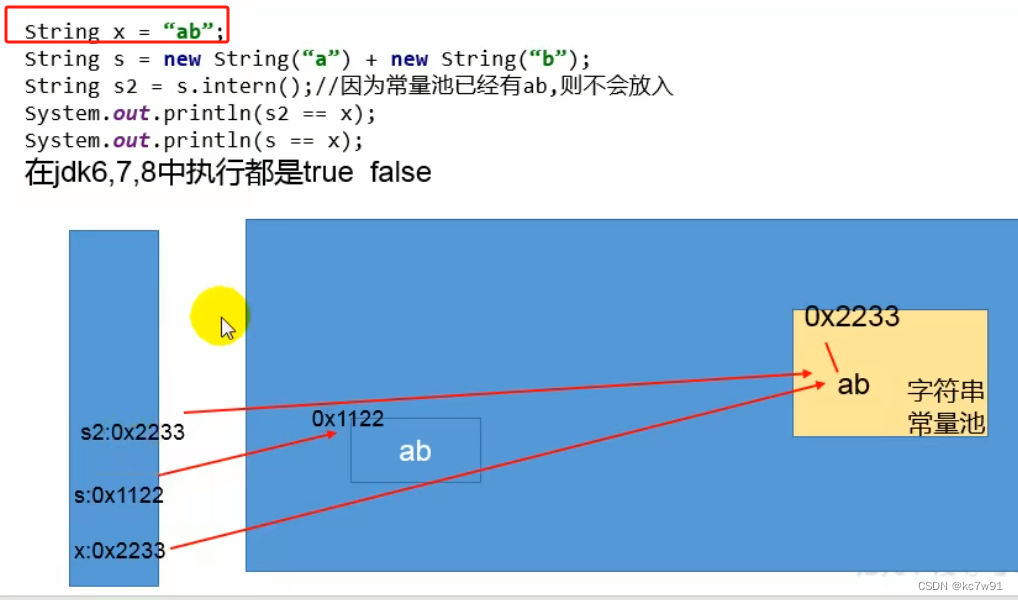
这几个例子直接给干蒙了,还是推荐视频
6 垃圾回收
6.1 垃圾标记方法
- 引用计数算法: 额外加个计数器,记录每个对象的被引次数,但是因为致命缺点(循环引用)所以不会使用这种GC方法

