











虽然是理工妹子,但仍是数学渣。症状之一就是每次学习算法都能把自己绕成鸡窝头。所以尝试写一篇数学渣眼中的HMM。
我们先看一个让人头疼的HMM定义式(喜欢从公式下手是我多年来应付考试养成的不良习性)
一、HMM五元素
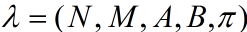
HMM简介 - 碳基体 - 碳基体
N:隐藏状态数 hidden states
M:观测状态数 observed states
A: 状态转移矩阵 transition matrix
B:发射矩阵 emission matrix
pi:初始隐状态向量 initial state vector
好了,接下来我们用数学渣可以理解的语言来解释上面都是些什么鬼
女主:小红 用食物丈量心情
心情状态有三种: 开心、正常、崩溃
上面三种状态的时候吃的食物也有三种: 汉堡、 西瓜、啤酒
男主:小明 面部表情识别障碍
因此对男主而言,
隐藏状态:女主的心情状态
观测状态:女主吃的食物
隐藏状态数 :N=3
观测状态数: M=3
初始隐状态向量pi:
对照下表看:女主处于各种心情状态的概率,例如女主51%的概率是正常的,36%的概率是开心的,13%的概率是崩溃的
开心 正常 崩溃
0.36 0.51 0.13
状态转移矩阵A:
上一个隐状态到下一个隐状态的转化概率矩阵
对照下表看:在女主上一个状态是开心的条件下,则此刻状态是开心的概率为36.5%,正常的概率为50%,崩溃的概率为13.5%
开心 正常 崩溃
开心 0.365 0.500 0.135
正常 0.250 0.125 0.625
崩溃 0.365 0.265 0.370
发射矩阵B:
隐状态对应的观测状态的概率
对照下表看:在女主是开心的状态下,她吃汉堡的概率是10%,西瓜的概率是20%,啤酒的概率是70%
汉堡 西瓜 啤酒
开心 0.1 0.2 0.7
正常 0.5 0.25 0.25
崩溃 0.8 0.1 0.1
一个HMM模型就由上面描述的隐藏状态数N,观测状态数M,初始隐状态向量pi,状态转移矩阵A,混淆矩阵B五个要素组成。
我们知道了什么是HMM,接下来看HMM是干嘛的,用mahout的HMM库来示例HMM解决哪三类问题,仍然用小红和小明的场景
二、HMM解决的三类问题-mahout示例
现在男主小明开始做任务了,我们用现成的工具mahout来示例
安装指南(仅介绍local版)
wget http://archive.apache.org/dist/mahout/0.9/mahout-distribution-0.9.tar.gz
cd mahout-distribution-0.9/
vim bin/mahout
修改
MAHOUT_JAVA_HOME=/usr/lib/jvm/java-6-openjdk-amd64 (修改为你自己的java所在地址)
MAHOUT_LOCAL=true
任务一:学习(本例中根据女主吃的食物序列,推断一个合适的HMM模型)
输入:观测状态序列——女主吃的食物序列,我们用数字表示对应的食物与心情
0:汉堡
1:西瓜
2:啤酒
0 :崩溃
1:开心
2: 正常
输出:生成一个合适的HMM模型
算法:BaumWelch
echo "0 1 2 2 2 1 1 0 0 2 1 2 1 1 1 1 2 2 2 0 0 0 0 0 0 2 2 2 0 0 0 0 0 0 1 1 1 1 2 2 2 2 2 0 2 1 2 0 2 1 2 1 1 0 0 0 1 0 1 0 2 1 2 1 2 1 2 1 1 0 0 2 2 0 2 1 1 0" > hmm-input
输入观测序列后,开始生成HMM模型
bin/mahout baumwelch -i hmm-input(观测序列文件) -o hmm-model(hmm模型文件) -nh 3(隐状态数) -no 3(观测状态数) -e .0001 -m 10
我们看结果
Initial probabilities: 初始隐状态向量pi
0 1 2
0.062295949769082204 0.22250521455286396 0.7151988356780538
Transition matrix:状态转移矩阵A:
0 1 2
0 0.3765444789556002 0.5583673988903969 0.06508812215400292
1 0.3759312048603327 0.2560959620304218 0.36797283310924545
2 0.5383787685979908 0.24752553248847228 0.21409569891353694
Emission matrix: 发射矩阵
0 1 2
0 0.4419117509334424 0.3106990713267408 0.2473891777398168
1 0.20948851558479514 0.2830936761513362 0.5074178082638686
2 0.34341499252552676 0.40310175949497634 0.2534832479794969
任务二:预测(根据上一个任务生成的HMM模型来预测女主后续会吃的东西)
输入:HMM模型
输出:预测后续的观测状态,或者计算给定规则状态序列的概率(这个我们在下一个场景中描述)
算法: ForwardBackward
