







目录
347. Top K Frequent Elements (Medium)
215. Kth Largest Element in an Array
347. Top K Frequent Elements (Medium)
451. Sort Characters By Frequency (Medium)
1.快速排序
理论部分
import java.util.Arrays;
public class QuickSort {
public static void main(String[] args) {
int[] nums={11,24,5,32,50,34,54,76};
System.out.println("快速排序前:"+ Arrays.toString(nums));
quickSort(nums,0,nums.length-1);
System.out.println("快速排序后:"+ Arrays.toString(nums));
}
public static void quickSort(int[] nums, int start, int end){
if(start>end) return;
int i,j,base;
i=start;
j=end;
base=nums[start];
while (i<j){
while (i<j && nums[j]>=base) j--;
while (i<j && nums[i]<=base) i++;
if(i<j){
swap(nums,i,j);
}
}
swap(nums,start,i);
quickSort(nums,start,j-1);
quickSort(nums,j+1,end);
}
public static void swap(int[] nums,int left,int right){
int temp=nums[left];
nums[left]=nums[right];
nums[right]=temp;
}
}
快速排序(详细讲解)_梦里Coding的博客-CSDN博客_快速排序
这个讲的非常好,建议就看这个看明白就好了
2.归并排序
理论部分
这一个比较好理解:
int* Merge_Sort(int arr[], int start, int end) {
//当start==end时,此时分组里只有一个元素,所以这是临界点
if (start < end) {
//分成左右两个分组,再进行递归
int mid = (start + end) / 2;
//左半边分组
Merge_Sort(arr, start, mid);
//右半边分组
Merge_Sort(arr, mid + 1, end);
//递归之后再归并归并一个大组
Merge(arr, start, mid, end);
}
return arr;
}
void Merge(int arr[], int start, int mid, int end) {
//左边分组的起点i_start,终点i_end,也就是第一个有序序列
int i_start = start;
int i_end = mid;
//右边分组的起点j_start,终点j_end,也就是第二个有序序列
int j_start = mid + 1;
int j_end = end;
//额外空间初始化,数组长度为end-start+1
int *temp = new int[end - start + 1];
int len = 0;
//合并两个有序序列
while (i_start <= i_end && j_start <= j_end) {
//当arr[i_start]<arr[j_start]值时,将较小元素放入额外空间,反之一样
if (arr[i_start] < arr[j_start]) {
temp[len] = arr[i_start];
len++;
i_start++;
}
else {
temp[len] = arr[j_start];
len++;
j_start++;
}
//temp[len++]=arr[i_start]<arr[j_start]?arr[i_start++]:arr[j_start++];
}
//i这个序列还有剩余元素
while (i_start <= i_end) {
temp[len] = arr[i_start];
len++;
i_start++;
}
//j这个序列还有剩余元素
while (j_start <= j_end) {
temp[len] = arr[j_start];
len++;
j_start++;
}
//辅助空间数据覆盖到原空间
for (int i = 0; i < end - start + 1; i++) {
arr[start + i] = temp[i];
}
}图解归并排序,带你彻底了解清楚!_程序员的时光的博客-CSDN博客_归并排序这个教程很推荐
然后下面是简洁版的:
void merge_sort(vector<int>& nums, int l, int r, vector<int>& temp) {
if (l + 1 >= r) {
return;
}
// divide
int m = l + (r - l) / 2;
merge_sort(nums, l, m, temp);
merge_sort(nums, m, r, temp);
// conquer
int p = l, q = m, i = l;
while (p < m || q < r) {
if (q >= r || (p < m && nums[p] <= nums[q])) {
temp[i++] = nums[p++];
}
else {
temp[i++] = nums[q++];
}
}
for (i = l; i < r; ++i) {
nums[i] = temp[i];
}
}3.插入排序
理论部分
void insertion_sort(vector<int> &nums, int n) {
for (int i = 0; i < n; ++i) {
for (int j = i; j > 0 && nums[j] < nums[j-1]; --j) {
swap(nums[j], nums[j-1]);
} } }4.冒泡排序
