







0x00 前言
上一篇主要如何通过向浏览器页面注入 JavaScript 代码来尽可能地获取页面上的链接信息,最后完成一个稳定可靠的单页面链接信息抓取组件。这一篇我们跳到一个更大的世界,看一下整个漏扫爬虫的运转流程,这一篇会着重描写爬虫架构设计以及调度部分。
0x01 设计
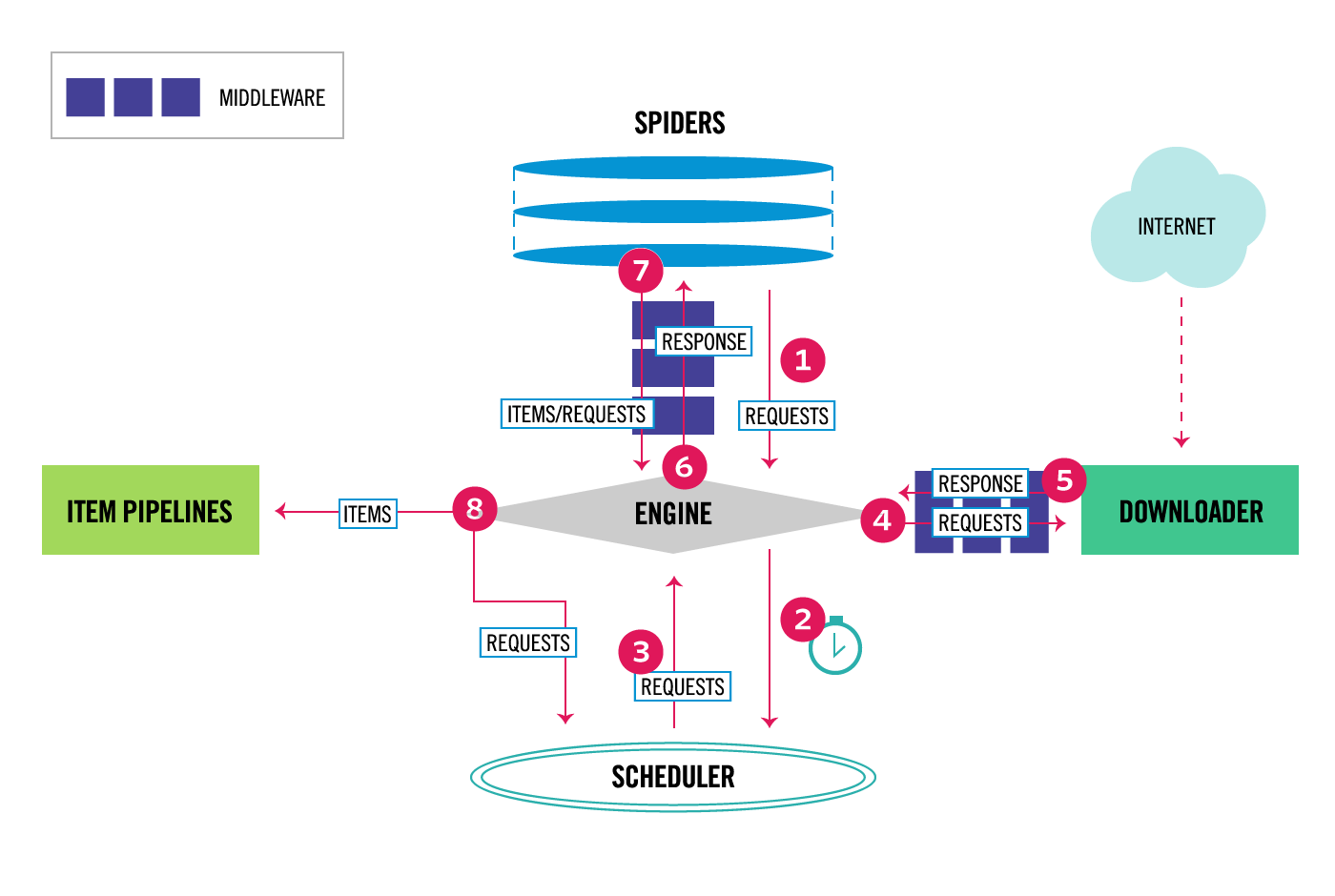
这张图片是不是很熟悉,其实这就是 Scrapy 的架构设计图,我们简单看一下这张图的流程:
- 1.Engine 拿到 Requests
- 2.Engine 将 Requests 丢到 Scheduler 中,并向 Scheduler 请求下一个准备抓取的 Request
- 3.Scheduler 返回下一个准备抓取的 Request
- 4.Engine 将 Request 丢到 Downloader 中,中途经过 Downloader Middlewares 处理
- 5.Downloader 处理 Request 产生 Response 返回给 Engine,中途经过 Downloader Middlewares 处理
- 6.Engine 将 Response 丢到 Spider 中,中途经过 Spider Middleware 处理