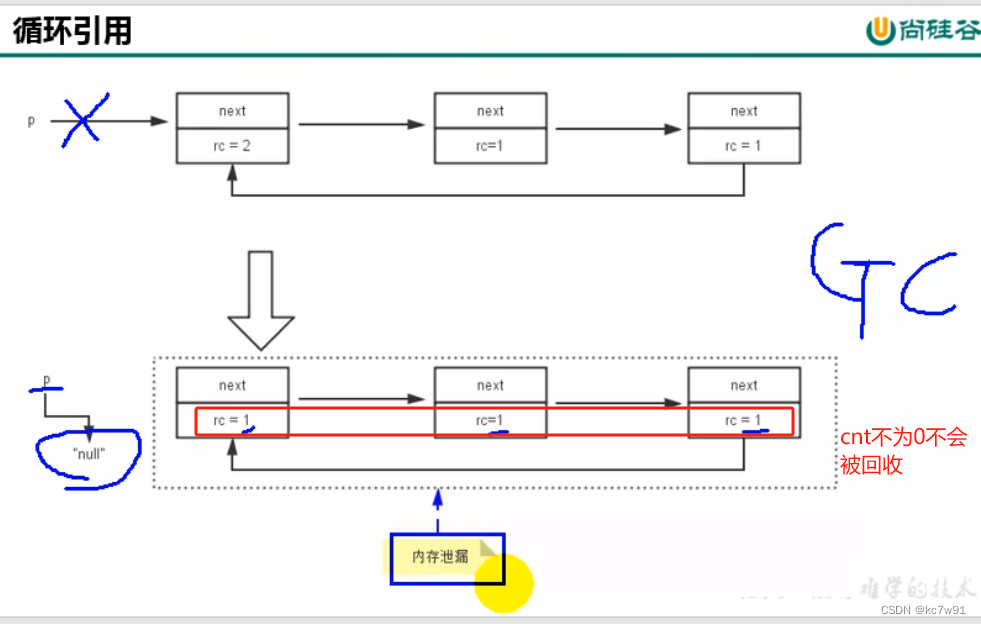
- 可达性分析: 引用链

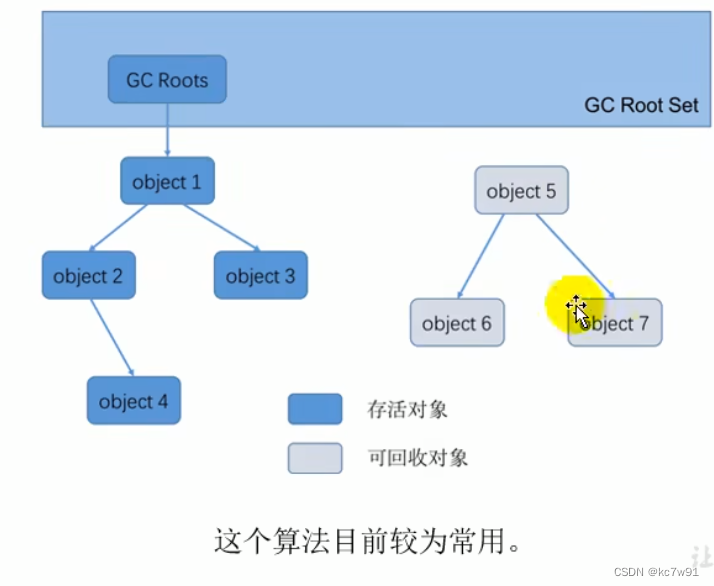
下图维面试题,至少答上来这三种GC Roots

extra:finalized方法(Object的方法,可被复写):对象被回收前的一些操作,由GC控制,给了一次“刀下留人”的机会,只会被调用一次
由于这个方法的存在,可以将要死的对象分为三种状态(面试题):

