







顺序表和链表
1.线性表
线性表 (linear list) 是n个具有相同特性的数据元素的有限序列。线性表是一种在实际中广泛使用的数据结构,常见的线性表:顺序表、链表、栈、队列、字符串…
线性表在逻辑上是线性结构,也就说是连续的一条直线。但是在物理结构上并不一定是连续的, 线性表在物理上存储时,通常以数组和链式结构的形式存储。
2.顺序表
2.1概念及结构
顺序表是用一段物理地址连续的存储单元依次存储数据元素的线性结构,一般情况下采用数组存储。在数组上完成数据的增删查改。
顺序表就是数组,要求数据是连续存储的
2.2分类
1.静态顺序表(不常用)
//静态顺序表(不太实用)
#define N 10 //N大了会造成浪费,N小了不够用,因此在使用中使用静态的更少
typedef int SLDataType; //这里的目的是方便处理不同类型的顺序表
typedef struct SeqList { //重命名,将struct SeqList结构体类型命名为SL
SLDataType a[N];
int size; //记录储存有多少个有效数据
}SL;
void SLInit(SL s); //初始化
void SLPushBack(SL s, SLDataType x); //尾插法
2.动态顺序表
2.3动态顺序表
1.动态存储实现
即使用动态空间开辟的顺序表
静态顺序表只适用于确定知道需要存多少数据的场景。静态顺序表的定长数组导致N定大了,空间开多了浪费,开少了不够用。所以现实中基本都是使用动态顺序表,根据需要动态的分配空间大小,所以下面我们实现动态顺序表。
//动态顺序表:按需扩展空间
typedef int SLDataType;
typedef struct SeqList {
SLDataType* a; //指向动态开辟的数组,这里a理解为数组名,代表首元素地址
int size; //记录储存有多少个有效数据
int capacity; //空间容量的大小
}SL;
注意:
1.我们在实现顺序表时,一共需要三种数据结构:数组a[],当前数值个数size,数组总容量capacity。
2.此外,为什么要typedef一下数组类型呢?
因为今后我们在开辟数组内容的时候并不一定是int型的,若要处理不同类型的数据,我们只需要改一下SLDateTpye,就能实现
2.函数功能与声明
void SLInit(SL* ps); //初始化
void SLDestroy(SL* ps); //删除
void SLPushBack(SL* ps, SLDataType x); //尾插
void SLPopBack(SL* ps); //尾删
void SLPushFront(SL* ps, SLDataType x); //头插
void SLPopFront(SL* ps); //头删
void SLInsert(SL* ps, int pos, SLDataType x); //中间插入
void SLErase(SL* ps, int pos); //中间删除
int SLFind(SL* ps, SLDataType x); //寻找值x
int SLFind2(SL* ps, SLDataType x,int begin); //寻找所有x
//打印顺序表内元素
void SLprint(SL* ps);
//检查容量是否够:由于多数函数涉及检查容量这方面的问题,因此我们将公共的函数提取出来
void SLCheckCpacity(SL* ps);
2.1顺序表的初始化
我们定义一个 struct SeqList(后简称位SL)类型的指针来创建顺序表,对其初始化的意思即为设置它的大小、元素个数为0,数组指针置为NULL
void SLInit(SL *ps){
assert(ps);
ps->a=NULL;
ps-size=0;
ps->capacity=0;
}
2.2顺序表的销毁
将顺序表的开辟的空间从内存中释放,并将此顺序表大小及元素个数设为0;
void SLDestroy(SL* ps){
assert(ps);
if(ps->a!=NULL){
free(ps->a);
ps->a=NULL;
ps->size=ps->capacity=0;
}
}
2.3尾插
从尾部插入一个元素,那么此时就要考虑顺序表容量问题,若顺序表满了(size=capacity),那么则将此顺序表扩容二倍,但若顺序表是空表(没有开辟空间,即需要重新开辟空间),我们通过realloc即可以实现扩容,又可以实现开辟空间
void SLPushBack(SL* ps, SLDataType x){
assert(ps);
if(ps->size==ps->capacity){
int newCapacity=ps->capaciyu==0?4:newCapacity=capacity*2;
SLDataType* tmp=(SLDataType*)realloc(ps->a,newCapacity*sizeof(SLDataType));
if(tmp==NULL){
