








文章目录
关注微信公众号:K哥爬虫,QQ交流群:808574309,持续分享爬虫进阶、JS/安卓逆向等技术干货!
声明
本文章中所有内容仅供学习交流,抓包内容、敏感网址、数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除!
逆向目标
本次的逆向目标是WB的登录,虽然登录的加密参数没有太多,但是登录的流程稍微复杂一点,经历了很多次中转,细分下来大约要经过九次处理才能成功登录。
在登录过程中遇到的加密参数只有一个,即密码加密,加密后的密码在获取 token 的时候会用到,获取 token 是一个 POST 请求,其 Form Data 里的 sp 值就是加密后的密码,类似于:e23c5d62dbf9f8364005f331e487873c70d7ab0e8dd2057c3e66d1ae5d2837ef1dcf86......
登录流程
首先来理清一下登录流程,每一步特殊的参数进都行了说明,没有提及的参数表示是定值,直接复制即可。
大致流程如下:
-
预登陆
-
获取加密密码
-
获取 token
-
获取加密后的账号
-
发送验证码
-
校验验证码
-
访问 redirect url
-
访问 crossdomain2 url
-
通过 passport url 登录
1.预登陆
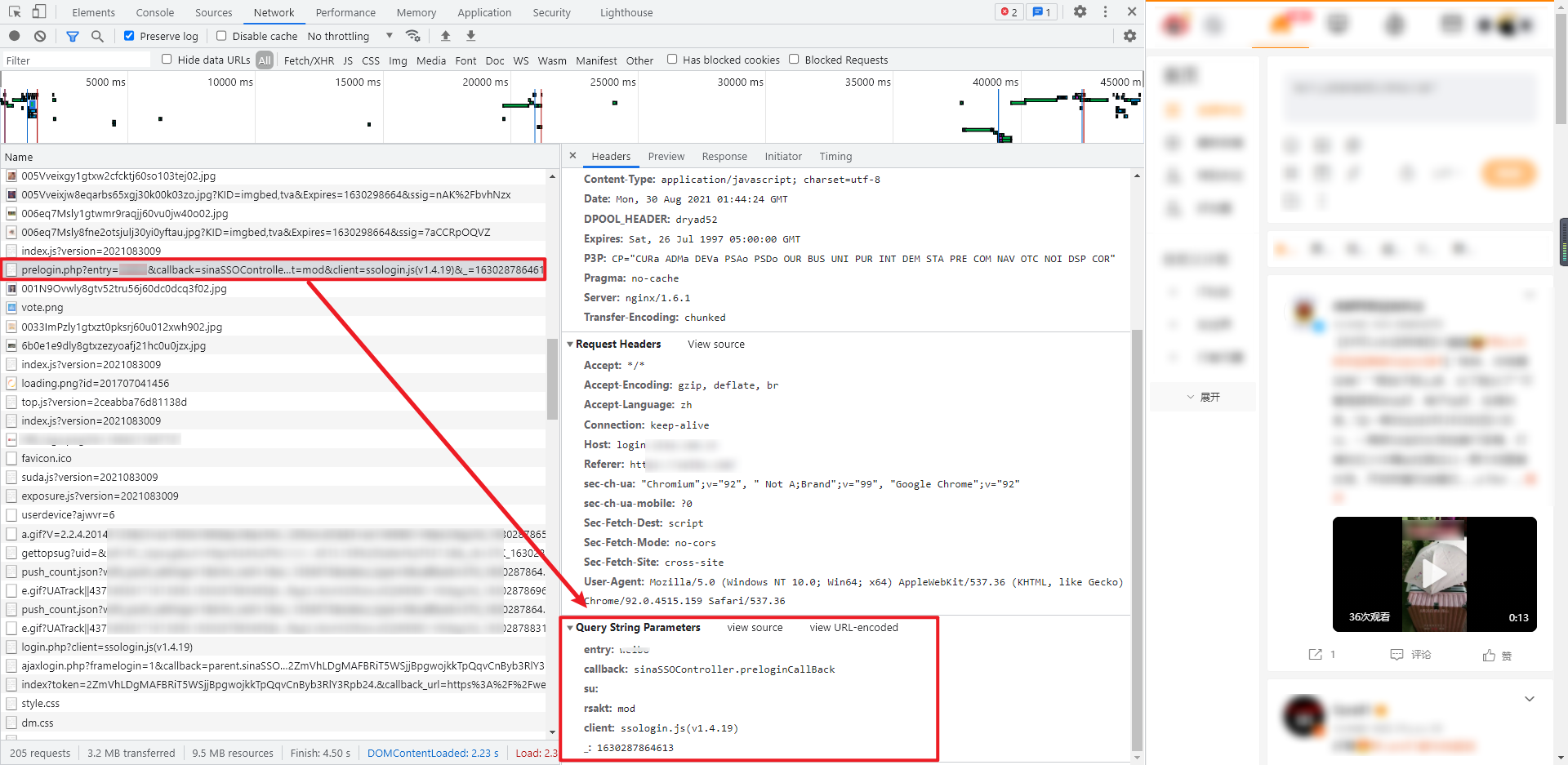
预登陆为 GET 请求,Query String Parameters 中主要包含两个比较重要的参数:su:用户名经过 base64 编码得到,_: 13 位时间戳,返回的数据包含一个 JSON,可用正则提取出来,JSON 里面包含 retcode,servertime,pcid,nonce,pubkey,rsakv, exectime 七个参数值,其中大多数值都是后面的请求当中要用到的,部分值是加密密码要用到的,返回数据数示例:
xxxxSSOController.preloginCallBack({
"retcode": 0,
"servertime": 1627461942,
"pcid": "gz-1cd535198c0efe850b96944c7945e8fd514b",
