









Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks論文研讀與問題討論
前言
Faster R-CNN改良自Fast R-CNN,它將Selective Search改為RPN。
本篇介紹Faster R-CNN的架構及實作細節。
在研讀過程中碰到不太了解的地方,筆者有做了一些研究,將它們整理到問題討論章節中。
本篇亮點
- RPN - 全卷積的架構,用於生成候選框。可取代selective search。
- anchor - RPN生成候選框的基準
- (RoI Pooling/RoI Warping) - RoI Warping改良自RoI Pooling層,對候選框座標可微
簡介
SPPNet及Fast R-CNN使用selective search來生成候選框,這成為了計算上的瓶頸。
本篇論文提出了Region Proposal Network(RPN)這種生成候選框的方法,由於RPN與目標檢測網路共用了feature maps,所以它所需的只有額外的一點時間花費。並且這種方法還能提升整體的準確度。
RPN是全卷積的架構,它給出了候選框及該候選框包含物體的機率(objectness)。
本篇論文將RPN套用到Fast R-CNN上,告訴它應該"看"哪裡,這也就是所謂的注意力機制。
(1)背景介紹
共享卷積層
R-CNN的做法是為每個候選框計算它的feature maps,因此需要花費大量的時間。
透過在候選框間共享卷積層,SPPNet及Fast R-CNN所需的時間被大幅縮短,推論時的瓶頸就變為候選框的生成了。
生成候選框的方法
常用的生成候選框的方法包括Selective Search及EdgeBox。
在CPU上每張圖片Selective Search要花2秒。
在CPU上每張圖片EdgeBox要花0.2秒。
RPN簡介
本篇論文提出的Region Proposal Network(RPN)與detection networks共享了卷積層。
在每張圖片只要0.01秒。
RPN基於卷積層抽出來的feature maps,在上面加入數個卷積層,其結構屬於Fully Convolutional Network(FCN)。
這些卷積層負責回歸出物體的邊界及判斷該範圍內是否有包含物體。
多尺度目標檢測
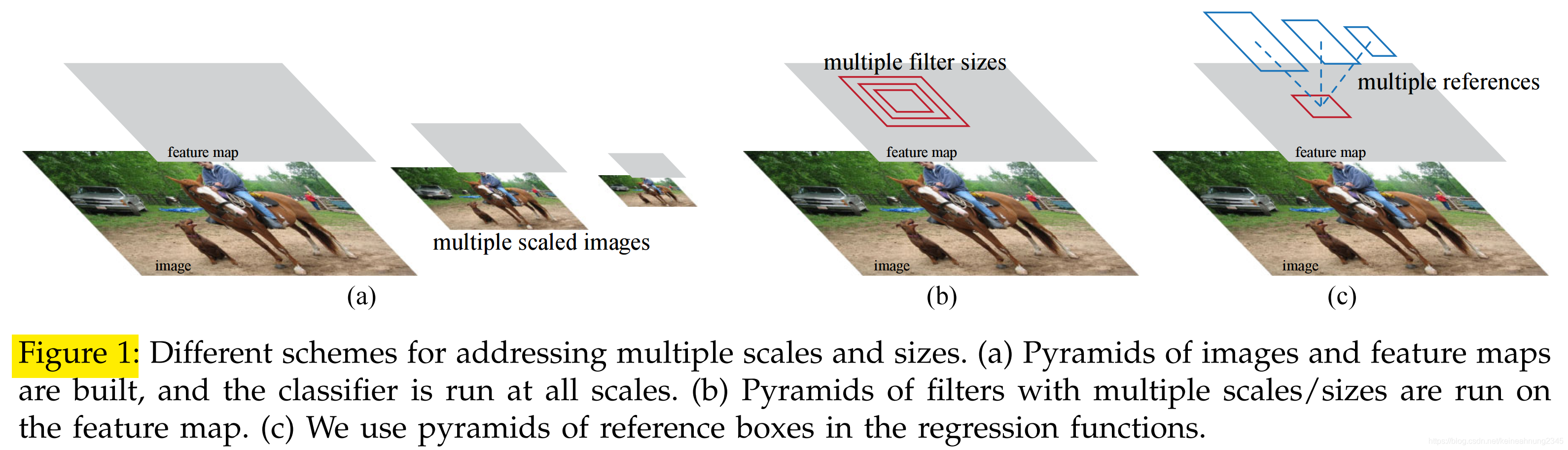
- 1(a) pyramid of images:Deformable Part Models (DPM)所採用的方法
- 1(b) pyramid of filters
- 1(c) pyramid of regression references —— anchors
在RPN出現之前,為了要處理多尺度目標檢測的問題,人們使用的是1(a)及1(b)這兩種方法。
1(a)是列舉了各種大小的圖片,1(b)則是列舉了各種大小的filter,因此速度會受到很大的影響。
而1(c)這種方法就不需要計算多張feature maps,模型速度因此得以提升。
模型表現
在PASCAL VOC上,使用RPN的Fast R-CNN生成候選框的時間約為10毫秒,總時間則為0.2秒。
它不管在速度或準確率方面都擊敗了使用Selective Search的Fast R-CNN。
RPN跟一般的神經網路一樣,是從大量數據中學習特徵。
因此如果使用更多層的backbone(如:ResNet101),RPN也能從中受益。
(2)相關方法
二階段的目標檢測通常包含:1.生成候選框,2.做分類及回歸的深度神經網路 這兩個部份。
以下分別介紹這兩個部份的相關方法。
生成候選框的方法
- 基於為super-pixel分組:Selective Search, CPMC, MCG
- 基於移動滑窗:EdgeBox, objectness in windows
R-CNN,Fast R-CNN採用了Selective Search(SS),而SS在這種架構中是獨立於detector的。
目標檢測(使用深度神經網路)
R-CNN的角色主要功能在於分類,物體邊界的提出主要是由SS來達成(但R-CNN稍後還會微調候選框的位置)。
OverFeat,SPPNet,Fast R-CNN共享卷積層的計算,相比R-CNN提升效率提升了不少。
(3)Faster R-CNN
Faster R-CNN便是上述二階段目標檢測方法的一種。
它由 1.全卷積的Region Proposal Network(RPN)及 2.Fast R-CNN detector 這兩部份所組成。
RPN的作用是生成候選框,即注意力機制,它負責告訴Fast R-CNN該關注哪個位置。
以下是Faster R-CNN的架構圖:

接下來會先介紹RPN(3.1),然後是Fast R-CNN detector(3.2),最後則是一些實作上的細節(3.3)。
3.1 Region Proposal Network
RPN的輸入是任意大小的圖片,輸出則是多個候選框及它們各自的objectness(即包含有物體的分數)。
RPN與Fast R-CNN中用來抽取特徵的CNN backbone是共用的,這裡作者嘗試了兩種模型:ZF Net及VGG-16。
CNN backbone會輸出feature map。
RPN的頭部會以大小為n x n(論文中設n=3)的視窗在CNN backbone輸出的feature map上滑動,
經過激活層ReLU之後,產出一個256維(ZF Net)或512維(VGG-16)的向量。
注意到:
如果使用的是ZF Net,那麼在輸入圖片上的有效感受野便是171,如果是VGG-16,有效感受野則是228。
(↑問題討論中有說明)
這個向量接著被送進:1.cls layer及2.reg layer這兩個由全連接層構成的子網路裡。
下圖左即為RPN的架構。

