






一:MicroSoft
Reverse linklist in block
eg. block size is 3 and list is
1 2 3 4 5 6 7 8
Output: 3 2 1 6 5 4 8 7
LNK_NODE* ReverseByBlock(LNK_NODE* pHead ,int nBlockSize);
代码如下:
#include<stdio.h>
#include<malloc.h>
typedef struct LinkNode
{
int data;
struct LinkNode *next;
} LNode, *pNode;
pNode Create(int n);
void ChangeList(pNode head, int Block);
void Print(pNode head);
void Delete(pNode head);
int main()
{
int n, Block;
pNode head;
scanf("%d %d", &n, &Block);
head = Create(n);
Print(head);
ChangeList(head, Block);
Print(head);
Delete(head);
return 0;
}
pNode Create(int n)
{
pNode p1, p2, head;
int temp = n;
head = p2 = (pNode)malloc(sizeof(LNode));
if(head == NULL)
return NULL;
while(temp)
{
p1 = (pNode)malloc(sizeof(LNode));
if(p1 == NULL)
return NULL;
scanf("%d", &p1->data);
p2->next = p1;
p2 = p1;
temp--;
}
p2->next = NULL;
return head;
}
void ChangeList(pNode head, int Block)
{
int count = Block;
pNode first , second;
first = head->next;
if(first != NULL)
second = first->next;
else
return;
while(second != NULL)
{
while(--count && second != NULL)
{
first->next = second->next;
second->next = head->next;
head->next = second;
second = first->next;
}
if(second == NULL && count > 0)
return;
count = Block;
head = first;
if(first->next == NULL || first->next->next == NULL)
return;
first = head->next;
second = first->next;
}
}
void Print(pNode head)
{
pNode temp;
temp = head->next;
while(temp != NULL)
{
printf("%d ", temp->data);
temp = temp->next;
}
printf("\n");
}
void Delete(pNode head)
{
pNode temp;
temp = head;
while(temp != NULL)
{
temp = head->next;
free(head);
head = temp;
}
}
最近在做网站测试时,遇到了需要在输入框输入 3000 字的测试用例。联想到平时聊天时经常复制粘贴一堆笑脸刷屏讨 MM 欢心的行为,不由想到了一个有趣的问题:为了输入一定数量的字符,最少需要按多少个键?
大家最常用的策略或许是, 先输一些字符,然后全选复制,粘贴到一定规模后,再全选复制,粘贴到一个新的数量级,如此反复。注意到进入全选状态(并且复制后),第一次粘贴将会覆盖掉选中的部分,第二次粘贴才会增加原来的文本长度。当然,全选复制后按一次向右键也可以消除选中状态,不过却并没有节省按键次数。因此我们规定,在输入字符时只有四种原子操作:
1. 按一个按键,输入一个字符
2. 按 Ctrl + A ,全选
3. 按 Ctrl + C ,复制
4. 按 Ctrl + V ,粘贴
排除明显不划算的行为,真正的决策其实只有两种:
1. 按一次按键,输入一个字符
2. 按 k + 2 次按键,将现有内容复制成 k 份。
这样一来,我们就有了一个清晰的递推思路。设 f(n) 表示输入 n 个字符所需要的最少按键次数,则 f(n) 将会在 f(n-1) + 1 和 f(n/k) + k + 2 中取一个最小值(其中 k 取遍 n 的所有约数)。
Mathematica 牛 B 就牛 B 在,这样的动态规划程序只需要一行便能写完:
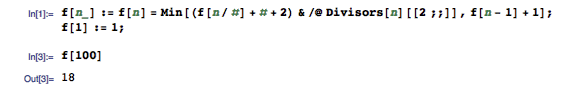
可见,输入 100 个字符需要 18 次按键。具体方法是,用 5 次按键输入 5 个字符,再用 7 次按键把它变成 25 个字符,再用 6 次按键把它变成 100 个字符。
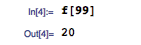
有趣的是,这个函数并不是单调的。输入 99 个字符需要的按键次数比输入 100 个字符需要的按键次数更多一些,事实上这最少要花费 20 次按键。方法是,先用 5 次按键输入 5 个字符,4 次按键把它变成 10 个字符,单独按一次键添加一个字符, 5 次按键把字符数复制粘贴到 33 ,再来 5 次按键把字符数复制粘贴到 99 。
那么, 20 次按键最多可以输入多少个字符呢?为了解决这个问题,我们可以给出另外一个递推式。令 g(n) 为 n 次按键最多可以输入的字符个数。对于每一个 n ,考虑两种转移决策:要么在 n - 1 次按键能够达到的最大字符数基础上加 1 ,要么把 n - k 次按键能够达到的字符数复制成 k - 2 份。也就是说, g(n) 就等于 g(n-1) + 1 和 g(n-k) * (k-2) 的最大值,其中 k 可以从 3 取到 n - 1。我们还是用一句话写下这个转移方程式:

可以看到, 20 次按键足以输入 150 个字符(方案是 6 → 30 → 150 ), 30 次按键足以输入 1600 个字符(方案是 5 → 25 → 100 → 400 → 1600 )。这样看上去,我们好像有了快速刷屏的指导思想:粘贴到原来的 4 倍长或者 5 倍长后再进行下一波全选复制粘贴似乎总是最优的选择。另外,这个数列增长得很快, 80 次按键能输入的字符数就已经上亿了。看来,要想刷屏到系统崩溃并不难,不足 100 次按键就能产生上 G 的数据。
以上分析转载自Matrix67,代码如下:
#include<stdio.h>
#include<malloc.h>
#include<math.h>
