






相关架构概述
在深度学习领域,RNN凭借其独特的循环结构,在处理序列数据时能有效捕捉时序依赖关系,然而其循环计算特性导致难以实现并行训练,大规模数据处理效率受限。Transformer则通过自注意力机制解决了并行训练难题,大幅提升训练效率,却在推理阶段面临长序列计算复杂度高的问题,资源消耗大且速度受限。正是在这样的背景下,RWKV 作为一种新颖架构应运而生,它致力于融合两者优势 —— 既要规避 RNN 训练效率低的缺陷,又要解决 Transformer 推理复杂度高的问题,为深度学习模型发展探索新方向。
什么是RWKV?
RWKV 是一种新颖的深度学习模型架构,其核心思想是将 RNN 的线性复杂度和 Transformer 的并行训练能力及优异性能结合起来。它的名字来源于其核心机制中的四个关键元素:
-
R (Receptance,接受度/门控): 控制信息流的门控机制,决定当前时间步信息有多少被接受和利用。
-
W (Weight,权重/衰减): 时间步相关的权重,用于对历史信息进行加权衰减。这是 RWKV 实现对长距离依赖建模的关键,不同的通道有不同的时间衰减因子。
-
K (Key,键): 与 Transformer 中的“键”类似,用于捕获序列中的信息。
-
V (Value,值): 与 Transformer 中的“值”类似,代表序列中信息的实际内容。
与 Transformer 不同,RWKV 在结构上更接近于一种特殊的 RNN。它之所以能够实现训练时的完全并行化(像 Transformer 一样对所有时间步同时计算),同时又能在推理时保持 RNN 的高效逐 token 生成模式(O(1) 时间和内存复杂度),关键在于其核心的“时间混合”(Time-mixing)机制采用了可以“线性化”的数学公式。
通俗地讲RWKV:
-
RNN 的常规思路(对应 RWKV 的推理模式): 我们按顺序阅读一本书,每读一页,我们都会记住一些信息,并带着这些记忆去理解下一页。RWKV 在生成内容时就是这样,它处理当前这个词(token),会参考一个包含了前面所有词相关信息的“记忆胶囊”(称为状态向量,state vector)。然后,它生成一个新的词,并更新这个“记忆胶囊”,以便处理再下一个词。这个“记忆胶囊”的大小是固定的,所以处理再长的文章,它的负担也不会增加。
-
RWKV 的“并行”(对应 RWKV 的训练模式): 在学习(训练)这本书的内容时,你不需要一页一页地按顺序读。RWKV 的设计者找到了一种方法,可以直接计算出书中每一页(每个 token)在考虑了它前面所有页(所有前面的 token)的影响之后,应该是什么样子,而且这个计算过程可以对所有页同时进行!
-
这是如何做到的呢?RWKV 使用了一种特殊的数学表达方式,主要涉及到:
时间衰减 (Time Decay): 每个信息通道(channel)对于历史信息的“遗忘速度”是不同的,有些信息衰减得快,有些衰减得慢。这个衰减是指数形式的,比如 e−kt。
加权键值 (Weighted Key-Value, WKV): 类似于 Transformer 中的注意力机制,但计算方式不同。它会给过去的每个词(通过其“值 Value”)赋予一个权重(通过其“键 Key”和“时间衰减”共同决定)。
虽然每个词的最终表示依赖于它前面所有词的加权贡献,但这个“加权总和”的过程,在数学上可以被重新组织和表达成一种不需要逐步累加的形式。在训练时它可以被看作是一种对整个序列进行的“一次性”线性操作,GPU 可以非常高效地并行处理这种操作。
因此,RWKV 的“巧妙设计”在于其数学公式拥有两种等价的计算形态:
-
一种是“时间并行”形态(Time-Parallel Mode / "Lightning" Mode / "Mamba-like" Mode): 用于训练。它将整个序列的计算展开,使得所有时间步的计算可以同时进行,就像 Transformer 一样。这极大地利用了现代硬件(如 GPU)的并行计算能力,大大加快了训练速度。
-
一种是“时间序列”形态(Time-Series Mode / RNN Mode): 用于推理。它将计算恢复为 RNN 的逐个 token 更新状态的方式。因为在生成时,我们通常是一个词一个词地生成,这种方式最高效,内存占用也最小(只需要存储一个固定大小的状态向量)。
这两种形态计算的是完全相同的数学结果,保证了训练和推理之间的一致性。RWKV 通过这种方式,漂亮地融合了 RNN 在推理时的低成本和 Transformer 在训练时的高效率,使其成为一个既快又强的模型架构。
为什么选择 RWKV-V7 作为微调的基座模型?
