









Feature Pyramid Networks for Object Detection論文研讀與問題討論
前言
本篇文章講述論文Feature Pyramid Networks for Object Detection。
本文除了介紹論文本身外,還加入了筆者研讀論文時的碰到的問題及個人的想法。將之記錄於問題討論章節中。
本論文著重於解決多尺度目標檢測的問題。
它使用CNN固有的多尺度,金字塔狀的結構,加上top-down pathway以及lateral connection,來建立feature pyramid。
這種做法僅額外多了一點計算量就能提升CNN對小物體檢測的效果。
並且FPN還能當作通用的特徵提取器來使用。
(1)背景介紹
Featurized Image Pyramids
以前要處理多尺度目標檢測的問題時,會使用到featurized image pyramids。
這個做法是將圖片縮放成各種尺度,送進CNN後就可以得到數個feature maps。
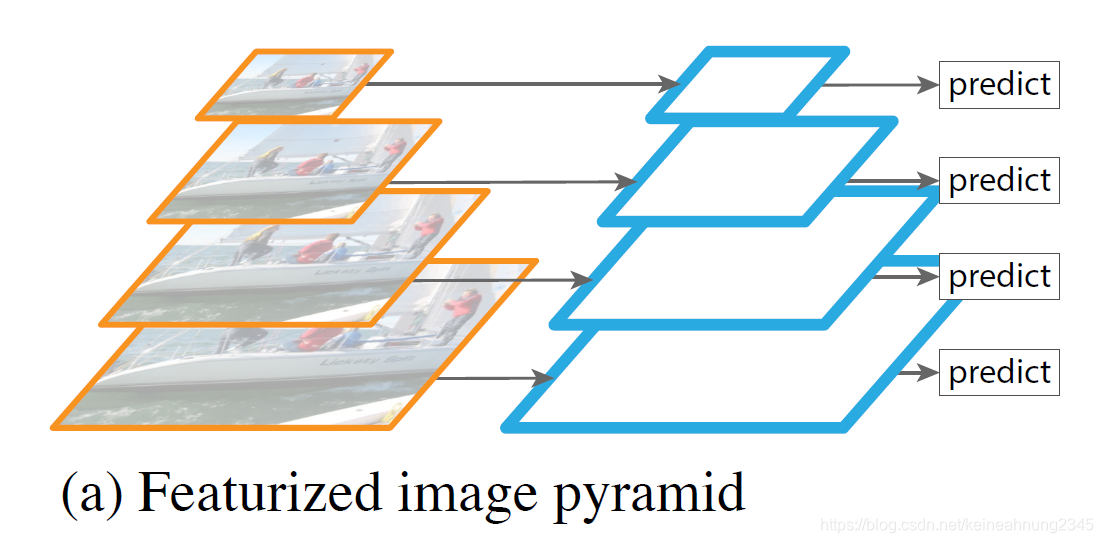
這種做法可以得到在每一層都有很強語義訊息的feature map。
但是會有幾個缺點:
- 如果使用featurized image pyramid來訓練模型的話,會需要大量的記憶體,所以這在現實上是不可行的。因此只有在推論時才會使用,但這又導致了訓練及測試時推論方法的不一致。
- 在推論時採用featurized image pyramid會讓速度下降很多。
Fast & Faster R-CNN
Fast & Faster R-CNN皆是以速度為重,所以並未採用featurized image pyramid。
它們只使用了最後一層的feature map。
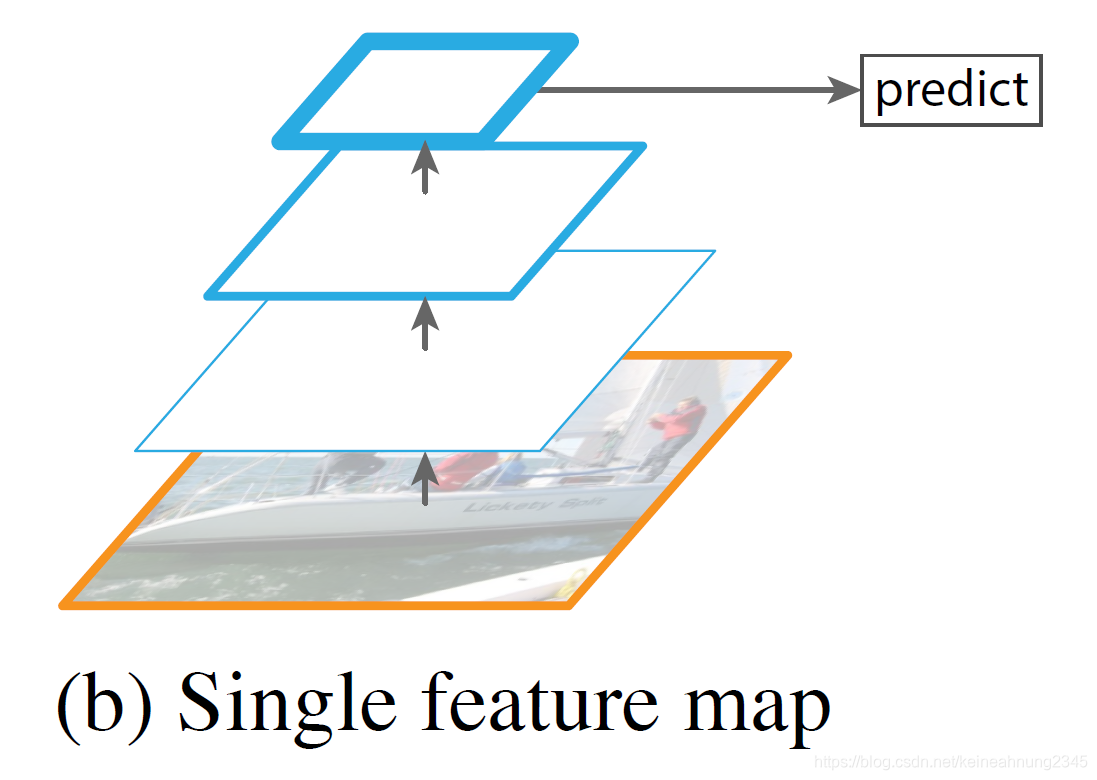
使用deep ConvNet固有的feature hierarchy
要造出多尺度的特徵,除了featurized image pyramid的方法外,還可使用deep ConvNet固有的feature map來建構。
但是使用這種方法造出來的feature maps所包含的語義訊息並不一致。
(較低層的kernel對角、線有反應,而較高層的kernel則負責辨識人、車等。)
這會在各feature maps間造成很大的semantic gaps(語義鴻溝)。
這種做法導致了一個不良的結果:較低層的feature map(高解析度,語義訊息少)的feature map可能會對模型準確度造成不良的影響。
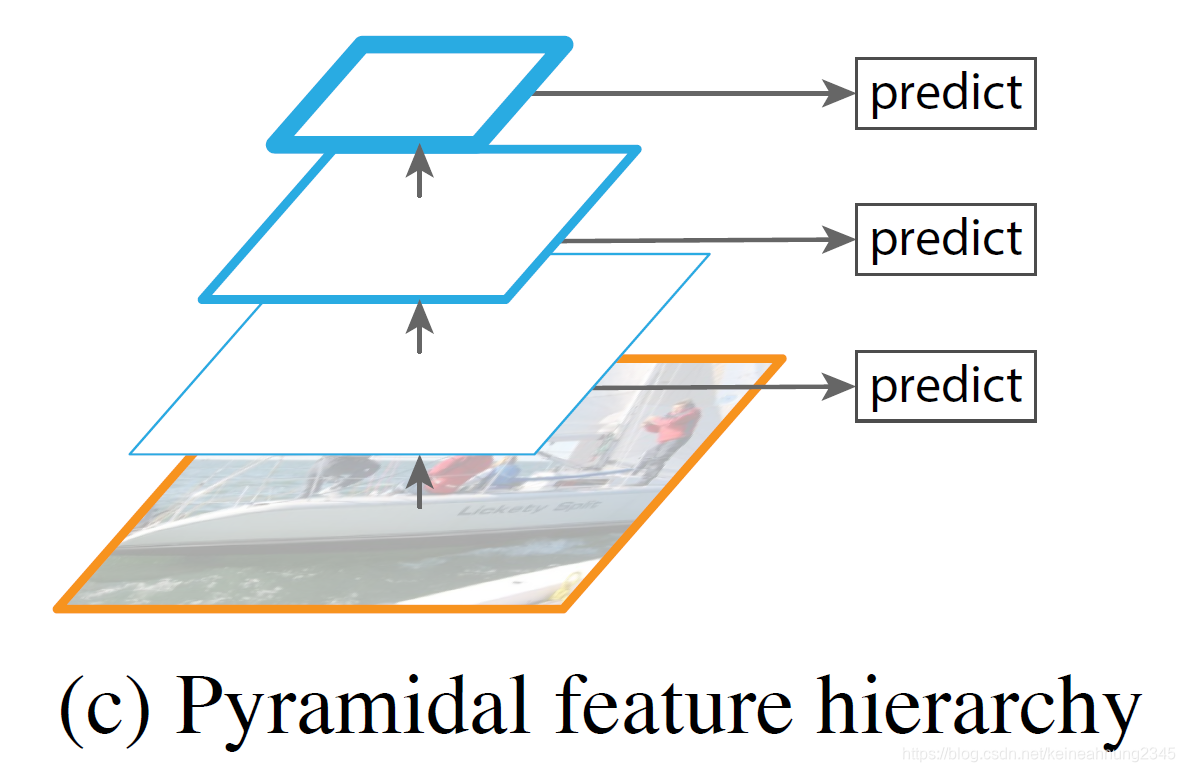
Single Shot Detector
Single Shot Detector為了防止低語義訊息的feature map對傷害到模型的表現,採用了不同的做法。