理论部分
public class BubbleSort implements IArraySort {
@Override
public int[] sort(int[] sourceArray) throws Exception {
// 对 arr 进行拷贝,不改变参数内容
int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);
for (int i = 1; i < arr.length; i++) {
// 设定一个标记,若为true,则表示此次循环没有进行交换,也就是待排序列已经有序,排序已经完成。
boolean flag = true;
for (int j = 0; j < arr.length - i; j++) {
if (arr[j] > arr[j + 1]) {
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
flag = false;
}
}
if (flag) {
break;
}
}
return arr;
}
}c++的是这样:
void bubble_sort(vector<int>& nums, int n) {
bool swapped;
for (int i = 1; i < n; ++i) {
swapped = false;
for (int j = 1; j < n - i + 1; ++j) {
if (nums[j] < nums[j - 1]) {
swap(nums[j], nums[j - 1]);
swapped = true;
}
}
if (!swapped) {
break;
}
}
}5.选择排序
理论部分
function selectionSort(arr) {
var len = arr.length;
var minIndex, temp;
for (var i = 0; i < len - 1; i++) {
minIndex = i;
for (var j = i + 1; j < len; j++) {
if (arr[j] < arr[minIndex]) { // 寻找最小的数
minIndex = j; // 将最小数的索引保存
}
}
temp = arr[i];
arr[i] = arr[minIndex];
arr[minIndex] = temp;
}
return arr;
}6.桶排序
347. Top K Frequent Elements (Medium)
用例子说明理论,关键难点在于一个嵌套装桶
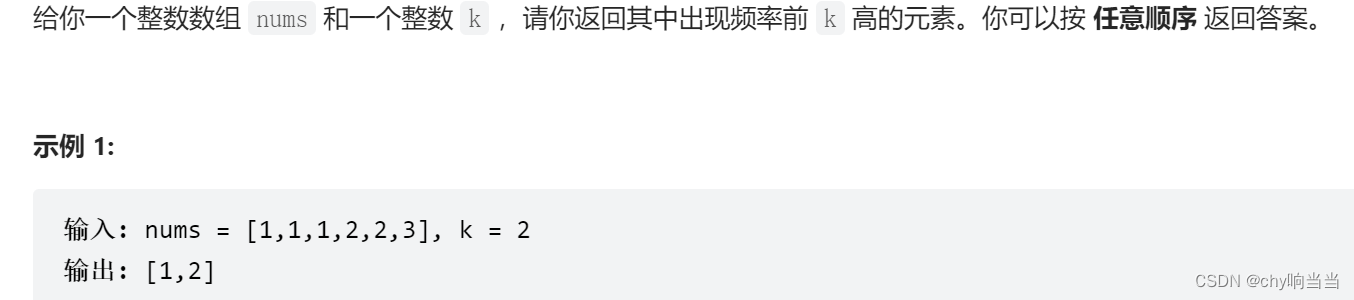
题解顾名思义,桶排序的意思是为每个值设立一个桶,桶内记录这个值出现的次数(或其它属 性),然后对桶进行排序。针对样例来说, 我们先通过桶排序得到四个桶 [1,2,3,4],它们的值分别 为 [4,2,1,1],表示每个数字出现的次数。紧接着,我们对桶的频次进行排序,前 k 大个桶即是前 k 个频繁的数。这里我们可以使用各种 排序算法,甚至可以再进行一次桶排序,把每个旧桶根据频次放在不同的新桶内。针对样例来说, 因为目前最大的频次是 4 , 我们建立 [1,2,3,4] 四个新桶,它们分别放入的旧桶为 [[3,4],[2],[],[1]], 表示不同数字出现的频率。最后,我们从后往前遍历,直到找到 k 个旧桶。
vector<int> topKFrequent1(vector<int>& nums, int k) {
unordered_map<int, int> counts;
int max_count = 0;
for (const int& num : nums) {
max_count = max(max_count, ++counts[num]);//通过key找到value
//这里其实是map添加元素方法里面的赋值添加,没有通过insert
}
vector<vector<int>> buckets(max_count + 1);
for (const auto& p : counts) {
buckets[p.second].push_back(p.first);
}
vector<int> ans;
for (int i = max_count; i >= 0 && ans.size() < k; --i) {
for (const int& num : buckets[i]) {
ans.push_back(num);
if (ans.size() == k) {
break;
}
}
}
return ans;
}注意,桶排序的话,map要先学会。
7.堆排序
理论部分
建议阅读大话数据结构,上面讲的非常清楚,由于本文章用于笔记而非教程,就不赘述了。
下面是大根堆的代码:
//大根堆
void HeapAdjust(vector<int>& r, int s, int m)
{
int temp, j;
temp = r[s];
for (j = 2 * s; j <= m; j *= 2) /* 沿关键字较大的孩子结点向下筛选 */
{
if (j < m && r[j] < r[j + 1])
++j; /* j为关键字中较大的记录的下标 */
if (temp >= r[j])
break; /* rc应插入在位置s上 */
r[s] = r[j];
s = j;
}
r[s] = temp; /* 插入 */
}
void swap(vector<int>& r, int i, int j) {
r[i] = r[i] ^ r[j];
r[j] = r[i] ^ r[j];
r[i] = r[i] ^ r[j];
}
void HeapSort(vector<int>& r, int len)
{
int i;
for (i = len / 2; i >= 0; i--) /* 把L中的r构建成一个大顶堆 */
HeapAdjust(r, i, len);
for (i = len; i > 0; i--)
{
swap(r, 0, i); /* 将堆顶记录和当前未经排序子序列的最后一个记录交换 */
HeapAdjust(r, 0, i - 1); /* 将L->r[1..i-1]重新调整为大顶堆 */
}
}
小根堆要是不用stl会很麻烦.......
