







LevelDB(四)
四、table
此部分主要讲解SSTable的源码。
1. SST概述
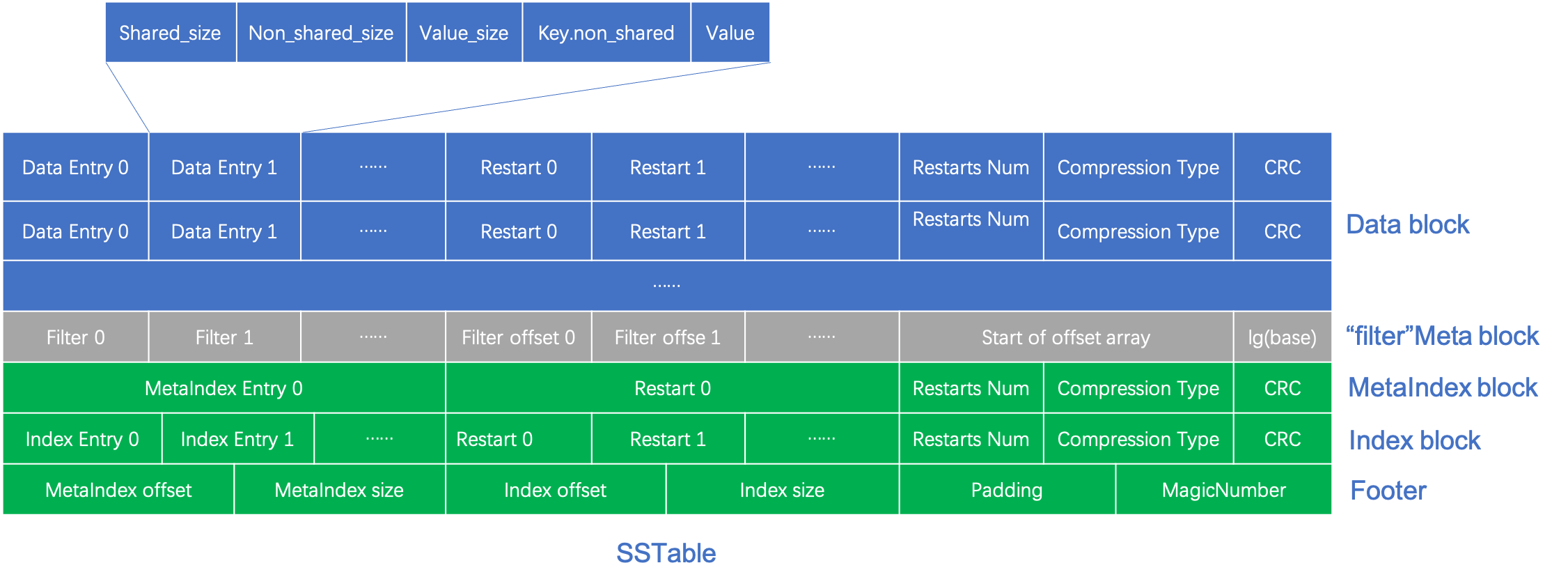
SSTable的构成是由若干Data Block、若干Meta Data Block、一个Index Block和一个Footer组成。其中:
-
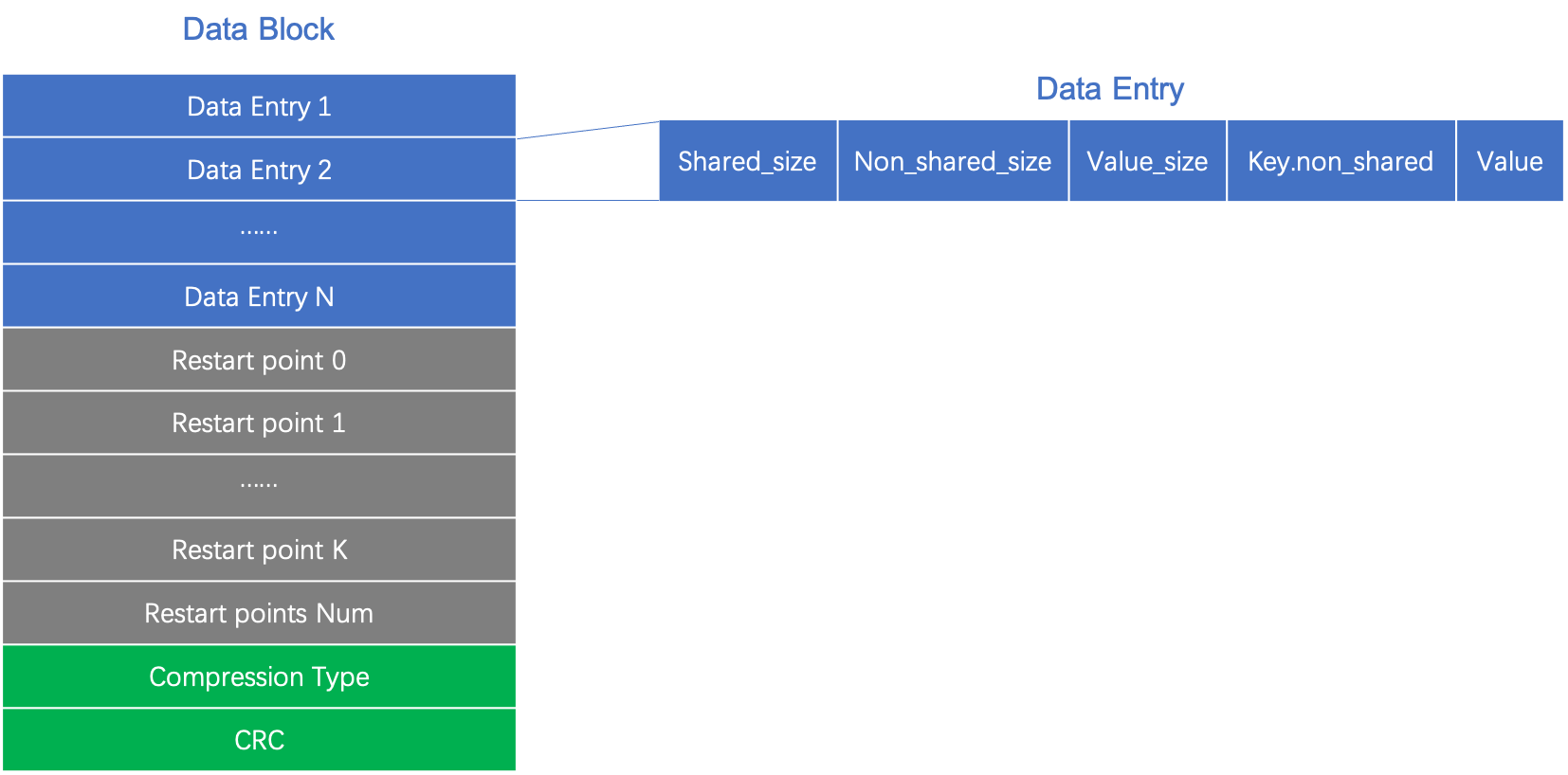
Data Block为key-value存储的结构,由于LevelDB在查询数据的时候,又想顺序读取数据(顺序读要快于随机读),又想缩短查找数据的时间(试想,如果只使用顺序读,一次性读取很大的内存再顺序查找是较慢的),所以LevelDB将默认每16个数据为一组(Group或者下图的Entry)使用进行顺序读,每组之间使用十分查找。其中:
- 每组(Entry)之间使用前缀表示,第一个key存储完整的数据,后面15个key,每一个都和前一个key进行公共前缀的查找(见下文)。value正常存储。
- Restart Point是记录每个Data Entry的偏移量。
- Compression Type压缩标志。
- CRC用来进行校验。

-
Meta Data Block是用来对key值进行快速查找的模块,LevelDB一般使用布隆过滤器(bloom filter),默认2kb,每个布隆过滤器对应一个Data Block,是这个Data Block中所有数据的存在性校验,可以快速的查找到一个key在不在这个Data Block中。
由于这个部分比较小,压缩type 和 crc 检验的5字节不需要使用。
-
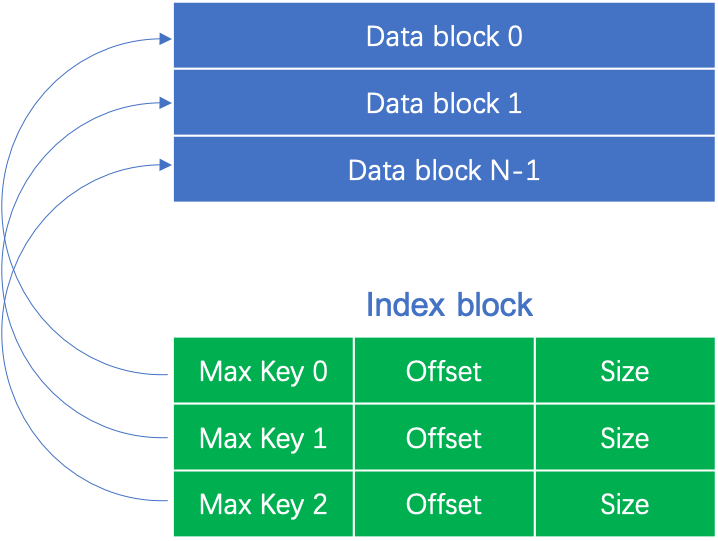
Index Block对应每个Data Block的最大key值、偏移量和大小,只有一个。
-
Footer存储Meta Data Block和Index Block的大小和文件偏移位置,以及一个 Magic number。

Block部分:包括Data Block和Index Block。以下以Data Block举例,实际上两者使用相同的数据结构,只是存储的数据类型不同。
Data Block中,存储了数据部分(Data Entry),重启点的偏移量,压缩类型和CRC检验码。
压缩类型和CRC检验码的长度为5byte:
// format.h
static const size_t kBlockTrailerSize = 5;
其中,数据部分(Data Entry)使用的是共享前缀表示法,第一个变量存储完整的key–value,后面重启点内15个(加上第一个总共16个)对key部分使用共享前缀表示。
- 和前一个key最大前缀个数(Shared_size)
- 除了Shared_size外的key长度(Non_shared_size)
- value长度(Value_size)
- 除了Shared_size外的key的值(Key_non_shared)
- value值(Value)
2. block_builder.h
BlockBuilder(block_builder.h)
BlockBuilder主要是用于index_block/data_block/meta_index_block的构建。
private:
// 重启点等 - 因为一个data entry中用的是共享前缀的保存方式,于是每16个key-value对为间隔,去保存一个完整的数据
const Options* options_;
// 序列化之后的数据
std::string buffer_;
// 内部重启点具体数值,需要注意的是他是偏移量
std::vector<uint32_t> restarts_;
// 重启点计数器
int counter_;
bool finished_;
// 记录上一次的key 在add的时候可以方便去计算上一个key的共享长度
std::string last_key_;
// 构造函数 初始化变量,对重启点个数进行判断 restarts_偏移量插入0
explicit BlockBuilder(const Options* options);
// 重置成员变量
void Reset();
// 添加数据
/*
1. 先初始化上一个key
2. 判断在重启点范围内, 并验证当前的key肯定要比上一次的key要大
3. 如果的个数counter_小于重启点 16
查找当前的key和上一个key重复的部分
如果当前的个数counter_==16 说明到重启点的 将存储完事的数据
添加偏移量(当前buffer_的总长度) counter_置0
4. 将数据序列化后添加到buffer_后
5. 更新last_key_便于添加下一个key-value使用