perror("realloc fail");
exit(-1);
}
else{
ps->a=tmp;
}
}
ps->a[ps->size]=x;
ps->size++;
}
2.4尾删
首先需要判断顺序表是否是空表,若不是空白则直接删除并将顺序表size–即可
void SLPopBack(SL* ps){
assert(ps->size=0);
ps->a[ps->size-1]=0;
ps->size--; //这就是删除的本质
}
2.5头插
从头部插入,关键点在于判断空间大小以及将每个元素后移一位
我们这里会发现:【检验空间是否足够/为空------>开辟空间/扩容】的操作也在这里出现了,因此我们不妨将这个操作给封装到函数中
我们还需要考虑数据的挪动方式:从最后一个元素开始向后挪动
void SLCheckCapacity(SL *ps){
if(ps->size==ps->capacity){
int newCapacity=ps->capacity==0?4:ps->capacity*2;
SLDataType* tmp=(SLDataType*)relloc(newCapacity*sizeof(SLDataType));
if(tmp==NULL){
perror("realloc fail");
exit(-1);
}
else{
ps->a=tmp;
}
}
}
void SLPushFront(SL* ps, SLDataType x) {
assert(ps);
SLCheckCapacity(ps);
int end=ps->size-1;
while(end>=0){
ps->a[end+1]=ps->a[end];
end--;
}
ps->a[0]=x;
ps->size++;
}
2.6 头删
将后续的元素向前移动,但是我们需要注意当表中一个元素都没有时(ps->size=0),可能会导致越界问题但编译时不一定会报错,因此我们仍然采用断言的方式;
void SLPopFront(SL* ps){
assert(ps->size>0);
int begin=0;
while(begin<ps->size-1){
ps->a[begin]=ps->a[begin+1];
begin++;
}
ps->size--;
}
2.7在下标为pos位置插入元素x
插入的元素思路很简单,即检查插入位置是否合法后,插入时都需要检查空间大小是否足够,再移动位置即可;
条件:pos>=0&&pos<=size(采用断言的方式来判断);再移动后续的元素即可
void SLInsert(SL *ps,int pos,SLDataType x){
assert(pos>=0);
assert(pos<=ps->size);
SLCheckCapacity(ps);
int end=ps->size-1;
while(end>=pos){
ps->a[end+1]=ps->a[end];
end--;
}
ps->a[pos]=x;
ps->size++;
}
2.8删除下标为pos位置的元素
判断删除位置是否合法,再移动元素(删除的本质)
void SLErase(SL* ps,int pos){
assert(pos>=0);
assert(pos<=ps-size-1);
int begin=pos;
while(begin<ps->size-1){
ps->a[begin]=ps->a[begin+1];
begin++
}
ps->size--;
}
2.9寻找元素值为x的元素并返回其下标
遍历找到值x并返回即可
int SLFind(SL* ps,SLDataType x){
assert(ps);
for(int begin=0;begin<ps->size;begin++){
if(ps->a[begin]==x){
return begin;
}
}
return -1;
}
另一个:若要设计一个能找到所有值为x的函数呢
思路是找到一个后,每次继续向后找,并返回
int SLFind2(SL* ps,SLDataType x,int begin){
assert(ps);
for(int i=begin;i<ps->size;i++){
if(ps->a[i]==x){
return i;
}
}
return -1;
}
int mian(){
int pos=SLFind2(&sl,4,0);
while(pos!=-1){
//操作
printf("%d",pos);
pos=SLFind2(&sl,4,pos); //每一次找到一个,就从找到的那个位置继续开始寻找
}
}
【注意】:
顺序表头插和尾插时间复杂度不同:头插:O(N) 尾插:O(1)
查越界的检查是运行时检查,由于编译器的检查点不同,越界不一定会报错,特别是在越界读取时,一般不会报错(检查方式:检查值(随机值)是否被改变)
3.单链表
1.单链表的引入
首先,链表是由一个个结点构成的,每个结点由两部分组成:数据域(data)与指针域(next),数据域顾名思义即是存放的数据,而指针域即是存放指向下一个同类型结点的地址