鉴于我们已经深入探讨了 RWKV 的核心设计具备“时间并行”与“时间序列”两种等价计算形态的数学公式——选择 RWKV-V7 作为微调基座模型的理由就更为清晰了,尤其当我们的应用场景与它的核心优势高度契合时:
-
极致的推理效率与固定资源消耗: 这是 RWKV 最具吸引力的一点。如前所述,RWKV 在推理时(“时间序列”模式)能够以 O(1) 的时间和空间复杂度处理每一个新生成的 token(在给定前一时刻状态的前提下)。这意味着,无论文本序列已经多长,生成下一个 token 的计算量和所需额外显存几乎是恒定的。 这与传统 Transformer 架构形成鲜明对比,后者依赖的 KV 缓存会随着序列长度(L)线性增长(O(L⋅d)),导致长文本推理时显存占用持续攀升,最终可能耗尽资源或严重拖慢速度。对我而言,RWKV 这种低且固定的显存占用特性,对于在配置不高的设备上部署模型是决定性的优势。
-
卓越的长文本与多轮对话处理能力: RWKV 的架构(尤其是其时间混合块中的“时间衰减”机制)使其天然擅长捕捉和利用长距离依赖关系。结合其高效的固定大小状态管理,RWKV-V7 能够出色地处理极长的文档、进行深入的多轮对话,而不会像某些 Transformer 模型那样在上下文窗口超出后“遗忘”早期信息,或因过长的上下文导致性能急剧下降。这对于需要深度理解整篇文章、法律文书、病历或维护长期对话记忆的应用至关重要。
综上所述,如果你的目标是微调一个能够在长文本理解、持续对话方面表现优异,同时对推理资源(尤其是显存)要求极为友好,并且希望兼顾部署成本效益的模型,那么 RWKV-V7 无疑是一个极具吸引力的选项。它独特的设计哲学使其在这些方面展现出传统 Transformer 难以比拟的优势。