SSD是從較高層級的feature map開始往下建立feature maps。
但這種做法就放棄了低層級那些高解析度的feature map。
Feature Pyramid Network
FPN使用單一尺度的圖片做為輸入,並在原有網路結構中加入top-down pathway(由上而下的路徑)及lateral conenction(側向連接)來得到一個在各層皆有很強語義訊息的feature pyramid。
還有一種做法同樣採用了top-down pathway,並在最底層做預測。
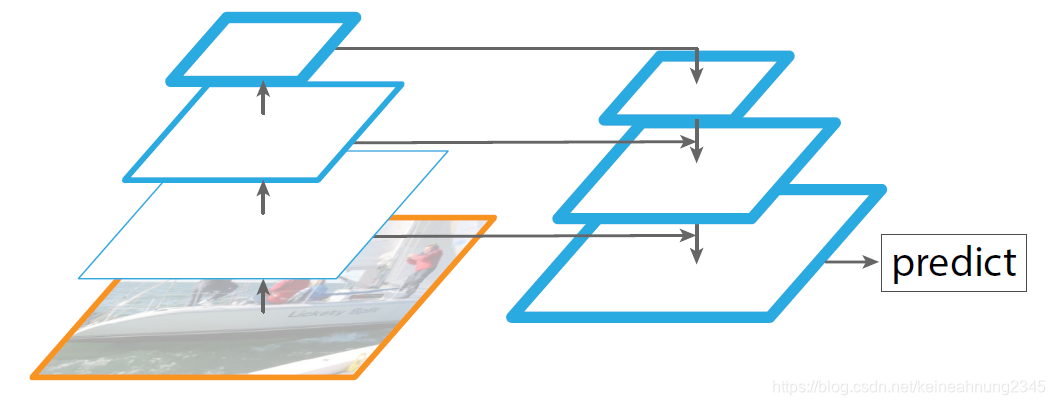
然而FPN的方法是在每一層都做預測。
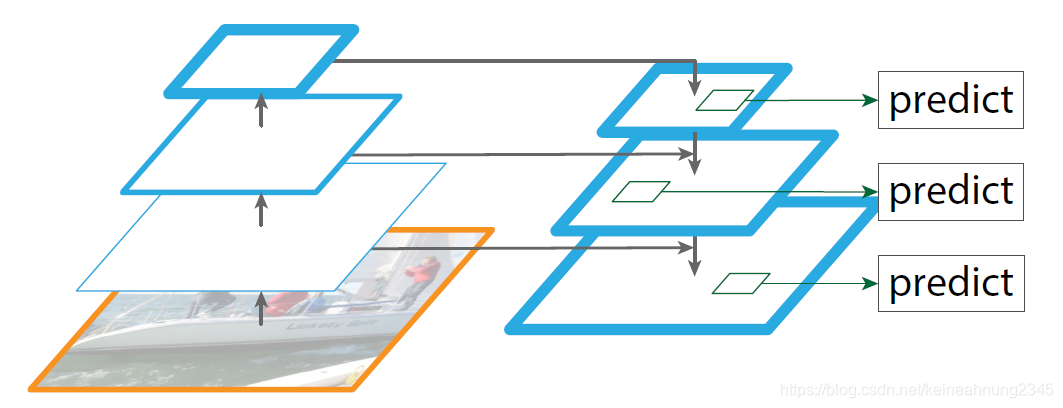
FPN在訓練及測試時的使用方式是一致的,而這點在featurized image pyramids由於內存的限制是不可行的。
(2)相關方法
使用Hand-engineered features及早期的NN
- 先建立featurized image pyramids,然後抽取其SIFT或HOG特徵
- 先建立featurized image pyramids,然後用淺層的ConvNet來抽取特徵
使用深度CNN來做物體偵測
- OverFeat:先建立image pyramid,再使用CNN以sliding window的方式來檢測目標
- R-CNN:先用Selective Search的方法得到候選框,normalize之後再使用CNN來做識別。以上兩種做法比起更早之前的做法有大幅的進步。
- Fast R-CNN及Faster R-CNN:因為速度的考量,只使用了從單一尺度抽取的特徵
使用多層特徵
- U-Net:使用了skip-connection及lateral-connection,這考慮了不同分辨率及擁有不同語義信息的feature maps。
(3)FPN架構
FPN的輸入是一張任意大小的圖片,輸出則是由多level的feature maps組成的feature pyramid。
FPN包含了三部份,分別是bottom-up pathway,top-bottom pathway以及lateral connection,以下逐一介紹。
Bottom-up pathway
- Bottom-up pathway直接採用了backbone ConvNet的前向傳播計算,而此處以ResNet為例。
- ResNet中的層可以依其輸出feature map的長寬被分到stage裡,而同一個stage裡的層都輸出相同大小的feature。ResNet共有5個stage,分別被命名為conv1~conv5,而每個stage最後一層的輸出則被稱作C1~C5。
- 這裡採用了C2~C5來建構pyramid,其中C1因為佔用內存太大而未被使用。