8.例子
215. Kth Largest Element in an Array

这个问题有多个方法,一个一个说:
快速选择
快速选择一般用于求解 k-th Element 问题,可以在 O(n) 时间复杂度,O(1) 空间复杂度完成求 解工作。快速选择的实现和快速排序相似,不过只需要找到第 k 大的枢( pivot )即可,不需要对其左右再进行排序。与快速排序一样,快速选择一般需要先打乱数组,否则最坏情况下时间复杂度为 O (n2),我们这里为了方便省略掉了打乱的步骤。
需要好好体会。
void swap(vector<int>&nums, int left, int right) {
int temp = nums[left];
nums[left] = nums[right];
nums[right] = temp;
}
void quickSort(vector<int>& nums, int start, int end) {
if (start > end) return;
int i, j, base;
i = start;
j = end;
base = nums[start];
while (i < j) {
//一定要先动j
while (i < j && nums[j] >= base) j--;
while (i < j && nums[i] <= base) i++;
if (i < j) {
swap(nums, i, j);
}
}
swap(nums, start, i);
quickSort(nums, start, j - 1);
quickSort(nums, j + 1, end);
}
int findKthLargest2(vector<int>& nums, int k) {
quickSort(nums, 0, nums.size() - 1);
int i = nums.size() - 1;
while (k > 1) {
i--;
k--;
}
return nums[i];
}归并
void Merge_Sort(vector<int>& arr, int start, int end) {
//当start==end时,此时分组里只有一个元素,所以这是临界点
if (start < end) {
//分成左右两个分组,再进行递归
int mid = (start + end) / 2;
//左半边分组
Merge_Sort(arr, start, mid);
//右半边分组
Merge_Sort(arr, mid + 1, end);
//递归之后再归并归并一个大组
Merge(arr, start, mid, end);
}
}
void Merge(vector<int>& arr, int start, int mid, int end) {
//左边分组的起点i_start,终点i_end,也就是第一个有序序列
int i_start = start;
int i_end = mid;
//右边分组的起点j_start,终点j_end,也就是第二个有序序列
int j_start = mid + 1;
int j_end = end;
//额外空间初始化,数组长度为end-start+1
int* temp = new int[end - start + 1];
int len = 0;
//合并两个有序序列
while (i_start <= i_end && j_start <= j_end) {
//当arr[i_start]<arr[j_start]值时,将较小元素放入额外空间,反之一样
if (arr[i_start] < arr[j_start]) {
temp[len] = arr[i_start];
len++;
i_start++;
}
else {
temp[len] = arr[j_start];
len++;
j_start++;
}
//!!!!!!!!!!!!!!!!!!!!!!!!!! temp[len++]=arr[i_start]<arr[j_start]?arr[i_start++]:arr[j_start++];
}
//i这个序列还有剩余元素
while (i_start <= i_end) {
temp[len] = arr[i_start];
len++;
i_start++;
}
//j这个序列还有剩余元素
while (j_start <= j_end) {
temp[len] = arr[j_start];
len++;
j_start++;
}
//辅助空间数据覆盖到原空间
for (int i = 0; i < end - start + 1; i++) {
arr[start + i] = temp[i];
}
}
int findKthLargest1(vector<int>& nums, int k) {
Merge_Sort(nums, 0, nums.size() - 1);
int i = nums.size() - 1;