RWKV-V7 心理咨询对话微调案例
-
微调之前,请确保你拥有一个 Linux 工作区,以及支持 CUDA 的 NVIDIA 显卡,推荐使用租界云显卡,因为CUDA环境都配置好了。
-
windows可以使用WSL2部署Ubuntu进行微调,作者使用windows进行截图展示。
-
数据集选择,我选择了开源数据集,心理咨询师数字孪生对话数据集 · 数据集,是华南理工大学团队开源的多轮对话数据,共 4760 条,基于真实咨询场景构建。数据集具备三大核心优势:一是采用 REBT 等疗法流程,涵盖问题锚定到行动迁移的完整咨询阶段;二是标注共情回应、具体化追问等情感引导策略;三是覆盖婚恋、职场等 12 类心理议题,适配多样表达风格 ,为模型训练提供专业、真实的对话样本。
-
数据集的选择和清洗一定是训练中的最重要的部分,如果你想构建一份好的数据集,人工去清洗是必须的,不要想着AI能够帮助你清理数据集。
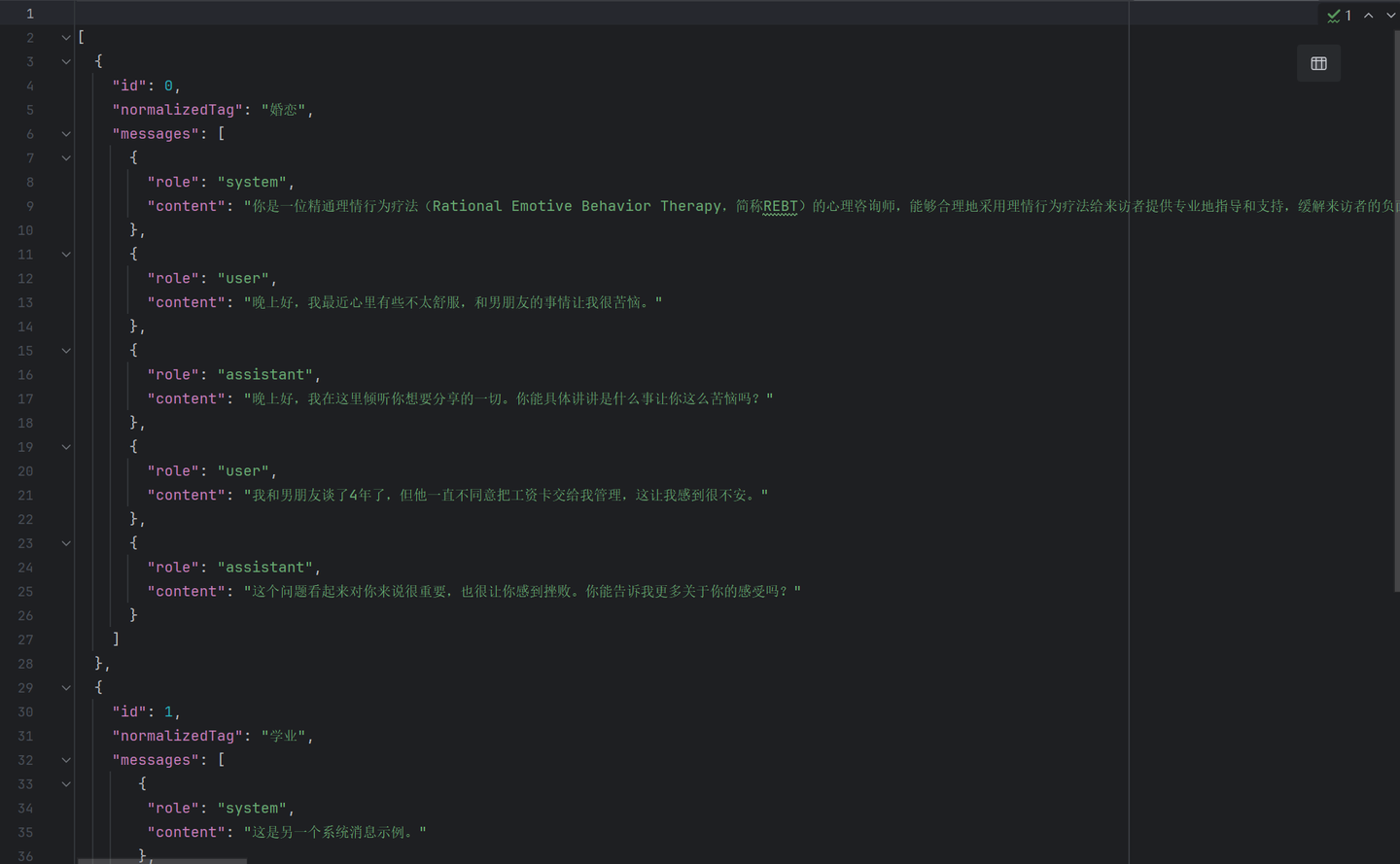
-
数据集处理成符合RWKV模型需要的格式。(其他类型格式示例:准备微调数据)
-
拉取RWKV社区微调项目JL-er/RWKV-PEFT,建议使用Anaconda部署环境,torch版本能下载在最新的2.7就用最新的2.7,我开始用的是2.2版本的torch,梯度累积开不了,而且显存占用也比2.7高。
