







 本文介绍了一个使用Python Scrapy框架编写的51job爬虫,旨在抓取地区招聘公司的详细信息并导出为Excel数据报表。首先分析51job网页结构,通过Request URL和curr_page参数实现翻页,定位到div标签提取公司信息。接着展示了核心代码,包括设置xpath规则抓取数据,并提及pipelines.py中处理Item字段。
本文介绍了一个使用Python Scrapy框架编写的51job爬虫,旨在抓取地区招聘公司的详细信息并导出为Excel数据报表。首先分析51job网页结构,通过Request URL和curr_page参数实现翻页,定位到div标签提取公司信息。接着展示了核心代码,包括设置xpath规则抓取数据,并提及pipelines.py中处理Item字段。
51job爬虫篇(一)
闲来无事,写取一个51job的爬虫,功能是爬取部分地区所有招聘公司的相关信息,最后导出成excel,做成数据报表
爬虫使用python的scrapy框架,简单高效,使用该爬虫还需要部分xpath的知识,需要简单进行学习下才能看懂规则语法
分析篇
写网络爬虫,最重要的是进行分析目标站点的一个html结构,我们打开51job的搜索界面,按F12打开浏览器的调试器,刷洗,可以看到请求后端的一个url
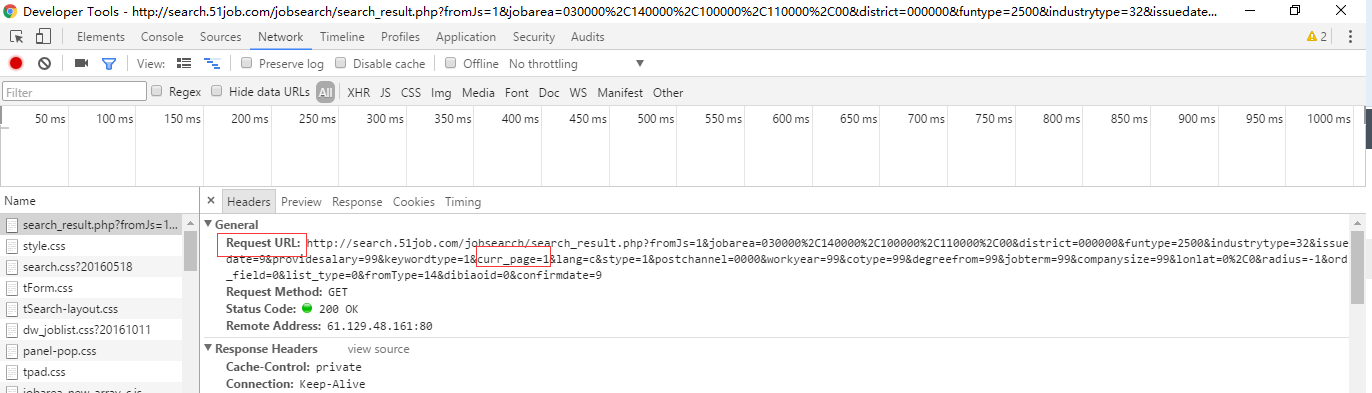
从上图可以看到Request URL就是我们需要的连接,而且又哥curr_page=1参数,说明通过这个参数可以跳转到任意页码
分析图二,因为我们要抓列表下的所有公司信息,所有应该先定位到这个列表头部,然后发现有一个div标签是
id="resultList",所以可以以这个为切入点
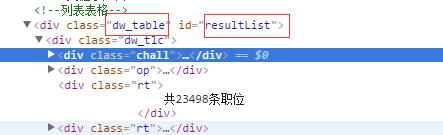
以
<div id="resultList">为切入点之后,可以看到他们整个的html结构,公司的信息都是藏在<div class="el">下面
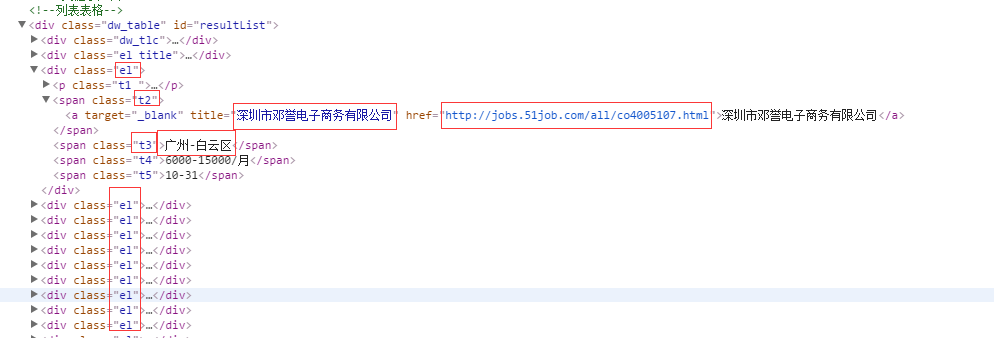
最后我们就可以根据xpath的语法,抓取到想要的信息
例如:
for sel in response.xpath('//div[@id="resultList"]/div[@class="el"]'):
try:
#公司链接
item['link'] = sel.xpath('span[@class="t2"]/a/@href').extract()[0]
#公司名字
item['company'] = sel.xpath('span[@class="t2"]/a/text()').extract()[0]
#地区
item['address'] = sel.xpath( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