#include<assert.h>
int Fun(int *p, int m);
int main()
{
int *p;
int n;
int i;
scanf("%d", &n);
p = (int *)malloc(sizeof(int) * (n+1));
assert(p != NULL && n >0);
for(i = 0; i < n+1; ++i)
p[i] = 0;
Fun(p, n+1);
for(i = 1; i < n+1; ++i)
{
printf("%4d ", p[i]);
if(i % 10 == 0)
printf("\n");
}
free(p);
return 0;
}
int Fun(int *p, int m)
{
int i, j;
int Min;
int k = 0;
for(i = 1; i < m; ++i)
{
Min = p[i-1] + 1;
for(j = 2; j < sqrt(i); j++)
{
if(i % j == 0)
{
k = p[i/j] + j+ 2;
if(k < Min)
Min = k;
}
}
p[i] = Min;
}
}//score. Find a set of segments have the largest score but non of them is overlapped with others.
{start point, end point, score}
比如{1,3,3}, {2,4,5}, {3,5,3}
答案是{1,3,3},{3,5,3},
#include<stdio.h>
#define N 8
typedef struct value
{
int begin;
int end;
int score;
} value, *pvalue;
void Find(pvalue arr, int n);
void My_Sort(pvalue arr, int n);
int main()
{
int i = 0;
value arr[N] = {{1, 3, 8},{2, 3, 8}, {0, 4, 2}, {3,5, 7}, {2, 6,1}, {0, 6, 2}, {2, 6, 1}, {6, 7, 10}};
My_Sort(arr, N);//按照开始的时间对数组排序
Find(arr, N);
}
void Find(pvalue arr, int n)
{
void Print(pvalue arr, int n, int j, int *pos);
int pos[N];//回溯寻找
int dp[N];//存放最大的分数值
int i = 0;
int j = 0;
int Max = 0;
for(i = 0; i < N; ++i)
{
dp[i] = arr[i].score;
pos[i] = -1;
}
for(i = 1; i < N; ++i)
{
for(j = 0; j < i; ++j)
{
if((arr[i].begin >= arr[j].end) && (dp[i] < dp[j]+arr[i].score))
{
dp[i] = dp[j] + arr[i].score;
pos[i] = j;
}
}
}
Max = dp[0];
j = 0;
for(i = 0; i < N; ++i)
{
if(Max < dp[i])
{
Max = dp[i];
j = i;
}
}
printf("The Max score is %d\n", Max);
Print( arr, n, j, pos);
}
void Print(pvalue arr, int n, int j, int *pos)
{
if(j < 0)
return;
Print(arr, n, pos[j], pos);
printf("{%d, %d, %d} ", arr[j].begin, arr[j].end, arr[j].score);
}
void My_Sort(pvalue arr, int n)
{
void swap(pvalue a, pvalue b);
int i, j;
int temp;
if(n <= 1)
return;
temp = arr->begin;
for(j = 0, i = 1; i < n; ++i)
{
if(arr[i].begin < temp)
{
j++;
if(i != j)
swap(arr+i, arr+j);
}
}
swap(arr, arr+j);
My_Sort(arr, j-1);
My_Sort(arr+j+1, n-j-1);
}
void swap(pvalue a, pvalue b)
{
value temp;
temp = *a;
*a = *b;
*b = temp;
}Google n条直线求交点 Given n lines in a panel, how can you find how many intersection points are there(count in the duplicated intersection point)
思路:根据所给的直线,算出斜率,根据斜率计算每增加一条直线增加多少个交点。假设直线不重合。
代码如下:
#include<iostream>
#include<vector>
#include<math.h>
using namespace std;
int GetPoint(vector<double> &vec);
int main()
{
int n;
double k;
int temp;
cin >>n;
vector<double> vec;
temp = n;
while(temp--)
{
cin>>k;
vec.push_back(k);
}
cout<<GetPoint(vec)<<endl;
}
int GetPoint(vector<double> &vec)
{
sort(vec.begin(), vec.end());
int count = 0; //交点的个数
double temp = vec[0];
int line = 1;//直线的条数
int m = 0;
for(vector<double>::iterator iter = vec.begin()+1; iter != vec.end(); iter++)
{
if((*iter - temp) > 0.0000001 || (*iter - temp) < -0.0000001)
{
m = line;
count+= m;
}
else{
count+= m;
}
line++;
temp = *iter;
}
return count;
}| google/Mircrosoft实现Random Shuffle的功能,就是说给你一个随机数发生器把一个数组里的元素乱序。 |
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
#define M 10
void swap(int *a, int *b);