- 注意到此處C2~C5的feature maps,他們相對於輸入圖片的stride分別是4,8,16及32。(C1經過一次stride為(2,2)的Conv2D跟一次stride同為(2,2)的MaxPooling2D,而stage 2則未改變輸入圖片的長寬。)
Top-down pathway
- 這一條pathway會對feature map進行上採樣,來提升高語義信息的feature map的(幻想的)分辨率。
Lateral connection
- Lateral connection將bottom-up pathway中(高分辨率的)feature map及top-down pathway中(高語義信息的)同樣大小的feature map合併起來。
整體架構
將上述的三個部份合起來就成為了FPN。
而合併的方法比較特別,合併的具體方式可以參考下圖:
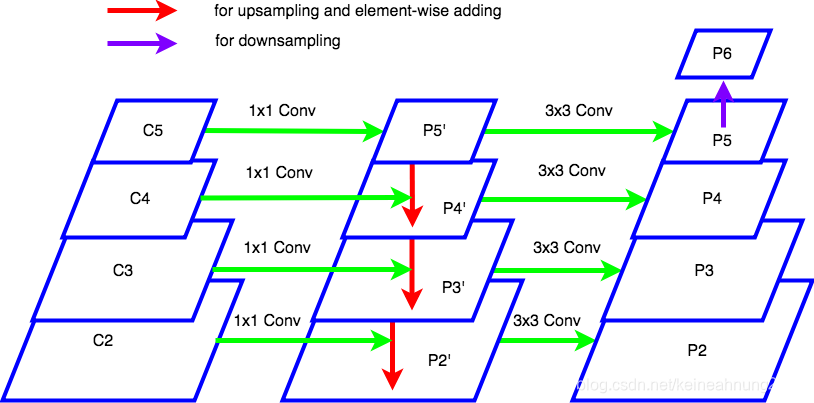
註:本圖為筆者參考Mask R-CNN代碼(matterport版本)後所繪。論文原圖並沒有P2’~P5’,此處為了說明方便而將中間結果畫出來。代碼研讀筆記可以參考Mask_RCNN代碼研讀(matterport版本)系列文(二)- Feature Pyramid Network部份。
從這張圖我們可以看到:
- 輸入是從ConvNet回傳的C2~C5,而輸出則是P2~P6。
- 在bottom-up pathway上的C2~C5首先會經過1x1 convolution來減少channel數。
- P5’在nearest neighbor upsampling後與經過1x1 convolution的C4逐元素相加成為P4’。P3’與P2’也是經過相似的過程得到。
- 經過top-down pathway得到P5’~P2’後,再使用3x3 convolution(沒有加nonlinearity)得到P2~P5。
- P6是由P5做downsampling而來。
關於為何P4’是經由逐元素相加而來,以及為何要在P5’~P2’後加上3x3 convolution,筆者有些疑惑。文末的問題討論中寫中了筆者自己的想法,希望各路大牛們也能一起參與討論。
要記住FPN是用來抽取特徵用的,而抽取出的P2~P5隨後會再送進預測類別或位置的頭部。而這些用來做預測的模型頭部是共享的。所以P2~P5這幾個feature map的channel數必須一致,而在論文中將這個超參數d設為256。
作者嘗試過在FPN裡加入類似ResNet的連接方式,但是效益不大,所以FPN還是保留原本較簡單的架構。
作者嘗試過在3x3 convolution後加上nonlinearity,但是幾乎沒有什麼作用。
(4.2)將FPN應用於Fast R-CNN
論文中是先講述Faster R-CNN再講Fast R-CNN,這邊則考慮了兩種模型出現的先後,將兩者的順序調換過來。
Fast R-CNN
網路架構
簡述一下Fast R-CNN的網路架構。
輸入圖片首先經過Deep ConvNet變成feature map。