有一點要注意的是,因為cls layer及reg layer是在feature map上滑動的,所以它們的權重是被feature map上的所有位置共享的。
RPN head的實作方式是n x n的卷積層跟著2個(cls及reg)並列的1 x 1卷積層(注意不是用全連接層),代碼部份詳見Mask_RCNN代碼研讀(matterport版本)系列文(三)- Region Proposal Network部份。
3.1.1 Anchors
前面提到過Faster R-CNN處理多尺度目標檢測問題的方式是使用"pyramid of regression references",也就是這裡要介紹的anchors。
RPN head使用滑動視窗的方式在CNN backbone輸出的feature map上做掃描。
在掃過的每個位置上,會挑選 3種尺度 x 3種寬高比 共k(=9)個anchors,生成k個候選框。
所以cls layer(二分類softmax layer)會有2k個輸出,說明該候選框是否包含物體;
為何classifier head要輸出2*k個值,而非k個值就好?
而reg layer則會有4k個輸出,這代表了候選框的位置。
而對於一個寬為W,高為H的feature map來說,總共會有W x H x k個anchors(候選框)。
其中W x H約為2400。
平移不變性
這裡說的平移不變性包括了anchor本身及RPN這個輸入為anchors,輸出為建議框的"函數"。
對anchor來說:如果一個物體在圖片中的位置不一樣了,同樣找得到anchor與它做配對,只不過是換了一個anchor而己。
對RPN來說:RPN對不同位置來的anchors都一視同仁,所以即使換了個anchor,它同樣能做出相同的預測。
總結一下,如果物體在輸入圖片中移動了,proposal也會跟著物體的位置移動,並且RPN同樣也可以做出同樣的預測。
注:MultiBox不具有平移不變性。
因為具有平移不變性,所以網路頭部對不同位置(滑動視窗在feature map上滑到的位置)上的anchors可以共享。
而這又帶來了另外一個好處:參數量可以大幅減少。
這裡拿MultiBox做為比較的基準,先看全連接層兩者的參數量比較:
| 全連接層 | CNN Backbone | 輸入 | 輸出 | 大小 |
|---|---|---|---|---|
| MultiBox | GoogleLeNet(InceptionV1)? | 1536 | (4+1) x 800 | 1536 x (4+1) x 800 = 6.1 x 106 |
| Faster R-CNN | VGG16 | 512 | (4+2) x 9 | 512 x (4+2) x 9 = 2.8 x 104 |
全連接層有兩個數量級的差距。
再看卷積層的比較:
| feature projection layer | CNN Backbone | 輸入 | 輸出 | kernel size | 大小 |
|---|---|---|---|---|---|
| MultiBox | GoogleLeNet(InceptionV1)? | 64 + 96 + 64 + 64 | 1536 | 7 x 7 | 7 x 7 x (64 + 96 + 64 + 64) = 2.1 x 107 |
| Faster R-CNN | VGG16 | 512 | 512 | 3 x 3 | 3 x 3 x 512 x 512 = 2.3 x 106 |
同樣也是有很懸殊的差距。
使用多尺度的anchors處理多尺度目標檢測的問題
比較一下三種處理多尺度目標檢測問題的方法:
- image/feature pyramid:
- 由多尺度的輸入圖片得到多尺度的feature map
- DPM, OverFeat, SPPNet, Fast R-CNN
- 有用但太花時間
- pyramid of filters:
- 在同一張feature map上使用多尺度/多寬高比的滑動視窗
- DPM
- pyramid of anchors
- 使用單一尺度的輸入圖片,單一大小的filter
- 得到單一大小的feature map
- 多尺度的anchors共享同一張feature map
- Faster R-CNN
- 最有效率的方法
3.1.2 Loss Function
訓練RPN的資料是要我們自己準備的,所以我們得為每個anchor加上標籤,用以訓練cls layer。
而被指定為正樣本的anchor會被指定到它所屬的ground truth box上,作為reg layer的訓練樣本。
為anchors指定標籤
- positive
- 它與某個ground truth box的IoU高於0.7(主要) 或者是
- 它與某個ground truth box有最高的IoU(備用)
- negative
- 非positive 及
- 它與每個ground truth box的IoU皆低於0.3
- neutral
- 非上述兩者的
- 不貢獻到loss
要注意的是一個ground truth box可能會對應到多個anchors,而每個anchor最多只可能對應到1個ground truth box。
公式
L
(
{
p
i
}
,
{
t
i
}
)
=
1
N
c
l
s
∑
i
L
c
l
s
(
p
i
,
p
i
∗
)
+
λ
1
N
r
e
g
∑
i
p
i
∗
L
r
e
g
(
t
i
,
t
i
∗
)
L(\{p_i\}, \{t_i\}) = \frac{1}{N_{cls}} \sum_i L_{cls}(p_i, p_i^*) + \lambda \frac{1}{N_{reg}} \sum_i p_i^*L_{reg}(t_i,t_i^*)
L({pi},{ti})=Ncls1i∑Lcls(pi,pi∗)+λNreg1i∑pi∗Lreg(ti,ti∗)
這個公式計算的是單個mini-batch的loss。
等號左側,
L
L
L的參數是
{
p
i
}
\{p_i\}
{pi}及
{
t
i
}
\{t_i\}
{ti}。
其中
{
p
i
}
\{p_i\}
{pi}表示的是由RPN的cls layer所預測出,當前mini-batch裡所有anchor的objectness。
而
{
t
i
}
\{t_i\}
{ti}表示的是當前mini-batch裡所有anchor,被RPN的reg layer所微調後的位置。
下標i表示的是該anchor在當前mini-batch裡的次序。
等號右側有兩項,分別為分類及回歸的loss,這種做法稱為multi-task loss。
分類的loss
第一項是關於分類的loss:
∑
i
L
c
l
s
(
p
i
,
p
i
∗
)
\sum_i L_{cls}(p_i, p_i^*)
∑iLcls(pi,pi∗)
p
i
p_i
pi指的是RPN所預測出,該anchor包含有物體的機率。
p
i
∗
p_i^*
pi∗則是標籤,如果anchor包含物體的話為1,如果是背景的話則為0。
L
c
l
s
L_{cls}
Lcls計算兩個類別的log loss(聽著有點陌生,這是什麼?)。
回歸的loss
第二項是關於回歸的loss:
∑
i
p
i
∗
L
r
e
g
(
t
i
,
t
i
∗
)
\sum_i p_i^*L_{reg}(t_i,t_i^*)
∑ipi∗Lreg(ti,ti∗)
其中
L
r
e
g
(
t
i
,
t
i
∗
)
L_{reg}(t_i,t_i^*)
Lreg(ti,ti∗)是
R
(
t
i
−
t
i
∗
)
R(t_i-t_i^*)
R(ti−ti∗),即robust loss function,也就是在Fast R-CNN論文中提出的smooth L1 loss。
描述anchor應該是用
x
x
x,
y
y
y,
w
w
w,
h
h
h,到這裡怎麼變成
t
t
t了呢?
這就得提到在R-CNN論文中提到的參數化法。
參數化法(x, y, w, h → t_x, t_y, t_w, t_h)
Faster R-CNN沿用R-CNN裡提出的參數化法:
原來我們是用
x
x
x,
y
y
y,
w
w
w,
h
h
h來表示一個anchor。其中
x
x
x,
y
y
y代表box中心的座標,
w
w
w,
h
h
h代表box的寬及高。
先看公式:
t
x
=
(
x
−
x
a
)
/
w
a
,
t
y
=
(
y
−
y
a
)
/
h
a
t
w
=
log
(
w
/
w
a
)
,
t
h
=
log
(
h
/
h
a
)
t
x
∗
=
(
x
∗
−
x
a
)
/
w
a
,
t
y
∗
=
(
y
∗
−
y
a
)
/
h
a
t
w
∗
=
log
(
w
∗
/
w
a
)
,
t
h
∗
=
log
(
h
∗
/
h
a
)
t_x = (x − x_a)/w_a, t_y = (y − y_a)/h_a \\ t_w = \log(w/w_a), t_h = \log(h/h_a) \\ t_x^* = (x^∗ − x_a)/w_a, t^∗_y = (y∗ − y_a)/h_a \\ t_w^* = \log(w^∗/w_a), t^∗_h = \log(h^∗/h_a)
tx=(x−xa)/wa,ty=(y−ya)/hatw=log(w/wa),th=log(h/ha)tx∗=(x∗−xa)/wa,ty∗=(y∗−ya)/hatw∗=log(w∗/wa),th∗=log(h∗/ha)
這裡用下標
a
_a
a的
x
x
x,
y
y
y,
w
w
w,
h
h
h來表示anchor box;用上標
∗
^*
∗的來表示ground truth box;RPN reg回歸出來的box則不帶下標。
此處的參數化法可說是對predicted box及ground truth box對anchor正規化的過程:
將座標
x
x
x(
y
y
y)正規化的方式是先計算該座標與anchor中心的距離,再除以anchor的寬(高)。
將寬高
w
w
w(
h
h
h)正規化的方是是先計算其與anchor寬(高)的商,然後再取對數。
正規化後,回歸的ground truth變成了"ground truth box與anchor box間的差距"。
這時候RPN reg layer是以某個anchor為基準,而它學習的是"要將anchor box做多少改變,才能變成ground truth box",可以把它想成是將anchor box修正為ground truth box的過程。
接下來看
L
r
e
g
(
t
i
,
t
i
∗
)
L_{reg}(t_i,t_i^*)
Lreg(ti,ti∗)這一項。
它是先算出RPN reg layer預測出來的box與ground truth box之間的差,然後再帶入smooth L1 loss。
以下介紹smooth L1 loss。
smooth L1 loss
在Fast R-CNN論文中定義的smooth L1 loss公式如下:
s
m
o
o
t
h
L
1
(
x
)
=
{
0.5
x
2
,
if
∣
x
∣
<
1
,
∣
x
∣
−
0.5
,
otherwise
.
smooth_{L1}(x) = \begin{cases} 0.5x^2, & \text{if } |x| < 1, \\ |x| - 0.5, & \text{otherwise}. \end{cases}
smoothL1(x)={0.5x2,∣x∣−0.5,if ∣x∣<1,otherwise.
以下是的smooth L1 loss與L2 loss的對比圖:

可以看到,如果使用smooth_l1_loss,絕對值較大的
x
x
x的影響力會下降。
從這裡可以看出這個loss的設計理念,也就是減低outlier的影響。
公式裡還有一項 p i ∗ p_i^* pi∗,它的作用是什麼呢?
pi*的作用
在anchor為背景(不包含物體)的情況下,我們不應該將它的回歸誤差計入回歸的loss裡。
所以此處在
L
r
e
g
(
t
i
,
t
i
∗
)
L_{reg}(t_i,t_i^*)
Lreg(ti,ti∗)前乘上
p
i
∗
p_i^*
pi∗,就是表示只有在anchor裡包含物體的情況下,才會計入回歸的loss。
上面介紹了分類的loss及回歸的loss。而式中還有normalization term,以及用來調和兩項的 λ \lambda λ。
Normalization & Lambda
第一項關於分類的loss會除以
N
c
l
s
N_{cls}
Ncls,第二項關於回歸的loss會除以
N
r
e
g
N_{reg}
Nreg來做normalize。
另外還會加一個可調的參數
λ
\lambda
λ用來平衡這兩項的權重。
N
c
l
s
N_{cls}
Ncls為mini-batch的大小,即256。(參考3.1.3)
而
N
r
e
g
N_{reg}
Nreg為anchor的數量,約為2400。(參考問題討論 - ConvNet backbone輸出的feature map長x寬約為2400?)
在論文實驗中,預設
λ
\lambda
λ為10,如此一來,分類及回歸的loss便有了相近的影響力。
經作者實驗過後,發現模型對 λ \lambda λ的值不敏感。並且 N c l s N_{cls} Ncls, N r e g N_{reg} Nreg這兩個值是可以被省略的。
特徵抽取方式:與SPPNet及Fast R-CNN的比較
| SPPNet及Fast R-CNN | Faster R-CNN | |
|---|---|---|
| 特徵來源 | feature map上任意大小的RoI | feature map上固定範圍(3x3)的滑動視窗 |
| 權重是否被不同大小的RoI所共享 | 是 | 否,從滑窗範圍內選取9個anchors後,用k(=9)個regressor來學習 |
SPPNet及Fast R-CNN處理多尺度目標問題的方法是讓同一個reg layer從多尺度的RoI學習。
Faster R-CNN則使用了多組reg layer權重,每組權重只負責學習一種尺度(寬高比)的RoI。
3.1.3 RPN的訓練
RPN的訓練是透過反向傳播及SGD進行端到端的訓練。
image-centric sampling
此處沿用Fast R-CNN論文中image-centric的採樣方式。引自Fast R-CNN論文:
In Fast R-CNN training, stochastic gradient descent (SGD) minibatches are sampled hierarchically, first by sampling N images and then by sampling R/N RoIs from each image.
一個mini-batch是從一張圖裡選取多個anchor來組成(大小為256)。但是顯而易見的,image裡的負樣本遠多於正樣本。這裡為了避免負樣本主導學習過程,所以還額外做了一些改變。
此處的採樣方法是從每張image裡選取 正:負樣本比例為1:1,共256個anchors。
如果正樣本數量不足,則拿負樣本來補齊。
3.2 共享RPN及Fast R-CNN的權重
Faster R-CNN包含了RPN及Fast R-CNN兩個部份。
RPN用於提出建議框,而Fast R-CNN則利用這些建議框來做分類及回歸。
這兩個部份都有用到卷積層,本篇論文提出了幾種訓練方式,讓他們的卷積層能共享權重。
如下圖:

輸入圖片經過conv layers之後變成一張feature map。然後會分兩路。左側經過RPN得到數個建議框。右側及上方是Fast R-CNN,利用RPN輸出的建議框來從conv layers輸出的feature map中挑出需要關注的部份。
因為RPN及Fast R-CNN是分開獨立訓練的,為了避免共用的卷積層訓練發散,這裡提出了三種方式來處理。
輪流訓練
輸流訓練是本篇論文預設的訓練方式。
採用四步的輪流訓練:
- 使用在ImageNet上預訓練過的權重來初始化RPN,端到端地訓練RPN
- 使用在ImageNet上預訓練過的權重來初始化Fast R-CNN,並固定使用RPN輸出的建議框,訓練一個分離的Fast R-CNN
- 使用Fast R-CNN初始化RPN的參數,固定住Conv layers,僅微調RPN特有的層。在這一步兩個網路的conv layers己經共享了。(RPN的Conv layers在這一步被捨棄?)
- 固定住共享Conv layers的參數,微調Fast R-CNN特有的層
這4個步驟可以重複執行多次,但是從實驗看來並沒有多大差別。
近似的聯合訓練
在這個訓練過程中,Fast R-CNN與RPN被合併成一個網路(如上圖)。
在訓練Fast R-CNN的前向傳播過程,RPN的輸出被當成固定的、事先計算好的建議框。
在訓練共享的conv layers時,使用的是將來自RPN及Fast R-CNN的反向傳播訊號合併後的結果。
但是這種做法忽略了RPN loss對建議框座標的導數(這代表根本沒有訓練reg layer?),但是事實上建議框也是神經網路輸出的訊號。所以才說這種做法是近似的。
使用這種做法可以得到跟上面類似的結果,但是可以節省25%~50%的時間。
非近似的聯合訓練
下圖是Fast R-CNN的架構:

在Fast R-CNN中(Faster R-CNN亦同),RoI pooling layer(在Faster R-CNN中換成了RoI Warping)的輸入除了conv layers輸出的feature map外,還包含了RPN輸出的建議框。
這代表如果要做反向傳播的的話,我們需要一個能處理"loss對建議框座標的微分"的RoI pooling layer。
Instance-aware semantic segmentation via multi-task network cascades這篇論文中提出了RoI Warping,可以達成這個目的,但是這己超出本篇論文的範圍了。
注:Mask R-CNN延伸自Faster R-CNN,它使用RoIAlign取代了此處的RoIWarp。
3.3 實作細節
strides
PASCAL數據集中圖片原始大小為500*375,此處沿用Fast R-CNN裡的方式,將圖片的短邊reisize成600。
在resize過後的圖片上,ZF Net及VGG最後一層conv layer的stride都是16個pixels(詳見問題討論);
換算回去,在原圖上的stride為16/600*375約等於10個pixels。
即始是10個pixels這麼大的strides,都能得到如此的準確率。
論文中提到,如果把strides縮小,準確率或許還可以繼續提升。
anchors
使用大小為1282,2562,5122,寬高比為1:1,1:2,2:1共9種不同的anchors。

上圖是Faster R-CNN的預測結果。可以看到,即使未採用image pyramid或filter pyramid,這個方法還是可以很好地辨別多種尺度及寬高比的物體。
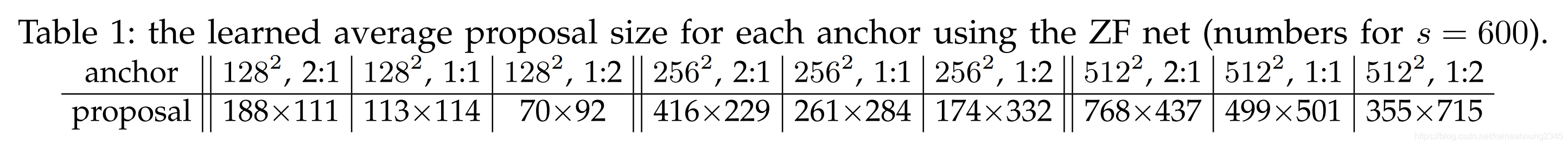
(這裡anchor尺度的單位似乎是在輸入圖片上的pixel。)
上表顯示的是使用ZF Net當backbone時,不同尺度及寬高比的anchor,他們所提出的建議框的平均大小。
從中可以看出一個anchor有能力預測出比它的感受野還大的建議框(
25
6
2
256^2
2562→
261
261
261x
284
284
284),作者解釋,這是因為人類也可以從一個物體的中心部位推算出該物體的邊界在哪裡。
超出邊界的建議框
一張大小為1000*600的圖在經過CNN backbone之後,會得到一張60*40的feature map。(上面提到了CNN backbone最後一層的stride是16。)(60*40可能是近似的算法,問題討論中算出來的是63*38)
因為feature map上的每個pixel會有9個anchors,所以對於一整張圖,我們會有60*40*9約為20000個anchors。
這20000個anchors中大概有6000個是不會超出邊界的,為了訓練的穩定性,論文中在訓練時將超出邊界的anchors都忽略掉。
但是在推論時會利用這些anchors產生的建議框,只不過會切除他們超出邊界的部份。
非極大值抑制
因為RRN輸出的建議框重疊太多,這裡使用Non-maximum suppression(NMS)的方法來將減少建議框的數量。
NMS是使用IoU=0.7的閾值,基於RPN的cls輸出的分數來做篩選。篩選過後剩餘約2000個建議框。
訓練時使用2000個建議框;測試時則選取前
N
N
N個建議框,實驗
N
N
N為不同值時的效果。
(4)實驗
4.1 在Pascal VOC數據集上的實驗
與SS,EB的比較

使用300個建議框的RPN+ZF 比 使用2000個建議框的SS或EB 結果要好。
並且因為1.權重共享 2.建議框數量較少,所以速度比前兩者快。
RPN的分離實驗
共享權重的效用
只執行4步的訓練過程中的前2步,這樣得到的就是分離的RPN及Fast R-CNN兩個網路,他們的conv layers權重並未共享。
分離網路的mAP為58.7%,低於權重共享時的59.9%。
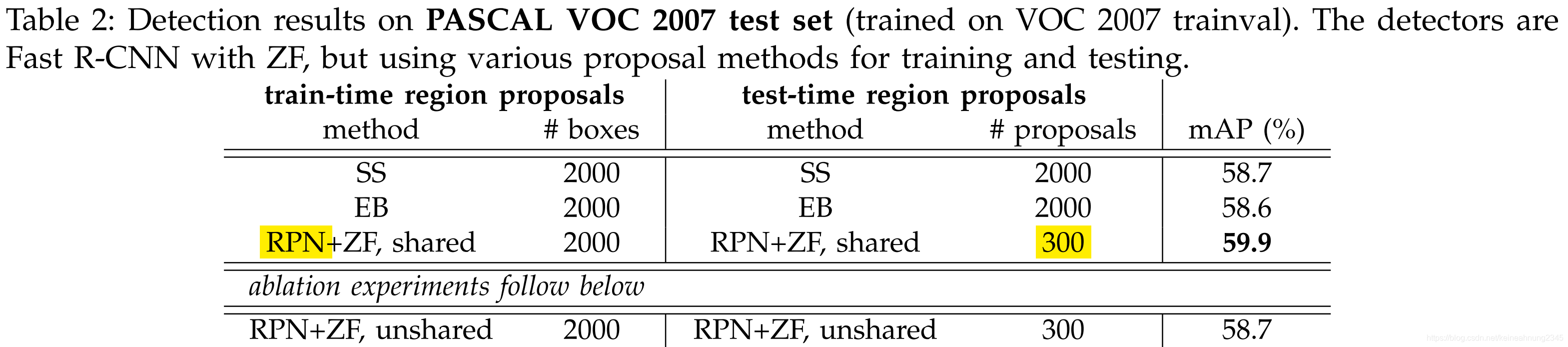
這是因為在第3步中,使用Fast R-CNN的feature來fine-tune RPN之後,RPN提出建議框的品質會提升。
RPN在訓練Fast R-CNN時的影響力
為了探討RPN在訓練Fast R-CNN時的影響力,在訓練時拿SS取代RPN,測試時則仍舊使用RPN。
訓練:使用2000個SS建議框+ZF Net來訓練Fast R-CNN。
測試:將SS替換成RPN(權重與Fast R-CNN不共享),得到56.8%的mAP,遠低於之前的59.9%。
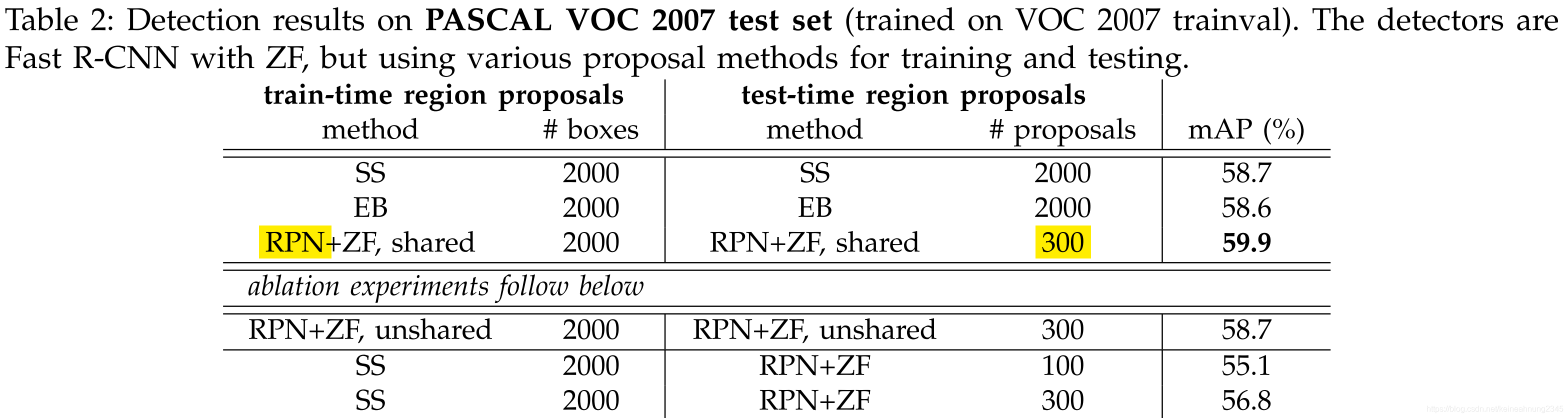
這是因為訓練及測試時的建議框不一致所導致。
建議框數量的影響