int main()
{
int a[M] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
int i = 0;
for(i = 0; i < M; ++i)
{
srand(time(NULL));
swap(&a[M-1-i], &a[rand()%(M-i)]);
}
for(i = 0; i < M; ++i)
printf("%d ",a[i]);
printf("\n");
return 0;
}
void swap(int *a, int *b)
{
int temp;
temp = *a;
*a = *b;
*b = temp;
}
google 两个大小相同的排好序的数组,A和B,如何找出两个数组的中数
二分搜索的思想 时间复杂度log(N);
代码如下:
//找到两个排序数组的中位数
#include<stdio.h>
#define N 5
int FindMedium(int *a, int *b, int n);
int FindMediumCycle(int *a, int *b, int n);
int main()
{
int a[N] = {1, 2, 5, 5, 6};
int b[N] = {1, 4, 4, 5, 7};
printf("中位数是%d\n", FindMediumCycle(a, b, N));
return 0;
}
int FindMedium(int *a, int *b, int n) //递归实现
{//注意边界条件
int mid;
if(n < 1)
{
printf("error\n");
return 0;
}
if(n == 1)
return (*a < *b) ? *b : *a;
mid = (n-1)/2;
if(a[mid] == b[mid])
return a[mid];
else if(a[mid] < b[mid])
return FindMedium(a+mid, b, mid+1);
else
return FindMedium(a, b+mid, mid+1);
}
int FindMediumCycle(int *a, int *b, int n)//循环
{
int mid;
int length = n;
while(length > 1)
{
mid = (length-1)/2;
if(a[mid] == b[mid])
return a[mid];
else if(a[mid] < b[mid])
{
length = mid+1;
a = a+mid;
}
else
{
length = mid+1;
b = b+mid;
}
}
return (*a < *b) ? *b : *a;
}//二分搜索
int binsearch(int x, int v[], int n)
{
int low, high, mid;
low = 0;
high = n-1;
while(low <= high)
{
mid = (low + high)/2;
if(x < v[mid])
high = mid-1;
else if( x > v[mid])
low = mid+1;
else
return mid;
}
return -1;
}比如:
1,2,5,3,4,7,8,6
pervert pairs : <5,3> <5,4> <7,6> <8,6>,
归并的过程中找出逆序对
#include<stdio.h>
#include<malloc.h>
#include<assert.h>
//#define N 10
int count = 0;
void MSort(int *a, int *b, int left, int right);
void Merge(int *a, int *b, int lpos, int rpos, int rightend);
int FindPervert(int *a, int n);
int main()
{
int a[10] = {9, 8, 7, 6, 5, 4, 3, 2, 1, 0};
printf("\nThe pervert pairs is %d\n", FindPervert(a, 10));
return 0;
}
int FindPervert(int *a, int n)
{
int i = 0;
int *b = (int *)malloc(sizeof(int) * n);
assert(b != NULL);
MSort(a, b, 0, n-1);
for(i = 0; i< n;++i)
printf("%d ", a[i]);
free(b);
return count;
}
void MSort(int *a, int *b, int left, int right)
{
int center;
if(left < right)
{
center = (left + right)/2;
MSort(a, b, left, center);
MSort(a, b, center+1, right);
Merge(a, b, left, center+1, right);
}
}
void Merge(int *a, int *b, int left, int rightbegin, int right)
{
int leftend = rightbegin-1;
int temp;
int pos = left;
int i;
int num = right - left + 1;
while(left <= leftend && rightbegin <=right)
{
if(a[left] <= a[rightbegin])
{
b[pos++] = a[left++];
}
else
{
//如果a[left]>a[rightbegin],那么逆序数为序列1中a[left]后边元素的个数(包括a[left]),即leftend-left + 1,
//count += leftend - left+1; //增加逆序数的个数
temp = left;
while(temp <= leftend)//输出逆序数对
{
printf("<%d,%d> ", a[temp++], a[rightbegin]);
count++;
if(count % 10 == 0)
printf("\n");
}
b[pos++] = a[rightbegin++];
}
}
while(left <= leftend)
{
b[pos++] = a[left++];
}
while(rightbegin <= right)
{
b[pos++] = a[rightbegin++];
}
for(i = 0; i < num; ++i, right--)
a[right] = b[right];
}














 596
596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