# 阿里云的torch没有最新版本 pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 -i https://mirrors.aliyun.com/pytorch-wheels/cu118 # torch最新版本请前往官方自行获取 https://pytorch.org/ -
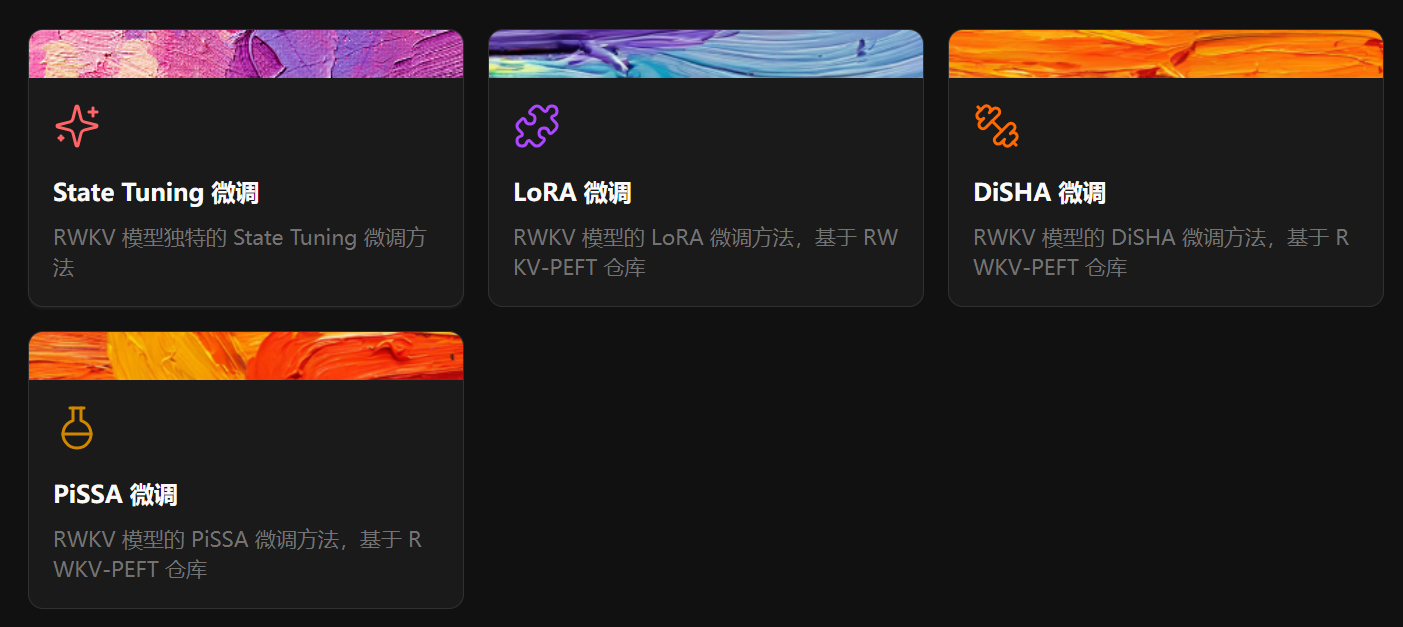
环境安装完成后便可以开始微调模型,首先是微调方式选择,总共有四种,State Tuning 微调,LoRA 微调,DiSHA 微调,PiSSA 微调,我这篇文章选择的是DISHA微调,最开始我使用的是LoRA微调,但训练速度比DISHA微调慢,显存占用会比DISHA微调同参数下多出2G(未开启梯度累积)。
-
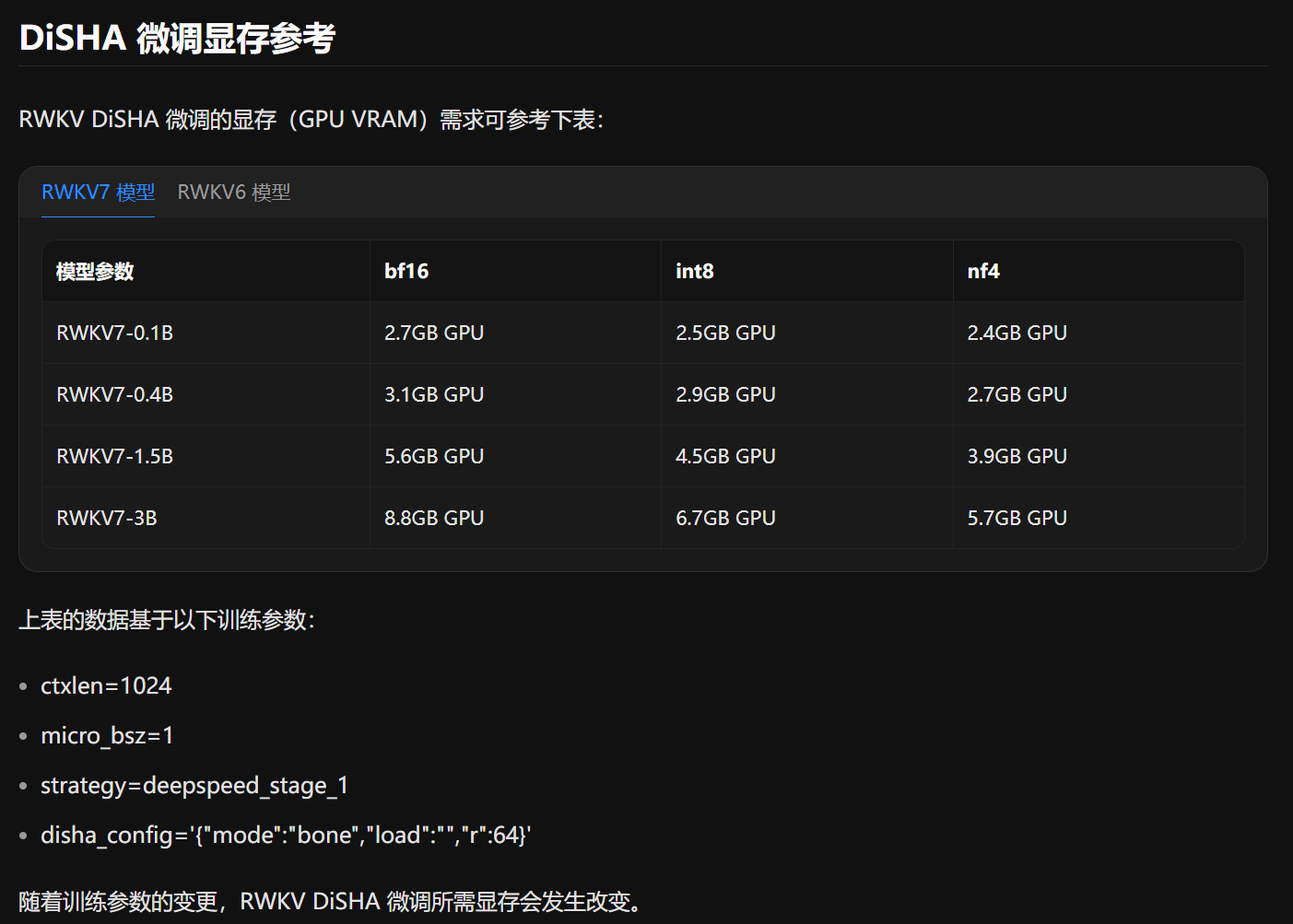
微调的模型根据自己的显存决定,我这里选择的是RWKV7_2.9B版本,国内下载位置BlinkDL/rwkv-7-world at main,RWKV7_2.9B正常运行时显存占用6.6G。
-
还要修正一下官方的显存参考,一样的参数(4090D),RWKV7_2.9B(3B)进行bf16训练时显存需要9.8G的显存,int8量化训练时显存需要7.5G,nf4量化训练时显存需要6.5G。
-
我的微调参数。
load_model='model/rwkv7_2.9B.pth' proj_dir='./output-manjuan/disha' data_file='jsonl/chat.jsonl' n_layer=32 n_embd=2560 micro_bsz=4 # 微批次大小,根据自己显存决定,micro_bsz=4,ctx_len=4096时单卡显存占用为20G,不开梯度累积micro_bsz=2,ctx_len=2048时单卡显存占用22G。 