調低:把建議框數量由300調低成100,發現mAP仍在一定水準之上(56.8%→55.1%)。
這表示RPN建議框中confidence的排名是準確的。
調高:如果不使用NMS,或者提高建議框的數量,準確率竟然會下降(56.8%→56.3%, 55.2%)!
這說明NMS不但不會傷害模型的準確率反而因為能降低false-positive發生,因而提高mAP。
RPN的cls層的作用
RPN的cls層為k個anchors輸出共2k個前景/背景的分數。
因為NMS及anchor的排名都是基於cls層輸出的分數來實現的,如果將cls層拿掉,這兩個步驟也將變得無法實施。
所以拿掉cls層後,實驗中的100,300,1000個建議框都只是隨機選取的。

我們可以看到隨著建議框數量減小,mAP也跟著大幅下降。
從這個實驗中可以得到一個結論:cls層對排名高的建議框的準確率十分重要。
RPN的reg層的作用
RPN中reg層的作用是微調anchor,輸出建議框的座標。
拿掉reg層後,RPN輸出的建議框就是我們預先定義的anchors。
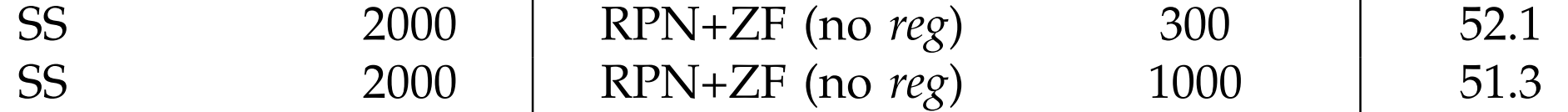
從實驗中可以看到拿掉reg層後,mAP下降了將近5個百分點(56.8%→52.1%)。
可以看出RPN reg層在微調建議框的位置上起了很大的作用。
backbone的作用
如果將RPN的backbone換成表達能力更強的VGG會怎麼樣呢?
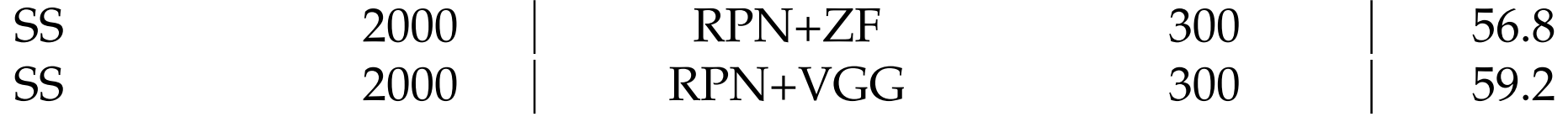
原來RPN是使用ZF來抽取特徵,實驗將原來的ZF換成VGG後,mAP提升了2.4%。
這代表RPN+VGG提出的建議框品質比RPN+ZF好。
因為使用RPN+ZF訓練及測試與使用SS訓練及測試的表現相當:
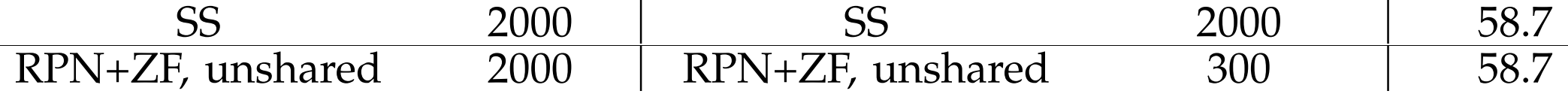
並且根據上面的發現,我們可以預期如果訓練及測試都使用RPN+VGG,mAP應該可以超過SS。
以下就是RPN+VGG的實驗。
VGG16的表現
在PASCAL VOC 2007測試集上的表現
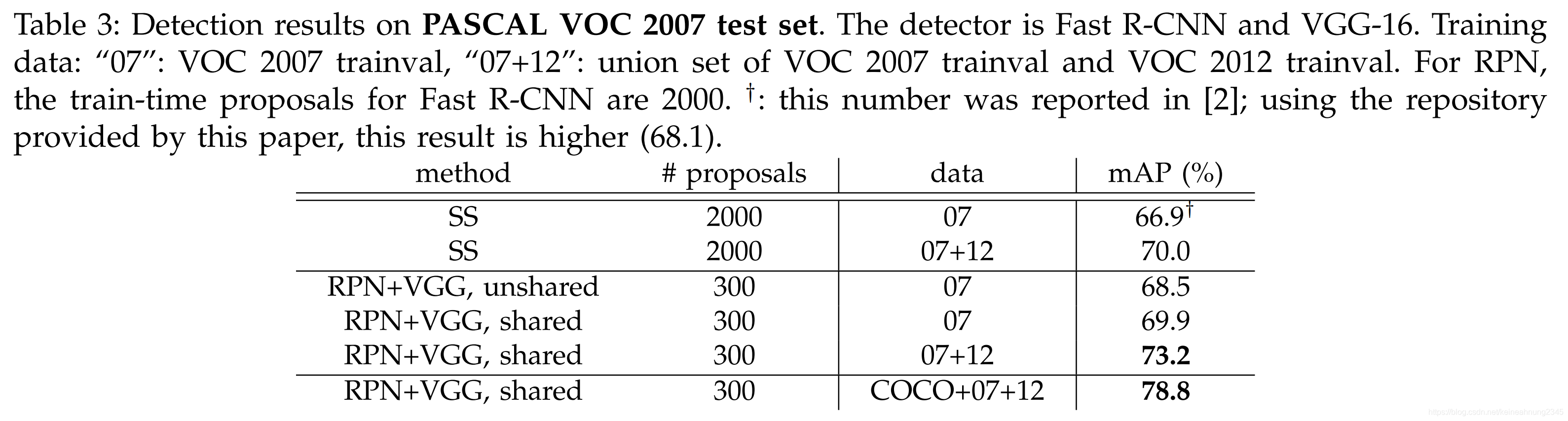
在未共享權重的情況下,RPN+VGG的mAP比SS略為高出一點(68.5% v.s. 66.9%),這顯示RPN+VGG的建議框比SS更準確。
而在共享權重時,RPN+VGG的mAP則可以達到69.9%。
如果加上12年的訓練數據,則mAP可以達到73.2%。
PASCAL VOC 2012測試集上的表現
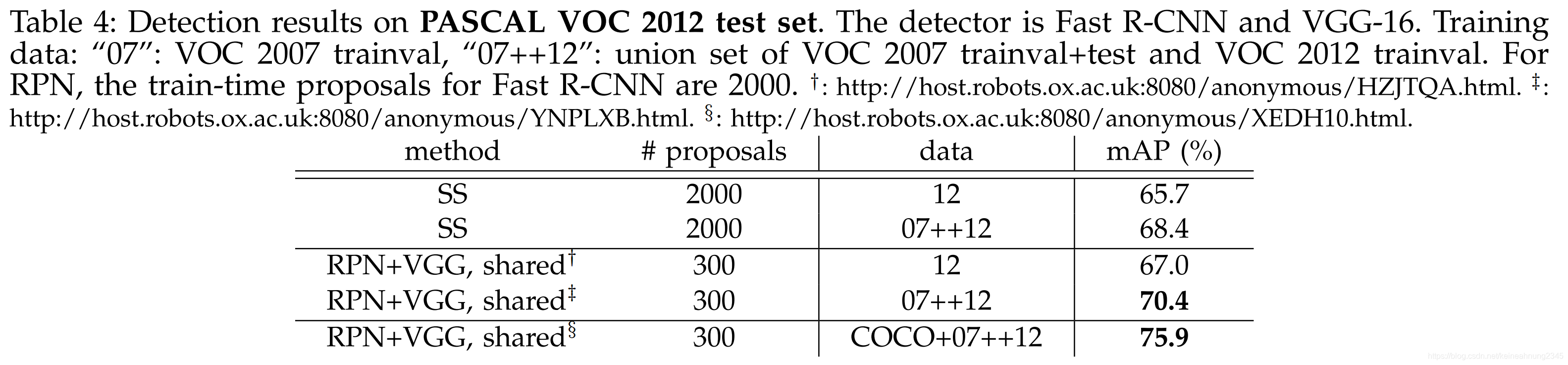
從這個實驗中也可以得出類似的結論。
運行時間比較