bin/mahout hmmpredict -m hmm-model(hmm模型文件) -o hmm-predictions (预测结果文件)-l 10(预测多少个后续观测状态)
我们看结果
more hmm-predictions
2 2 0 0 1 2 1 2 2 1
预测女主后续会吃的东西依次为 :啤酒,啤酒,汉堡,汉堡,西瓜,啤酒,西瓜,啤酒,啤酒、西瓜
任务三:编码(根据女主吃的东西,判断女主当前的心情,这个也是男主最关心的任务,女孩的心思你别猜。。。)
输入:HMM模型,观测状态序列
输出:观测状态序列对应的隐藏状态序列
算法:viterbi
输入观测状态序列,本例中女主吃的食物
echo "2 2 0 0 1 2 1 2 2 1" > hmm-viterbi-input
判断观测状态序列对应的隐状态序列
bin/mahout viterbi -i hmm-viterbi-input -o hmm-viterbi-output -m hmm-model -l
我们看结果
more hmm-viterbi-output
2 1 2 0 0 1 2 0 1 2
可以看到女主
吃的东西 : 啤酒,啤酒,汉堡,汉堡,西瓜,啤酒,西瓜,啤酒,啤酒、西瓜
对应的心情: 正常,开心,正常,崩溃,崩溃,开心,正常,崩溃,开心,正常
三、安全上的应用—— jahmm示例
现在我们知道了什么是HMM以及HMM能做什么,最关键的时刻到了,现实场景的应用。我们先提出
需要解决的问题——HTTP异常请求的检测(弥补基于签名检测的不足)
解决方案猜想——HTTP请求内容实际是一系列字符串,而正常字符串出现的概率远大于异常字符串。我们可以靠概率来划分正常请求与异常请求。
有了这个前提,再结合HMM的学习功能与预测功能,学习功能能根据观测序列(HTTP请求内容)生成最适合的HMM模型,而预测功能能在HMM模型下能计算指定观测序列(HTTP请求内容)的概率 。我们得出下面这个
解决方案——两个阶段解决问题:
阶段一: 训练; 使用正常日志生成HMM模型,并设置正常请求的概率范围
阶段二: 检测; 使用待检测的请求来计算该请求在上一步所生成的HMM模型中的概率,不在正常请求概率范围内的则判定为异常请求。
原理:我们可以根据概率分布来区分正常与异常请求的原理是正常请求远远多于异常请求;正常请求是相似的,异常请求各异
接下来是代码实现,我们先了解一下jahmm——java实现的hmm算法库。我们从命令行使用来了解其功能,接受能力强的,可以直接看第3部分——实现 HTTP协议异常检测的关键部分
- jahmm 命令行
(1) 安装指南
http://code.google.com/p/jahmm/
git clone https://github.com/tanjiti/jahmm (不能翻墙的)
我们从命令行熟悉这款工具
(2) 选项说明
java -cp jahmm-0.6.1.jar be.ac.ulg.montefiore.run.jahmm.apps.cli.Cli -help
-opdf [integer|gaussian|gaussian_mixture|multi_gaussian] 指定观测序列的分布特征
Determines the observation distribution type associated with the
states of the HMM.-r <range> 如果观测序列为整数,指定范围 The 'range' option is mandatory when using distributions dealing with integers; <range> is a number such that the distribution is related to numbers in the range 0, 1, ..., range-1.
-ng <number> 如果观测序列的分布为多个高斯分布,指定高斯分布的个数
This option is mandatory when using gaussian mixture
distribution. It determines the number of gaussians.
-d <dimension> 如果观测序列的分布为多维度向量的高斯分布,指定向量纬度
This option is mandatory when using multi-variate gaussian
distributions. It determines the dimension of the observation
vectors.
-n <nb_states> 指定隐状态数
The number of states of the HMM.
-i <input_file> 指定输入
An HMM input file. Default is standard input.
-o <output_file> 指定输出
An HMM output file. Default is standard output.
-os <output_file> 指定输出序列文件
A sequences output file.
Default is standard output.
-is <input_file> 指定输入序列文件
A sequences input file.