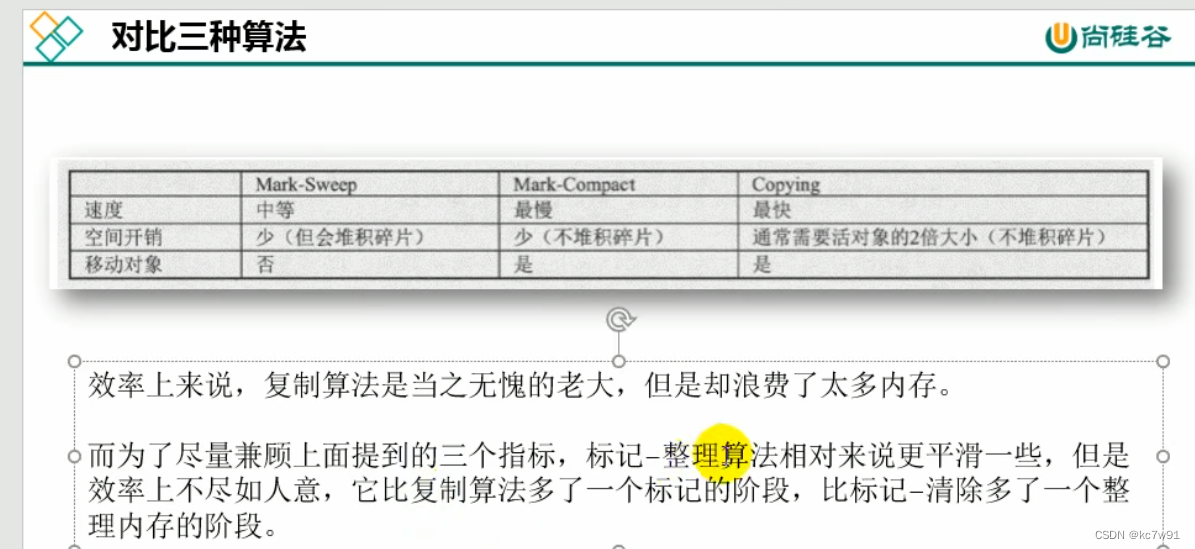
6.2 垃圾清除算法
-
标记-清除法
标记可达对象,放在对象头里,没被标记的清除 -
复制算法(空间紧密)
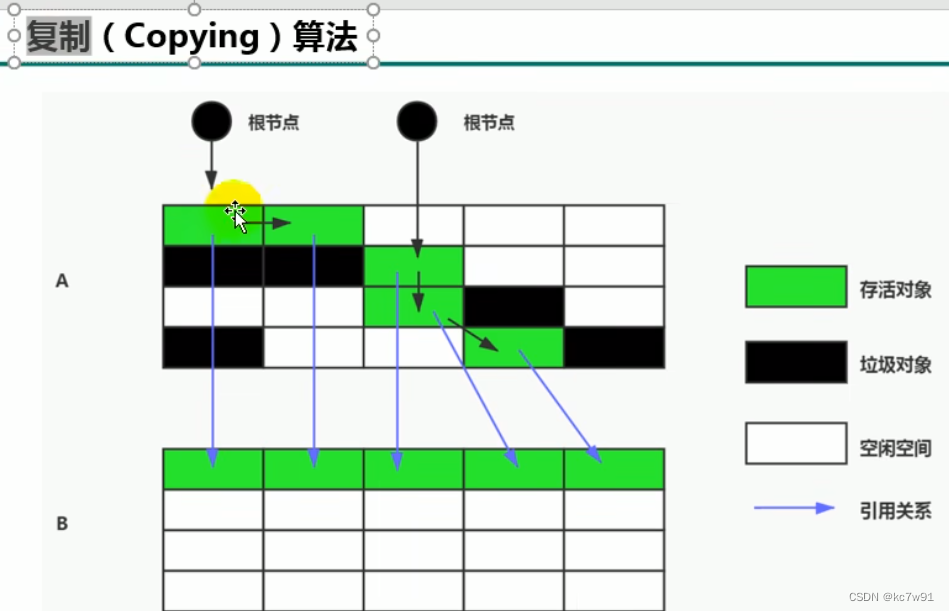
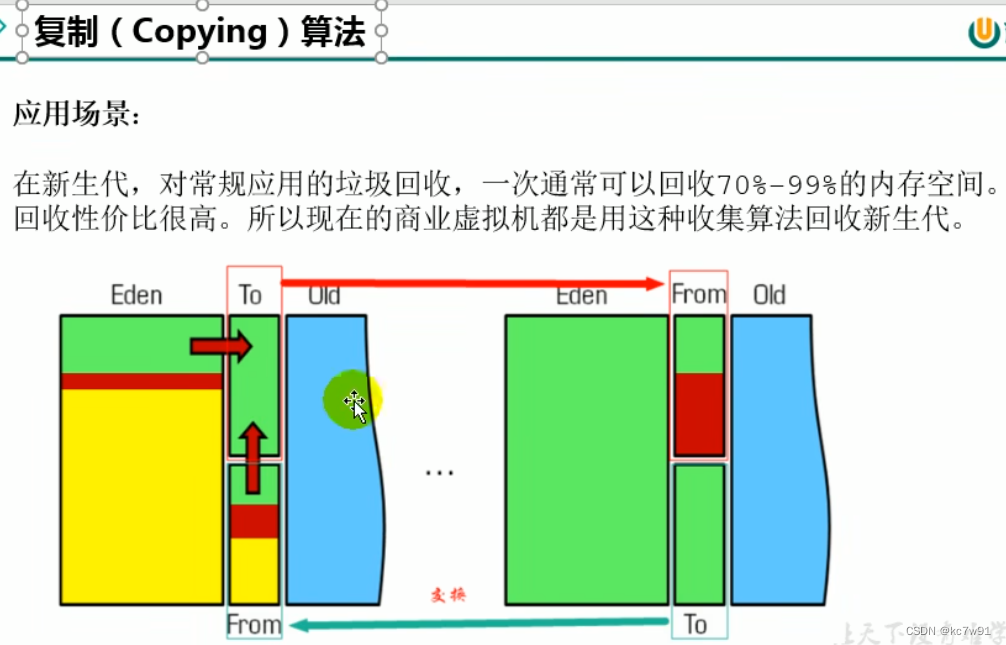
适合场景:存活对象少,垃圾多,这样复制过去的少,AB区会互换