6. 当前重启点个数++
*/
void Add(const Slice& key, const Slice& value);
// 如果整个Data Entry部分添加完成了
// 1.将restarts_中保存的Data Entry的偏移量序列化到buffer_中
// 2.将restarts_的个数序列化到buffer_中
Slice Finish();
// 返回当前序列化后的数据buffer_ 和 偏移量大小 + 4 (重启点大小)
size_t CurrentSizeEstimate() const;
// 判断序列化后的数据buffer_是否为空
bool empty();
3. filter_block.h
1. FilterBlockBuilder(filter_block.h)
使用布隆过滤器的Meta Data Block的构建过程:
FilterBlockBuilder中也是要对每个key进行存储,其中每个布隆过滤器存储着一部分key值。
private:
// 平铺的keys
std::string keys_;
// 每个key在keys_中的起始位置(偏移量)
std::vector<size_t> start_;
// result_中存放着很多个bf过滤器,其中每个bf过滤器都是以2kb原始数据计算得来的
std::string result_;
// 对result_中的bf过滤器的偏移量进行记录
std::vector<uint32_t> filter_offsets_;
// bf过滤器
const FilterPolicy* policy_;
// 把keys_和start_恢复出来的数据放到CreateFilter()的入参中
std::vector<Slice> tmp_keys_;
// 生成bf的过程
/*
1. 如果没有key,记录当前bf的偏移量result_.size(),直接返回 因为result_中都是bf
2. 否则:start_中记录keys的偏移量 tmp_keys_为start_大小-1
3. 在tmp_keys_中恢复key数据
4. filter_offsets_.push_back(result_.size()); 表示要创建的这个bf是从result_.size()开始的
5. 在result_后增加这次新增的bf
6. 清除数据
*/
void GenerateFilter();
// 初始化过滤器
explicit FilterBlockBuilder(const FilterPolicy*);
// 参数: data在data block中的偏移量
// 1. 得到data在filter block中的位置
// 2. 如果比filter_offsets_.size()多,就要构建一个新的bf
void StartBlock(uint64_t block_offset);
// 1. start_中记录keys的偏移量,是当前key的大小
// 2. keys中记录当前key的数据和长度
void AddKey(const Slice& key);
// 1. 如果当前start_不为空,说明之前是有key加进来但是没有新增bf,调用GenerateFilter()新增bf
// 2. 将所有bf的偏移量加在result_后面
// 3. 将所有bf的偏移量的个数 和 kFilterBaseLg=11 编码参数加在result_后面 1 byte for base_lg_ and 4 for start of offset array
Slice Finish();
2. FilterBlockReader(filter_block.h)
读bf过滤器。
private:
// bf
const FilterPolicy* policy_;
// 指向bf的数据部分
const char* data_;
// 指向bf结尾的数据长度的个数部分
const char* offset_;
// entries的大小
size_t num_;
// bf的编码
size_t base_lg_;
// 参数:bf 和 数据内容
// 1. 如果小于base_lg_1 + 偏移数组 4 = 5 返回
// 2. 解析base_lg_
// 3. last_word只解析前n-5个数
// 4. 解析last_word
FilterBlockReader(const FilterPolicy* policy, const Slice& contents);
// 反解析出对应的数据,使用bf进行判断
// 1. filer offset固定是4个字节
// 2. start:跳转到offset的起始位置
// 3. 解析出数据 使用bf进行判断