然後會使用selective search的方式從feature map生成候選框(即RoI)。
這些RoI經過RoI max pooling layer後會變成固定大小的feature map。
這些固定大小的feature map再經過兩層全連接層得到一個RoI feature vector。
這個feature vector最後會被送到classifier及regressor得到它包含有物體的機率及bounding box的offset。
Fast R-CNN + FPN
獲取RoI
RoI的獲取仍與原來的步驟相同,即使用selective search得到。
將RoI分配到feature pyramid上
因為Fast R-CNN的設計是只在單一scale上做預測,所以對於單一個RoI,我們不會用到所有的pyramid level,而是依據它的長寬為它指定一個特定的level。
論文中依據以下公式將寬高為
w
,
h
w,h
w,h的RoI指定到
P
k
P_k
Pk:
k
=
⌊
k
0
+
l
o
g
2
(
w
h
224
)
⌋
k = \lfloor k_0 + log_2(\frac{\sqrt{w}{h}}{224}) \rfloor
k=⌊k0+log2(224wh)⌋
,其中
k
0
=
4
k_0=4
k0=4。
式中的224是由於ImageNet的圖片大小為224*224。
參照Faster R-CNN的論文,它只使用
C
4
C_4
C4這個feature map,所以我們設
k
0
=
4
k_0=4
k0=4,代表224*224大小的RoI將會被對應到
P
4
P_4
P4。
根據公式,對於較小的RoI,我們會將其指定到較低層的feature map。
例如有一個RoI大小為112*112,我們會將它指到到
P
3
P_3
P3。
這意味著如果一個RoI比較小,我們會傾向使用較高分辨率的feature map?
RoI max pooling + FC*2 + classifier/regressor
得到RoI後,RoI會經過RoI max pooling變成7*7的大小,然後再經過兩層FC+ReLU變成一個1024為的向量,最後才進入classifier跟regressor。
classifier跟regressor會被加到feature pyramid的所有level上。而它們的參數對於feature pyramid中的每一層來說是共享的。
(4.1)將FPN應用於RPN
Region Proposal Network(RPN)是使用類似sliding-window的方式來做目標檢測,它跟selective search的功能相近,都是用於提出候選框(Region of Interest,RoI),以供模型的下一階段使用。
而RPN是出自Faster R-CNN這篇論文,所以下面將比較Faster R-CNN與經此篇論文修改過後的Faster R-CNN + FPN。