应用:
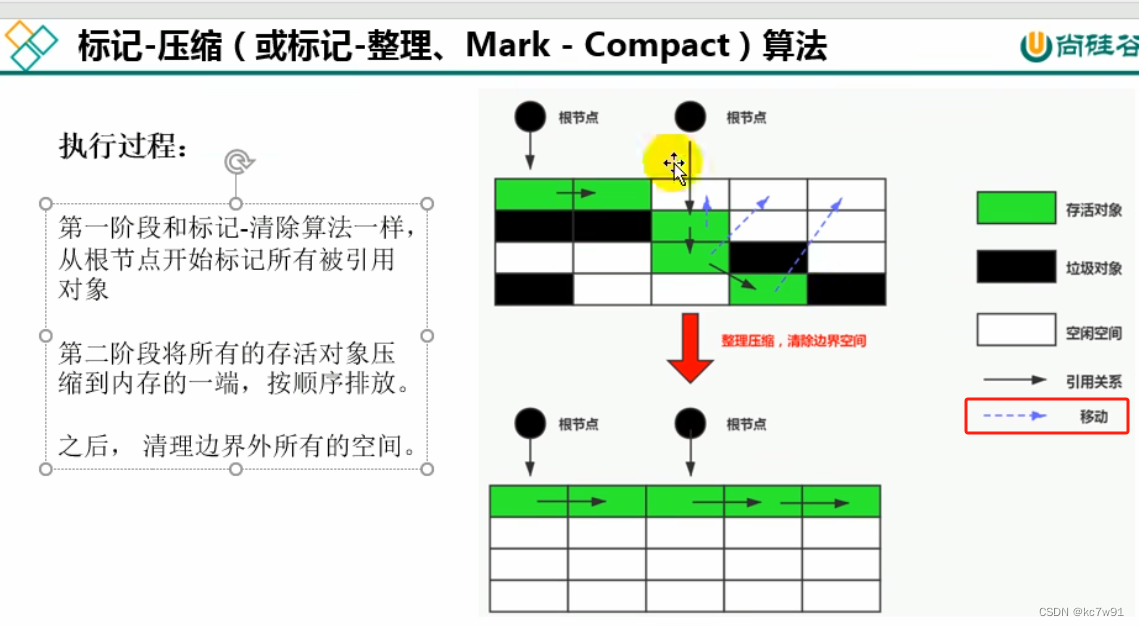
3. 标记-压缩(整理)算法
4. 分代收集算法(具体问题具体分析,不同生命周期不同回收方式)
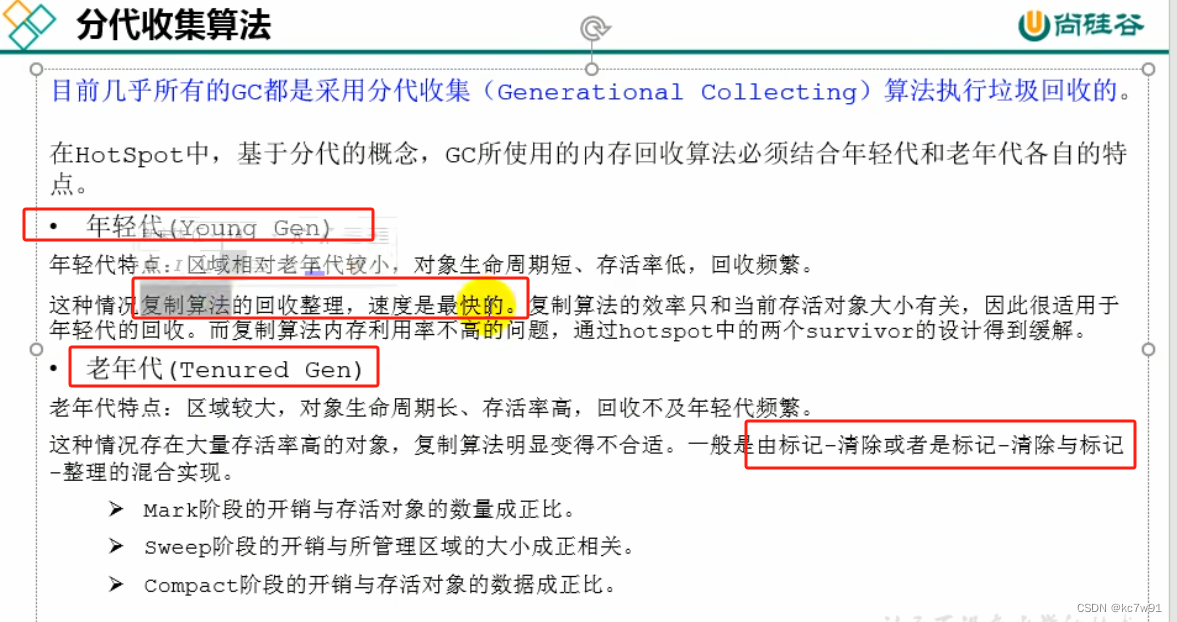
针对老年代的回收器:CMS