因此每一个结点本质就是含有data与next两部分的一个结构,定义如下:
struct SListNode{
int data;
struct SListNode* next;
};
这里我们可以进行优化:①对于数据类型来说,我们使用时不一定存放int类型;②结点类型为:struct SListNode比较复杂,可以重新命名,因此可优化为:
typedef int SLTDataType;
typedef struct SListNode{
SLTDataType data;
struct SListNode* next;
}SLNode;
2.函数的声明与实现
//动态开辟空间是创建结点时必不可少的操作,因此我们将其封装于函数中(x代表data域的值)
SLTNode* CreatSLTNode(SLTDataType x);
//在我们创建结点后,需要将后一个结点的地址传给前一结点的next域
//即处理n个结点间的链接问题
SLTNode* CreatSList(int n);
//遍历链表/打印
void SLTPrint(SLTNode* phead); //phead指向链表首结点
void SLTPushBack(SLTNode** pphead, SLTDataType x); //尾插
void SLTPopBack(SLTNode** pphead); //尾删
void SLTPushHead(SLTNode** phead, SLTDataType x); //头插
void SLTPopHead(SLTNode** phead); //头删
// 查找数据x
SLTNode* SListFind(SLTNode* phead, SLTDataType x);
//在pos位置之后插入数据x
void SLTInsertAfter(SLTNode* pos, SLTDataType x);
//在pos位置之前插入数据x
void SLTInsertBefore(SLTNode** pphead,SLTNode* pos, SLTDataType x);
//删除pos位置之后的数据x
void SLTEraseAfter(SLTNode* pos);
//删除pos位置
void SLTErase(SLTNode** pphead, SLTNode* pos);
//单链表的释放
void SLTDestroy(SLTNode** pphead);
2.1动态开辟空间
SLTNode* CreatSLTNode(SLTDataType x){ //数据域的值为x
SLTNode* newnode=(SLTNode*)malloc(sizeof(SLTNode));
if(newnode==NULL){
perror("malloc fail");
exit(-1);
}
newnode->data=x;
newnode->next=NULL;
return newnode;
}
2.2创建一个有n个结点的链表
SLTNode* CreatSList(int n) {
/*这里的逻辑是创建头节点后由phead和ptail指针指向它,phead用于保存头结点位置
方便找到整个链表,而ptail在每次创建后都指向链表的尾结点,用于下一个结点的创建
*/
SLTNode* phead = NULL; //头指针
SLTNode* ptail = NULL;
int x = 0;
for (int i = 0; i < n; i++)
{
//scanf("%d", &x);
SLTNode* newnode = CreatSLTNode(i); //这里的值可以自定
if (phead == NULL) {
phead = ptail = newnode; //都指向首结点
}
else {
ptail->next = newnode; //上一结点的next域存下一结点
ptail = newnode; //ptail指针指向新结点(尾结点)
}
}
return phead; //需要存首结点的位置才能找到链表
}
2.3遍历打印链表中结点数据值
一般的我们有了头结点的地址即可遍历整个链表,但是从代码习惯上来说,建议每次使用时单独定义一个指针来代替指向头节点的指针来遍历链表,这样如果后续代码需要头节点地址就能直接拿出来
void SLPrint(SLTNode* phead){
SLTNode* cur=phead;
while(cur!=NULL){
printf("%d->",cur->data);
cur=cur->next;
}
printf("NULL\n");
}
2.4尾插元素x
对于链表来说,链表最重要的即是头节点的地址,有了头节点指针,就可以通过每个结点的next域找到下一个结点了;因此在尾部插入一个元素时,我们首先创建一个数据域为x,next域为NULL的结点,然后使用指针保存头节点位置,然后依次向后挪动找到尾结点;而有一种情况我们需要考虑;就是当链表为空时又该如何插入元素?