Faster R-CNN
RPN網路架構
RPN包含一個3x3 Conv接著兩個並列的1x1 Conv做分類(有無物體)及回歸(物體位置),這個部份又叫做network head。
RPN的輸入
在Faster R-CNN(RPN的出處)中,RPN是建立在單一尺度的feature map上的。
我們會在feature map上預先定義各種尺度及寬高比的anchors。
這些anchors會接著被送進RPN。
Faster R-CNN + FPN
RPN網路架構
此處RPN(network head)的架構跟原來一樣。
而要將FPN應用於RPN,這裡所做的修改就是將RPN建立在FPN輸出的feature pyramids上。
RPN的輸入:準備anchors
在Fast R-CNN中,selective search扮演了提出候選框的角色。
Faster R-CNN捨棄了selective search,改用預先定義好的anchors。
這些anchors做為RPN的輸入,我們要讓RPN學習的是判斷某個anchor是否包含物體,如果有的話,則還需要學出物體的包圍框。
在監督式學習中,是需要有標籤的。所以我們還得為每個anchor加上它是否包含物體的標籤。
定義anchor的scale及aspect ratio,並將它們分配到feature pyramid上
我們會預先定義anchors,並且為它們加上標籤(positive, neutral, negative)來訓練RPN。
因為network head會在FPN輸出的feature map(
P
2
P_2
P2~
P
6
P_6
P6)移動,所以我們不需要再為同一個pyramid level設置多個scale的anchors。
相反地,我們在
P
2
P_2
P2,
P
3
P_3
P3,
P
4
P_4
P4,
P
5
P_5
P5及
P
6
P_6
P6等不同的feature map上分別定義了面積為
3
2
2
32^2
322,
6
4
2
64^2
642,
12
8
2
128^2
1282,
25
6
2
256^2
2562,
51
2
2
512^2
5122像素點的anchors 。
即,面積較小的anchors是由較低層(較大,較高分辨率)的feature map負責。這種分配方式與上面Fast R-CNN + FPN中的指定方式有異曲同工之妙。
這樣一來,單一pyramid level上現在就只有單一尺度的anchors。
另外在每個pyramid level,我們還會定義3種不同aspect ratio({1:2,1:1,2:1})的anchors,用來捕捉不同寬高比的ground truth boxes。
指定anchors的標籤
接著就是為這些anchors加上標籤,根據以下規則:
- positive anchors:
- 它與某個ground truth box有最高的IoU