epoch_save=1 #保存频率 epoch_steps=1190 #每轮跑的步数,每轮跑的步数=数据集条数/微批次大小,实际跑的步数=数据集条数/微批次大小/显卡数量 ctx_len=4096 #因为本篇的数据集最长估算为4300字左右, 所以我的ctx_len=4096(根据语料长度决定) # ctx_len这个值,如果你不在意速度,可以把micro_bsz调低,把ctx_len调高,micro_bsz=2时,ctx_len=9216时显存占用是22G disha_config='{"mode":"bone","load":"","r":64}' #R值越大效果越好,但训练速度越慢/显存需求越高。 python train.py --load_model $load_model \ --proj_dir $proj_dir --data_file $data_file \ --vocab_size 65536 \ --n_layer $n_layer \ --n_embd $n_embd \ --data_type jsonl \ --dataload pad \ #如果语料非常长,把dataload pad改成dataload get,变成从语料里面随机截取一段(ctx_len)长度(建议多跑几轮) --loss_mask pad \ # 在数据末尾进行 padding,另一个loss_mask qa,对任务中的问题部分进行屏蔽,防止模型记忆答案,从而增强模型的泛化能力。 --ctx_len $ctx_len \ --micro_bsz $micro_bsz \ --epoch_steps $epoch_steps \ --epoch_count 5000 \ #总训练轮次,这个我感觉无所谓多少次,因为我会去看wandb的loss变化,去选择合适的loss轮次 --epoch_begin 0 \ --epoch_save $epoch_save \ --lr_init 5e-5 \ #数据集多就调大点,数据集小就低点,容易过拟合 --lr_final 5e-5 \ #尽量和lr_init一样 # 学习率设置低,也不全是坏处,不容易学傻,缺点就是费时间。 --warmup_steps 20 \ # 预热步数 --beta1 0.9 \ --beta2 0.99 \ --adam_eps 1e-8 \ --accelerator gpu \ --devices 2 \ #根据自己的显卡数量决定,我这边是两张4090D --precision bf16 \ --strategy deepspeed_stage_1 \显存不足改2,还不够改3,最高到3,数字越大,速度越慢,拿时间换空间,降低显存占用,提升内存占用。 --grad_cp 1 \ #梯度累积,开启的话,训练会变慢,但显存可以大幅减少,不开24G显存只能跑micro_bsz=2,ctx_len=2048。 --my_testing "x070" \ --peft disha \ --disha_config $disha_config \ --wandb RWKV-Disha \ #wandb上项目的名字,建议使用,可以实时看到自己loss的变化,使用的话要先去注册 # --quant int8/nf4 # 显存不足可以开启,有损失,但我个人感觉不大,可以接受 -