bool KeyMayMatch(uint64_t block_offset, const Slice& key);
4. format.h
1. BlockHandle(format.h)
封装了Block的偏移量和数据的大小。为固定的20B
private:
// offset是累加的 是起始地址
// 8 + 8 = 16
uint64_t offset_;
uint64_t size_;
// 16 + 4 = 20
enum { kMaxEncodedLength = 10 + 10 };
// 构造函数 将成员变量初始化为0
BlockHandle();
// 返回偏移量
uint64_t offset();
// 设置偏移量
void set_offset(uint64_t offset);
// 返回大小
uint64_t size();
// 设置大小
void set_size(uint64_t size);
// 将offset_和size_进行编码
void EncodeTo(std::string* dst);
// 将offset_和size_进行解码
Status DecodeFrom(Slice* input);
2. Footer(format.h)
Footer 是文件末尾存储的 SSTable 的一些固定信息,这里实际上就是 metaindex block 和 index block 的大小和文件偏移位置,以及一个 Magic number;
private:
//元数据的偏移量和大小(bloom filter)
BlockHandle metaindex_handle_;
//索引数据的偏移量和大小
BlockHandle index_handle_;
// magic number 用于校验
enum { kEncodedLength = 2 * BlockHandle::kMaxEncodedLength + 8 };
Footer();
// 返回元数据
const BlockHandle& metaindex_handle();
// 设置元数据
void set_metaindex_handle(const BlockHandle& h);
// 返回索引数据
const BlockHandle& index_handle();
// 设置索引数据
void set_index_handle(const BlockHandle& h);
// 将元数据和索引数据进行编码
void EncodeTo(std::string* dst);
// 将元数据和索引数据进行解码
Status DecodeFrom(Slice* input);
3. 其他
BlockContents
将读到的block数据放到BlockContents中。
struct BlockContents {
// 真实的数据部分
Slice data; // Actual contents of data
// true表示可以被缓存
bool cachable; // True iff data can be cached
// true 表示应该调用delete去析构
bool heap_allocated; // True iff caller should delete[] data.data()
};
ReadBlock()
// 1-byte type + 32-bit crc 在block尾部
static const size_t kBlockTrailerSize = 5;
// 先读取到block中的数据所在的偏移量 和 数据大小 , 然后直接读取数据(不包括最后的crc32和compresstype),
// 读一整个block(data block meta & data block & index block)
/*
1. 获取当前存放数据 data 的大小 n
2. 创建n + 5大小的空间存放block的数据
3. 从当前数据的 offset 开始 读取 n + 5 个字节
4. 如果配置了需要crc校验 就进行crc校验
5. 判断第n位是否需要压缩
*/
Status ReadBlock(RandomAccessFile* file, const ReadOptions& options, const BlockHandle& handle, BlockContents* result);
5. block.h
1. Block(block.h)
将一个block中的数据部分(Entry)进行解析。
// 数据内容
const char* data_;
// 数据大小
size_t size_;
// 数据存储的 重启点 (每隔16个会记录一次完整的key值)
uint32_t restart_offset_;
// true 表示需要显示释放内存
bool owned_;