void SLTPushBack(SLTNode* phead,SLTDataType x){
SLTNode* newnode=CreatSLTNode(x);
if(phead==NULL){
phead=newnode; //标准的错误
}
else{
SLTNode* ptail=phead;
while(ptail->next!=NULL){
ptail=ptail->next;
}
ptail->next=newnode;
}
}
这里存在一个很标准的错误:

假设在调用函数时,通过pList将首结点地址传给函数;那么phead即是pList的一份临时拷贝,我们让phead指向我们开辟的结点,在函数调用结束后栈销毁,不会修改pList所指向的位置,因此这里我们需要使用二级指针来实现对pList的修改:
void SLTPushBack(SLTNode** pphead,SLTDataType x){
SLTNode* newnode=CreatSLTNode(x);
if(*pphead==NULL){
*pphead=newnode;
}
else{
SLTNode* ptail=*pphead;
while(ptail->next!=NULL){
ptail=ptail->next;
}
ptail->next=newnode;
}
}
此时再调用函数时,传入的是pList指针的地址了
SLTPushBack(&pList,10);
2.5尾删
同样的原因,当只有一个结点时,即对phead直接进行操作,这样就会导致出现形参无法修改实参的问题,因此同样的这里需要二级指针
void SLTPopBack(SLTNode** pphead) {
assert(*pphead); //断言:空链表不能被删除
if (NULL == (*pphead)->next) {
free(*pphead);
*pphead = NULL;
}
else{
SLTNode* ptail=*pphead;
while(ptail->next->next!=NULL){
ptail=ptail->next;
}
free(ptail->next);
ptail->next=NULL;
}
}
同学们请留意这段代码:

请注意,这里循环的条件是ptail->next->next!=NULL,所以当循环结束时,ptail指针指向的是倒数第二个结点,因此patil->next保存的是最后一个结点的地址,free后再置为空指针即可完成删除
2.6头插
头插相对容易,只需要新建一个数据域为data的结点,让它的next域指向头节点并让头节点指针指向它即可,而修改头节点phead即是修改pList因此还是需要二级指针
void SLTPushHead(SLTNode** pphead,SLTDataType x){
SLTNode* newnode=CreatSLTNode(x);
newnode->next=*pphead;
*pphead=newnode;
}
2.7头删
删去头部元素,涉及到对头指针操作,因此只需使用二级指针即可
void SLTPopHead(SLTNode** pphead){
assert(*pphead);
SLTNode* next=*pphead->next;
free(*pphead);
*pphead=next;
}
2.8查找数据x
查找的关键,即在遍历整个链表后,返回数据域值为x的结点的地址
SLTNode* SListFind(SLTNode* phead,SLTDataType x){
SLTNode* cur=phead;
//链表为空,就没有查找到,返回空指针,因此这里不用断言
while(cur){
if(cur->data==x){
return cur;
}
cur=cur->next;
}
return NULL;
}
2.9在pos位置之后插入x
首先,pos是一个结点地址,要想获得结点地址,一般的是通过【查找】操作获得的;pos位置可以是任何结点,修改pos的next域即可,因此这里不需要使用二级指针;再因为pos不可能为空,因此需要断言
void SLTInsertAfter(SLTNode* pos,SLTDataType x){
assert(pos);
SLTNode* newnode=CreatSLTNode(x);
//这里插入时先修改newnode的next再修改pos,否则就找不到原pos的下一个结点了
newnode->next=pos->next;
pos->next=newnode;
}
2.10在pos位置之前插入x
这里就需要注意了,因为如果pos位置是首结点,那么就相当于是头插,那么需要修改phead的地址,因为形参无法修改实参,因此这里需要使用二级指针、并对头插的情况单独作讨论
void SLTInsertBefore(SLTNode** pphead,SLTNode* pos,SLTDataType x){
assert(pos);
//相当于头插,可直接调用头插函数
if(*pphead=pos){
