







 本文详细介绍了TF-IDF算法在文本处理中的应用,包括基本概念、计算公式以及如何使用gensim库和自定义实现来计算TF-IDF。通过实例展示了如何从文本中提取关键词,强调了TF-IDF在衡量单词重要性中的作用。
本文详细介绍了TF-IDF算法在文本处理中的应用,包括基本概念、计算公式以及如何使用gensim库和自定义实现来计算TF-IDF。通过实例展示了如何从文本中提取关键词,强调了TF-IDF在衡量单词重要性中的作用。
本文主要介绍了自然语言处理领域中文本表示的一个重要算法:TF-IDF算法。包括其基本概念,以及简单的代码实现。
文章目录
TF-IDF概述
什么是TF-IDF?
词频-逆文档频率(Term Frequency-Inverse Document Frequency,TF-IDF)是一种常用于文本处理的统计方法,可以评估一个单词在一份文档中的重要程度。简单来说就是可以用于文档关键词的提取。
TF-IDF的基本思想
看到下面这段文本,我们应该很容易就能看出“篮球”应该是一个关键词,但是我们如何通过算法的形式让计算机也能够辨别呢?
篮球,是以手为中心的身体对抗性体育运动,是奥运会核心比赛项目。
1891年12月21日,由美国马萨诸塞州斯普林菲尔德基督教青年会训练学校体育教师詹姆士·奈史密斯发明。1896年,篮球运动传入中国天津。1904年,圣路易斯奥运会上第1次进行了篮球表演赛。1936年,篮球在柏林奥运会中被列为正式比赛项目,中国也首次派出篮球队参加奥运会篮球项目。1992年,巴塞罗那奥运会开始,职业选手可以参加奥运会篮球比赛。
篮球的最高组织机构为国际篮球联合会,于1932年成立,总部设在瑞士日内瓦。中国最高组织机构为中国篮球协会,于1956年10月成立。
脑海中想到的第一个方法就是对单词出现的次数进行统计,也就是词频。如果一个单词在文中出现的频率很高,那我们是否可以认为这个单词就是文章的关键词呢?
其实不一定,词频很高的单词往往更有可能是一些没有意义的停用词(stopword),例如“我”,“的”,“了”等等。
与此同时,在文章中出现次数很少的单词也不一定是不重要的单词。
因此,TF-IDF的基本思想是:如果某个单词在一篇文章的出现的频率很高,同时在其他文章中很少出现,则认为该单词大概率是一个关键词。
词频(Term Frequency,TF)
词频统计的思路:单词w在文档d中出现的频率。
最简单的计算公式如下:
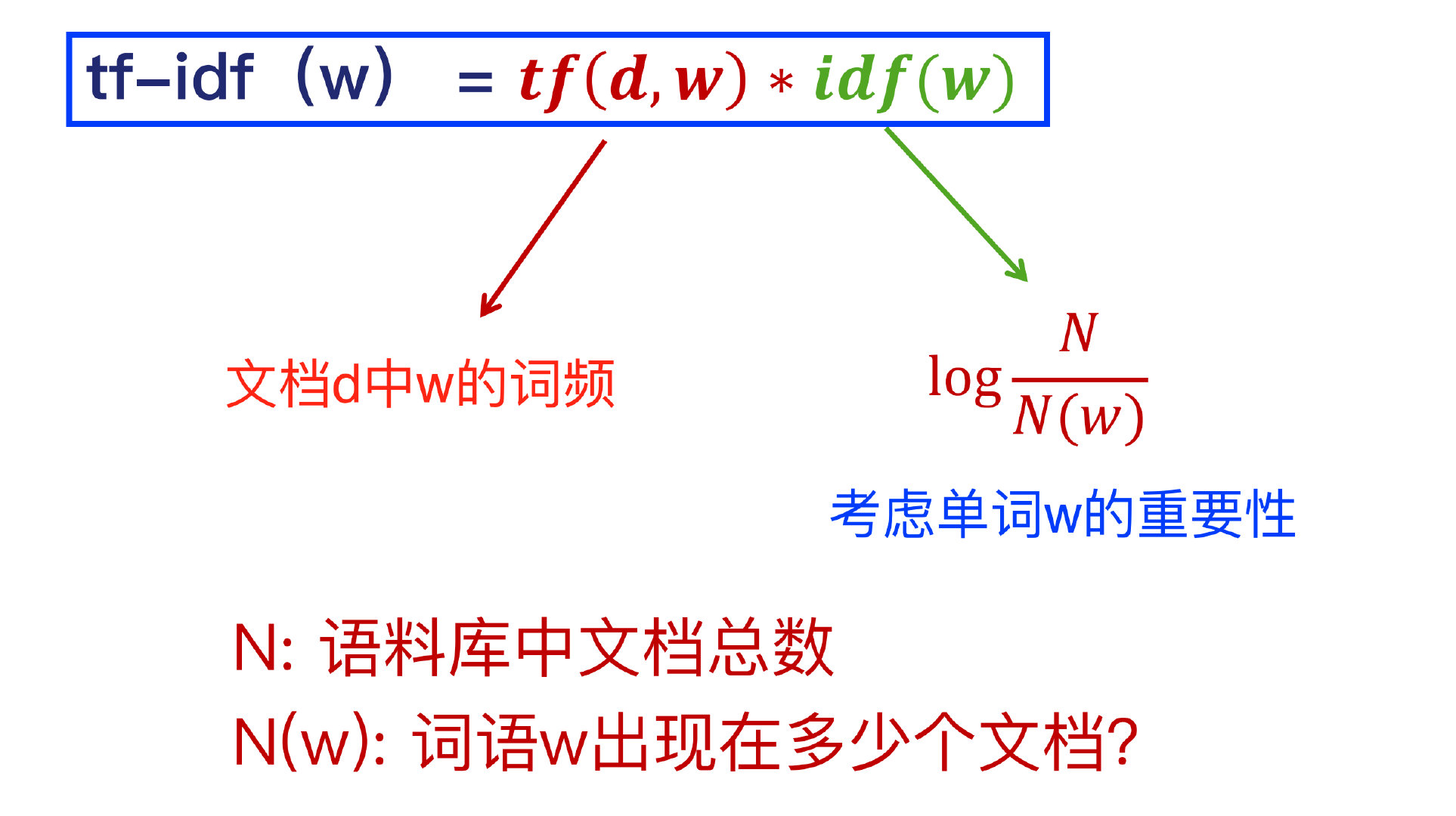