// 数据内容
const char* data_;
// 数据大小
size_t size_;
// 数据部分的长度
uint32_t restart_offset_;
// true 表示需要显示释放内存
bool owned_;
// 反解析出来的实际restarts offset个数
// 数据的最后sizeof(uint32_t) = 4位
uint32_t NumRestarts() const;
// data最后一个保存的是restart总个数,因此最多保留的restart个数(剩余所有的都是restarts offset)
// 解析出数据部分的长度
// 总长度 - (总的restarts offset个数 + 实际restarts offset个数) * 4
explicit Block(const BlockContents& contents);
// 根据owned_对data_进行释放
~Block();
// 返回数据的大小
size_t size() const;
// 新建一个遍历Block数据的迭代器
Iterator* NewIterator(const Comparator* comparator);
2. Iter(block.cc)
<beginning_of_file>
[data block 1]
[data block 2]
...
[data block N]
[meta block 1]
...
[meta block K]
[metaindex block]
[index block]
[Footer] (fixed size; starts at file_size - sizeof(Footer))
<end_of_file>
遍历一个block中的数据部分,遍历block中的每个Entry。
是从后往前遍历的过程。
解析Entry中的一条kv数据的长度字段:
- shared:共享key的长度
- non_shared:非共享key的长度
- value_length:值的长度
/*
p: 开始的位置
limit: 最长限制
shared:共享key的长度
non_shared:非共享key的长度
value_length:值的长度
shared non_shared value_length 经过编码后只占一位!!!
*/
static inline const char* DecodeEntry(const char* p, const char* limit, uint32_t* shared, uint32_t* non_shared, uint32_t* value_length);
// 比较器
const Comparator* const comparator_;
// 数据实体
const char* const data_;
// 实际的数据长度
uint32_t const restarts_;
// 实际数据个数
uint32_t const num_restarts_;
// 当前的位置 初始化为restarts_
uint32_t current_;
// 实际数据下标 初始化为num_restarts_
uint32_t restart_index_;
// 当前entry的key
std::string key_;
// 表示某个Entry(重启点)的起始地址
Slice value_;
// 保存状态
Status status_;
// 使用比较器的比较函数
inline int Compare(const Slice& a, const Slice& b) const;
// 找到下一个Entry的起始点距离开始的偏移量 (当前Entry + 长度 - 起始长度)
inline uint32_t NextEntryOffset() const;
// 反解析出对应数据的偏移量
// 起始地址 + 数据部分的长度 + 下标 * sizeof(uint32_t) = index 数据的偏移量
uint32_t GetRestartPoint(uint32_t index);
// 查找下标为index的Entry
// key_ 清空
// restart_index_ = index
// value_ = index位置
void SeekToRestartPoint(uint32_t index);
// current_ 和 restart_index_ = 最大 返回错误
void CorruptionError();
// 解析下一个Key
bool ParseNextKey();
// 初始化成员变量
// 比较器 数据实体 实际的数据长度(不是连续的) 实际数据个数