- 它與某個ground truth box有高於0.7的IoU
- negative anchors:
- 它與每個ground truth box的IoU都低於0.3
- neural anchors:
- 非上述兩種情況者
- 不會拿來做訓練
Note: ground truth boxes是輸入圖片中,物體存在的位置。ground truth boxes會先依其位置、大小和寬高比被指定到某個anchor,而anchor又會依據上述的規則被分配到各自的pyramid level上。
共享頭部
輸入圖片在經過FPN及RPN後會變成RoIs(Region of Interest),我們可以注意到RoI有可能是從FPN的任一層出來的。照理說不同scale的RoI應該要使用不同的classifier及regressor,但是作者在這裡做了一個實驗:他只使用了一個共享權重的head,來跟為每一層都訓練不同的head做比較。結果顯示兩者的差異並不大,這可以說明一個現象,即:
all levels of our pyramid share similar semantic levels
(5)效果
RPN Region proposal的效果變化
只使用C4或C5 v.s. 使用FPN

我們可以看到比起(a)
C
4
C_4
C4,(b)較高層的
C
5
C_5
C5表現的還差一點,這是因為
C
5
C_5
C5為了語義訊息而犧牲了分辨率,最終結果是導致AR下降。
(c)比起只使用
C
4
C_4
C4或
C
5
C_5
C5,使用FPN使得AR大幅上升,並且對於小物體的效果十分顯著。這是因為FPN不僅包含了高層的feature map,也將低層高分辨率的feature map納入,因而能有效地識別小物體。
top-down enrichment的重要性

(d)的結果顯示的是不使用top-down pathway,而是把bottom-up pyramid上的feature map經過lateral connection(1x1 convolution)及3x3 convolutions後建成的pyramid。
我們可以看出這個結果只比只使用
C
4
C_4
C4或
C
5
C_5
C5好一些,並且遠不如FPN。論文作者猜測是因為bottom-up pyramid上的feature map有很大的semantic gap所造成的。
lateral-connection的重要性

(e)top-down pyramid上的feature map有高語義訊息,但是這並不夠。因為位置訊息在連續的下採樣及上採樣變得十分不準確,我們可以看到實驗結果甚至比baseline的
C
4
C_4
C4還差。
pyramid-representation的重要性
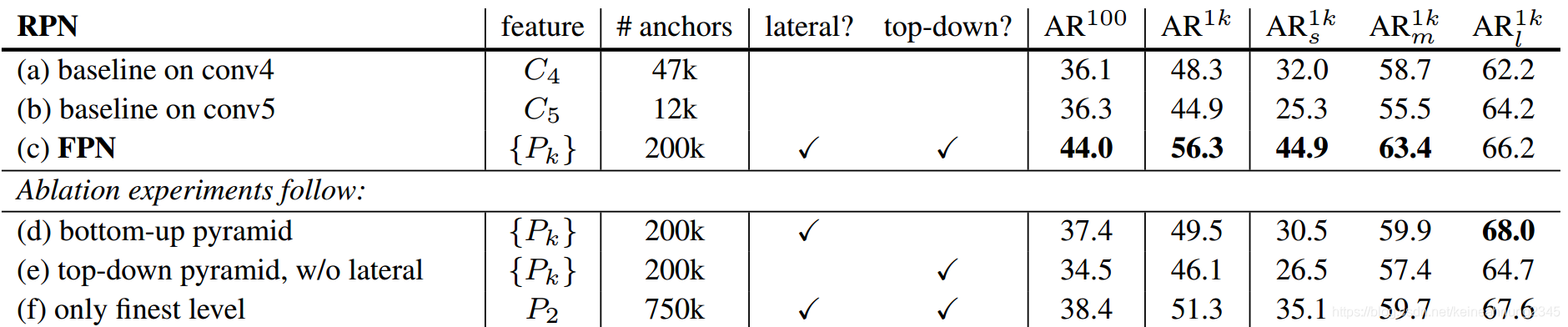
(f)顯示的是只使用高語義訊息且最高分辨率的
P
2
P_2