SLTPushHead(pphead,x);
}
else{
//需要知道pos之前的结点
SLTNode* prev=*pphead;
while(prev->next!=pos){
prev=prve->next;
}
//创建结点并插入
SLTNode* newnode=CreatSLTNode(x);
prev->next=newnode;
newnode->next=pos;
}
}
2.11删除pos位置之后的结点
首先我们对pos位置作限定:pos不能为空,且pos不能在尾结点(pos位置之后没有元素结点),而且删除一般需要保存待删除结点的下一个结点的地址,防止找不到下一个结点/或者是保存待删除结点的地址
void SLTEraseAfter(SLTNode* pos){
assert(pos);
if(pos->next==NULL){
return;
}
else{
//保存待删除结点的地址
SLTNode* nextnode=pos->next;
pos->next=pos->next->next;
free(nextnode);
nextnode=NULL;
}
}
2.12删除pos位置的结点
同理,如果pos的位置位于首结点,那么就会涉及到头删,即修改phead指针的地址,因此需要使用二级指针
void SLTErase(SLTNode** pphead,SLTNode* pos){
assert(pos);
if(pos==*pphead){
SLTPophead(pphead);
}
else{
SLTNode* prev=pphead;
while(prev->next!=pos){
prev=prve->next;
}
prve->next=pos->next;
free(pos);
pos=NULL; //pos是形参,修改无效,但这里也没必要置空
}
}
2.13释放单链表
释放单链表需要一个结点一个结点的释放,最终要的是要把首结点地址置空,防止野指针
void SLTDestroy(SLTNode** pphead){
SLTNode* cur=*pphead;
while(cur){
SLTNode* nextnode=cur->next;
free(cur);
cur=nextnode;
}
//首结点指针成为了野指针,因此需要置空
*pphead=NULL;
}
【总结】:链表最核心的即是首结点地址,通过首结点地址即可访问整个链表,因此在链表销毁时,在释放它的内存空间后,一定要将其置为空指针,防止非法访问
4.带头双向循环链表
1.引入
实际中链表的结构非常多样,以下情况组合起来就有8种链表结构
虽然有这么多的链表的结构,但是我们实际中最常用还是两种结构:
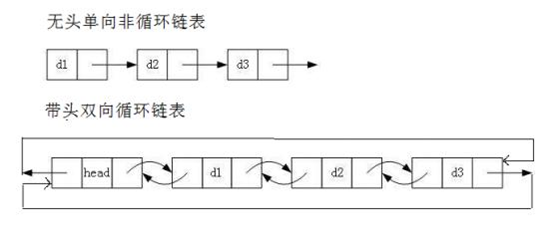
①无头单向非循环链表: 结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结 构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
②带头双向循环链表: 结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都 是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了,后面我们代码实现了就知道了。(结构带来的优势)
这里我们讨论最复杂的结构:带头双向循环链表
其结点的结构如下:
typedef int LTDatatype;
typedef struct ListNode
{
struct ListNode* next;
struct ListNode* prev;
LTDatatype data;
}LTNode;
因此在实现与单链表同样的操作时,带头双向循环链表由于其结构特点,要比单链表更好的实现功能
2.函数的声明与实现
//创建
LTNode* CreatListNode(LTDatatype x);
//初始化
LTNode* ListInit();
//打印遍历链表
void LTPrint(LTNode* phead);
void LTPushBack(LTNode* phead,LTDatatype x); //尾插
void LTPopBack(LTNode* phead); //尾删
void LTPushHead(LTNode* phead, LTDatatype x); //头插
void LTPopHead(LTNode* phead); //头删
//寻找值为x的结点
LTNode* LTFind(LTNode* phead, LTDatatype x);
//在pos之前插入x
void LTInsert(LTNode* pos, LTDatatype x);
void LTInsertHead(LTNode* phead, LTDatatype x); //改写头插
void LTInsertBack(LTNode* phead, LTDatatype x); //改写尾插