-ikl <input_file> 指定使用 Kullback-Leibler 算法计算HMM距离的另一个HMM模型
An HMM input file with respect to which a Kullback-Leibler distance can be computed.-ni <nb> 指定BaumWelch算法迭代次数 The number of iterations performed by the Baum-Welch algorithm. Default is 10.All input (resp. output) file names can be replaced by '-' to mean usingstandard input (resp. output).
1)生成hmm模型
java -cp jahmm-0.6.1.jar be.ac.ulg.montefiore.run.jahmm.apps.cli.Cli create -opdf integer -r 3 -n 3 -o initial.hmm
生成一个
隐藏状态数N=3
观测状态数M= 3
-opdf 参数:观测序列的类型
-opdf integer -r 10 观测状态序列为0,1,2,...,9表示
-opdf gaussian_mixture -ng 3 观测状态序列的分布为3个高斯分布
-opdf multi_gaussian -d 3 观测状态序列的元素为3*3矩阵
2)打印这个hmm模型
java -cp jahmm-0.6.1.jar be.ac.ulg.montefiore.run.jahmm.apps.cli.Cli print -i initial.hmm
也可以直接打开文本看
HMM with 3 state(s)
State 0
Pi: 0.333
Aij: 0.333 0.333 0.333
Opdf: Integer distribution --- 0.333 0.333 0.333
State 1
Pi: 0.333
Aij: 0.333 0.333 0.333
Opdf: Integer distribution --- 0.333 0.333 0.333
State 2
Pi: 0.333
Aij: 0.333 0.333 0.333
Opdf: Integer distribution --- 0.333 0.333 0.333
3)使用k-means算法生成HMM模型
输入:观测状态序列
输出:HMM模型
vim testInteger.seq
编辑
0; 1; 2; 2; 2; 1; 1; 0; 0; 2; 1; 2; 1; 1; 1; 1; 2; 2; 2; 0; 0; 0; 0; 0; 0; 2; 2; 2; 0; 0; 0; 0; 0; 0; 1; 1; 1; 1; 2; 2; 2; 2; 2; 0; 2; 1; 2; 0; 2; 1; 2; 1; 1; 0; 0; 0; 1; 0; 1; 0; 2; 1; 2; 1; 2; 1; 2; 1; 1; 0; 0; 2; 2; 0; 2; 1; 1; 0;
使用k-means算法生成HMM模型, 隐状态数为3,观测状态数为3
java -cp jahmm-0.6.1.jar be.ac.ulg.montefiore.run.jahmm.apps.cli.Cli learn-kmeans -opdf integer -r 3 -n 3 -is testInteger.seq -o test.hmm
查看模型
java -cp jahmm-0.6.1.jar be.ac.ulg.montefiore.run.jahmm.apps.cli.Cli print -i test.hmm
HMM with 3 state(s)
State 0
Pi: 1.0
Aij: 0.56 0.16 0.28
Opdf: Integer distribution --- 1 0 0
State 1
Pi: 0.0
Aij: 0.24 0.4 0.36
Opdf: Integer distribution --- 0 1 0
State 2
Pi: 0.0
Aij: 0.185 0.407 0.407
Opdf: Integer distribution --- 0 0 1
4)使用BaumWelch算法生成HMM模型
输入:观测状态序列
输出:HMM模型
使用BaumWelch算法生成HMM模型,隐状态数为3,观测状态数为3,算法迭代次数为10
java -cp jahmm-0.6.1.jar be.ac.ulg.montefiore.run.jahmm.apps.cli.Cli learn-bw -opdf integer -r 3 -is testInteger.seq -ni 10 -i initial.hmm -o test_bw.hmm
查看模型
java -cp jahmm-0.6.1.jar be.ac.ulg.montefiore.run.jahmm.apps.cli.Cli print -i test_bw.hmm HMM with 3 state(s)
State 0
Pi: 0.333
Aij: 0.333 0.333 0.333
Opdf: Integer distribution --- 0.333 0.321 0.346
State 1
Pi: 0.333
Aij: 0.333 0.333 0.333
Opdf: Integer distribution --- 0.333 0.321 0.346
State 2
Pi: 0.333
Aij: 0.333 0.333 0.333
Opdf: Integer distribution --- 0.333 0.321 0.346
5)按指定的HMM模型生成观测序列
输入:HMM模型
输出:观测序列
java -cp jahmm-0.6.1.jar be.ac.ulg.montefiore.run.jahmm.apps.cli.Cli generate -opdf integer -r 3 -i test.hmm -os kmeans.seq
6)计算两个HMM模型之间的距离
