






翻译:https://zhuanlan.zhihu.com/p/36699992
解读:https://baijiahao.baidu.com/s?id=1622064575970777188&wfr=spider&for=pc
公式解读:https://zhuanlan.zhihu.com/p/39034683
主要工作
•问题:RNN是根据前一个状态产生后一个状态,阻碍了训练的的并行化
•解决方法:提出一种新的简单的网络架构Transformer,仅基于attention机制并完全不用循环和卷积网络
编码器和解码器堆栈

Transformer编码器和解码器都使用self-attention堆叠和point-wise、完全连接的层
编码器由6个完全相同的层堆叠,每一层都有两个子层。 第一层是一个multi-head self-attention机制,第二层是一个简单的、位置完全连接的前馈网络。 我们对每个子层再采用一个残差连接(将输出表述为输入和输入的一个非线性变换的线性叠加),接着进行层标准化。
解码器同样由N = 6 个完全相同的层堆叠而成。 除了每个编码器层中的两个子层之外,解码器还插入第三个子层,该层对编码器堆栈的输出执行multi-head attention。 与编码器类似,我们在每个子层再采用残差连接,然后进行层标准化。 我们还修改解码器堆栈中的self-attention子层,以防止位置关注到后面的位置。 这种掩码结合将输出嵌入偏移一个位置,确保对位置的预测 i 只能依赖小于i 的已知输出。
Attention
•Attention函数可以描述为将query和一组key-value对映射到输出,输出为value的加权和,其中分配给每个value的权重通过query与相应key的sore来计算。

一个输入X, 通过3个线性转换把X转换为Q,K,V
缩放版的点积attention
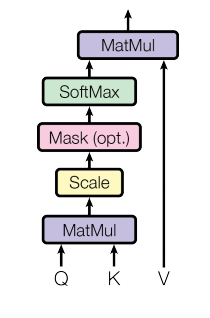
计算query和所有key的点积、用 ![]() 相除,然后应用一个softmax函数以获得值的权重。
相除,然后应用一个softmax函数以获得值的权重。
实践中点积attention的速度更快、更节省空间,因为它可以使用高度优化的矩阵乘法代码来实现。
Multi-Head Attention

Multi-Head Attention就是把上面的过程做H次,然后把输出Z合起来,可以类比CNN中的多通道。
位置编码
•由于本文的模型不包含循环和卷积,为了让模型利用序列的顺序,我们必须注入序列中关于词符相对或者绝对位置的一些信息
另建立了一个交流群,感兴趣的朋友可以加下

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