5. 增量收集算法
之前的方法必须STW(stop the world)中止所有用户线程

模拟并发,低延迟
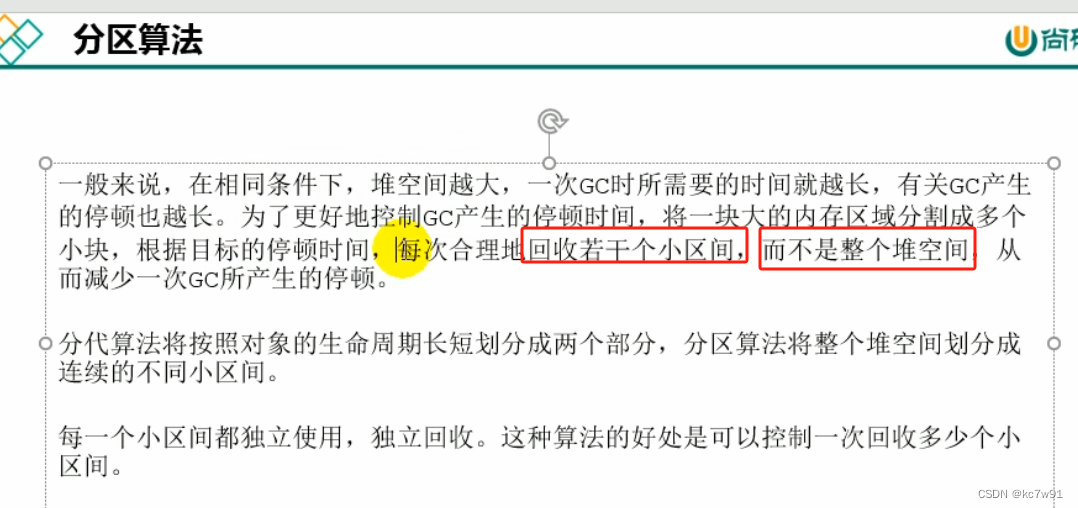
- 分区算法,也为了降低延迟(STW)
7 垃圾回收器
垃圾回收中的并发:用户线程与垃圾回收线程交替执行
垃圾回收中的并行:多条垃圾回收线程并行工作(多核)
GC评估指标:
(1)吞吐量:用户线程时间/(用户线程时间+GC时间)
(2)暂停时间:单词GC时间
现在标准:在最大吞吐量优先的情况下,降低停顿时间(G1)
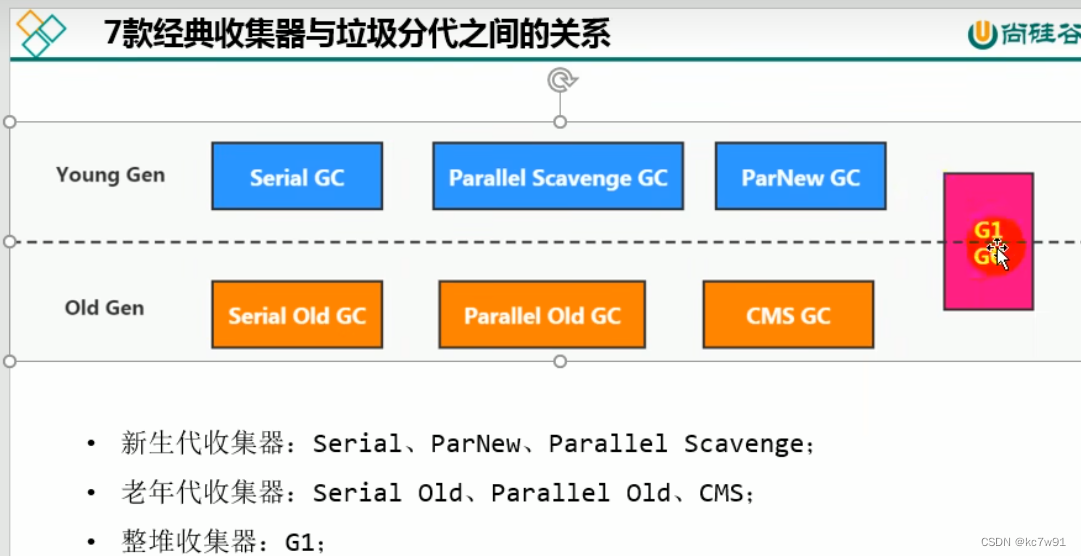
新生代垃圾收集器跟老年代垃圾收集器的组合:
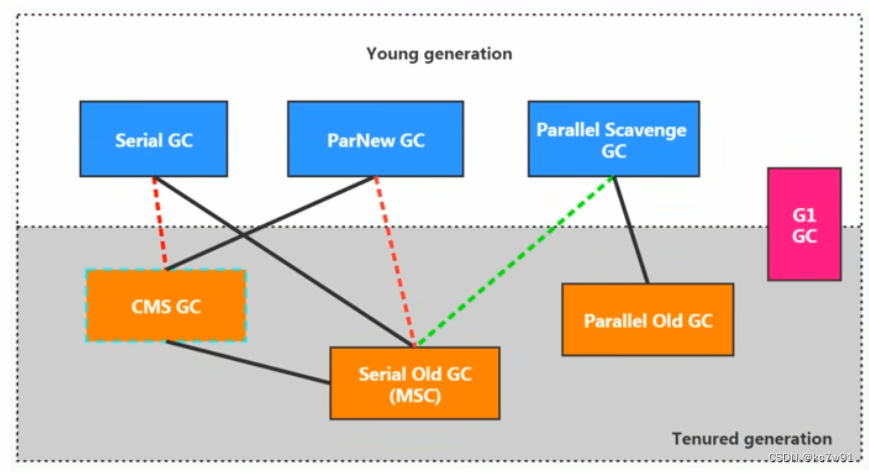