//删除pos位置的结点
void LTErase(LTNode* pos);
void LTEraseHead(LTNode* phead); //改写头删
void LTEraseBack(LTNode* phead); //改写尾删
//判断链表是否为空
bool LTEmpty(LTNode* phead);
//求链表结点数
size_t LTSize(LTNode* phead);
//销毁链表
void LTDestroy(LTNode* phead);
2.1创建结点
目标:动态开辟空间,并调整结点的prev域和next域,设置data域
LTNode* CreatListNode(LTDataType x){
LTNode* newnode=(LTNode*)malloc(sizeof(LTNode));
if(newnode==NULL){
perror("malloc fail");
exit(-1);
}
newnode->next=x;
newnode->prev=NULL;
newnode->next=NULL;
}
2.2初始化结点
对于【带头结点】的链表来说,对这种类型链表的初始化就是创建头节点(哨兵位)、由于我们创建的链表还有双向循环的特点,因此有prev域和next域;在只有一个结点时吗,它们指向结点自己
在创建结点后,在空间中已经有了这个结点,但是我们并没有根据链表的特点来定义成员,对于单个的结点来说,它的next域和prev域指向的是它自己,我们由此性质,来对我们创建的结点进行从初始化
这里是带头结点的(哨兵位),因此在下面描述中,phead一直指向哨兵位;
LTNode* ListInit(){
LTNode* phead;
phead=CreatListNode(-1);
phead->next=phead;
phead->prev=phead;
return phead;
}
2.3打印输出链表
遍历链表即可
注意结束遍历的条件:尾结点的next域指向头结点(phead)
void LTPrint(LTNode* phead){
LTNode* cur=phead;
while(cur!=phead){
printf("%d->",cur->data);
cur=cur->next;
}
printf("NULL\n");
}
2.4尾插
这里我们将链表的头节点传给函数(注意是头结点不是首结点),而无论链表是否为空,头节点都是存在的,因此需要断言phead
void LTPushBack(LTNode* phead, LTDatatype x) {
//phead不可能位空:phead指向的是带头结点(哨兵位),因此需要断言
assert(phead);
LTNode* newnode = CreatListNode(x);
LTNode* tail = phead->prev; //找尾结点,用tail指针指向
//插入时,修改指针
tail->next = newnode;
newnode->prev = tail;
phead->prev = newnode;
newnode->next = phead;
//这里的尾插就比单链表更好实现了:不用考虑空表的情况
}
2.5尾删
有一点需要我们注意,就是链表不能为空,而链表为空的特点是头节点的next指向的不是首结点了,而是它自己
因此我们需要两个断言:①头节点phead是否为空,②链表是否为空
void LTPopBack(LTNode* phead) {
assert(phead);
assert(phead->next != phead); //判空
LTNode* tail = phead->prev; //找到尾结点
LTNode* tailPrev = tail->prev; //找到尾结点的前一个结点(作为新的尾结点)
//修改指针,实现双向、循环
tailPrev->next = phead;
phead->prev = tailPrev;
//删除:释放空间
free(tail);
//这里不用像单链表一样,考虑还剩一个结点的情况
}
2.6头插
这里就不用像单链表一样传递二级指针了,因为有头结点
void LTPushHead(LTNode* phead, LTDatatype x) {
assert(phead);
//创建插入结点
LTNode* newnode = CreatListNode(x);
//调整指针位置
//这里因为要先通过phead来找到原第一个结点的地址,因此选择后改phead
//或者说,事先存储phead->next(即第一个结点的地址):顺序无关
newnode->next = phead->next;
phead->next->prev = newnode;
phead->next = newnode;
newnode->prev = phead;
//同理,这里对于空链表,也适合头删,不用作单独讨论
}
2.6头删
void LTPopHead(LTNode* phead) {