while (k > 1) {
i--;
k--;
}
return nums[i];
}根堆
void HeapAdjust(vector<int>& r, int s, int m)
{
int temp, j;
temp = r[s];
for (j = 2 * s; j <= m; j *= 2) /* 沿关键字较大的孩子结点向下筛选 */
{
if (j < m && r[j] < r[j + 1])
++j; /* j为关键字中较大的记录的下标 */
if (temp >= r[j])
break; /* rc应插入在位置s上 */
r[s] = r[j];
s = j;
}
r[s] = temp; /* 插入 */
}
void swap(vector<int>& r, int i, int j) {
r[i] = r[i] ^ r[j];
r[j] = r[i] ^ r[j];
r[i] = r[i] ^ r[j];
}
void HeapSort(vector<int>& r, int len)
{
int i;
for (i = len / 2; i >= 0; i--) /* 把L中的r构建成一个大顶堆 */
HeapAdjust(r, i, len);
for (i = len; i > 0; i--)
{
swap(r, 0, i); /* 将堆顶记录和当前未经排序子序列的最后一个记录交换 */
HeapAdjust(r, 0, i - 1); /* 将L->r[1..i-1]重新调整为大顶堆 */
}
}
int findKthLargest(vector<int>& nums, int k) {
HeapSort(nums, nums.size() - 1);
int i = nums.size() - 1;
while (k > 1) {
i--;
k--;
}
return nums[i];
}347. Top K Frequent Elements (Medium)

法一桶排序已经在理论部分讲过了
我们来看法二:
堆排序加优先队列(或者就叫小根堆,利用stl的priority_queue)
其实前k个高频或者低频的问题就要想到用根堆
这里就需要小根堆
求前 k 大,用小根堆,求前 k 小,用大根堆。
map是很合适的一种存储结构,key就是元素,value就是出现次数思路是这样:
我们之前不是学了把一个数组构建成堆嘛
那在这里我们先把数据存入map然后其实关键是对value进行排序,然后输出对应的key
不过,既然要求前k个高频的,我们不需要对map所有的元素进行排序(nlogn),我们只要维护前K个高频
说到这里是不是有想法了,我们以大根堆为例,用完全二叉树来编号,我们限制编号最大为k
我们对map进行遍历,每次来判断是不是要加入堆里面,要加就加进去,并且要维持大根堆的形状
这里为什么要用小根堆?大根堆不是顶点最大吗,好像要用大顶堆
定义一个大小为k的大顶堆,在每次移动更新大顶堆的时候,每次弹出都把最大的元素弹出去了(加入元素都加在末尾)
一般弹出都是弹出顶
所以我们要用小顶堆,因为要统计最大前k个元素,只有小顶堆每次将最小的元素弹出,最后小顶堆里积累的才是前k个最大元素。
这样时间复杂度就是n*logk,因为二叉树只维护k个元素
然后这里还有一个现成的数据结构,叫优先队列 priority_queue时间复杂度:O(nlogk)
空间复杂度:O(n)
topk (前k大)用小根堆,维护堆大小不超过 k 即可。每次压入堆前和堆顶元素比较,如果比堆顶元素还小,直接扔掉,否则压入堆。检查堆大小是否超过 k,如果超过,弹出堆顶。复杂度是 nlogk 避免使用大根堆,因为你得把所有元素压入堆,复杂度是 nlogn,而且还浪费内存。如果是海量元素,那就挂了。
[注意]求前 k 大,用小根堆,求前 k 小,用大根堆。
class Solution {
public:
// 小顶堆
class mycomparison {
public:
bool operator()(const pair<int, int>& lhs, const pair<int, int>& rhs) {
return lhs.second > rhs.second;/*注意这个是大于,这和底层实现有关,反正就是用到了查一查就好,没必要记*/
}
};
vector<int> topKFrequent(vector<int>& nums, int k) {
// 要统计元素出现频率
unordered_map<int, int> map; // map<nums[i],对应出现的次数>
for (int i = 0; i < nums.size(); i++) {
map[nums[i]]++;
}
// 对频率排序
// 定义一个小顶堆,大小为k
priority_queue<pair<int, int>, vector<pair<int, int>>, mycomparison> pri_que;
// 用固定大小为k的小顶堆,扫面所有频率的数值