java -cp jahmm-0.6.1.jar be.ac.ulg.montefiore.run.jahmm.apps.cli.Cli distance-kl -opdf integer -r 3 -i test_bw.hmm -ikl initial.hmm
结果为
8.623062905801134E-4
(3) 文件格式说明
jahmm定义了两种文件格式
a. 观测序列文件
obser1; obser2; obser3;
观测序列之间用分号+空格隔开
多个观测序列用换行符号隔开
b. HMM模型文件
Hmm v1.0
NbStates 3
State
Pi 0.333
A 0.333 0.333 0.333
IntegerOPDF [0.33333333333333365 0.32051282051282076 0.3461538461538464 ]
State
Pi 0.333
A 0.333 0.333 0.333
IntegerOPDF [0.33333333333333365 0.32051282051282076 0.3461538461538464 ]
State
Pi 0.333
A 0.333 0.333 0.333
IntegerOPDF [0.33333333333333365 0.32051282051282076 0.3461538461538464 ]
- jahmm java 接口
在使用命令行熟悉了jahmm的功能后,我们先熟悉一下我们会用到的jahmm 关键类
(1)HMM类(最重要的类)
属性:
初始变量pi double pi[];
隐状态转移矩阵A double a[][];
发射矩阵B ArrayList<Opdf> opdfs;
构造函数
Hmm(int nbStates, OpdfFactory<? extends Opdf> opdfFactory) 初始向量,状态转移函数,发射矩阵 皆取平均值
Hmm(double[] pi, double[][] a, List<? extends Opdf> opdfs) 用指定初始向量,状态转移函数,发射矩阵生成HMM对象
Hmm(int nbStates) 初始向量,状态转移函数,发射矩阵 皆取空
getter
初始向量矩阵:double getPi(int stateNb)
发散矩阵:Opdf getOpdf(int stateNb)
状态转移矩阵:double getAij(int i, int j)
setter
初始向量矩阵:setPi(int stateNb, double value)
发散矩阵:setOpdf(int stateNb, Opdf opdf)
状态转移矩阵:setAij(int i, int j, double value)
方法:
获得隐状态数:int nbStates()
获得指定观测状态序列对应的最有可能的隐状态序列,使用viterbi算法 int[]mostLikelyStateSequence(List<? extends O> oseq)
获得指定观测状态序列的概率,使用ForwardBackward算法 doubleprobability(List<? extends O> oseq)
获得指定观测状态序列的概率(用自然对数来表示),使用ForwardBackward算法 double lnProbability(List<? extends O> oseq)
获得指定观测状态序列的P[oseq,sseq|H]概率 double probability(List<?extends O> oseq, int[] sseq)
获得HMM文本描述 toString()
获得HMM文本描述String toString(NumberFormat nf)
(2)learn 训练算法类
BaumWelchLearner
setter
设置迭代次数 setNbIterations(int nb) 默认为9次
getter
获得迭代次数 getNbIterations()
方法
训练 learn(Hmm initialHmm, List<? extends List<? extends O>>sequences)
BaumWelchScaledLearned (继承BaumWelchLearner,避免underflows)
(3)HMM代码示例
接下来的代码用来示例生成HMM模型,完成HMM解决的三个问题,以及HMM模型可视化
package helloHMM;
import java.util.ArrayList;
import java.io.IOException;
import be.ac.ulg.montefiore.run.jahmm.Hmm;
import be.ac.ulg.montefiore.run.jahmm.ObservationInteger;
import be.ac.ulg.montefiore.run.jahmm.OpdfIntegerFactory;
import be.ac.ulg.montefiore.run.jahmm.OpdfInteger;
import be.ac.ulg.montefiore.run.jahmm.learn.BaumWelchScaledLearner;
import be.ac.ulg.montefiore.run.jahmm.draw.GenericHmmDrawerDot;
public class test {
public static void main(String[] args){
/
//generate origin HMM model 生成初始的HMM模型,以小红与小明为例子
/
int nbHiddenStates = 3;
int nbObservedStates = 3;
Hmm<ObservationInteger> originHmm =
new Hmm<ObservationInteger>(nbHiddenStates,new OpdfIntegerFactory(nbObservedStates));
//set initial state vector -Pi
originHmm.setPi(0, 0.36);
originHmm.setPi(1, 0.51);
originHmm.setPi(2, 0.31);