"nonce": "GWBOCL",
"pubkey": "EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D245......",
"rsakv": 1330428213,
"exectime": 16
})
2.获取加密后的密码
密码的加密使用的是 RSA 加密,可以通过 Python 或者 JS 来获取加密后的密码,JS 加密的逆向在后面拿出来单独分析。
3.获取 token
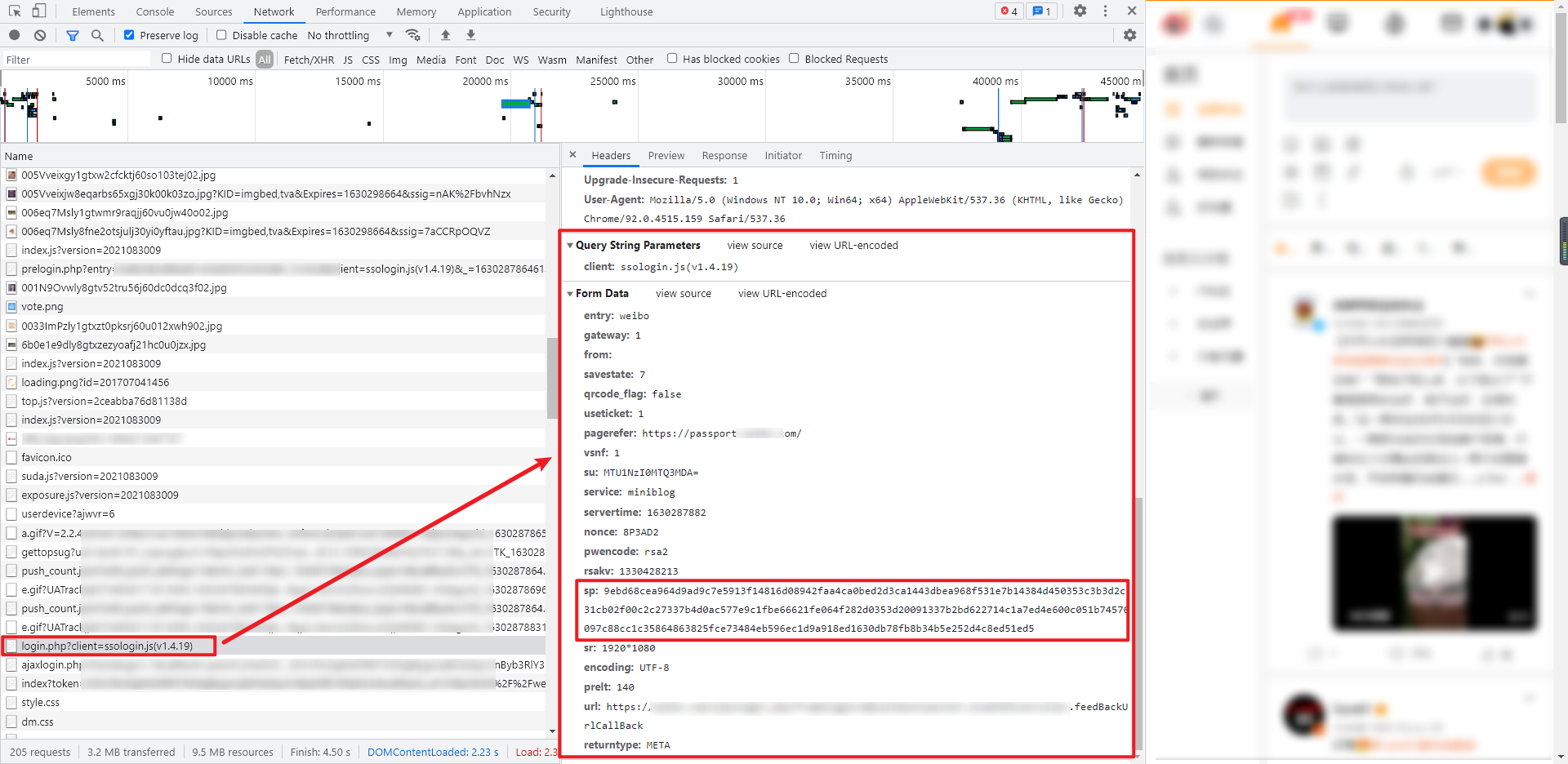
这个 token 值在后面的获取加密手机号、发送验证码、校验验证码等步骤中都会用到,获取 token 值为 POST 请求,Query String Parameters 的值是固定的:client: ssologin.js(v1.4.19),Form Data 的值相对来说比较多,但是除了加密的密码以外,其他参数其实都是可以在第1步预登陆返回的数据里找到,主要的参数如下:
su:用户名经过 base64 加密得到servertime:通过第1步预登陆返回的 JSON 里面获取nonce:通过第1步预登陆返回的 JSON 里面获取rsakv:通过第1步预登陆返回的 JSON 里面获取sp:加密后的密码prelt:随机值
返回数据为 HTML 源码,可以从里面提取 token 值,类似于:2NGFhARzFAFAIp_QwX70Npj8gw4lgj7RbCnByb3RlY3Rpb24.,如果返回的 token 不是这种,则说明账号或者密码错误。
4.获取加密后的账号
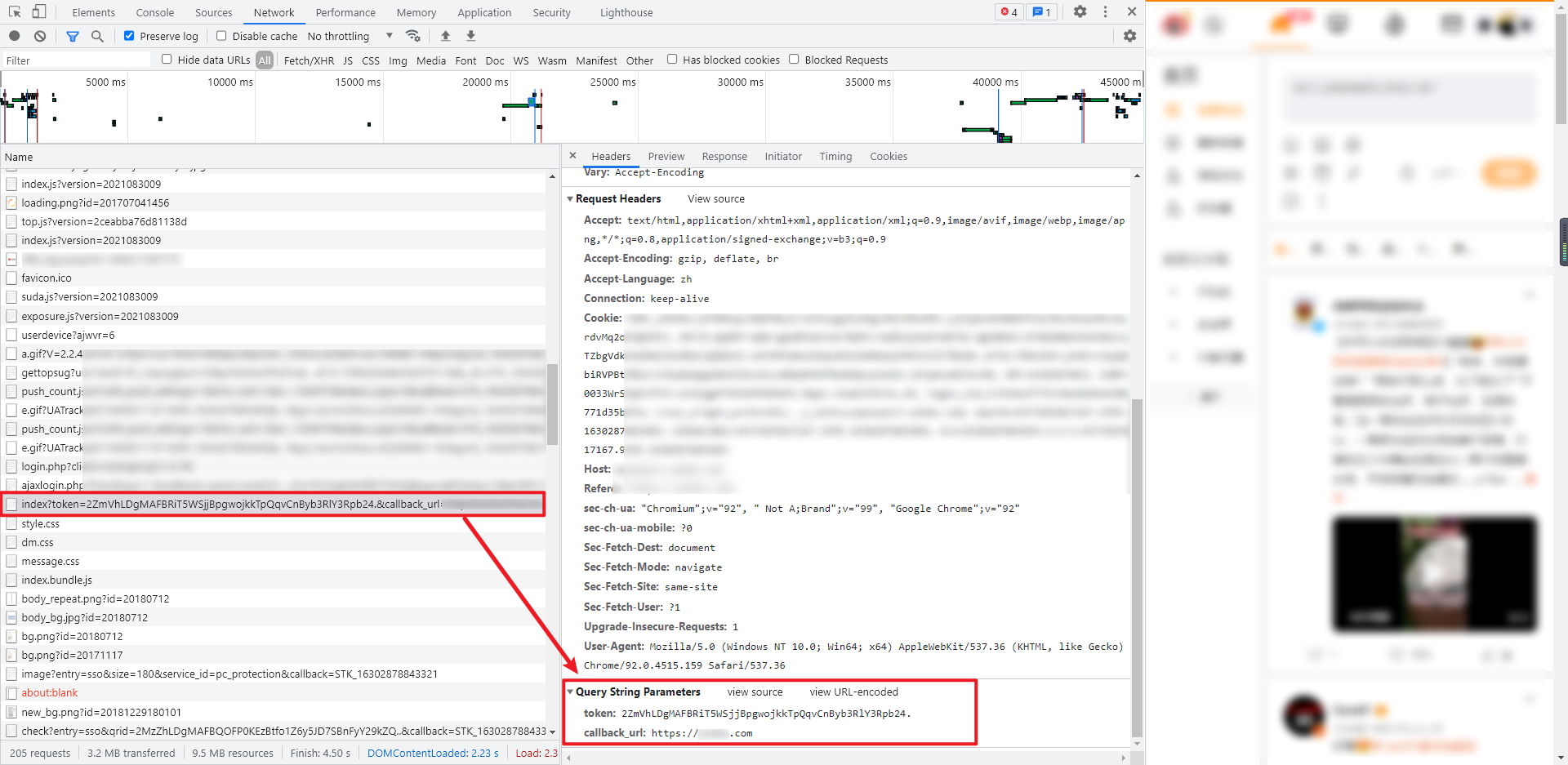
前面我们遇到的 su 是用户名经过 base64 加密得到,这里它对用户名进行了进一步的加密处理,加密后的用户名在发送验证码和校验验证码的时候会用到,GET 请求,Query String Parameters 的参数也比较简单,token 就是第3步获取的 token 值,callback_url 是网站的主页,返回数据是 HTML 源码,可以使用 xpath 语法://input[@name='encrypt_mobile']/@value 来提取加密后的账号,其值类似于:f2de0b5e333a,这里需要注意的是,即便是同一个账号,每次加密的结果也是不一样的。