在SS+Fast R-CNN(VGG backbone)中,SS花約1500毫秒,Fast R-CNN花146+174=320毫秒(處理2000個建議框),總共花1830毫秒。
在共享權重的RPN+Fast R-CNN中,提出建議框的時間降到了10毫秒。另外因為建議框的數量減少到300,所以region-wise的部份也下降不少。
如果使用較簡單的ZF net的話,frame rate還可以提升到17 fps。
對超參數的敏感程度
anchor的scale及aspect ratio

論文中默認使用3 scales, 3 ratios,這樣可以取得69.9%的mAP。
如果在每個位置只使用1 scale, 1 ratio,mAP會下降3~4%。
增加不同scale, ratio的anchor(變成1 scale, 3 ratios或3 scale, 1 ratios),可以有效提升mAP。
在使用3 scales, 1 ratio的情況下,跟3 scales, 3 ratios的mAP十分相近,這表示scale及ratio這兩個因素對mAP的影響並不是獨立的。
λ
λ
\lambda
λ的作用是協調classification loss與regression loss在總體loss中所佔的權重:
L
(
{
p
i
}
,
{
t
i
}
)
=
1
N
c
l
s
∑
i
L
c
l
s
(
p
i
,
p
i
∗
)
+
λ
1
N
r
e
g
∑
i
p
i
∗
L
r
e
g
(
t
i
,
t
i
∗
)
L(\{p_i\}, \{t_i\}) = \frac{1}{N_{cls}} \sum_i L_{cls}(p_i, p_i^*) + \lambda \frac{1}{N_{reg}} \sum_i p_i^*L_{reg}(t_i,t_i^*)
L({pi},{ti})=Ncls1i∑Lcls(pi,pi∗)+λNreg1i∑pi∗Lreg(ti,ti∗)
這裡實驗了不同 λ \lambda λ值對mAP的影響:

從實驗結果可以看到當
λ
\lambda
λ在1~100這個範圍內時,mAP只有十分微小的變化。
因此我們可以說模型mAP對
λ
\lambda
λ是不太敏感的。
Recall-To-IoU的分析(診斷proposal method的表現)
Recall-To-IoU指的是proposal在不同IoU threshold下的recall。
相比於mAP,這並不是一個嚴謹的評量指標。
Recall-To-IoU只適用於診斷proposal method的表現。
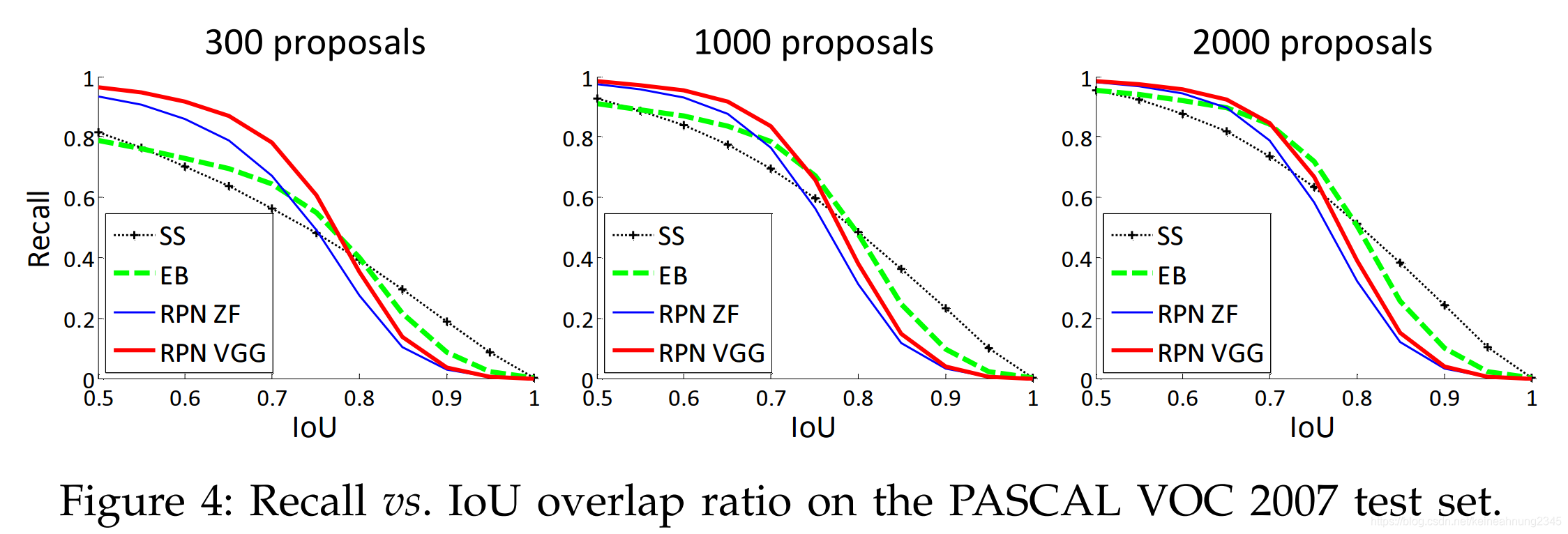
當將建議框的數量從2000降到300時,SS跟EB的recall都從1降到0.8左右。RPN卻仍維持在1附近。
這可以當成是上面"建議框數量的影響"章節的佐證。
一階段目標檢測 v.s. 二階段提出建議框+檢測
一階段的目標檢測(如:OverFeat)是在convolutional feature map上用滑動視窗的方式得到應該關注的方框,然後直接利用這些方框來做分類及回歸。
二階段的目標檢測(如:Faster R-CNN)則包含了 第一階段-在convolutional feature map上用滑動視窗的方式得到應關注的方框,然後基於這些方框,提出與類別無關的建議框 及 第二階段-利用第一階段提出的建議框(而非滑動視窗),對他們做分類及回歸。
為了比較一階段及二階段目標檢測的表現,這裡模仿Overfeat,建立了一階段的Fast R-CNN:
- 模仿OverFeat,採用image pyramid上5種尺度的convolutional feature maps
- 捨棄SS,改用滑動視窗的方法生成3種尺度 X 3種寬高比的候選框
- 為每個候選框預測其類別及回歸其位置