Iter(const Comparator* comparator, const char* data, uint32_t restarts, uint32_t num_restarts);
// 当前位置小于最大数据长度
bool Valid();
// 查找key >= target
/*
二分查找:
1. 获取中间Entry的位置
2. 反解析出完整的key
3. 构造Key 比较两个key的大小 判断向前还是向后缩小区间
4. 定位到当前key所在的重启点的位置
5. 如果没有下一个key了 返回
6. 找到当前第一个大于等于目标key的实体 返回
*/
void Seek(const Slice& target);
// 找到下一个key
void Next();
// 找到上一个key
/*
1. 当前数据的重启点大于等于当前位置 一直往前移动
1. 当前block没有数据了 返回false
2. 否则下标--
2. 找到上一个Entry开始位置
3. 查找上一个Entry的最后一个key
*/
void Prev();
// 下一个kv的key
Slice key();
// 下一个kv的value
Slice value();
// 返回状态
Slice status();
// 找到block中的第一个key
/*
1. 定位到第一个Entry
2. 找下一个key
*/
void SeekToFirst();
// 找到block中的最后一个key
/*
1. 定位到最后一个Entry
2. 找最后一个key
*/
void SeekToLast();
6. filter_block.h
1. FilterBlockBuilder(filter_block.h)
Filter block用于提高 sstable 的读取效率,目前leveldb中使用的Filter算法是布隆过滤器。
FilterBlockBuilder中也保存了一份data block的key,因为要构建bf。
// 2的11次 = 2kb
static const size_t kFilterBaseLg = 11;
// 2kb
static const size_t kFilterBase = 1 << kFilterBaseLg;
// bf过滤器
const FilterPolicy* policy_;
// 平铺的keys
std::string keys_;
// 每个key在keys_中的起始位置(偏移量)
std::vector<size_t> start_;
// 以追加的方式构建的filter二进制数据
// 就是对应每2kb数据进行bf过滤器计算的二进制数据
// result_中存放着很多个bf过滤器,其中每个bf过滤器都是以2kb原始数据计算得来的
std::string result_;
// 以2kb的数据创建一个filter 记录filter的偏移量
// 这个就是对result_中的bf过滤器的偏移量进行记录
std::vector<uint32_t> filter_offsets_;
// 把keys_和start_恢复出来的数据放到CreateFilter()的入参中
std::vector<Slice> tmp_keys_;
// 生成filter Bloom Filter 生成bf的过程
/*
1. key偏移量的个数 num_keys
2. 如果num_keys个数为0 直接添加偏移量 返回
3. 更新start_中的偏移量 重新开启tmp_keys_的空间
4. 将keys中的key通过start_中的偏移量还原到tmp_keys_中
5. 添加新构建bf的偏移量 在result_后构建bf
6. 清空 tmp_keys_ keys:keys_ start_
*/
void GenerateFilter();
// 初始化过滤器
explicit FilterBlockBuilder(const FilterPolicy*);
// 根据datablock的偏移量来构建新的filterblock
// 参数: data 的 偏移量
/*
1. 拿到block_offset依稀量的下标
2. 如果下标比 当前保存的bf个数还多 说明是新的数据,还没有构建bf, 于是构建bf --> GenerateFilter()
*/
void StartBlock(uint64_t block_offset);
// 增加key到待创建的filterblock中
/*
1. 在start_中添加key的偏移量
2. 在keys_中添加key
*/
void AddKey(const Slice& key);
// 结束当前block的构建,进行收尾操作
/*
1. 如果start_中不为空 将当前的数据进行构建一个bf
2. 遍历filter_offsets_数组,将每个bf的长度编码放到result_中