assert(phead);
assert(phead->next != phead);
LTNode* first = phead->next;
LTNode* second = first->next;
free(first);
phead->next = second;
second->prev = phead;
//优点:结构自成一体,不用对各种情况做判断
}
2.7查找数据x
遍历即可
LTNode* LTFind(LTNode* phead, LTDatatype x) {
assert(phead);
LTNode* cur = phead->next;
while (cur != phead) {
if (cur->data == x) {
return cur;
}
cur = cur->next;
}
return NULL;
}
2.8pos位置前插入x
void LTInsert(LTNode* pos, LTDatatype x) {
assert(pos);
LTNode* prevnode = pos->prev;
LTNode* newnode = CreatListNode(x);
prevnode->next = newnode;
newnode->prev = prevnode;
newnode->next = pos;
pos->prev = newnode;
//因此,头插可改写为: LTInsert(phead->next, x);
//尾插可改写为:LTInsert(phead, x); phead的prev就是尾结点
}
//改写头插
void LTInsertHead(LTNode* phead, LTDatatype x) {
LTInsert(phead->next, x);
}
//改写尾插
void LTInsertBack(LTNode* phead, LTDatatype x) {
LTInsert(phead, x);
}
2.9删除pos位置结点
void LTErase(LTNode* pos) {
assert(pos);
LTNode* prevnode = pos->prev;
LTNode* nextnode = pos->next;
free(pos);
prevnode->next = nextnode;
nextnode->prev = prevnode;
}
//改写头删
void LTEraseHead(LTNode* phead) {
LTErase(phead->next);
}
//改写尾删
void LTEraseBack(LTNode* phead) {
LTErase(phead->prev);
}
2.10判断链表是否为空
bool LTEmpty(LTNode* phead) {
assert(phead);
//通过比较式的结果即可直接返回
return phead->next == phead;
}
2.11求链表长度
size_t LTSize(LTNode* phead) { //size_t代表unsighed int
assert(phead);
size_t size = 0;
//从首结点开始
LTNode* cur = phead->next;
while (cur != phead) {
size++;
cur = cur->next;
}
return size;
}
2.12销毁链表
void LTDestroy(LTNode* phead) {
assert(phead);
LTNode* cur=phead->next;
while(cur!=phead){
LTNode* nextnode=cur->next;
free(cur);
cur=nextnode;
}
free(phead);
phead=NULL;
//把phead置空无意义:形参的改变不影响实参
//因此提示在调用该函数后,还需在函数外将phead置空
}
5.链表和顺序表的区别
顺序表:
优点:尾插尾删效率高,下标的随机访问
缺点:空间不够需要扩容(扩容代价大);头部或者中间插入删除效率低,需要挪动数据
链表:
优点:需要扩容,按需申请释放小块结点内存;任意位置插入效率很高——O(1)
缺点:不支持下标随机访问
| 不同点 | 顺序表 | 链表 |
|---|---|---|
| 存储空间上 | 物理上一定连续 | 逻辑上连续,但物理上不一定 连续 |
| 随机访问 | 支持O(1) | 不支持: O(N) |
| 任意位置插入或者删除 元素 | 可能需要搬移元素,效率低 O(N) | 只需修改指针指向 |
| 插入 | 动态顺序表,空间不够时需要 扩容 | 没有容量的概念 |
| 应用场景 | 元素高效存储+频繁访问 | 任意位置插入和删除频繁 |
| 缓存利用率 | 高 | 低 |














 2051
2051











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