//set transition matrix - Aij
originHmm.setAij(0, 0, 0.365);
originHmm.setAij(0, 1, 0.500);
originHmm.setAij(0, 2, 0.135);
originHmm.setAij(1, 0, 0.250);
originHmm.setAij(1, 1, 0.125);
originHmm.setAij(1, 2, 0.625);
originHmm.setAij(2, 0, 0.365);
originHmm.setAij(2, 1, 0.265);
originHmm.setAij(2, 2, 0.370);
//set emission matrix - Opdf
originHmm.setOpdf(0, new OpdfInteger(new double[] {0.1, 0.2, 0.7} ));
originHmm.setOpdf(1, new OpdfInteger(new double[] {0.5, 0.25, 0.25}));
originHmm.setOpdf(2, new OpdfInteger(new double[] {0.8, 0.1, 0.1}));
String originHmmStr = originHmm.toString();
System.out.print("Origin HMM *************** \n");
System.out.print(originHmmStr);
/
//task One: learn use BaumWelch Algorithm 学习,生成合适的HMM模型
/
ArrayList<ArrayList<ObservationInteger>> observSequence =
new ArrayList<ArrayList<ObservationInteger>>();
int [] array = {0,1,2,2,2,1,1,0,0,2,1,2,1,1,1,1,2,2,2,0,0,0,0,0,0,2,2,2,0,0,0,0,0,0,1,1,1,1,2,2,2,2,2,0,2,1,2,0,2,1,2,1,1,0,0,0,1,0,1,0,2,1,2,1,2,1,2,1,1,0,0,2,2,0,2,1,1,0};
ArrayList<ObservationInteger> OneSequence = new ArrayList<ObservationInteger>();
for(int i = 0; i < array.length; i++)
OneSequence.add(new ObservationInteger(array[i]));
observSequence.add(OneSequence);
BaumWelchScaledLearner bw = new BaumWelchScaledLearner();
bw.setNbIterations(10);
Hmm<ObservationInteger> learnedHmm_bw = bw.learn(originHmm, observSequence);
String learnedHmmStr_bw = learnedHmm_bw.toString();
System.out.print("\nTask 1:Learned HMM use BaumWelch *************** \n");
System.out.print(learnedHmmStr_bw);
//task two: get the sequence the probability 评估,获得指定观测序列的概率
int [] array_seq = {1, 2, 0, 0, 0, 0, 1, 2, 0};
ArrayList<ObservationInteger> Sequence_to = new ArrayList<ObservationInteger>();
for(int i = 0; i < array_seq.length; i++)
Sequence_to.add(new ObservationInteger(array_seq[i]));
//HMM's Probability use ForwardBackward Algorithm
double seq_prob = learnedHmm_bw.probability(Sequence_to);
System.out.printf("\nTask 2: %s 's probability is %f \n", Sequence_to.toString(), seq_prob);
//task three: get the hidden states sequence of the observer states sequence解码,获得指定观测序列对应的最有可能的隐藏序列
//
int [] array_seq_2 = {2, 2, 0, 0, 1, 2, 1, 2, 2, 1};
ArrayList<ObservationInteger> Sequence_three = new ArrayList<ObservationInteger>();
for(int i = 0; i < array_seq_2.length; i++)
Sequence_three.add(new ObservationInteger(array_seq_2[i]));
//use the Viterbi Algorithm
int [] hidden_states_seq = learnedHmm_bw.mostLikelyStateSequence(Sequence_three);
ArrayList<ObservationInteger> Sequence_hidden = new ArrayList<ObservationInteger>();
for(int i=0; i<hidden_states_seq.length; i++)
Sequence_hidden.add(new ObservationInteger(hidden_states_seq[i]));