3. 将bf的个数编码放到result_中
4. 将bf保存的数据大小(11-->2kb)放到result_中
*/
Slice Finish();
2. FilterBlockReader(filter_block.h)
读取FilterBlock。
// bf策略
const FilterPolicy* policy_;
// 指向第一个bf的地址
const char* data_;
// 指向保存bf偏移量的开始
const char* offset_;
// bf的个数
size_t num_;
// bf映射的data block的大小
size_t base_lg_;
// 解析contents中的数据
/*
1. 如果contents长度小于5 直接返回
有1byte(size_t)的 filter block的大小 和 4byte的偏移量个数
2. base_lg_保存filter block的大小
3. 解析记录 bf位置的偏移量
4. 如果结果比n-5还大 不合法
5. data_指向bf的开始 offset_指向bf偏移量的开始 num_为bf的个数(每个偏移量个数都是4byte)
*/
FilterBlockReader(const FilterPolicy* policy, const Slice& contents);
// 反解析出对应的数据,使用bf进行判断key是否在当前的bf中
// 参数: block_offset是data block的偏移量
/*
1. 当前block_offset在第几个bf中
2. start跳转到保存该bf位置的起点 limit为终点
3. 如果位置合法
找到bf的内容 交给policy_判断是否在当前的bf中
如果不全法 返回false
*/
bool KeyMayMatch(uint64_t block_offset, const Slice& key);
7. iterator_wrapper.h
见include/leveldb/iterator.h/IteratorWrapper。
8. table_builder.cc
1. Rep
保存构建table中各个模块中的配置信息。
就是单纯的封了一层。
// table配置
Options options;
// index_block配置
Options index_block_options;
// 写文件对象
WritableFile* file;
// 当前的起始地址
uint64_t offset;
// 状态
Status status;
// 构建data_block
BlockBuilder data_block;
// 构建index_block
BlockBuilder index_block;
// 保存上一个key
std::string last_key;
// 数据个数
int64_t num_entries;
// 关闭的状态
bool closed;
// 构建filter_block
FilterBlockBuilder* filter_block;
// 用来控制index block的刷新
bool pending_index_entry;
// 使用一块全局的BlockHandle代表indexblock 在每次添加datablock的时候 更新数据
// 然后在插入相应的datablock之后 写入index_block
BlockHandle pending_handle; // Handle to add to index block
// block压缩后的结果
std::string compressed_output;
// 所有配置设为opt file为f filter_block是opt中的
Rep(const Options& opt, WritableFile* f);
2. TableBuilder
<beginning_of_file>
[data block 1]
[data block 2]
...
[data block N]
[meta block 1]
...
[meta block K]
[metaindex block]
[index block]
[Footer] (fixed size; starts at file_size - sizeof(Footer))
<end_of_file>
// 保存table对应的配置
Rep* const rep_;
// 返回状态
bool ok() const { return status().ok(); }
// block写入最后一块数据
/*
1. 设置block_contents的起始位置 和 block_contents的大小 并写入文件
2. 在block尾部 1-byte type + 32-bit crc
设置标志位 设置CRC校验