從上面的實驗結果可以看出One-Stage的表現比Two-Stage的表現差了近5%。
並且因為一階段目標檢測需要處理約20000個建議框,所以速度也跟著下降許多。
4.2 在MS COCO數據集上的實驗
相比於在PASCAL VOC數據集上的實驗,這邊做了一點修改,包括以下幾點。
調整mini-batch size
| VOC | COCO | |
|---|---|---|
| mini-batch size | 256 | 8 for RPN / 16 for Fast R-CNN |
| learning rate | 0.001 x 60K + 0.0001 x 20K | 0.003 x 240K + 0.0003 x 80K |
mini-batch size變小,要把學習率調大???
MS COCO數據集中小物體較多,在本次實驗中,也對模型或訓練數據做出了相應的修改,包括anchors尺度及負樣本定義。
增加anchors的尺度種類
| VOC | COCO | |
|---|---|---|
| anchors | 128, 256, 512 | 64, 128, 256, 512 |
修改負樣本定義,提升小物體辨識能力
在SPPNet,Fast R-CNN中,與ground truth box的IoU在[0.1, 0.5)範圍內的會被定義為負樣本,這是因為在[0, 0.1)範圍內的仍然會被SPPNet後期的SVM所看到(Fast R-CNN則忽略了[0, 0.1)範圍內的樣本)。如下表所示:
| 與ground truth box的IoU為(xx,xx)的樣本會被網路的哪個部份看到? | SPPNet | Fast R-CNN | Faster R-CNN |
|---|---|---|---|
| [0, 0.1) | SVM | None | Both |
| [0.1, 0.5) | Both components | Both | Both |
實驗發現,將[0,0.1)範圍內的數據納入負樣本中,可以提升Fast R-CNN及Faster R-CNN在MS COCO數據集上mAP@0.5的表現。(但在VOC上的表現差異不大)
原版Fast R-CNN v.s. 修改版Fast R-CNN v.s. Faster R-CNN
修改過後的Fast R-CNN在COCO數據集上的mAP@0.5表現提升不少(下表前兩行)。可以將它歸功於上述所做的幾項改變。

同樣使用COCO train當訓練集,COCO test-dev當測試集:
Faster R-CNN的mAP@.5比Fast R-CNN好2.8%,mAP@[.5,.95]比Fast R-CNN好2.2%(上表二、三行)。這顯示RPN對於定位的準確度是有一定作用的。
改用ResNet當backbone
如果有更好的特徵,Faster R-CNN的表現還可以更好。
在COCO val上的表現:
| 模型 | mAP@0.5 | mAP@[0.5, 0.95] |
|---|---|---|
| Faster R-CNN w/ VGG-16 | 41.5 | 21.2 |
| Faster R-CNN w/ ResNet-101 | 48.4 | 27.2 |
| Faster R-CNN w/ ResNet-101 + 其它改進 | 55.7 | 34.9 |
| Faster R-CNN w/ ResNet-101 (多模型) | 59.0 | 37.4 |
4.3 在COCO上訓練,在VOC上測試
COCO數據集是比VOC數據集還大的,並且VOC數據集中的類別是COCO數據集類別的子集合。
這裡實驗看看如果用較大的COCO數據集來訓練,在VOC數據集上的表現會有何改變。

圖中的第4行是在COCO上訓練,在VOC上測試的結果,可以看到它比第2行的mAP還高出2.9%。
如果使用COCO+VOC一起訓練(第5行)則比只用VOC訓練高出了5.6%。
在本實驗中,Faster R-CNN(VGG Backbone)的測試時間不變,仍是200毫秒。
問題討論
ZF Net及VGG 16最後一層卷積層的感受野是如何計算出來的?
ZF Net
ZF Net出自Visualizing and understanding convolutional neural networks這一篇論文。
以下是論文中ZF Net的架構圖。
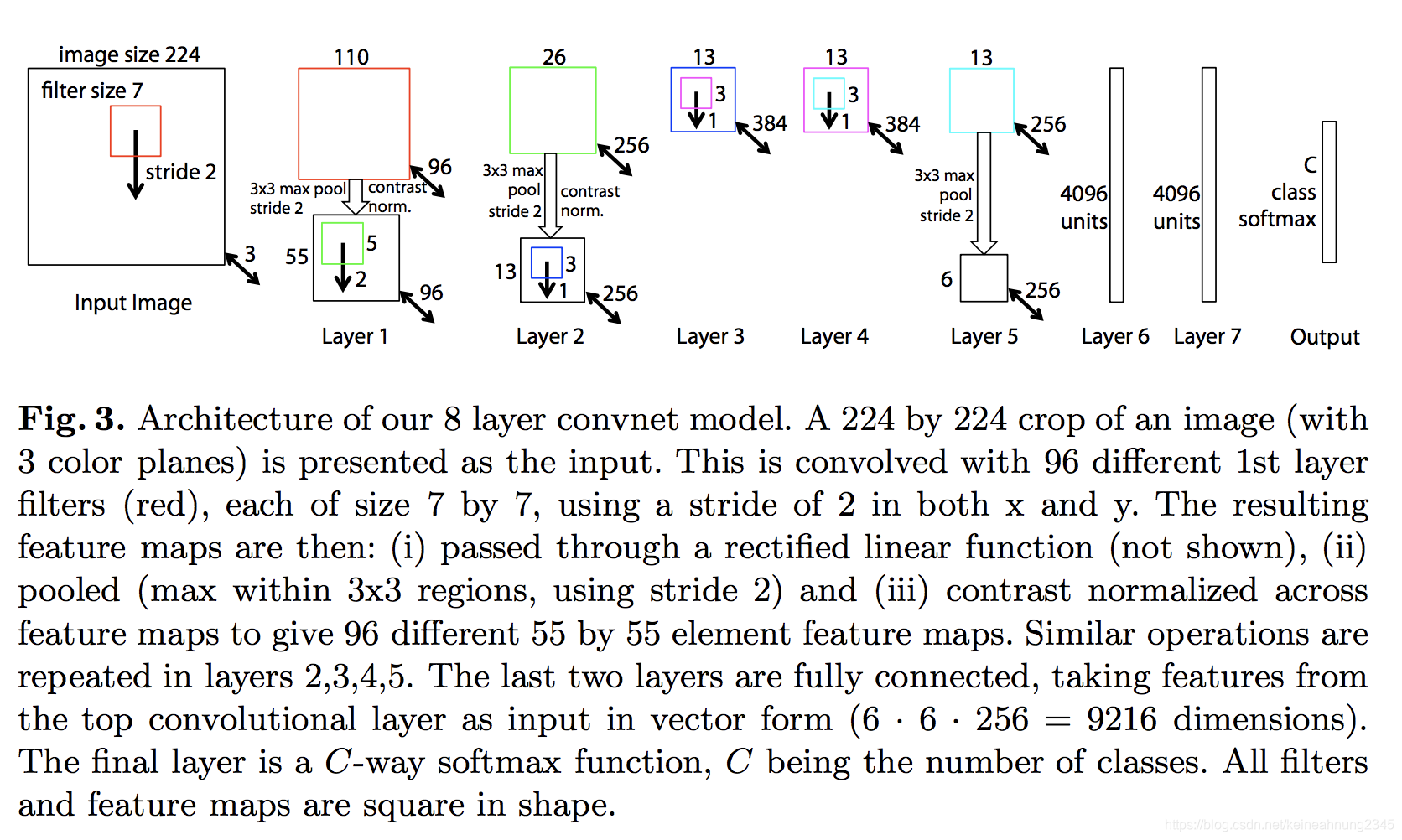
我們可以照著上面那張圖畫出如下的表格:
| layer | kernel_size | stride | padding | note |
|---|---|---|---|---|
| Conv | 7 | 2 | 3 | |
| Max Pool | 3 | 2 | 1 | |
| Conv | 5 | 2 | 2 | |
| Max Pool | 3 | 2 | 1 | |
| Conv | 3 | 1 | 2 | |
| Conv | 3 | 1 | 2 | |
| Conv | 3 | 1 | 2 | ZF Net最後一層卷積 |
| Conv | 3 | 1 | 0 | 滑動視窗的大小 |
應該有同學注意到,明明圖中Layer 2-4只有三層卷積層,為何表中會有四層呢?
這是因為此處計算的不是feature map上單個pixel的感受野,而是Faster R-CNN所用滑動視窗的感受野。
因為滑窗的大小為n x n(n = 3),所以才會在表中加上最後一層。
筆者按照這張表在Fomoro AI - Receptive Field Calculator架了一個ZF Net:Receptive Field Calculator - ZF Net,可以從這個連結裡驗證,ZF Net最後一層輸出的feature map的感受野確實是171。
VGG16
論文裡提到VGG16 backbone包含了13個卷積層,因此可以推斷Faster R-CNN所使用的是下圖中的D版本:

VGG16的D版包含了13個卷積層及3個全連接層。
同樣先畫表格:
| layer | kernel_size | stride | padding | note |
|---|---|---|---|---|
| Conv | 3 | 1 | 2 | |
| Conv | 3 | 1 | 2 | |
| Max Pool | 2 | 2 | 0 | |
| Conv | 3 | 1 | 2 | |
| Conv | 3 | 1 | 2 | |
| Max Pool | 2 | 2 | 0 | |
| Conv | 3 | 1 | 2 | |
| Conv | 3 | 1 | 2 | |
| Conv | 3 | 1 | 2 | |
| Max Pool | 2 | 2 | 0 | |
| Conv | 3 | 1 | 2 | |
| Conv | 3 | 1 | 2 | |
| Conv | 3 | 1 | 2 | |
| Max Pool | 2 | 2 | 0 | |
| Conv | 3 | 1 | 2 | |
| Conv | 3 | 1 | 2 | |
| Conv | 3 | 1 | 2 | ZF Net最後一層卷積 |
| Conv | 3 | 1 | 0 | 滑動視窗的大小 |
VGG16的感受野是228,可以由此驗證:Receptive Field Calculator - VGG16。
注意到連結中有14層卷積層,跟ZF Net裡的情況一樣,最後多出來的那一層是為了滑動視窗而設的。
參考RPN(fasterRCNN)网络中每个anchor,感受野覆盖问题。
為何classifier head要輸出2*k個值,而非k個值就好?
論文注腳第4點提到:
- For simplicity we implement the cls layer as a two-class
softmax layer. Alternatively, one may use logistic regression to
produce k scores.
因此事實上是可以只預測k個值就好。
但是論文中並未說明預測2*k個值的動機。
另外可否不要人為定義正負樣本,直接回歸IoU?(類似YOLO)
ConvNet backbone輸出的feature map長x寬約為2400?
3.3實作細節裡提到,VOC數據集中的圖片大小為375 x 500,論文裡將短邊放大成600。
所以在進入神網路之前,圖片大小變成了600 x 800。
但是後面又提到輸入圖片的大小通常是600 x 1000(怎麼不是600 x 800,難道是非等比例縮放?),所以此處以這一句為準。
一樣點進剛才的連結:Image output size - ZF Net 及 Image output size - VGG16。
然後把最上面INPUT SIZE的地方改成600或1000,可以得到:
| feature map短邊(輸入圖片短邊600) | feature map短邊(輸入圖片短邊1000) | feature map面積 | |
|---|---|---|---|
| ZF Net | 38 | 63 | 2394 |
| VGG16 | 38 | 63 | 2394 |
注意:OUTPUT SIZE是看倒數第二層的,那才是卷積層的最後一層。
算出來feature map的面積為2394,與2400十分相近。
MultiBox的backbone是GoogleLeNet?
論文說中MultiBox使用的CNN Backbone是GoogleLeNet(InceptionV1),但是該論文中卻找不到1536這個關鍵字。
因此筆者合理懷疑這裡說的應該是Inception V4,附上一張Inception V4的架構圖:

為何RPN具有平移不變性?
參考Why and how are convolutional neural networks translation-invariant?及What is translation invariance in computer vision and convolutional neural network?。
來自Brando Miranda的回答:
?(?(?))=?(?(?))
即,對convolution的輸入做平移得到的結果 會等於 將convolution後的結果做平移。
convolution在神經網路裡的作用是抽取特徵,而因為有上述translation invariance的性質,所以不管輸入圖片中的物體怎麼平移,RPN都有辦法得到相同(跟著輸入平移)的候選框。
log loss
log loss: used when the output is a probability between 0 and 1.
以下是log loss的Python實現:
if p_true==1:
return -log(p)
else:
return -log(1-p)
其實可以將上述兩式合併:
-[p_star*log(p) + (1-p_star)*log(1-p)]
看起來就跟cross entropy loss一樣,參考ML Cheetsheet - Loss Functions:
Cross-entropy loss, or log loss, measures the performance of a classification model whose output is a probability value between 0 and 1.
果然兩者是一樣的東西。
ZF Net及VGG最後一層conv layer的stride都是16個pixels?
同樣看這兩個連結:Receptive Field Calculator - ZF Net及Receptive Field Calculator - VGG16。
如果把輸入圖片大小設為600,則ZF Net及VGG16最後一層conv layer(連結中倒數第二層)輸出的feature map長度皆為38。
參考CNN: input stride vs. output stride的算法,兩者最後一層conv layer在輸入圖片上的stride都是600/38=15.78約等於16。
anchor尺度的單位是在輸入圖片上的pixel?
mini-batch size變小,要把學習率調大?
Lesson Learned
注意力機制
當mini-batch大小改變時,學習率也要跟著調整(4.2)
四步訓練
可以用Recall-To-IoU來診斷RPN的表現
參考連結
Mask_RCNN代碼研讀(matterport版本)系列文(三)- Region Proposal Network部份
Visualizing and understanding convolutional neural networks
Fomoro AI - Receptive Field Calculator
Receptive Field Calculator - ZF Net
Receptive Field Calculator - VGG16
RPN(fasterRCNN)网络中每个anchor,感受野覆盖问题
Why and how are convolutional neural networks translation-invariant?
What is translation invariance in computer vision and convolutional neural network?
fast.ai的wiki頁面
ML Cheetsheet - Loss Functions
CNN: input stride vs. output stride















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