5.发送验证码
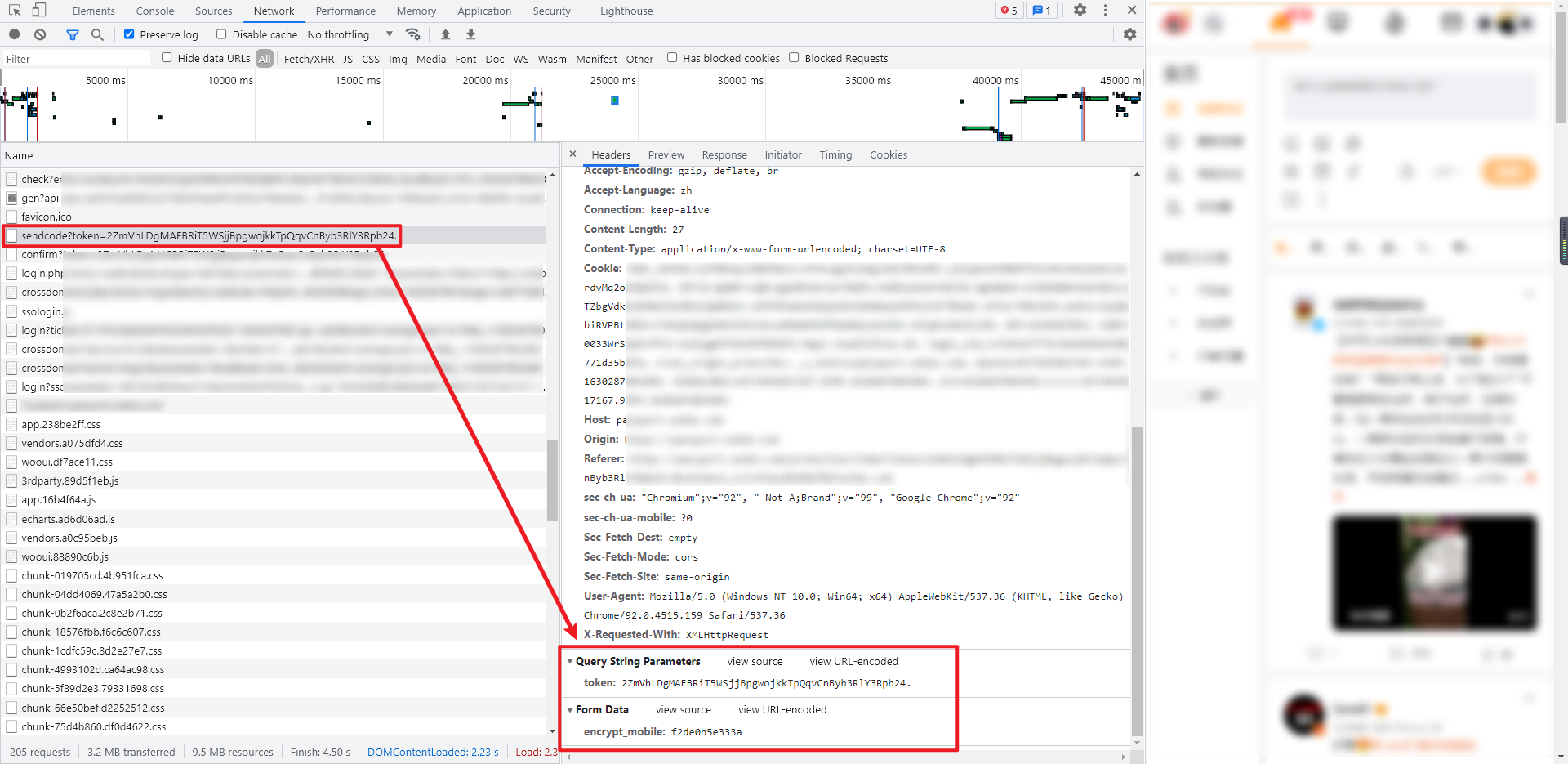
发送验证码是一个 POST 请求,其参数也比较简单,Query String Parameters 里的 token 是第3步获取的 token,Form Data 里的 encrypt_mobile 是第4步获取的加密后的账号,返回的数据是验证码发送的状态,例如:{'retcode': 20000000, 'msg': 'succ', 'data': []}。
6.校验验证码

校验验证码是一个 POST 请求,其参数也非常简单,Query String Parameters 里的 token 是第3步获取的 token,Form Data 里的 encrypt_mobile 是第4步获取的加密后的账号,code 是第5步收到的验证码,返回数据是一个 JSON,retcode 和 msg 代表校验的状态,redirect url 是校验步骤完成后接着要访问的页面,在下一步中要用到,返回的数据示例:
{
"retcode": 20000000,
"msg": "succ",
"data": {
"redirect_url": "https://login.xxxx.com.cn/sso/login.php?entry=xxxxx&returntype=META&crossdomain=1&cdult=3&alt=ALT-NTcxNjMyMTA2OA==-1630292617-yf-78B1DDE6833847576B0DC4B77A6C77C4-1&savestate=30&url=https://xxxxx.com"
}
}
7.访问 redirect url
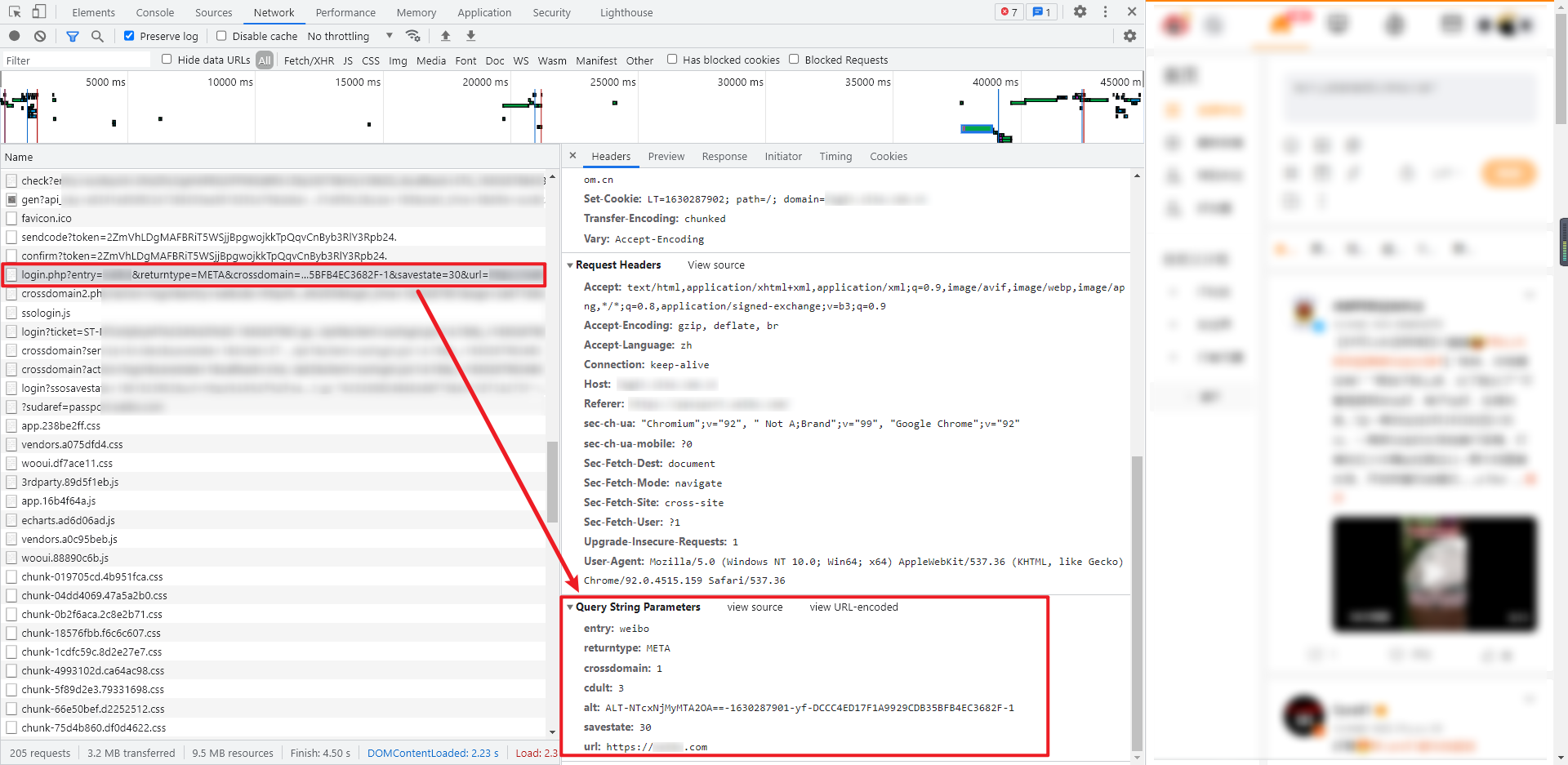
这一步的请求接口其实就是第6步返回的 redirect url,GET 请求,类似于:https://login.xxxx.com.cn/sso/login.php?entry=xxxxx&returntype=META......