System.out.printf("\nTask 3: observer hidden states sequence %s 's hidden states sequence is %s \n",
Sequence_three.toString(),Sequence_hidden.toString());
//
//HmmDrawerDot Hmm模型可视化
//
//you can install graphviz and use GVEdit to view the HMM model
GenericHmmDrawerDot hmmDrawer = new GenericHmmDrawerDot();
try{
hmmDrawer.write(originHmm, "hmm-origin.dot");
}
catch(IOException e){
System.err.print("Writing file triggered an exception: " + e);
}
}
}
注意:
jahmm BaumWelch的观测状态序列必须超过1个,否则就会抛出Observation sequence too short异常
3. 实现 HTTP协议异常检测的关键部分
整个过程由三部分组成
(1)日志解析
输入: 正常的访问日志(可以混有少量攻击日志)
可以按以下条件来去重筛选
响应码 2xx, 3xx
动态页面
参数名符合规范: 字符,数字,数组,排除参数名注入
输出:参数名值对 (对url重写需要另行考虑)
(2)参数值泛化处理
输入:参数值
输出:观测序列
转换规则:
序列 符号 参数值类型
0 U 若字符串为URI格式,标记为U
1 N 若字符为非ASCII码,标记为N,字符包括\x00-\x07以外
2 W 若字符为word类型,标记为W,字符包括
数字\x30-\x39、字母\x41-\x5A \x61-\x7A、下划线\x5F ,一共63个字符
3 S 若字符为空格类型,标记为S,字符包括\x00NUL \x09\t \x0A\n \x0B\v \x0C\f \x0D\r \x20space ,一共7个字符
4 V 若字符为控制字符类型,标记为V,字符包括\x01-\x08、\x0E-\x1F、\x7F,一共27个字符
5 保留字符 ! ” # $ % & ‘ ( ) * + , – . / : ;< = > ? @ [ \ ] ^ ` { | } ~,一共31个字符
(3) 训练阶段
指定隐状态数hidden与观测状态数初始化一个HMM对象
Hmm hmm = new Hmm(hidden, new OpdfIntegerFactory (observed));
使用上一步生成的观测序列,调用BaumWelch算法进行学习,生成合适的HMM的对象
BaumWelchScaledLearner bw = new BaumWelchScaledLearner();
bw.setNbIterations(20000);
Hmm learnedHmm_bw = bw.learn(originHmm, observSequence);
获得每个观测序列的概率,指定合法值的概率的范围或阈值
double seq_i_prob = learnedHmm_bw.probability(Sequence_i);
我们可以将训练结果以key:value对的方式存储在数据库中,例如redis。
key为 /path?paramName
value为 val对应的HMM训练对象learnedHmm_bw、观测状态序列、概率阈值的序列化值
(4)检测阶段
将待检测日志,通过上面介绍的日志解析与参数值泛化处理生成观测序列,然后计算出该观测序列在第二步学习的HMM对象中的概率值
double seq_to_prob = learnedHmm_bw.probability(Sequence_to);
判断概率是否在合法范围内
最简单的方法是将阈值设置为所有观测序列中的最小值,
我们还可以按概率的统计分布特征(中位数,算术平均,方差)来选取范围
当然这些都需要根据实际情况进行参数调优
好了,关键步骤讲完了。在实际应用中,特别是日志量过大的情况下,我们需要做很多异常和优化处理,例如
(1)异常处理
测状态数不能超过36,否则抛出异常
学习时间花费不能超过XXX,否则抛出异常
(2)观测状态序列及序列集合的优化
训练阶段:观测序列数量过大的情况下,会影响训练时间与结果,所以需要做reduce处理,例如观测序列包含的字符相同,则忽略顺序认为是同一个序列
检测阶段:待检测观测序列的取样处理,例如相同观测状态的合并
(3)隐状态数的选择
最简单的是选取所有观测状态序列中去重后的观测状态数的平均值
- 大数据处理
当日志量很大的情况下,我们需要引入数据的并行处理。于是hadoop上场了,我们将日志存储在HFDS里,采用Hadoop提供的MapReduce计算机制,来完成日志异常训练与检测,调用示例如下
hadoop jar HMM_Abnormal.jar HmmAbnormal.train /data/in/ /data/out/model/
hadoop jar HMM_Abnormal.jar HmmAbnormal.check /data/in/ /data/out/model/ /data/out/result/
- 总结
HMM异常检测同朴素贝叶斯分类器也是白名单(异常)的思路,在第一学习阶段通过对正常的请求的学习,得出正常请求的模式,在第二检测阶段将不符合正常模式则判定为异常。
实时的HMM可以用于WAF或IPS系统实时检测,离线的HMM可以用于WAF或IPS误报漏报运维。
我们知道白名单(异常)最大的优点是弥补黑名单签名知识库更新滞后的漏报情况,但其在模型训练数据污染严重(攻击日志大量混入到学习日志中)、模型训练不充分和模型训练不到(有些有漏洞的攻击请求不会出现在正常请求中)的情况下会丧失这一优点。因此需要其他模型来弥补缺陷,使用数据分析来解决问题,就是要多个模型(算法)综合使用,这是个有挑战的路线,与君共勉。
参考














 425
425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