P2來預測的結果,我們可以看到它的表現仍遠不及FPN。這是因為RPN只使用單一尺度的sliding window,如果不搭配feature pyramid使用的話,模型識別小物體的能力無法大幅提升。但其表現仍是所有結果中次好的。
Fast R-CNN物體偵測效果的變化
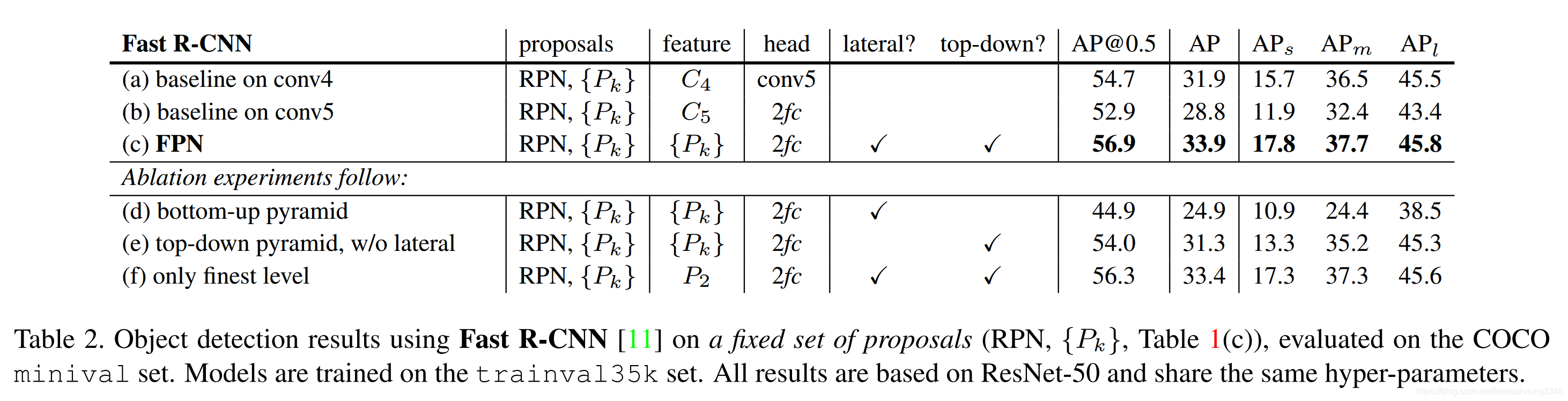
(a)是baseline,從C4這個feature map抽取RoI,經過conv5後再輸入network head。
(b)改從C5抽取RoI,經過FC*2後輸入network head。這個結果比起(a)下降了一些,這代表使用FC*2並不一定會帶來準確率的提升。
(c)使用FPN結果提升不少,代表FPN對region-based的物體偵測器是有效的。
(d)的準確率最差。這顯示了使用低語義訊息的特徵反而會傷害到Fast R-CNN的表現。
(e)移除了lateral connection。這也會使得Fast R-CNN對小物體的辨識能力下降。並且其表現不如baseline的(a)。
(f)的表現是六個實驗當中次好的。這是因為P2是feature pyramid的一部份,所以feature pyramid在這個實驗仍然發揮了作用。
Faster R-CNN物體偵測效果的變化

(*)是ResNet論文中發表的結果。
(a)是論文作者復現ResNet的結果,因為使用了較高規格的配置,所以準確率才會上升。
(b)跟上面Fast R-CNN的結果類似,多了FC*2反而會傷害模型的表現。
(c)跟上面Fast R-CNN的結果類似,使用FPN能讓模型表現大幅提升。
共享RPN及Fast R-CNN的權重
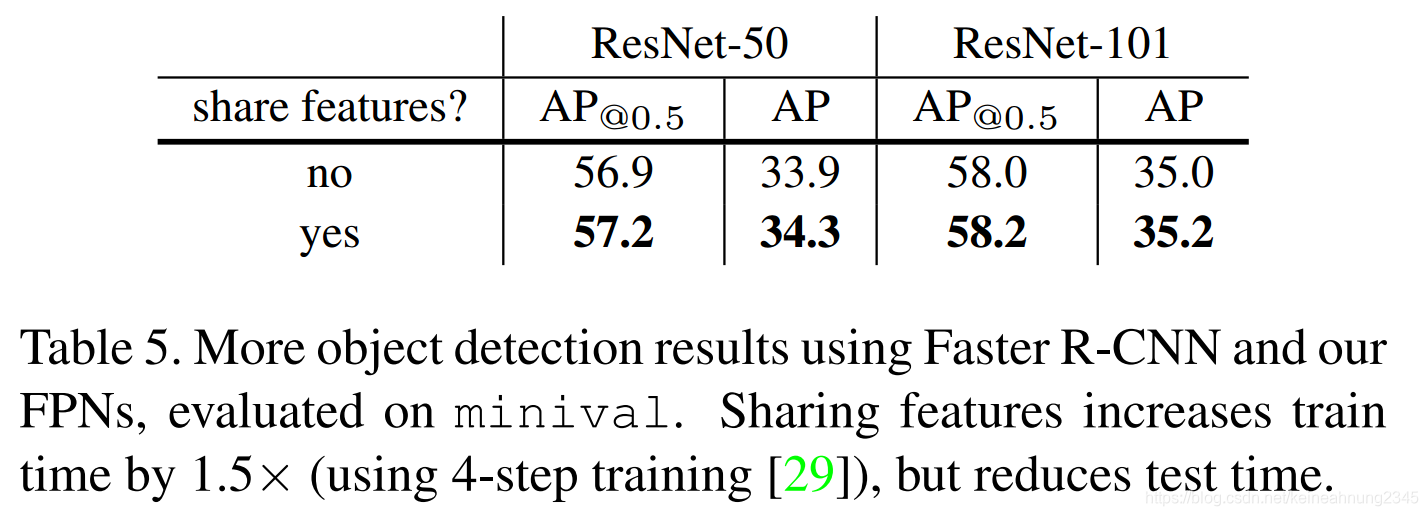
共享RPN及Fast R-CNN的權重可以提升些許準確率,也可以縮短測試時間。
在COCO比賽上的表現
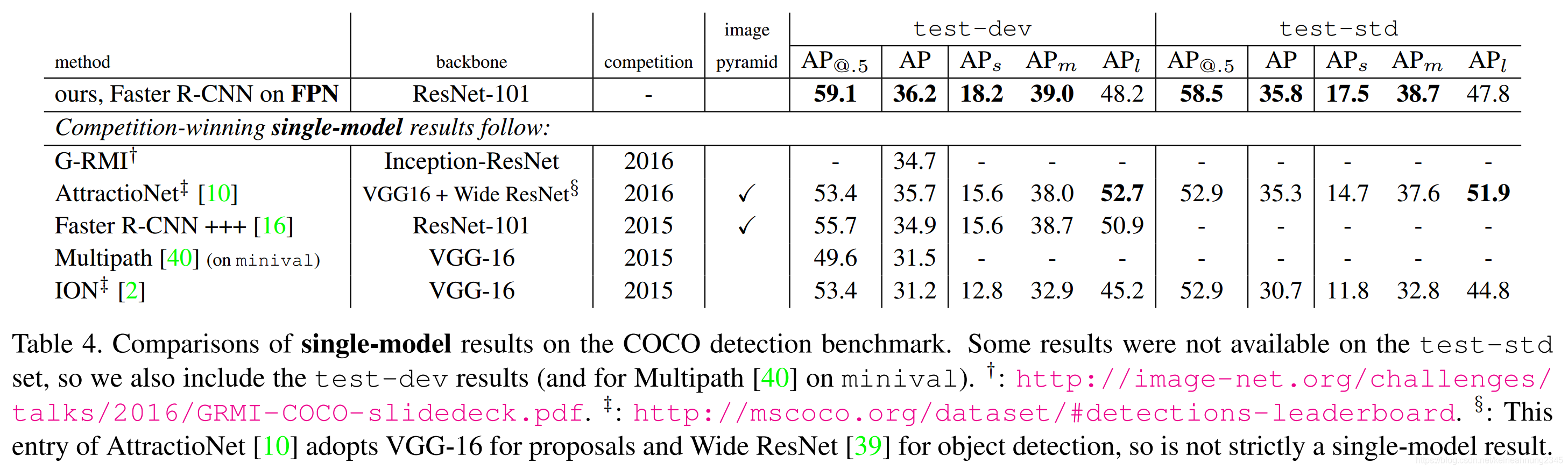
FPN並未使用image pyramid,iterative regression, hard negative mining, context modeling, stronger data augmentation等方法就取得比COCO比賽冠軍更優的結果。
Segmentation Proposals的效果變化
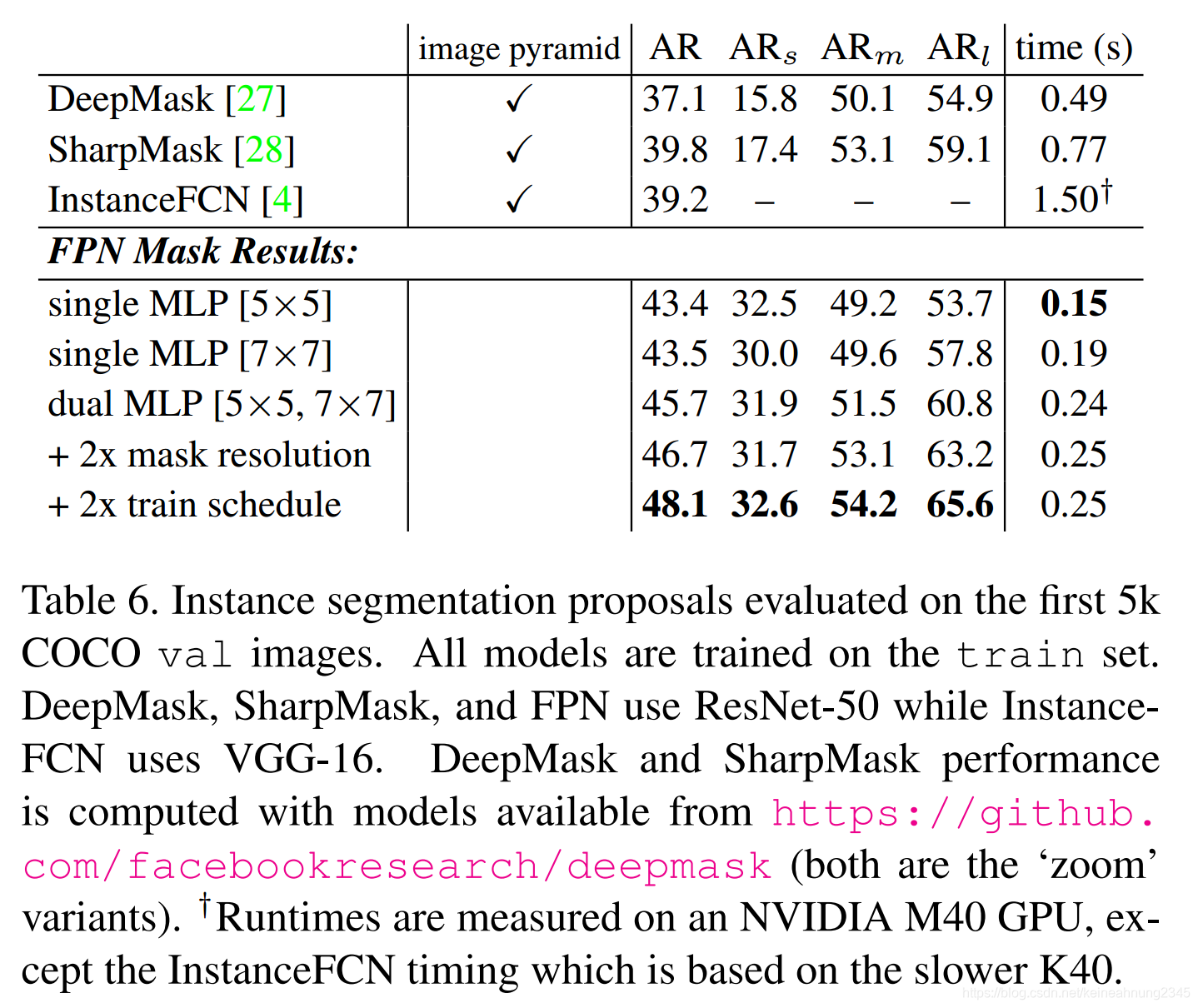
將FPN應用於DeepMask/SharpMask可以讓AP提升8.3%,對小物體的辨別能力則將近達到兩倍。
這顯示了FPN是可以作為通用的特徵提取器來使用的。而且在多尺度目標檢測的領域中己經可以取代image pyramids的角色。
問題討論
為何在計算top-down pathway上的feature map時是將bottom-up pathway上feature map與上一層的結果逐元素相加?