返回的数据是 HTML 源码,我们要从中提取 crossdomain2 的 URL,提取的结果类似于:https://login.xxxx.com.cn/crossdomain2.php?action=login&entry=xxxxx......,同样的,这个 URL 也是接下来需要访问的页面。
8.访问 crossdomain2 url
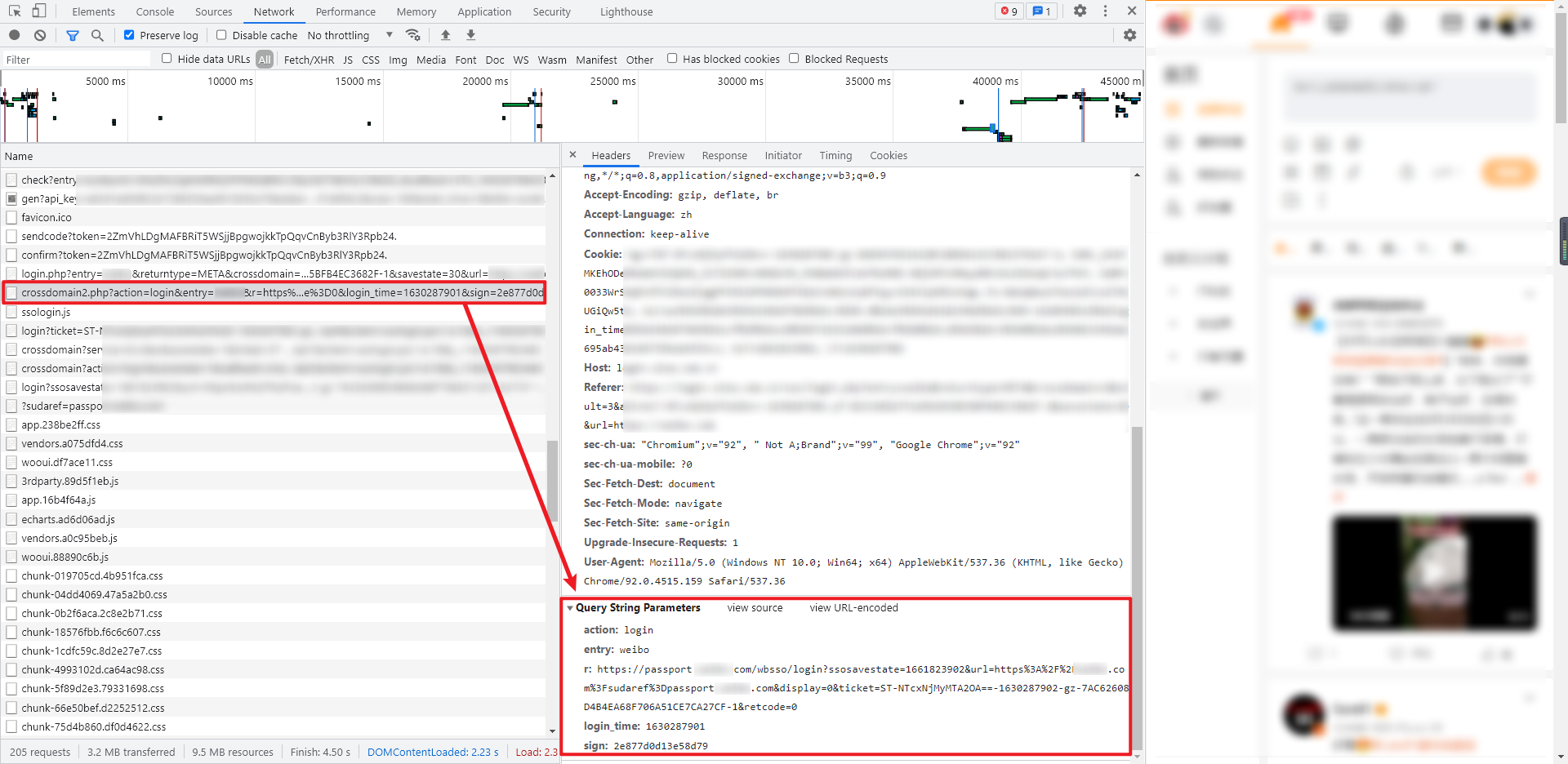
这一步的请求接口就是第7步提取的 crossdomain2 url,GET 请求,类似于:https://login.xxxx.com.cn/crossdomain2.php?action=login&entry=xxxxx......
返回的数据同样是 HTML 源码,我们要从中提取真正的登录的 URL,提取的结果类似于:https://passport.xxxxx.com/wbsso/login?ssosavestate=1661828618&url=https......,最后一步只需要访问这个真正的登录 URL 就能实现登录操作了。
9.通过 passport url 登录
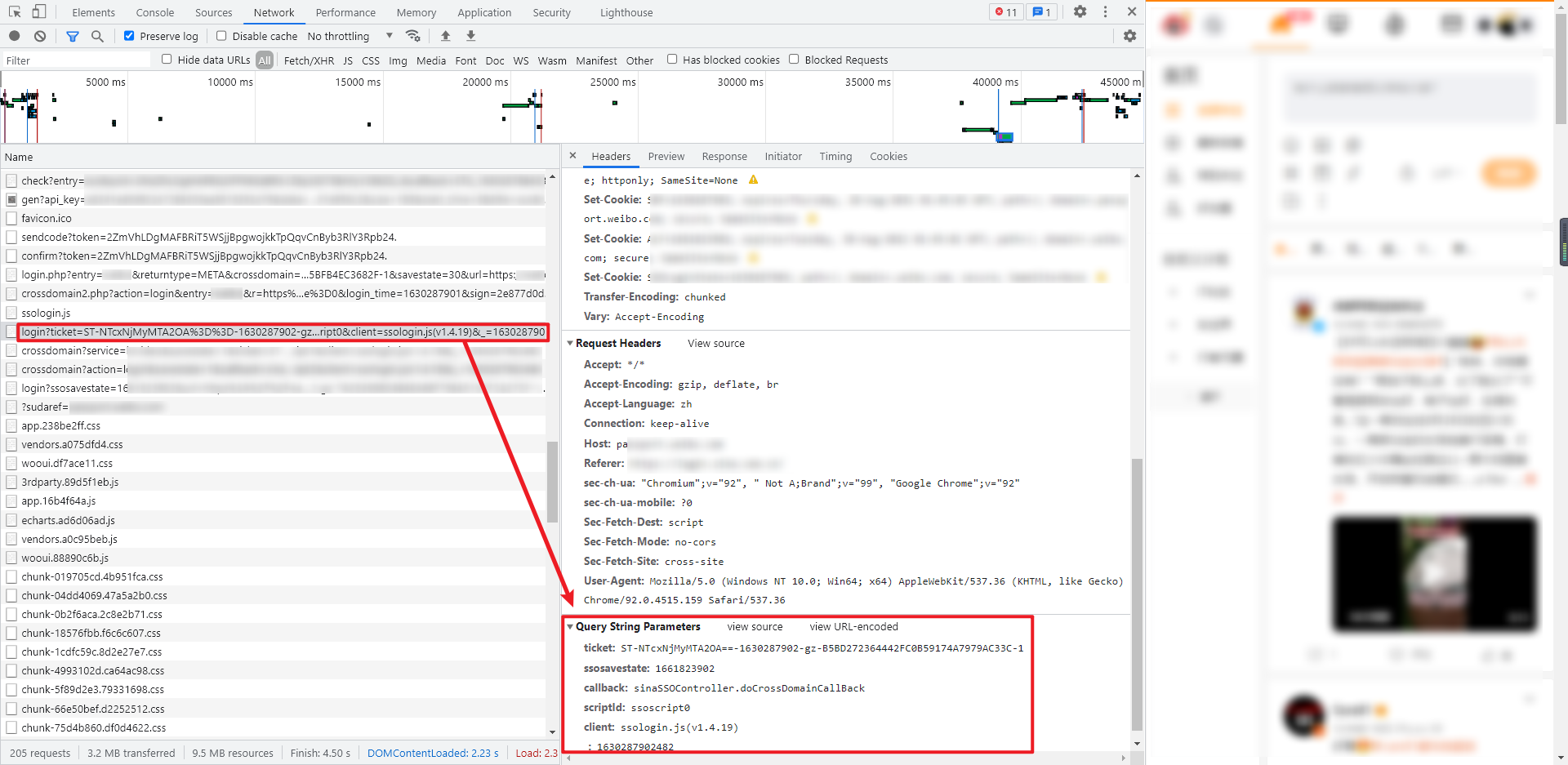
这是最后一步,也是真正的登录操作,GET 请求,请求接口就是第8步提取的 passport url,类似于:https://passport.xxxxx.com/wbsso/login?ssosavestate=1661828618&url=https......