T F ( d , w ) = c o u n t ( d , w ) c o u n t ( d , ∗ ) TF(d, w) = \frac{count(d, w)}{count(d, *)} TF(d,w)=count(d,∗)count(d,w)
- count(d, w):单词w在文档d中出现的次数。
- count(d, *): 文档d的总词数。
逆文档频率(Inverse Document Frequency,IDF)
逆文档频率的思路:如果一个单词在很多的文档中出现,则意味着该单词的的重要性不高;反之则意味着该单词的重要性很高。主要是考虑了单词的重要性。
单词w的IDF计算方法如下:
I D F ( w ) = log N N ( w ) IDF(w) = \log {\frac{N}{N(w)}} IDF(w)=logN(w)N
- N: 语料库中的文档总数。
- N(w): 单词w出现在多少个文档中。
文档数量越大,同时单词出现在越少的文档中,IDF值就越大,则说明单词越重要。
上面IDF公式已经可以使用了,但是在一些特殊情况下可能会有一些小问题,比如某一个生僻词在我们的语料库中没有出现过,那么分母N(w)=0,IDF就没有意义了。
所以常用的IDF需要做平滑处理,使得没有在语料库中出现的单词也可以得到一个合适的IDF值。
参考TF-IDF概述,常见的IDF平滑公式之一为:
I D F ( w ) = log N + 1 N ( w ) + 1 + 1 IDF(w) = \log {\frac{N + 1}{N(w) + 1} + 1} IDF(w)=logN(w)+1N+1+1
TF-IDF计算公式
最终,单词w的TF-IDF计算公式如下:
T F − I D F ( w ) = T F ( d , w ) ∗ I D F ( w ) TF-IDF(w) = TF(d,w) * IDF(w) TF−IDF(w)=TF(d,w)∗IDF(w)
一个单词的TF-IDF值越大,意味着该单词越重要。
动手计算TF-IDF
下面通过3个简单的文档,演示一下如何计算TF-IDF。
句子1: 今天 上 NLP 课程
句子2: 今天 的 课程 有 意思
句子3: 数据 课程 也 有 意思
Step1 定义词典
词典的长度 |词典|=9 :
[今天,上,NLP,课程,的,有,意思,数据,也]
Step2 分别把每个句子用TF-IDF向量表示
句子1:
S 1 = ( 1 4 ∗ log
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