- ResNet中將shortcut輸出的feature map與主幹的輸出進行逐元素相加,這是因為主幹裡學習的是殘差。
- 難道此處也是殘差的概念?
- 如果不是的話用逐元素相加的方式難道不會破壞掉抽取到的feature?
為何得到P2’~P5’後,還要再做3x3 Convolution?
-
引自論文原文:
we append a 3×3 convolution on each merged map to generate the final feature map, which is to reduce the aliasing effect of upsampling.
筆者不是很明白這句話的意思,於是上網查了一些aliasing effect的相關資料。
-
Lecture 2.2 – Image Processing Image Pyramids提到aliasing effect是由於downsampling產生???
這與論文裡描述的並不一致,論文裡的aliasing effect是因為upsampling才發生的。 -
為了確認論文描述的正確性,筆者找到了這篇文章Upsampling and Aliasing?。討論串中有一段
Distortion during upsampling is called imaging. It means creation of frequency components above 1/2 sampling rate of the original signal. Sometimes it is also considered to be a form of aliasing.
它淺顯地說明了由upsampling所造成的失真情況應該叫imaging,但是在某些情況我們也可以將之稱為aliasing。從這裡看來,論文裡的描述並沒有錯,只不過是用了一種不同的說法。
-
來看看imaging的詳細介紹。據Aliasing vs Imaging. What is imaging?這則問答的描述:
Imaging is from over-sampling duplicating the signal spectrum at harmonics of the sample rate according to the amount of sampling errors or false interpolation or in other cases intentional zeros added to the sample to up-convert the spectrum.
imaging是從oversampling(也可以理解為upsampling)而來,並且有以下幾個原因造成這個現象:採樣錯誤、錯誤的內插值或者是由zero padding所造成的錯誤。
-
接著繼續查找3x3 convolution是如何解決aliasing effect的。在Matlab的Multirate Filters中,它提到了downsampling會造成aliasing的問題;而upsampling會造成imaging的問題(與上述連結描述一致)。而解決的方法如下所述:
Typically in decimation of a signal a filter is applied first, thereby allowing decimation without aliasing.
Conversely, a filter is typically applied after interpolation to avoid imaging.也就是說在upsampling之後我們通常會讓信號再經過一個濾波器來避免imaging的問題。
-
查查濾波器對過採樣的信號起到什麼樣的作用?在降采样,过采样,欠采样,子采样,下采样中,有這麼一段話:
过采样目的:就是要改变的噪声的分布,减少噪声在有用信号的带宽内,然后再通过低通滤波器滤除掉噪声,达到较好的信噪比。
綜上所述,我們可以了解到在upsampling之後會出現aliasing的問題(更準確地說是imaging)。而為了要解決這個問題,我們可以在upsampling後的信號加上一個(低通)濾波器,而這就是我們需要3x3 convolution的原因!
看來這年頭不懂信號處理的調參俠還真不是好的AI工程師!
為何在Fast R-CNN/Faster R-CNN + FPN中,是將較小的RoIs/anchors指定給較低層(較大)的feature map?
- P2 ~ P6相對於輸入圖片的stride分別是4,8,16,32及64
從感受野的角度來看,各pyramid上的RoIs/anchors的感受野差距會被擴大(?),這樣不會有不良影響?- 但從feature map分辨率的角度來看,把小的RoI分配給低層的feature map就利用了低層feature map的高分辨率,因此這或許是一個合理的設置。
Lesson Learned
- 在做錯誤分析時可以分別計算小、中、大物體的AP。
- 使用ablation experiment可以查看模型各部份所發揮的作用。
- iterative regression(Object detection via a multi-region & semantic segmentation-aware CNN model), hard negative mining(Training Region-based Object Detectors with Online Hard Example Mining), context modeling(Deep Residual Learning for Image Recognition), stronger data augmentation(SSD: Single Shot MultiBox Detector)等方法或許可以進一步提升模型的表現。
參考連結
Feature Pyramid Networks for Object Detection論文連結
Lecture 2.2 – Image Processing Image Pyramids
Upsampling and Aliasing?
Aliasing vs Imaging. What is imaging?
Matlab的Multirate Filters
降采样,过采样,欠采样,子采样,下采样
Mask_RCNN代碼研讀(matterport版本)系列文(二)- Feature Pyramid Network部份


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