block尾部写入block
写入成功 更新当前的偏移量
*/
void WriteRawBlock(const Slice& data, CompressionType, BlockHandle* handle);
// 将block全部写入文件
/*
1. 在data后添加重启点数据
2. 根据配置 选择压缩或者不压缩
3. 更新handle 添加尾部type+crc 压缩空间清空
4. 重置文件的offset和当前数据的大小
*/
void WriteBlock(BlockBuilder* block, BlockHandle* handle);
// 初始化rep_中的参数
TableBuilder(const Options& options, WritableFile* file);
// 改变相同比较器的其他配置信息
Status ChangeOptions(const Options& options);
// 写入data_blockk(真正写入) 和filter_block(写入到FilterBlockBuilder中)
/*
1. 确保data_block不为空
2. 写入data_block 更新pending_handle
3. 写入成功 pending_index_entry = true 表示已经写入了data_block 并进行刷盘Flush
4. 写入filter_block的偏移量(起始位置) 生成bf
*/
void Flush();
// Table中新增数据
/*
--> data_block(真正写入)
key --> filter_block(写入到FilterBlockBuilder中)
--> index_block(更新)
1. 确保新增的key大于Table中key的最大值
2. 如果pending_index_entry = true 表示已经写入了data_block 下面要写入相就的indexblock
找到最短距离最近的key存储下来
把pending_handle写进index_block中
pending_index_entry = false 表示应该写入datablock了
3. 将key写入到filterblock(用于构建bf)
4. 设置当前SST中的最大key last_key = key 数据个数++
5. 将key写入到data_block中
6. 如果data_block超过了block的阈值 Flush()
1. 确保data_block不为空
2. 写入data_block 更新pending_handle
3. 写入成功 pending_index_entry = true 表示已经写入了data_block 并进行刷盘Flush
4. 写入filter_block的偏移量(起始位置) 生成bf
*/
void Add(const Slice& key, const Slice& value);
// 返回构建过程中的状态位
Status status() const;
// 完成SST的写入
/*
1. 写入data_blockk(真正写入) 和filter_block(写入到FilterBlockBuilder中)
2. 在配置中设置文件的关闭状态
3. filter_block(真正写入)
4. 写入bf的名字和bf索引meta_index_block
5. 写入index block
6. 写入footer
*/
Status Finish();
// 在配置中设置文件的关闭状态
void Abandon();
// 返回SST所有数据个数
uint64_t NumEntries() const;
// 返回SST的大小
uint64_t FileSize() const;
9. table.cc
1. Rep
// Table相关的参数信息
Options options;
// Table相关的状态信息
Status status;
// Table所持有的文件
RandomAccessFile* file;
// Table本身对应的缓存id
uint64_t cache_id;
// filter block块的读取
FilterBlockReader* filter;
// 保存对应的filter数据
const char* filter_data;
// 解析保存metaindex_handler
BlockHandle metaindex_handle; // Handle to metaindex_block: saved from footer
// index block数据
Block* index_block;
~Rep() {
delete filter;
delete[] filter_data;
delete index_block;
