






首先说文件,经常说二进制文件,文本文件,视频文件,音频文件。这多种类型的文件对于计算机来说有啥区别呢?
对于计算机存储来说没有区别,计算机存下来的都是二进制文件,及所谓的文本文件,视频文件,音频文件,其实就是二进制文件的一种,即文本文件,视频文件,音频文件都是二进制文件。那都是二进制文件为什么打开区别这么大。问题出在你用什么工具打开,用什么工具打开本质上又是用什么形式打开的二进制文件。譬如,你按字符串写入的文本文件,以记事本等文本工具打开就是文本形式,某些bin(二进制)文件,视频文件用记事本打开就是乱码。
二进制打开文本文件和二进制文件:上面说了文本文件也是二进制的一种,所以二进制打开文本文件和二进制文件,得到的都是二进制数,此时文本文件不会去做对应的编码转换。
文本格式打开二进制和文本文件:文本文件也是二进制文件,但是,在存储的时候是将字符都按照某种编码格式转换成了二进制数存储下来了。以文本格式打开,就又以这种编码格式将二进制对应成字符显示出来。而以文本格式打开二进制文件,这个二进制文件可能在写入的时候并不是像文本编码格式写的(比如说可能是一种结构体格式),所以按照文件文件打开可能乱码。
以文本格式打开乱码现象的原因:
因为该文件本来写入的时候也不是按照文本格式写的,里面的内容格式不清楚,所以并不能对应ASCII码格式能组成一句话,甚至那个字节数都不属于ASCII码的对应范围。这就造成了乱码。简单来说,写入的格式与解析的格式不对应,造成了乱码。
上面说到以文本格式打开并不是按照文本格式存储的文件会乱码,那么为什么有时候同样都是文本文件以文本打开,为什么还有乱码呢?
原因:文本格式编码格式有ASCII,GBK,UTF8格式,以某种格式编码写入,却又以另外一种编码格式解析,这种时候就造成了都是文本文件却乱码的现象。比如windows下系统通常默认使用GBK编码,而Linux中,系统使用UTF8编码,所以文件换系统打开就出现了乱码。
各编码特性,历史起源及发展,互相之间的关系:参考:https://zhuanlan.zhihu.com/p/38333902

ASCII码:
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为 ASCII 码,一直沿用至今。
ASCII 码一共规定了128个字符的编码,比如空格SPACE是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的一位统一规定为0。
UTF8:
UTF-8 的编码规则很简单,只有二条:
1)对于单字节的符号:字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的;
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。UTF-8 是 Unicode 的实现方式之一。
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间。
这也是为什么同一段字符串在VS上统计长度和在VX上统计长度不一样的原因。在VXWorks上,如果当前文件被设置为UTF8编码,统计生僻字符和汉字的长度按照以上UTF8的说明,长度是不定的,一个汉字和一个生僻字符占3个字节(实际情况可能需要利用strlen具体来看)。而VS上采用的GBK编码,汉字和生僻字符占两个字节,所以两种编译器上的长度不一样。但如果VXWorks上按照GBK的编码来,那应该就是一样的了。
1)出现了 Unicode 的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示 Unicode。2)Unicode 在很长一段时间内无法推广,直到互联网的出现。
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。其他实现方式还包括 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示),不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8 是 Unicode 的实现方式之一。
彻底搞清楚ASCII,Unicode和UTF-8之间的关系_ascii utf8 关系-CSDN博客
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
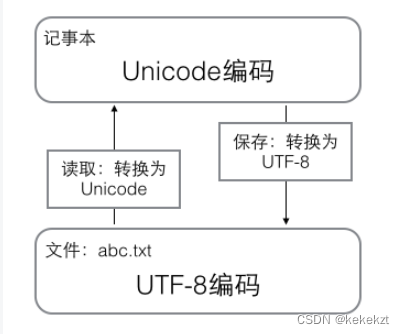
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
GBK编码
GB系列编码,GB系列编码为中国的国标系列编码,GBK编码是微软的编码,在Windows系统上默认为GBK编码。
天朝专家把那些127号之后的奇异符号们(即EASCII)取消掉,规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到 0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。在这些编码里,还把数学符号、罗马希腊的 字母、日文的假名们都编进去了,连在ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。
上述编码规则就是GB2312上述
















 1714
1714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