返回的数据包含了登录结果、用户 ID 和用户名,类似于:
({"result":true,"userinfo":{"uniqueid":"5712321368","displayname":"tomb"}});
自此,WB的完整登录流程已完成,可以直接拿登录成功后的 cookies 进行其他操作了。
加密密码逆向
在登录流程中,第2步是获取加密后的密码,在登录的第3步获取 token 里,请求的 Query String Parameters 包含了一个加密参数 sp,这个就是加密后的密码,接下来我们对密码的加密进行逆向分析。
直接全局搜索 sp 关键字,发现有很多值,这里我们又用到了前面讲过的技巧,尝试搜索 sp=、sp: 或者 var sp 等来缩小范围,在本案例中,我们尝试搜索 sp=,可以看到在 index.js 里面只有一个值,埋下断点进行调试,可以看到 sp 其实就是 b 的值:
PS:搜索时要注意,不能在登录成功后的页面进行搜索,此时资源已刷新,重新加载了,加密的 JS 文件已经没有了,需要在登录界面输入错误的账号密码来抓包、搜索、断点。
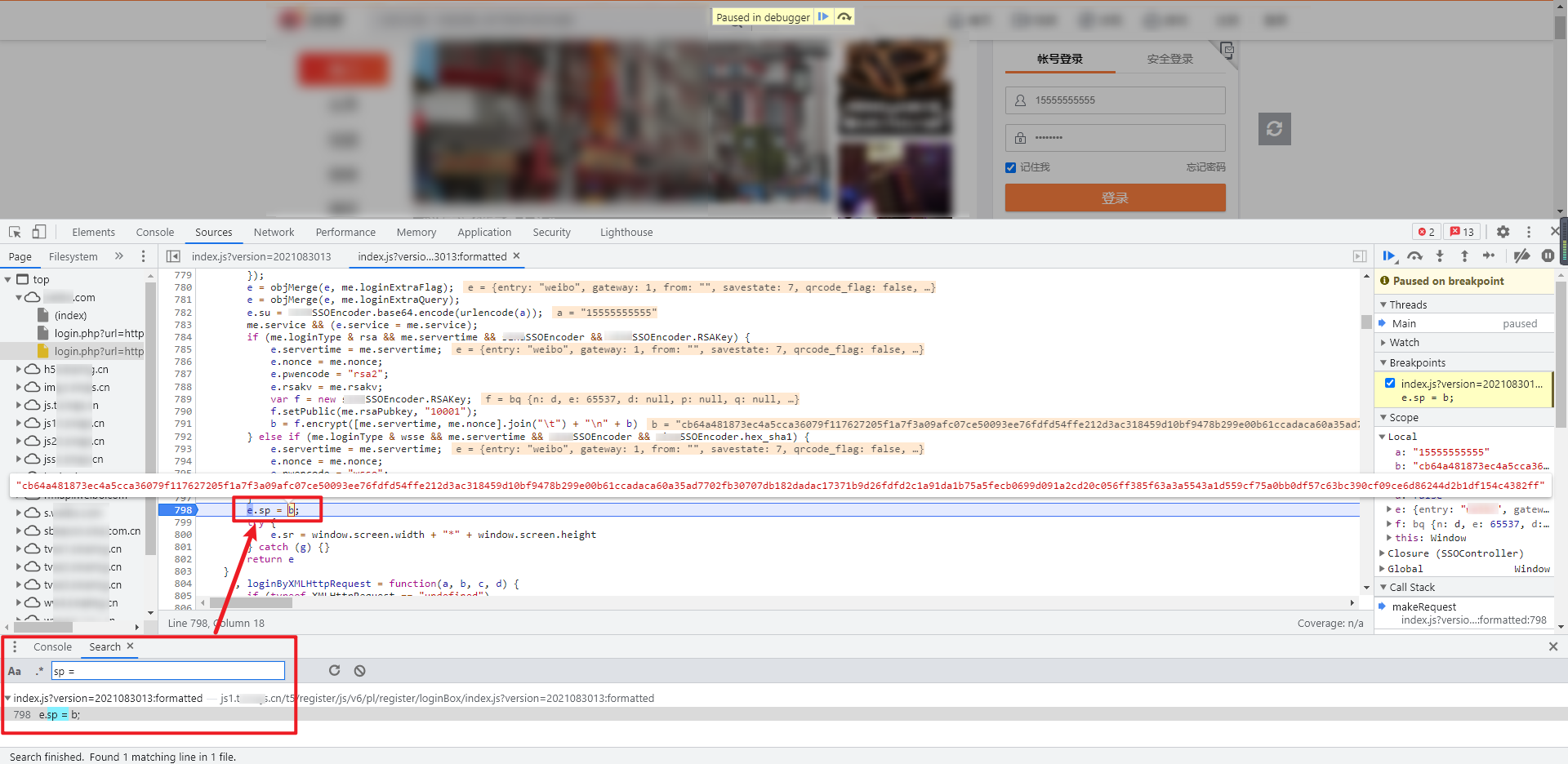
继续往上追踪这个 b 的值,关键代码有个 if-else 语句,分别埋下断点,经过调试可以看到 b 的值在 if 下面生成:
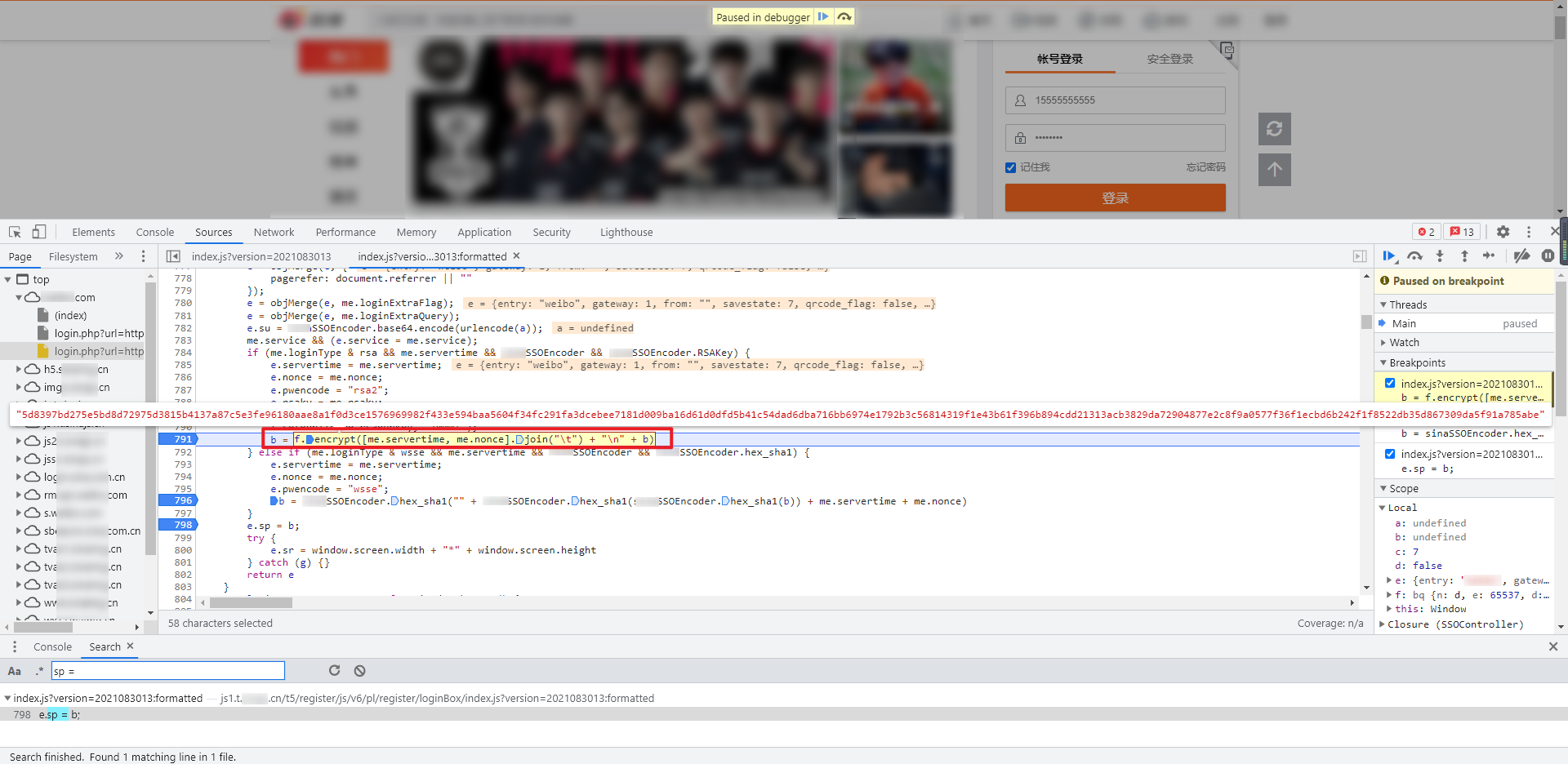
分析一下两行关键代码:
f.setPublic(me.rsaPubkey, "10001");
b = f.encrypt([me.servertime, me.nonce].join("\t") + "\n" + b)
me.rsaPubkey、me.servertime、me.nonce 都是第1步预登陆返回的数据。
把鼠标移到 f.setPublic 和 f.encrypt,可以看到分别是 br 和 bt 函数:
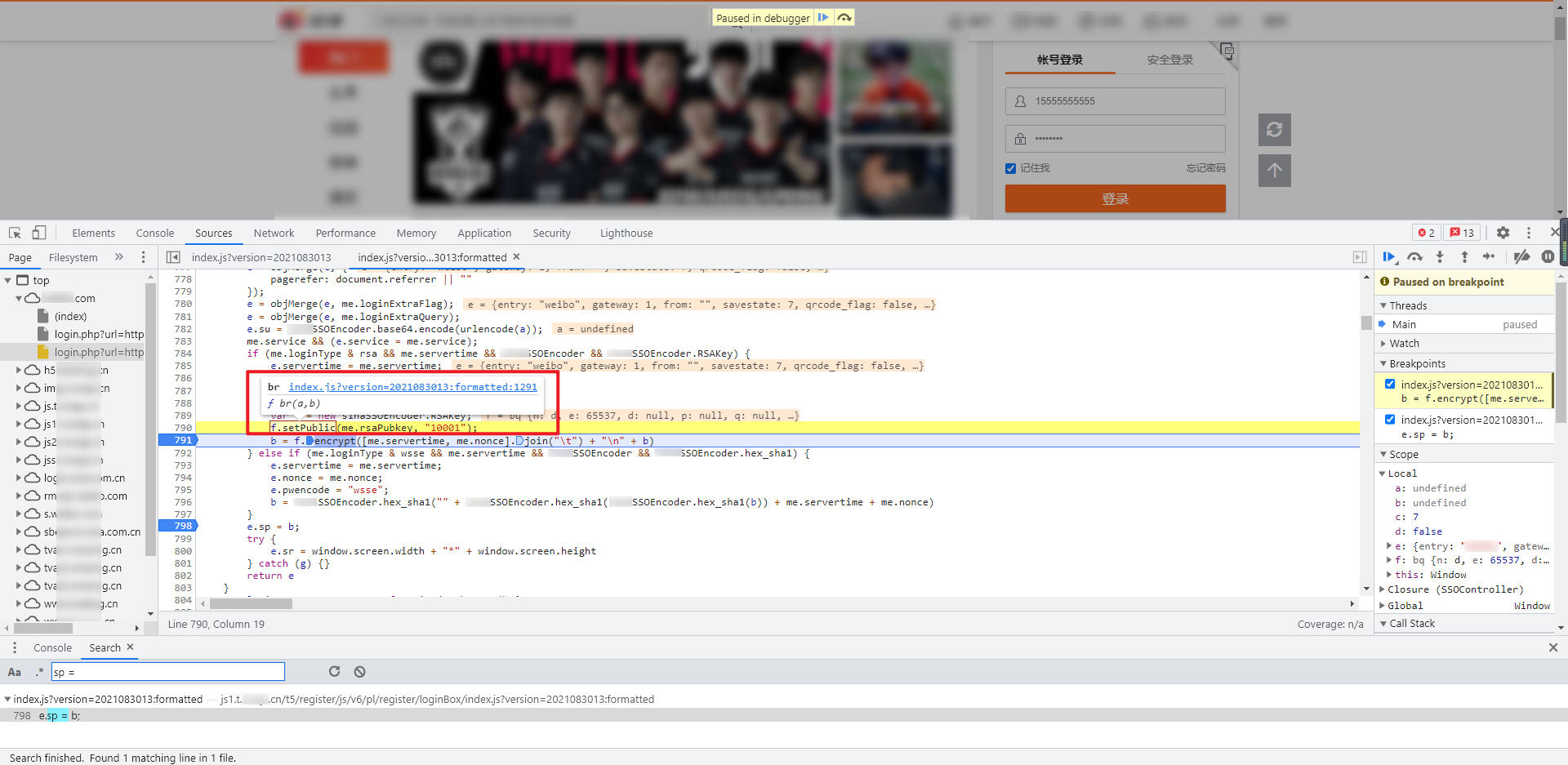
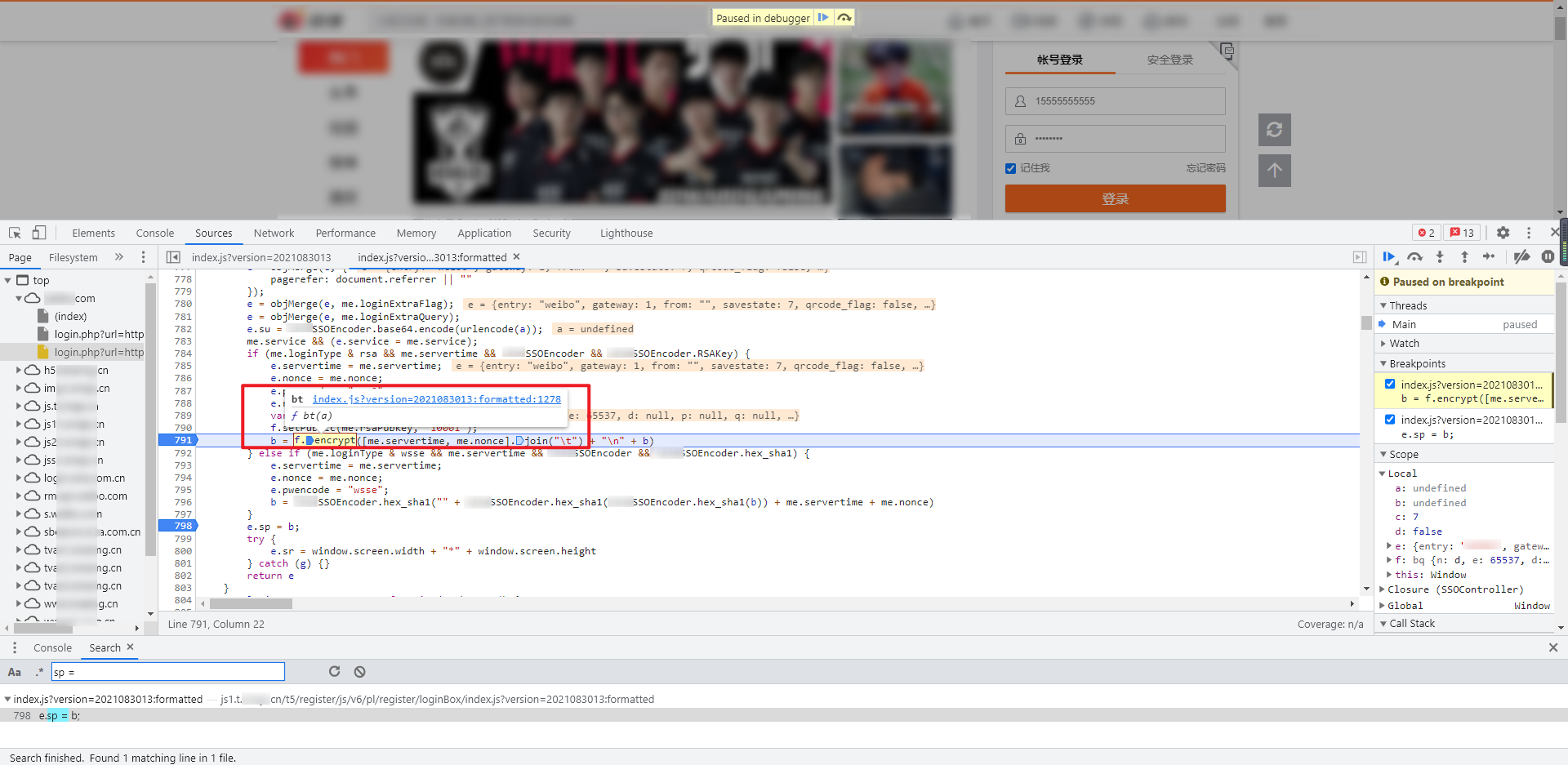
分别跟进这两个函数,可以看到都在一个匿名函数下面:
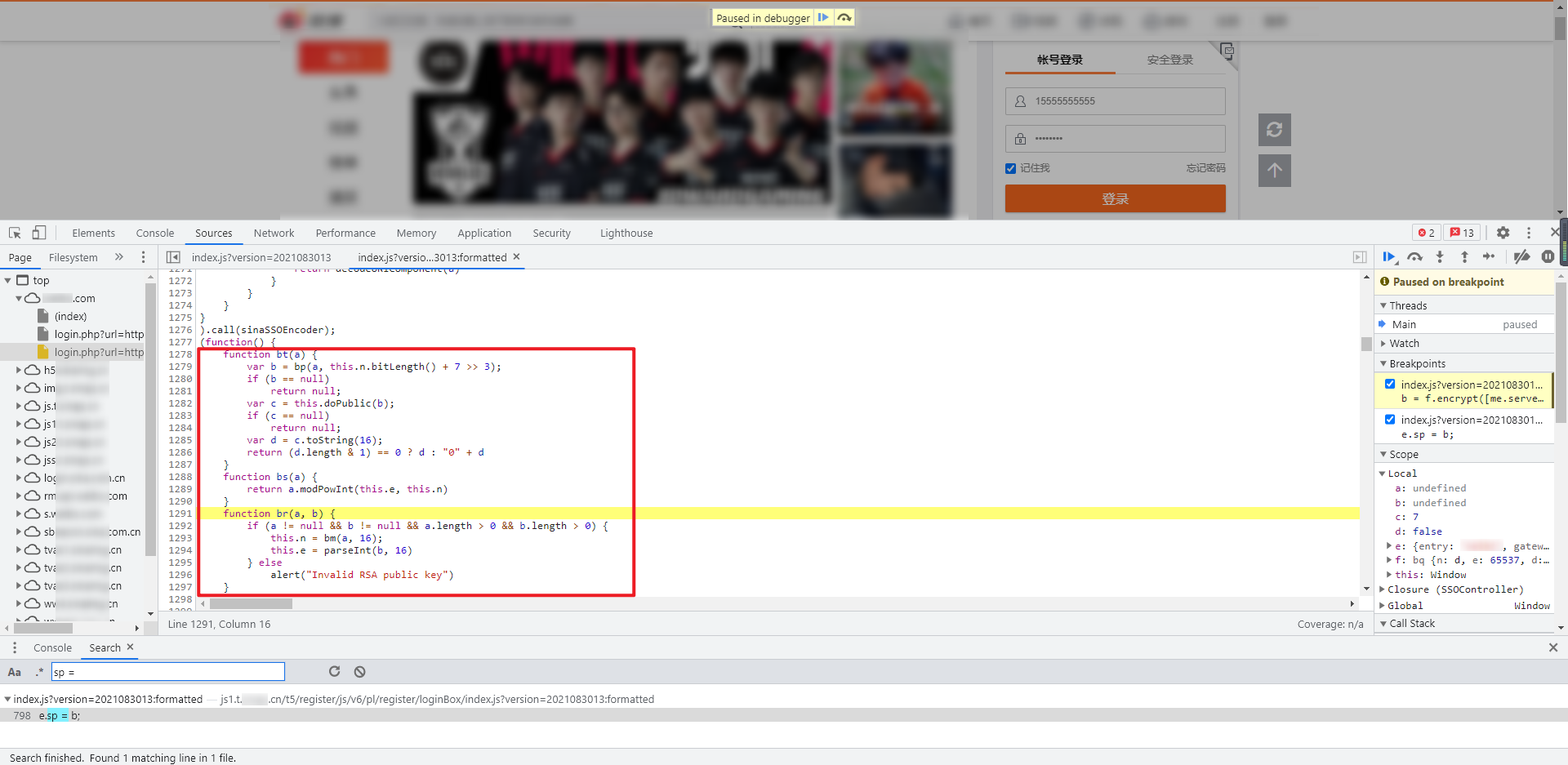
直接将整个匿名函数复制下来,去掉最外面的匿名函数,进行本地调试,调试过程中会提示 navigator 未定义,查看复制的源码,里面用到了 navigator.appName 和 navigator.appVersion,直接定义即可,或者置空都行。
navigator = {
appName: "Netscape",
appVersion: "5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
继续调试会发现在 var c = this.doPublic(b); 提示对象不支持此属性或方法,搜索 doPublic 发现有一句 bq.prototype.doPublic = bs;,这里直接将其改为 doPublic = bs; 即可。
分析整个 RSA 加密逻辑,其实也可以通过 Python 来实现,代码示例(pubkey 需要补全):
import rsa
import binascii
pre_parameter = {
"retcode": 0,
"servertime": 1627461942,
"pcid": "gz-1cd535198c0efe850b96944c7945e8fd514b",
"nonce": "GWBOCL",
"pubkey": "EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D245......",
"rsakv": 1330428213,
"exectime": 16
}
password = '12345678'
public_key = rsa.PublicKey(int(pre_parameter['pubkey'], 16), int('10001', 16))
text = '%s\t%s\n%s' % (pre_parameter['servertime'], pre_parameter['nonce'], password)
encrypted_str = rsa.encrypt(text.encode(), public_key)
encrypted_password = binascii.b2a_hex(encrypted_str).decode()
print(encrypted_password)
完整代码
GitHub 关注 K 哥爬虫,持续分享爬虫相关代码!欢迎 star !https://github.com/kgepachong/
**以下只演示部分关键代码,不能直接运行!**完整代码仓库地址:https://github.com/kgepachong/crawler/
关键 JS 加密代码架构
navigator = {
appName: "Netscape",
appVersion: "5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
function bt(a) {}
function bs(a) {}
function br(a, b) {}
// 此处省略 N 个函数
bl.prototype.nextBytes = bk;
doPublic = bs;
