










解析一个网页时,常常需要有特定的需要,而对于Extractor而言,是将网站上所有网页全部抓取下来,所以通过扩展Extractor来抓取特定的网页。
Extractor:
package org.archive.crawler.extractor;
/*
*Extractor:抓取网页时,将网页上的所有信息都抓取下来,没有任何的格式选择
*/
import java.util.logging.Level;
import java.util.logging.Logger;
import org.archive.crawler.datamodel.CrawlURI;
import org.archive.crawler.framework.Processor;
public abstract class Extractor extends Processor {//继承自Processor类
private static final long serialVersionUID = 1L;
private static final Logger logger = Logger
.getLogger(Extractor.class.getName());
/**
* Passthrough constructor.
*
* @param name
* @param description
*/
public Extractor(String name, String description) {//构造函数
super(name, description);//调用父类的构造函数
}
public void innerProcess(CrawlURI curi) {//内部实现
try {
extract(curi);//抓取链接
} catch (NullPointerException npe) {
// both annotate (to highlight in crawl log) & add as local-error
curi.addAnnotation("err=" + npe.getClass().getName());
curi.addLocalizedError(getName(), npe, "");
// also log as warning
logger.log(Level.WARNING, getName() + ": NullPointerException",
npe);
} catch (StackOverflowError soe) {
// both annotate (to highlight in crawl log) & add as local-error
curi.addAnnotation("err=" + soe.getClass().getName());
curi.addLocalizedError(getName(), soe, "");
// also log as warning
logger.log(Level.WARNING, getName() + ": StackOverflowError", soe);
} catch (java.nio.charset.CoderMalfunctionError cme) {
// See http://sourceforge.net/tracker/index.php?func=detail&aid=1540222&group_id=73833&atid=539099
// Both annotate (to highlight in crawl log) & add as local-error
curi.addAnnotation("err=" + cme.getClass().getName());
curi.addLocalizedError(getName(), cme, ""); // <-- Message field ignored when logging.
logger.log(Level.WARNING, getName() + ": CoderMalfunctionError",
cme);
}
}
//定义一个extract()抽象类,用于子类的实现
//所有的Extractor继承自它后,只需要实现extract()方法就可以了
protected abstract void extract(CrawlURI curi);
/*
* 扩展Extractor:
* 1、写一个类,继承Extractor的基类
* 2、在构造函数中,调用父类的构造函数,以形成完整的家族对象
* 3、继承extrac(curi)方法
* */
}
ExtractorSohu:
package org.archive.crawler.extractor;
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.archive.crawler.datamodel.CrawlURI;
import org.archive.io.ReplayCharSequence;
import org.archive.util.HttpRecorder;
public class ExtractorSohu extends Extractor {
private static final long serialVersionUID = -7914995152462902519L;
public ExtractorSohu(String name, String description) {//构造函数
super(name, description);//调用父类的构造函数
}
public ExtractorSohu(String name) {//构造函数
super(name, "sohu news extractor");
}
//<a class="" href="xxxx" target="_blank">
//http://news.sohu.com/20131020/n388534488.shtml
//private static final String A_HERF = "<a(.*)href\\s*=\\s*(\"([^\"])\"|[^\\s>])(.*)>";
//用于匹配所有的<a href="xxx">
private static final String A_HERF = "<a(.*)href\\s*=\\s*(\"([^\"]*)\"|[^\\s>])(.*)>";
//用于匹配新闻的格式
private static final String NEWS_SOHU = "http://news.sohu.com/(.*)/n(.*).shtml";
@Override
//实现extract()方法
protected void extract(CrawlURI curi) {
/*
* 下面一段代码主要用于取得当前链接的返回字符串,以便对内容进行分析时使用
* */
String url = "";
try {
HttpRecorder hr = curi.getHttpRecorder();
if(hr == null){
throw new IOException("HttpRecorder is null");
}
ReplayCharSequence cs = hr.getReplayCharSequence();
if(cs == null){
return;
}
String context = cs.toString();//将网页内容转换成字符串形式
//将字符串内容进行正则匹配
//取出其中的链接信息
Pattern pattern = Pattern.compile(A_HERF, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(context);
//若找到一个链接
while(matcher.find()){
url = matcher.group(2);
System.out.println("url:"+url);
url = url.replace("\"", "");
//查看是否为sohu新闻的格式
if(url.matches(NEWS_SOHU)){
System.out.println("true");
//若是,则将链接加入队列中
//以备后续处理
curi.createAndAddLinkRelativeToBase(url, context, Link.NAVLINK_HOP);
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
在Exreactor类开发完毕后,如果使用webUI的方式启动heritrix,并让它出现在下拉选项中,则需要修改eclipse工程下的modules目录下的Processor.options文件:
添加:org.archive.crawler.extractor.ExtractorSohu|ExtractorSohu
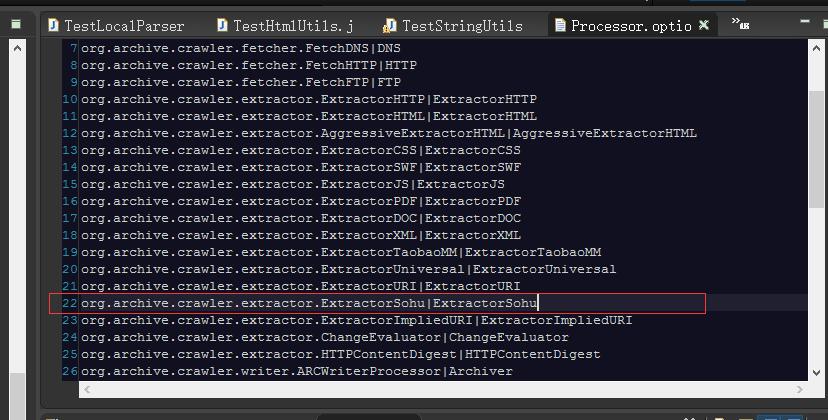
再次启动heritrix时,创建任务后,就可以选在自己开发的Extractor。















 341
341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









