







【省流:打算直接测试效果的可以访问这个网址】
http://decaptcha.ai?project_name=netease_zh_overlap
【实现方案】
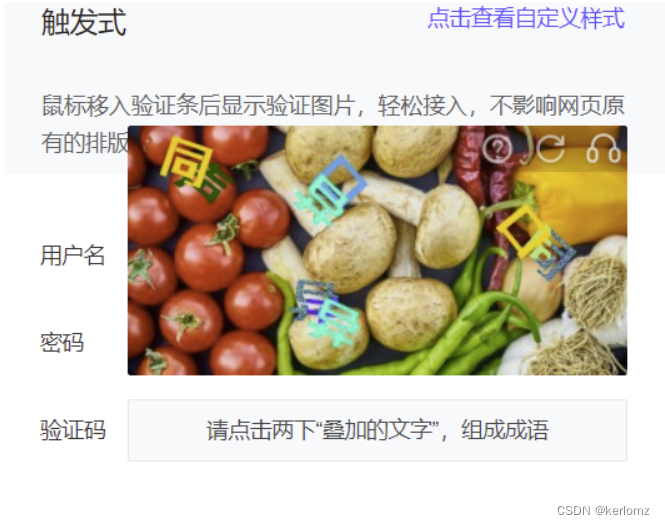
如图所示,我们能看到,比起以往的“单个字”语序点选,这个验证码的难点在于“重叠汉字“,我们知道,一般的深度学习训练单个汉字的图像分类,我们假设一般的汉字常用字有3500个汉字。我们的输出层维度一般是(1, 3500)
而对于重叠汉字的问题,我们有两种建模形态,一种是两个重叠的字作为一个整体,另一种是把两个重叠的汉字分开,作为两个独立的分类任务。
我当前选择的方案是前者,作为一个整体,为什么我不选择后者呢?因为后者的重叠目标虽然区分开来,但是遮挡部分的特征太过随机了,对于下层汉字被遮挡缺失的特征,很难识别出来具体的内容,而如果我们把它作为一个整体看待,我们特征既提取了上层汉字的特征,也能利用上层的特征推测下层汉字被遮挡部分的特征的可能性,能够帮助网络更加精准的推测出来具体的内容。
那么我们把大致的方向确立好了之后,就可以开始进一步的方案设计了,我们已经确立了把两个重叠的汉字作为一个整体之后,我们就需要开始考虑如何对两个汉字的识别建模了,首先我们有以下几种方案的选择:
- 作为多标签分类,建模就是(1, 3500)一样的输出,只不过值是0-1范围,作为概率,那么两个重叠的汉字概率可以设置为0.5,0.5,或者1, 1。其余的分类都是0,如果我们使用这种方式建模,那么我们会遇到一个问题,因为绝大多数分类都是0,模型很容易收敛,即使忽略我们1的部分,损失一样可以很小,在数学层面上,使用BCE损失很难达到预测出来我们需要的两个重叠汉字的目的,所以我们需要对损失函数进行改进,设计一种能够针对极端的正负样本不平衡情况的损失函数。需要标注每张图中的两个汉字的内容,标注成本一般。
- 第二种就是我们把它作为两个独立的分类情况,区分上下层,建模就是(1, 2, 3500)这样的话,我们可以把它作为两个独立的多分类任务,只不过这种方案对于标注的要求很高,需要区分上下层,人工外包单独标注单个样本的时候如果没有其他组图进行范围参照的话,错误率挺高。
- 我们可以端到端的把四组图作为一个批次的输入(batch_size, 4, 224, 224, 3),这样能够加强每一组图彼此之间的约束,我们的输出可以有多个,结合上面两种方案,顺序输出:(batch_size, 4,2,4),分类输出(batch_size, 4,2, 3500)/(batch_size, 4,3500)。对于端到端的顺序输出,如果我们加入一个小型语言模型的多模态,或者直接单独训练这个语言模型再嵌入端到端模型中,都可以达到比较好的端到端效果,因为现实中我们挺难直接从样本中获取到尽可能多的成语的可能,我们单独训练语料库的难度更低一些。网上有很多开源的语料库可以下载作为训练样本。如果我们只保留顺序输出的话,样本的成本最低,只需要对接人工标注平台打码的同时,采集验证通过的图,我们就能通过得到的顺序坐标,结合一点点(500-1000张左右)目标检测的成本,推理出四组图的顺序,自动化产生样本标注。
有了以上的思路,我们尝试实现它:
def forward(self, inputs):
batch_size, num_images, height, width, channel = inputs.size()
predictions = self.core_net(
inputs.view(batch_size, num_images, height, width, channel)
)
predictions = predictions.view(batch_size, num_images, self.core_num_classes)
embedded = self.embedding(predictions)
batch_size, num_groups, embedding_dim = embedded.size()
suit_gru, _ = self.pair_gru(embedded)
global_gru, hidden_gru = self.global_gru(suit_gru)
hidden_gru = hidden_gru.permute(1, 0, 2).contiguous()
hidden_gru = hidden_gru.view(batch_size, self.hidden_dim)
ranks = self.rank_dense(hidden_gru)
ranks = ranks.view(batch_size, 2, num_groups).sigmoid()
return ranks
再根据我们选择的建模方案,来设计它对应的损失函数,可以根据我们已知的信息增加多维度的约束,比如我们得到的排序结果的因果关系,结果本身的取值范围的数学规律,场景中存在的某些隐性规则,我们都可以把它作为损失中的加权的影响因子。如果是使用多标签分类我们甚至可以设计一个专用的topk2损失。
除此之外,我们可以使用增强手段,比如把标注的样本相同标注的可以随机配对组合成语,作为一组新的样本等等,损失计算也可以设计阶梯式,引导网络先学习某个容易学习的特征,学习好了再学习另一个特征,加速模型收敛。















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