虚线表示随着jdk升级,不再搭配使用
8.1 Serial串行回收器
针对新生代的收集器,采用复制算法+串行回收+STW
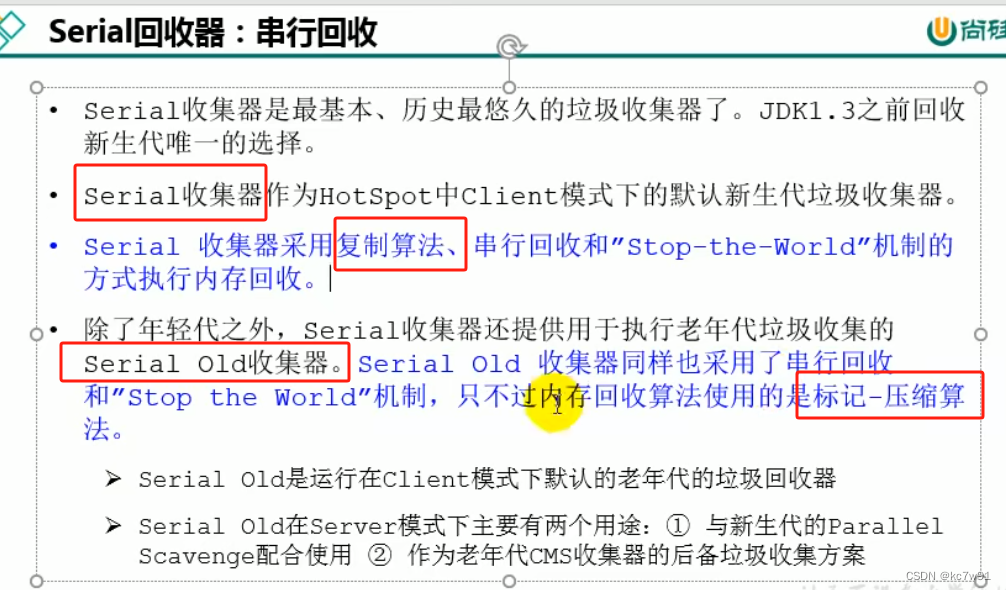
一般单核场景才使用
8.2 ParNew并行回收器 & Parallel回收器
都是回收新生代,复制算法+并行回收+STW
但后者吞吐量优先,且能自适应调节策略
jdk8默认:parallel gc+parallel old gc
8.3 CMS垃圾回收器(低延迟/低暂停时间)
CMS:concurrent mark sweep 并发标记清除,实现用户线程和垃圾回收线程同时工作
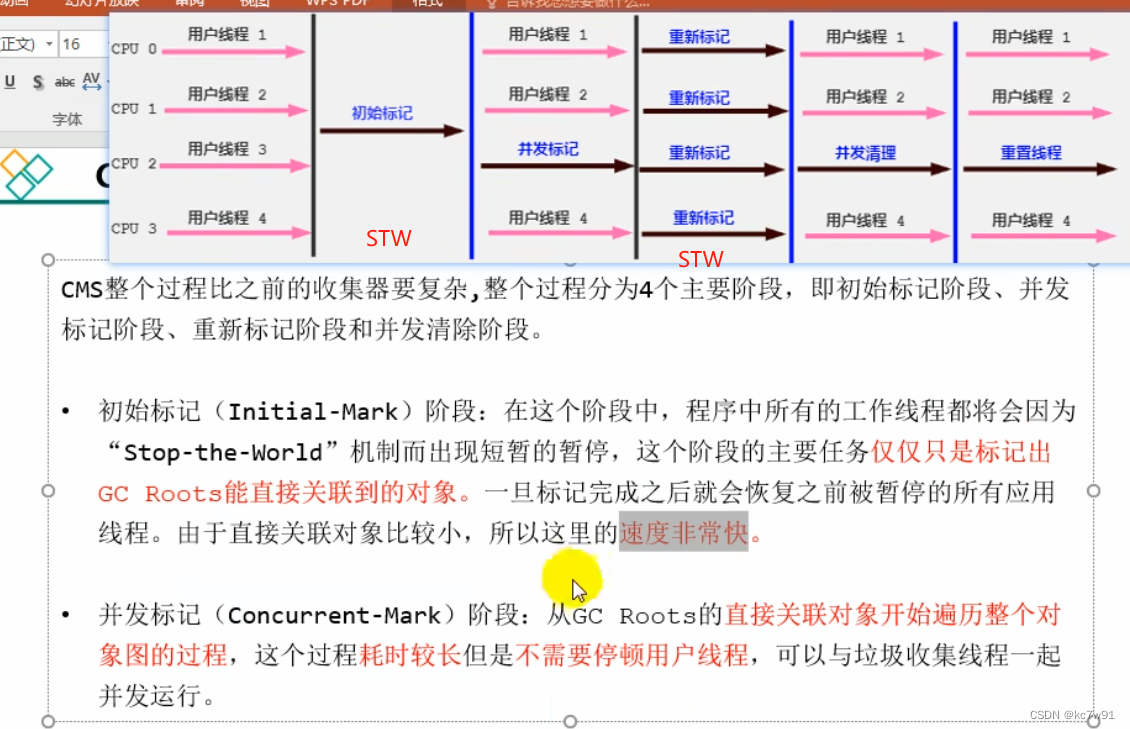