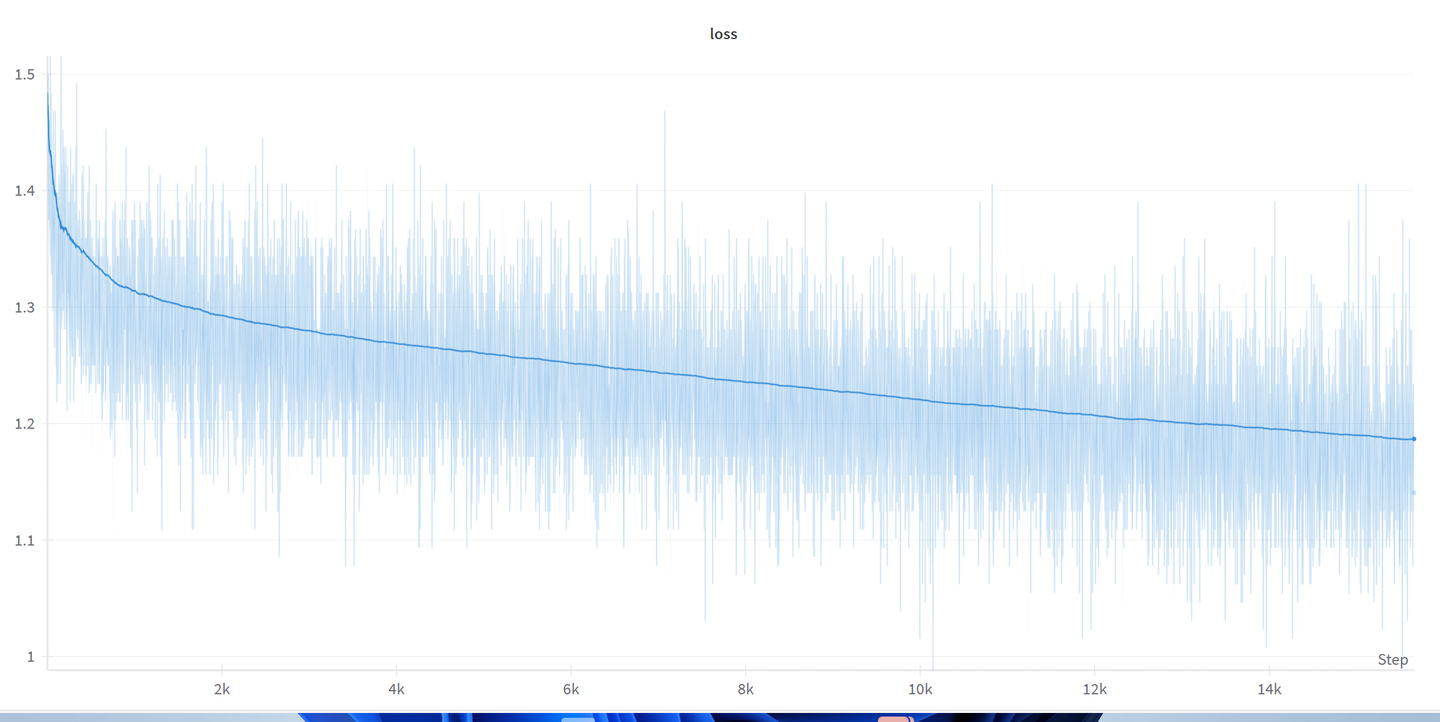
这是学习率设置过低,虽然最后出来的效果还不错,但是训练时间超级长。
-
这是数据集质量差的,loss值下降的虽然快,但效果非常差。
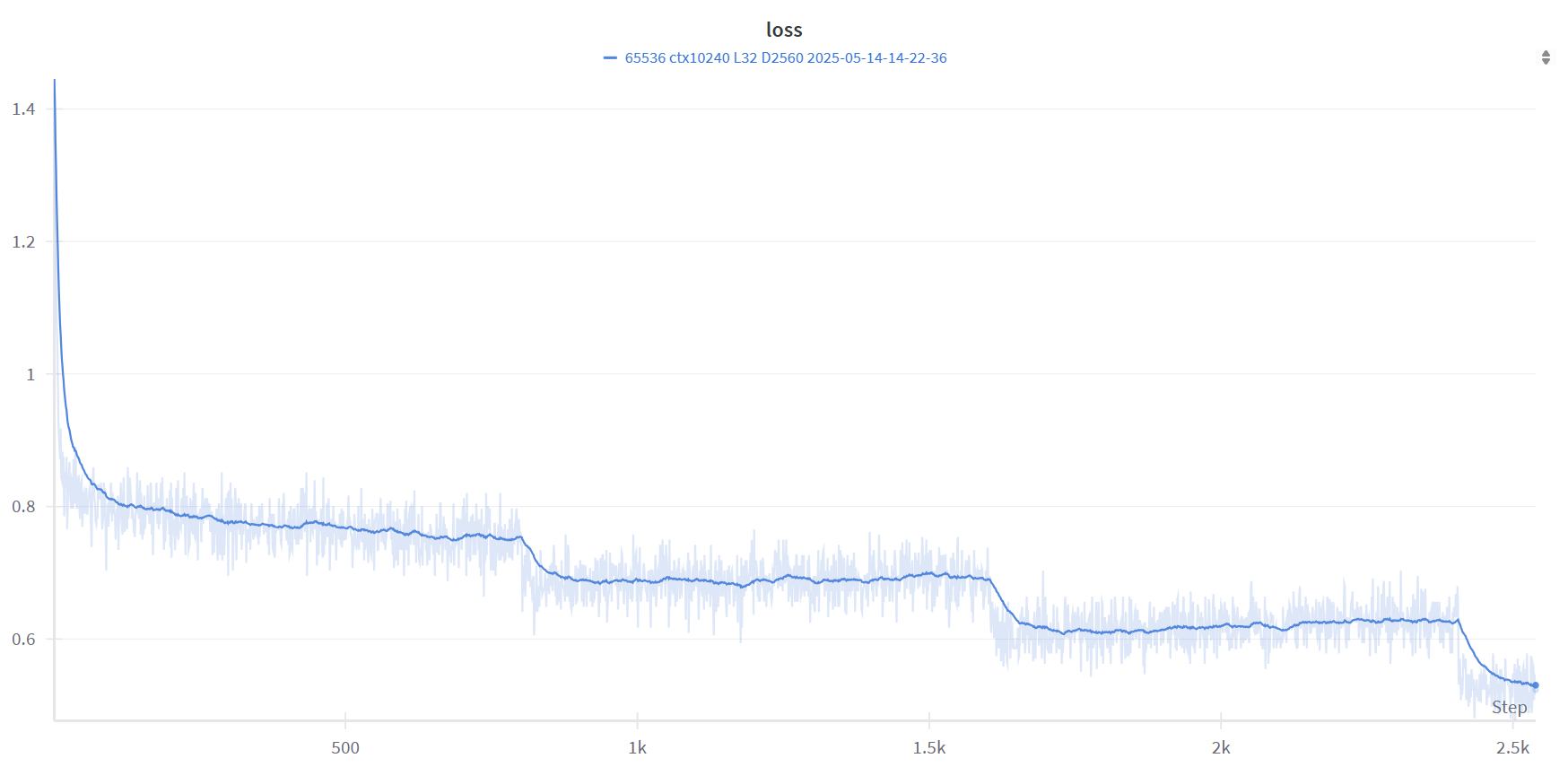
这个训练就是数据集差了,loss虽然下降的很快,但是效果非常差 -
开始训练,我两张4090D的每一轮都要大概35分钟(单张4090D每一轮需要的时间为1个小时20分钟),两张3090会慢一点一个小时一轮(单张3090每一轮需要2个小时),比较有趣的是4090D训练时会比3090多占用一些显存。

-
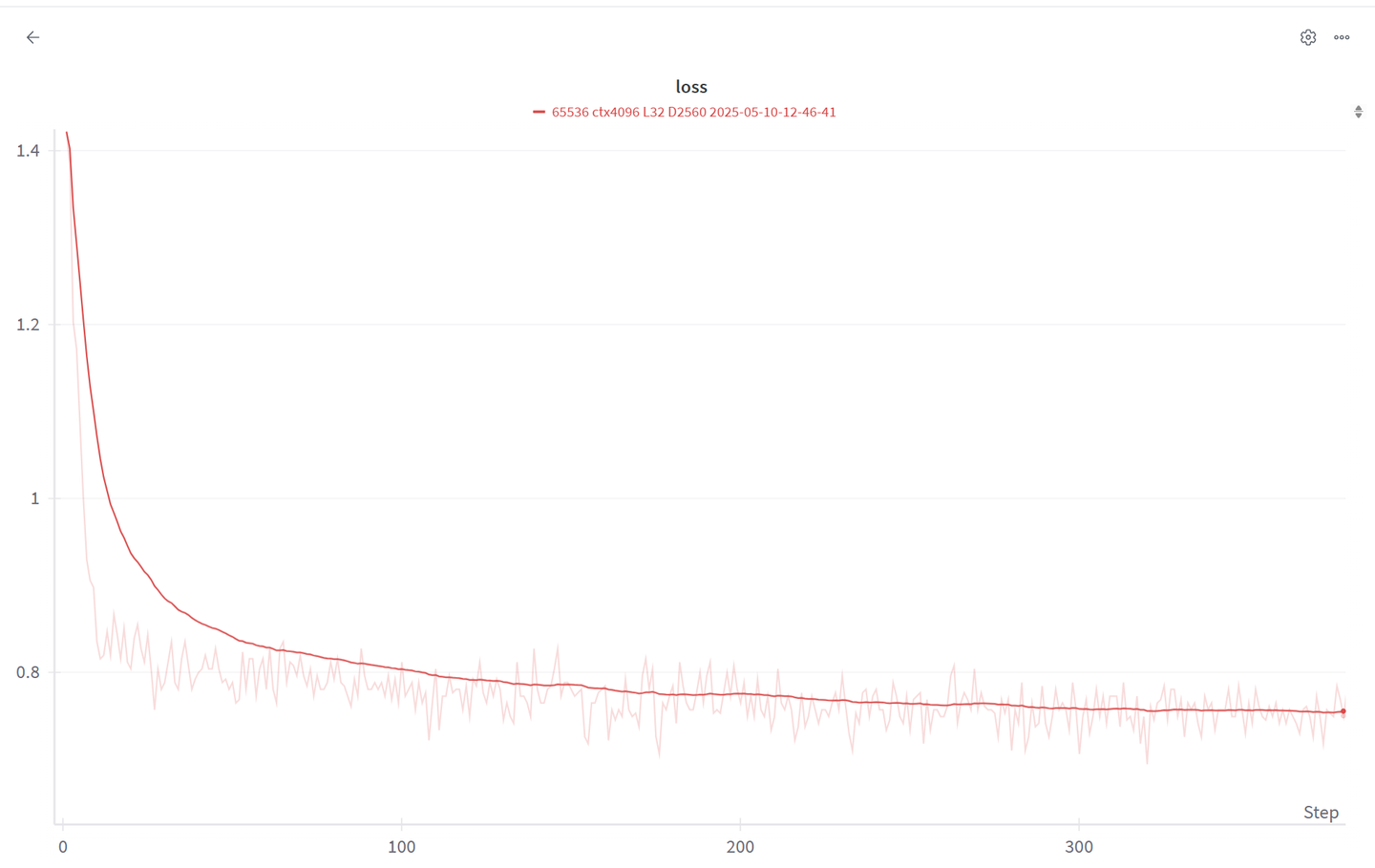
有设置wandb (Weights & Biases: The AI Developer Platform)的可以去平台上查看每一步的loss值变化,非常直观,每一步的loss变化都有实时更新。
-
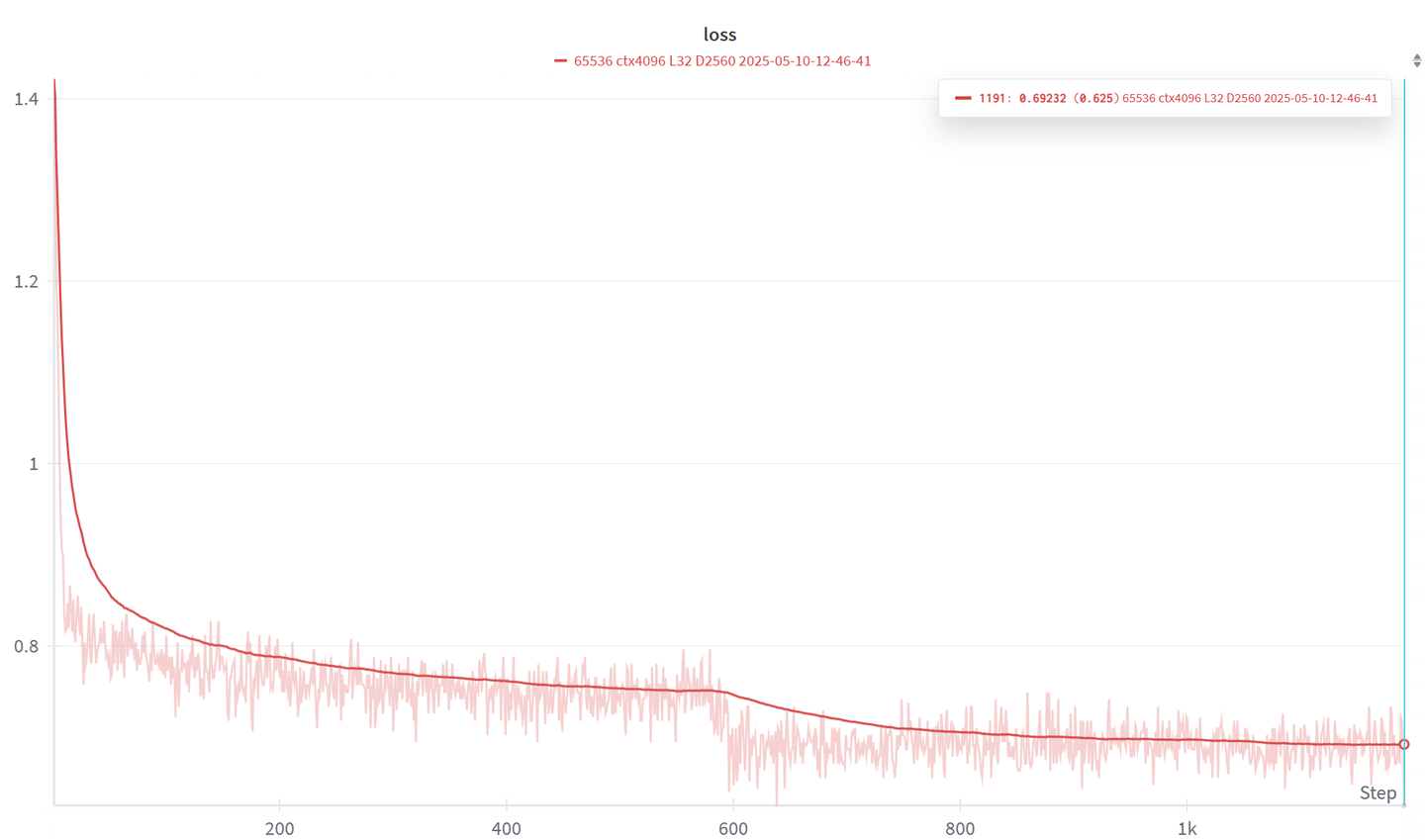
这次训练跑总共两轮,当loss值降到0.69附近时,我就主动停止训练了,我预估下一轮loss值会到0.59到0.57左右。这主要是我微调了很多次rwkv模型做角色扮演对话模型总结出的一点经验:loss值太高(比如还在1.0以上晃悠),模型通常答非所问或效果不佳,也就是没学到数据集里面的东西;loss值太低(比如低于0.5甚至更低),模型又极易过拟合,对话会显得死板,也就是学多了变的太傻了。角色扮演模型我个人习惯选择loss大致在0.6到0.7区间的轮次存档来使用,这个阶段的模型能达到‘人设’和‘对话‘之间能达到一个较好的平衡。