bq.prototype.setPublic = br;
bq.prototype.encrypt = bt;
this.RSAKey = bq
function getEncryptedPassword(me, b) {
br(me.pubkey, "10001");
b = bt([me.servertime, me.nonce].join("\t") + "\n" + b);
return b
}
// 测试样例
// var me = {
// "retcode": 0,
// "servertime": 1627283238,
// "pcid": "gz-a9243276722ed6d4671f21310e2665c92ba4",
// "nonce": "N0Y3SZ",
// "pubkey": "EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D245A87AC253062882729293E5506350508E7F9AA3BB77F4333231490F915F6D63C55FE2F08A49B353F444AD3993CACC02DB784ABBB8E42A9B1BBFFFB38BE18D78E87A0E41B9B8F73A928EE0CCEE1F6739884B9777E4FE9E88A1BBE495927AC4A799B3181D6442443",
// "rsakv": "1330428213",
// "exectime": 13
// }
// var b = '12312312312' // 密码
// console.log(getEncryptedPassword(me, b))
Python 登录关键代码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import re
import json
import time
import base64
import binascii
import rsa
import execjs
import requests
from lxml import etree
# 判断某些请求是否成功的标志
response_success_str = 'succ'
pre_login_url = '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
get_token_url = '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
protection_url = '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
send_code_url = '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
confirm_url = '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
headers = {
'Host': '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler',
'Referer': '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
session = requests.session()
def get_pre_parameter(username: str) -> dict:
su = base64.b64encode(username.encode())
time_now = str(int(time.time() * 1000))
params = {
'entry': '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler',
'callback': '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler',
'su': su,
'rsakt': 'mod',
'checkpin': 1,
'client': 'ssologin.js(v1.4.19)',
'_': time_now,
}
response = session.get(url=pre_login_url, params=params, headers=headers).text
parameter_dict = json.loads(re.findall(r'\((.*)\)', response)[0])
# print('1.【pre parameter】: %s' % parameter_dict)
return parameter_dict
def get_encrypted_password(pre_parameter: dict, password: str) -> str:
# 通过 JS 获取加密后的密码
# with open('encrypt.js', 'r', encoding='utf-8') as f:
# js = f.read()
# encrypted_password = execjs.compile(js).call('getEncryptedPassword', pre_parameter, password)
# # print('2.【encrypted password】: %s' % encrypted_password)
# return encrypted_password
# 通过 Python 的 rsa 模块和 binascii 模块获取加密后的密码
public_key = rsa.PublicKey(int(pre_parameter['pubkey'], 16), int('10001', 16))
text = '%s\t%s\n%s' % (pre_parameter['servertime'], pre_parameter['nonce'], password)
encrypted_str = rsa.encrypt(text.encode(), public_key)
encrypted_password = binascii.b2a_hex(encrypted_str).decode()
# print('2.【encrypted password】: %s' % encrypted_password)
return encrypted_password
def get_token(encrypted_password: str, pre_parameter: dict, username: str) -> str:
su = base64.b64encode(username.encode())
data = {
'entry': '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler',
'gateway': 1,
'from': '',
'savestate': 7,
'qrcode_flag': False,
'useticket': 1,
'pagerefer': '',
'vsnf': 1,
'su': su,
'service': 'miniblog',
'servertime': pre_parameter['servertime'],
'nonce': pre_parameter['nonce'],
'pwencode': 'rsa2',
'rsakv': pre_parameter['rsakv'],
'sp': encrypted_password,
'sr': '1920*1080',
'encoding': 'UTF-8',
'prelt': 38,
'url': '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler',
'returntype': 'META'
}
response = session.post(url=get_token_url, headers=headers, data=data)
# response.encoding = 'gbk'
ajax_login_url = re.findall(r'replace\("(.*)"\)', response.text)[0]
token = ajax_login_url.split('token%3D')[-1]
if 'weibo' not in token:
# print('3.【token】: %s' % token)
return token
else:
raise Exception('登录失败! 用户名或者密码错误!')
def get_encrypted_mobile(token: str) -> str:
params = {
'token': token,
'callback_url': '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
}
response = session.get(url=protection_url, params=params, headers=headers)
tree = etree.HTML(response.text)
encrypted_mobile = tree.xpath("//input[@name='encrypt_mobile']/@value")[0]
# print('4.【encrypted mobile】: %s' % encrypted_mobile)
return encrypted_mobile
def send_code(token: str, encrypt_mobile: str) -> str:
params = {'token': token}
data = {'encrypt_mobile': encrypt_mobile}
response = session.post(url=send_code_url, params=params, data=data, headers=headers).json()
if response['msg'] == response_success_str:
code = input('请输入验证码: ')
# print('5.【code】: %s' % code)
return code
else:
# print('5.【failed to send verification code】: %s' % response)
raise Exception('验证码发送失败: %s' % response)
def confirm_code(encrypted_mobile: str, code: str, token: str) -> str:
params = {'token': token}
data = {
'encrypt_mobile': encrypted_mobile,
'code': code
}
response = session.post(url=confirm_url, params=params, data=data, headers=headers).json()
if response['msg'] == response_success_str:
redirect_url = response['data']['redirect_url']
# print('6.【redirect url】: %s' % redirect_url)
return redirect_url
else:
# print('6.【验证码校验失败】: %s' % response)
raise Exception('验证码校验失败: %s' % response)
def get_cross_domain2_url(redirect_url: str) -> str:
response = session.get(url=redirect_url, headers=headers).text
cross_domain2_url = re.findall(r'replace\("(.*)"\)', response)[0]
# print('7.【cross domain2 url】: %s' % cross_domain2_url)
return cross_domain2_url
def get_passport_url(cross_domain2_url: str) -> str:
response = session.get(url=cross_domain2_url, headers=headers).text
passport_url_str = re.findall(r'setCrossDomainUrlList\((.*)\)', response)[0]
passport_url = json.loads(passport_url_str)['arrURL'][0]
# print('8.【passport url】: %s' % passport_url)
return passport_url
def login(passport_url: str) -> None:
response = session.get(url=passport_url, headers=headers).text
login_result = json.loads(response.replace('(', '').replace(');', ''))
if login_result['result']:
user_unique_id = login_result['userinfo']['uniqueid']
user_display_name = login_result['userinfo']['displayname']
print('登录成功!用户 ID:%s,用户名:%s' % (user_unique_id, user_display_name))
else:
raise Exception('登录失败:%s' % login_result)
def main():
username = input('请输入登录账号: ')
password = input('请输入登录密码: ')
# 1.预登陆,获取一个字典参数,包含后面要用的 servertime、nonce、pubkey、rsakv
pre_parameter = get_pre_parameter(username)
# 2.通过 JS 或者 Python 获取加密后的密码
encrypted_password = get_encrypted_password(pre_parameter, password)
# 3.获取 token
token = get_token(encrypted_password, pre_parameter, username)
# 4.通过 protection url 获取加密后的手机号
encrypted_mobile = get_encrypted_mobile(token)
# 5.发送手机验证码
code = send_code(token, encrypted_mobile)
# 6.校验验证码,校验成功则返回一个重定向的 URL
redirect_url = confirm_code(encrypted_mobile, code, token)
# 7.访问重定向的 URL,提取 crossdomain2 URL
cross_domain2_url = get_cross_domain2_url(redirect_url)
# 8.访问 crossdomain2 URL,提取 passport URL
passport_url = get_passport_url(cross_domain2_url)
# 9.访问 passport URL 进行登录操作
login(passport_url)
if __name__ == '__main__':
main()
















 5763
5763











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