- 7.Spider 处理 Response 产生出 item 和新的 Requests 返回给 Engine,中途经过 Spider Middleware 处理
- 8.Engine 将 item 丢到 Item Pipelines 处理,同时将 Requests 丢到 Scheduler 中
重复 1-8 步骤,直到 Scheduler 没有新的 Requests
在整体架构上我直接参考了 Scrapy 的设计,只不过我实在受不了 Twisted 那种扭曲的写法, 所以直接换了个网络库重新造了个和 Scrapy 差不多的轮子,新的架构图如下:
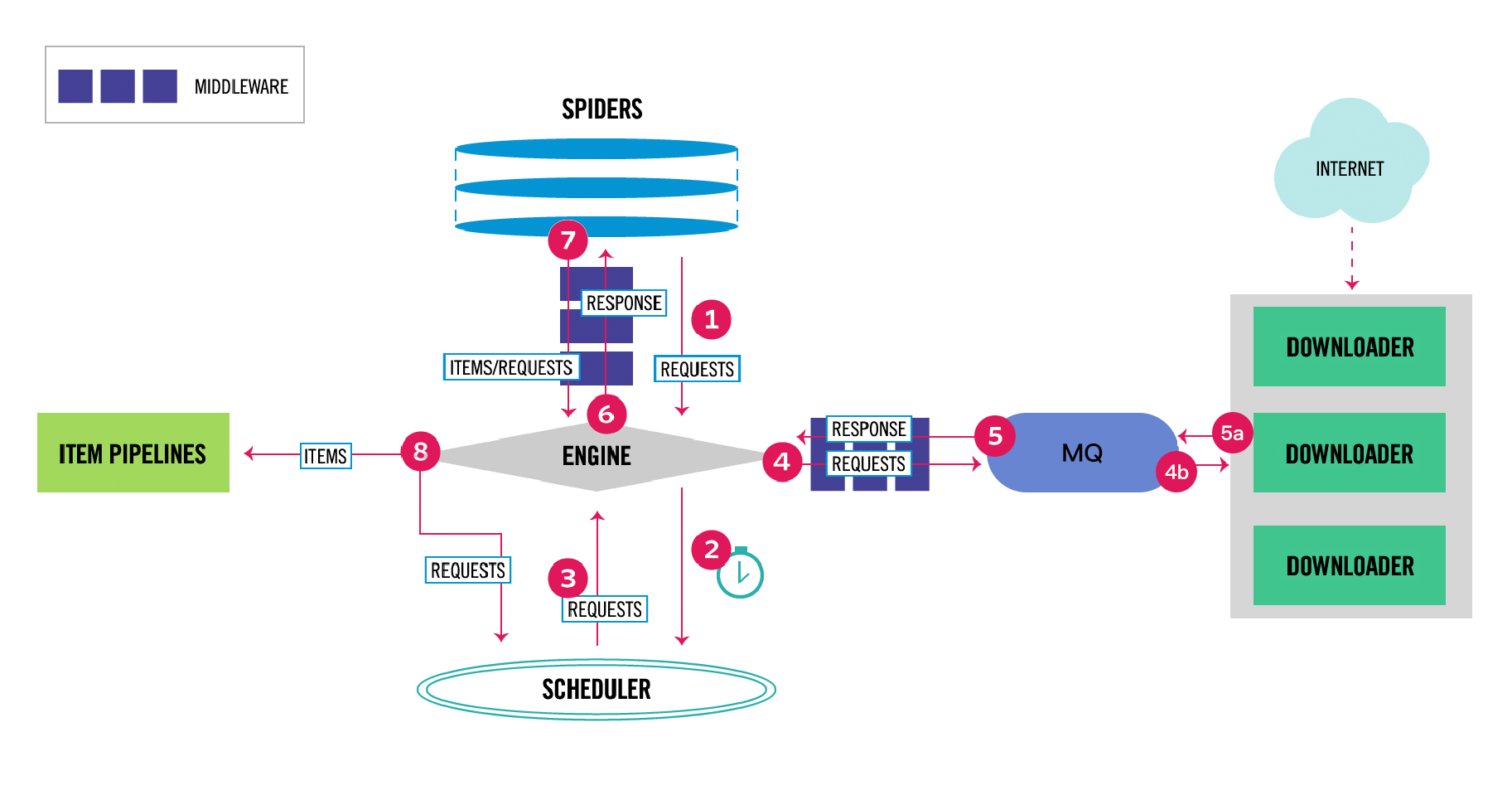
上面架构图中消息队列(MQ)左边的内部名为 CasterPy,右边的内部名为 CasterJS, 我们前两篇主要介绍的单页面链接信息抓取组件(CasterJS)就是上面的架构设计中的 Downloader, 我们的架构设计和 Scrapy 的区别是:
- 我们的 Downloader 直接返回链接信息而不是返回响应内容
- 我们的 Downloader 是分布式的,可部署在不同
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1696
1696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