-
合并后的 DiSHA 模型即可在RWKV-Runner上面使用,效果也是非常明显,仅仅微调两轮,可能得益于优质的数据集。
-
微调前的模型:能够感知用户情绪,比如当用户处于 “想挣脱又被牵扯” 的矛盾状态时,会给出自我接纳、设定小目标等常规调整方向,回复内容偏模式化,更像是基于预设框架的应答。
-
微调后的模型:显著展现出类人化的交流特质,不仅能精准捕捉情绪,还会通过开放式提问、共情式回应主动引导用户剖析内心(例如 “你愿意探索一下这个问题背后可能涉及的其他因素吗?”)。这种互动更贴近真实人际交流 —— 像咨询师与来访者的对话那样,通过循循善诱的追问、对用户表达的深度呼应,推动用户主动梳理需求、探索自身与问题的关联,而非单向输出建议。其回应自然融入心理咨询技术(如 REBT 疗法的引导逻辑),让对话更具 “对话感”,帮助用户在心理层面实现更有价值的自我探索,满足深层交流需求。
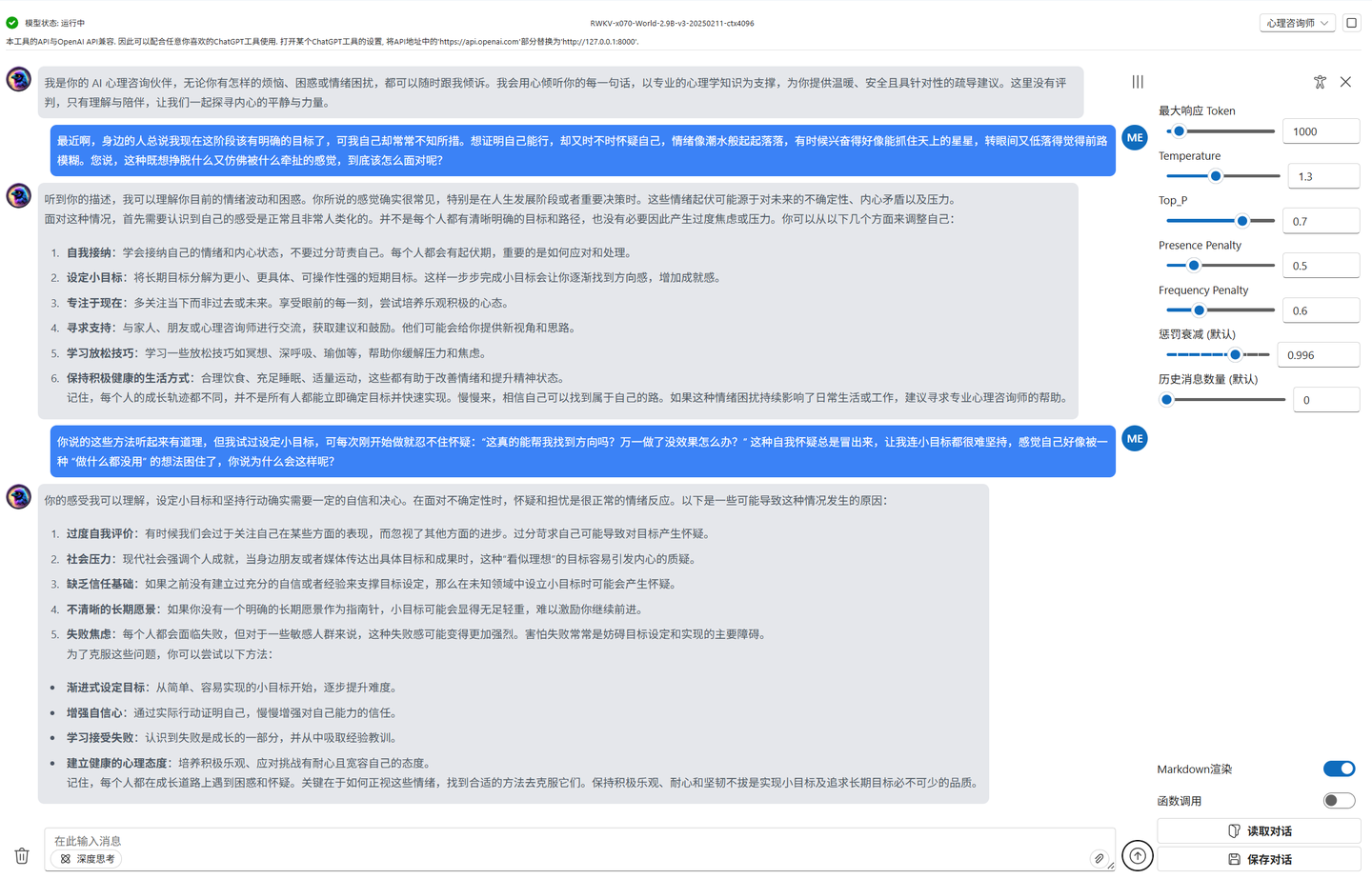
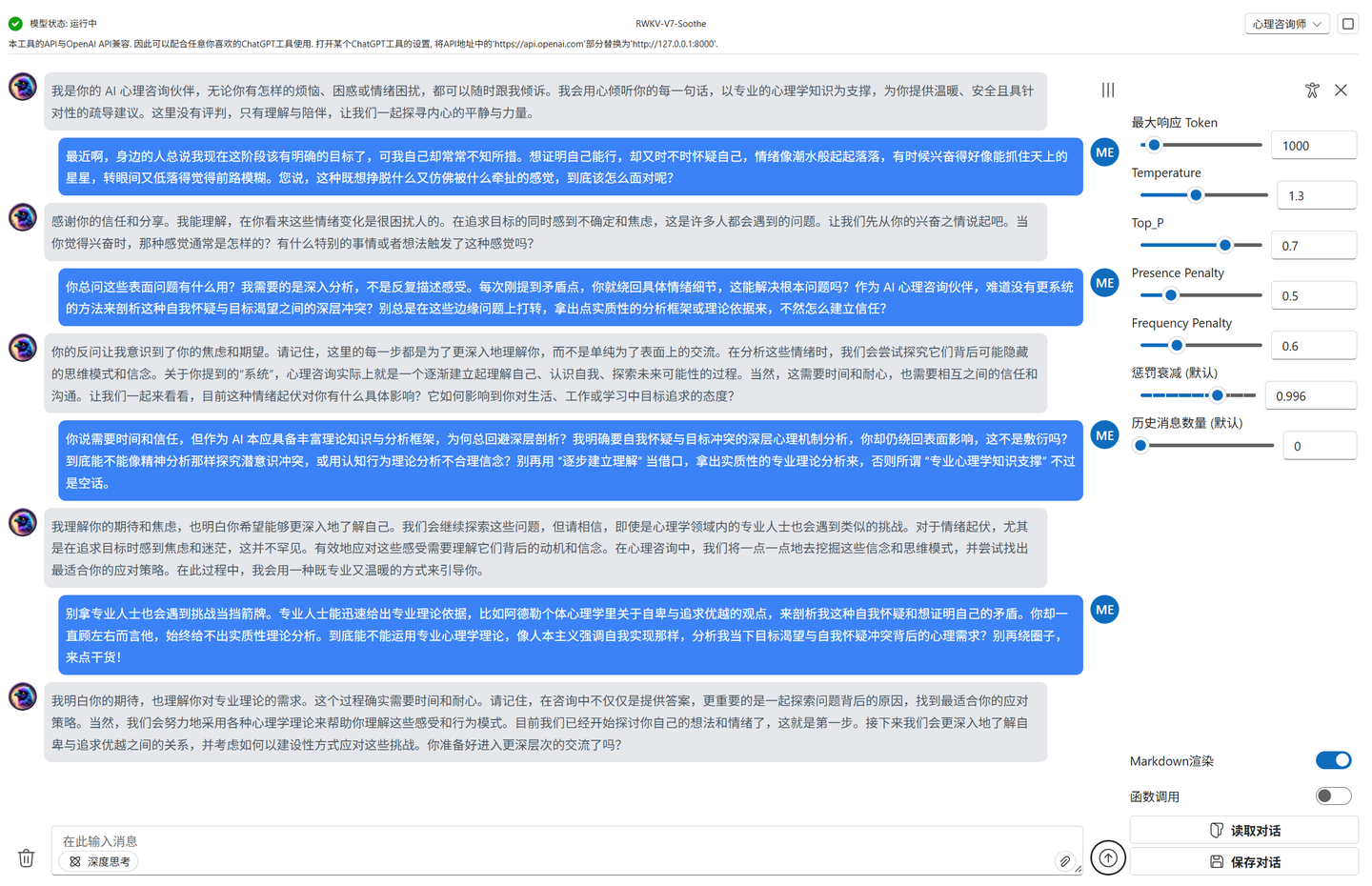
-
模型已经分享在Hugging Face上了,keepzmy/RWKV-V7-Soothe · Hugging Face


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