}
2. Table
// 保存table对应的配置
Rep* const rep_;
// 删除arg block
static void DeleteBlock(void* arg, void* ignored);
// 删除value block
static void DeleteCachedBlock(const Slice& key, void* value);
// 释放缓存 arg 中的Handle h
static void ReleaseBlock(void* arg, void* h);
private:
// 初始化配置信息
explicit Table(Rep* rep);
// 找到key 并调用handle_result处理
/*
1. 新建index_block的迭代器 查找到k索引的位置
2. 找到k对应的value
3. 从block对应的迭代器中找到k
4. 调用handle_result函数 处理key 和 value
*/
Status InternalGet(const ReadOptions&, const Slice& key, void* arg, void (*handle_result)(void* arg, const Slice& k, const Slice& v));
// 读取Meta Data bf内容
/*
1. 如果配置中没有过滤策略 返回
2. 保存 积极性检查的配置
3. 将数据从rep_->file中读到block中
4. 实例化Block对象 实例化Block的迭代器 解析过滤器名
5. 读取数据
*/
void ReadMeta(const Footer& footer);
// 读取一块block内容
/*
1. 将参数解析成BlockHandle
2. 保存 积极性检查的配置
3. 将数据从rep_->file中读到block中
4. 保存数据内容 需要显示释放
5. 实例化filter指针
*/
void ReadFilter(const Slice& filter_handle_value);
public:
// 将文件以table的格式进行读取
/*
1. 如果文件长度小于footer的长度 返回
2. 从尾部解析出,Footer的固定长度的内容
3. 二进制数据反序列化footer内容
4. 保存 积极性检查的配置
5. 根据footer中的index_handle解析出index block内容
6. 根据index block内容实例化index_block对象
实例化空的Rep配置 初始化Rep配置
*/
static Status Open(const Options& options, RandomAccessFile* file, uint64_t file_size, Table** table);
// 释放rep_实例
~Table();
// 返回两层的迭代器对象
Iterator* NewIterator(const ReadOptions&) const;
// 查找key的偏移量
/*
1. 先实例化index_block的迭代器 并查找key的位置
2. 声明一个结果
3. 如果找到key的位置 对key的值进行解析
如果中间调用错误 返回index的起始位置
4. 如果找不到key的位置 返回index的起始位置
*/
uint64_t ApproximateOffsetOf(const Slice& key) const;
struct Rep;
// 返回index_value对应block的迭代器
/*
1. 将index_value解析到handle中
2. 如果配置了缓存 就先在缓存中找
1. 编码 cache_id缓存id和BlockHandle的位置
2. 在缓存中查找 序列化后的BlockContents 的内容
1. 如果找到 直接保存block
2. 如果没找到 读取文件
构造block 加入到缓存中
3. 如果没有配置缓存 直接在文件中查找 构造block
4. 用迭代器查找对应的block,删除block 或者 block_cache
*/
static Iterator* BlockReader(void*, const ReadOptions&, const Slice&);
10. two_level_iterator.h
见include/leveldb/iterator.h/TwoLevelIterator。
11. merger.h
见include/leveldb/iterator.h/MergingIterator。
















 359
359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