for (unordered_map<int, int>::iterator it = map.begin(); it != map.end(); it++) {
pri_que.push(*it);
if (pri_que.size() > k) { // 如果堆的大小大于了K,则队列弹出,保证堆的大小一直为k
pri_que.pop();
}
}
// 找出前K个高频元素,因为小顶堆先弹出的是最小的,所以倒叙来输出到数组
vector<int> result(k);
for (int i = k - 1; i >= 0; i--) {
result[i] = pri_que.top().first;
pri_que.pop();
}
return result;
}
};451. Sort Characters By Frequency (Medium)
桶排序

体会叠加
string frequencySort(string s) {
unordered_map <char, int> count;
int max_count = 0;
for (int i = 0; i < s.size(); ++i) {
++count[s[i]];
max_count = max(max_count, count[s[i]]);
}
//这种叠加的,真的要体会
vector<string> buckets(max_count );
for (const auto& p : count) {
int temp = p.second;
while (temp > 0) {
buckets[p.second - 1].push_back(p.first);
--temp;
}
}
string ans;
for (int i = max_count - 1; i >= 0; --i) {
ans.append(buckets[i]);
}
return ans;
}
75. Sort Colors (Medium)
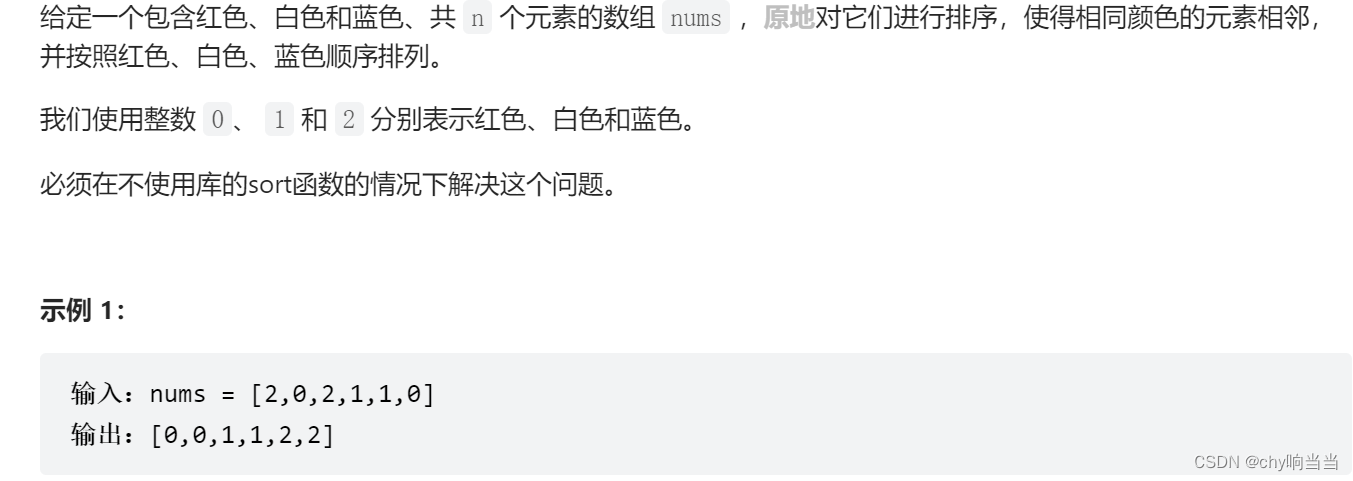
特色是只有012,所以可以写出更简洁的代码
先看通用的快速排序:
void swap(vector<int>& nums, int left, int right) {
int temp = nums[left];
nums[left] = nums[right];
nums[right] = temp;
}
void quickSort(vector<int>& nums, int start, int end) {
if (start > end) return;
int i, j, base;
i = start;
j = end;
base = nums[start];
while (i < j) {
//一定要先动j
while (i < j && nums[j] >= base) j--;
while (i < j && nums[i] <= base) i++;
if (i < j) {
swap(nums, i, j);
}
}
swap(nums, start, i);
quickSort(nums, start, j - 1);
quickSort(nums, j + 1, end);
}
void sortColors(vector<int>& nums) {
quickSort(nums, 0, nums.size() - 1);
}
更简洁的:
//扫描一遍的
void sortColors2(vector<int>& nums, int len) {
int r1 = -1;
int r2 = -1;
for (int i = 0; i < len; i++) {
if (nums[i] < 2)
{
r2++;
swap(nums, i, r2);
if (nums[r2] < 1)
{
r1++;
swap(nums, r1, r2);
}
}
}
}
class Solution {
public:
void sortColors(int nums[], int len) {
int num0 = 0, num1 = 0, num2 = 0;
for (int i = 0; i < len; i++) {
if (nums[i] == 0) {
nums[num2++] = 2;
nums[num1++] = 1;
nums[num0++] = 0;
}
else if (nums[i] == 1) {
nums[num2++] = 2;
nums[num1++] = 1;
}
else {
nums[num2++] = 2;
}
}
}
};注意:还有希尔排序、基数排序等,个人认为熟练掌握以上排序已经完全足够,以后有时间会继续补充的。
















 170
170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