因为采用标记-清除算法,所以会产生内存碎片

8.4 G1垃圾回收器(区域化分代式)
parallel实现吞吐量(垃圾收集时间占比小)
CMS实现低延迟(不让用户线程等待过长)
G1:延迟可控(用户等待时间短,STW少)的情况下尽可能提高吞吐量(垃圾收集时间占比小)
既能用于新生代,又能用于老年代

分区(跳出之前的分区逻辑),优先回收垃圾多(价值大)的region
接下来(4个)每小节代表其一个特点
8.4.1 并行与并发
并行:多个GC同时进行,需要STW
并发:无需STW,GC与用户线程交替执行

8.4.2 分代收集
不再要求伊甸园区、幸存者区、老年区连续,而是以Region的视角
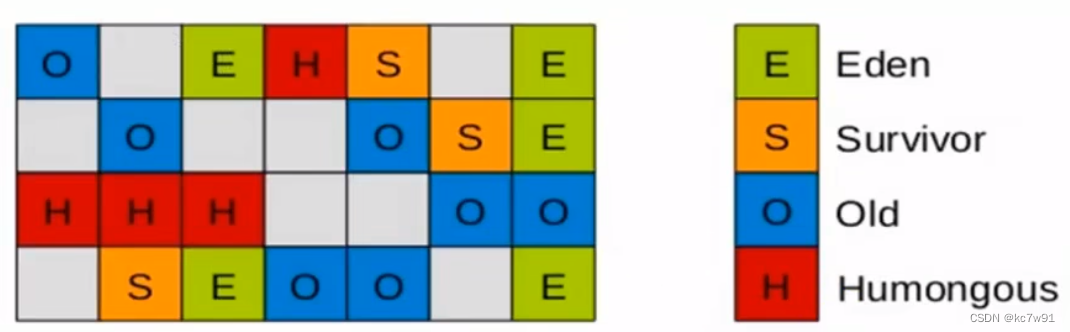
8.4.3 空间整合
解决碎片化问题

复制之后紧密排列到一起
8.4.4 可以限制垃圾回收时间

每次按照region的优先级清理一部分垃圾(同时考虑垃圾回收时间)
8.4.5 G1垃圾回收过程
适合大内存,多处理器的服务端
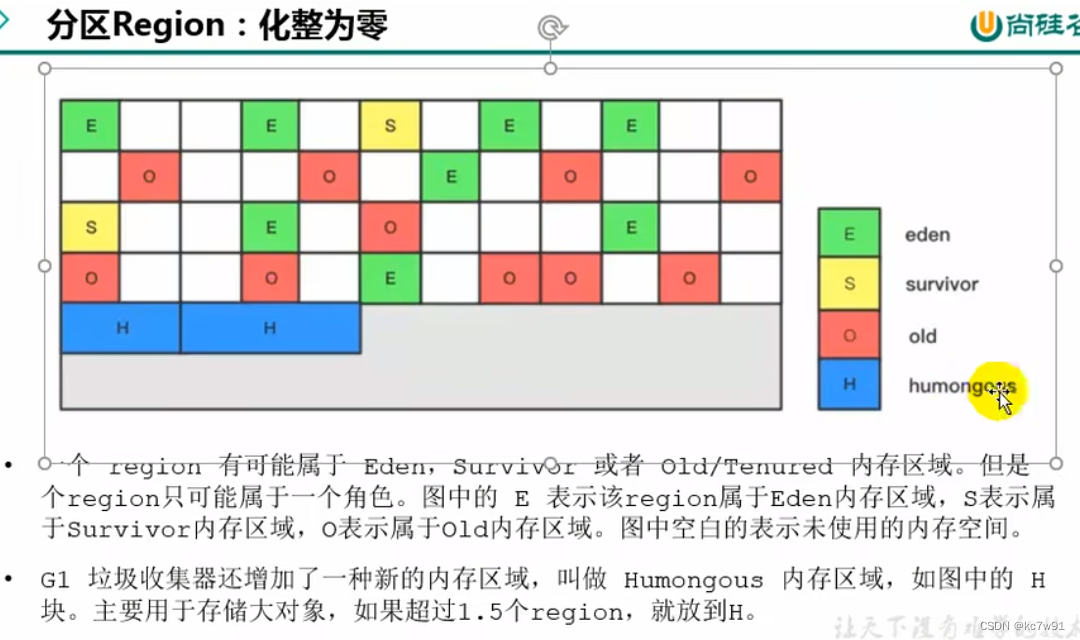
region细节:




8.4.6 记忆集
场景:回收某个伊甸园区的region时,此region中的内容可能被其它region引用(用于判断当前region是否存活)。如果引用他的也是伊甸园区的region那还好说,一次遍历结束。但是如果是老年区的引用了,那遍历起来就很麻烦(YGC时遍历老年区,离谱)
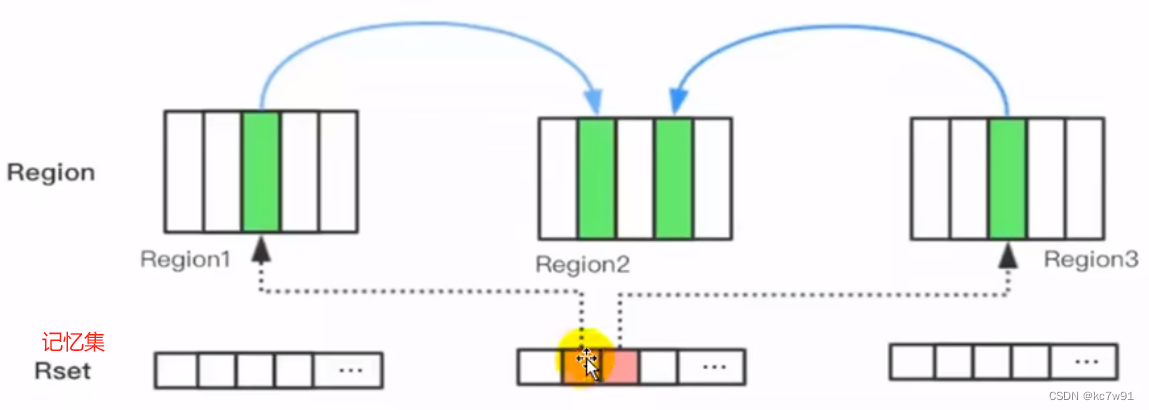
每个region对应一个记忆集,记录了有谁引用当前region。之后GC就不扫描全堆了,只看记忆集就行

完整过程:


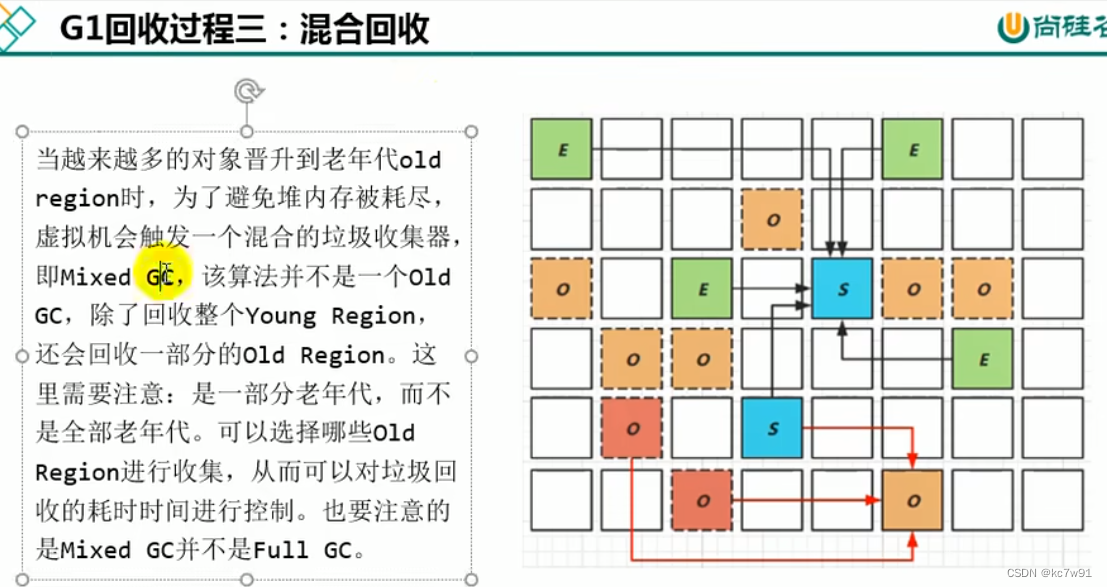















 410
410











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









