







特殊知识
调试脚本
在运行脚本的时候使用
sh -x xx.sh
能跟踪执行信息,将执行脚本的过程中把实际执行的每个命令显示出来,行首显示+, +后面显示经过替换之后的命令行内容,有助于分析实际执行的是什么命令.
这里也相当于打印出来了执行的命令。
shell脚本中设置
- set -x 开启调试
- set +x 禁止调试
bash -n modify_suffix.sh 查看脚本语法是否有错误
执行shell脚本的四种方式
1../test.sh 相对路径下执行
2./data/test.sh 绝对路径下执行
3.bash test.sh or sh test.sh 直接使用bash 或 sh 来执行bash shell脚本
注意,若是以方法三的方式来执行,那么,可以不必事先设定shell的执行权限,甚至都不用写shell文件中的第一行(指定bash路径)。因为方法三是将test.sh作为参数传给sh(bash)命令来执行的。这时不是test.sh自己来执行,而是被人家调用执行,所以不要执行权限。那么不用指定bash路径自然也好理解了。
4.. test.sh or source test.sh 在当前的shell环境中执行bash shell脚本 不需要执行权限
前三种方法执行shell脚本时都是在当前shell(称为父shell)开启一个子shell环境,此shell脚本就在这个子shell环境中执行。shell脚本执行完后子shell环境随即关闭,然后又回到父shell中。而方法四则是在当前shell中执行的。
在Shell中,"$“和”&"的作用
"$"后面引用的时系统变量,
比如 $USER
"&"后面则是一个命令,
比如 echo &date
shell退出后后台程序保持运行 &
在liunx上,如果想让一个进程在后台运行,最直接的方法是用&符号.
比如ping www.baidu.com &
但是这样一来,这个进程便成为了当前shell的一个job,在shell退出时,job会收到一个信号,也随之停止.
处理这个问题,可以使用nohup命令,让job忽略shell的退出信号,也可以采用其他方式.
既然后台命令作为shell的子进程会在shell退出时被杀掉,那么只要不让后台命令作为shell的子进程即可.比较简单的方式是利用subshell来调用后台命令.
比如写个start.sh
#!/bin/bash
ping www.baidu.com &
然后在shell中调用start.sh
./start.sh
我猜测虽然start.sh是ping命令的父进程,但是start.sh运行完毕就退出了,ping命令成了孤儿进程,会被init进程收养.所以退出shell也不会导致ping命令中断
wait
https://blog.csdn.net/yangshangwei/article/details/87691890
等待前边&并行执行完毕
a.sh
sleep 5
echo a
b.sh
sleep 10
echo b
c.sh
./a.sh &
./b.sh &
wait # 如果没有wait 会先打印字母c 然后等待5s打印字母a 在等5s打印b
echo c
在执行c.sh的时候会先等5s打印a字母 在等5s打印字母b 然后打印c 因为a和b是并行所以耗时是10s
nohup
nohup命令:如果你正在运行一个进程,而且你觉得在退出帐户时该进程还不会结束,那么可以使用nohup命令。该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。
在缺省情况下该作业的所有输出都被重定向到一个名为nohup.out的文件中。
- nohup command > myout.file 2>&1 &
在上面的例子中,0 – stdin (standard input),1 – stdout (standard output),2 – stderr (standard error) ;
2>&1是将标准错误(2)重定向到标准输出(&1),标准输出(&1)再被重定向输入到myout.file文件中。
- 0 22 * * * /usr/bin/python /home/pu/download_pdf/download_dfcf_pdf_to_oss.py > /home/pu/download_pdf/download_dfcf_pdf_to_oss.log 2>&1
这是放在crontab中的定时任务,晚上22点时候怕这个任务,启动这个python的脚本,并把日志写在download_dfcf_pdf_to_oss.log文件中
nohup和&的区别
& : 指在后台运行
nohup : 不挂断的运行,注意并没有后台运行的功能,,就是指,用nohup运行命令可以使命令永久的执行下去,和用户终端没有关系,例如我们断开SSH连接都不会影响他的运行,注意了nohup没有后台运行的意思;&才是后台运行
&是指在后台运行,但当用户推出(挂起)的时候,命令自动也跟着退出
那么,我们可以巧妙的吧他们结合起来用就是
nohup COMMAND &
这样就能使命令永久的在后台执行
例如:
-
sh test.sh &
将sh test.sh任务放到后台 ,关闭xshell,对应的任务也跟着停止,标准输出和标准错误信息会丢失(缺少的日志的输出)
-
nohup sh test.sh
将sh test.sh任务放到后台,关闭标准输入,终端不再能够接收任何输入(标准输入),重定向标准输出和标准错误到当前目录下的nohup.out文件,即使关闭xshell退出当前session依然继续运行。 -
nohup sh test.sh &
将sh test.sh任务放到后台,但是依然可以使用标准输入,终端能够接收任何输入,重定向标准输出和标准错误到当前目录下的nohup.out文件,即使关闭xshell退出当前session依然继续运行。
nohup + & 执行的命令如果没有重定向 则在退出当前会话 会将 输出的内容保存到nohup.out文件中,如果有重定向 则不会输出到nohup.out文件中
2>/dev/null和>/dev/null 2>&1和2>&1>/dev/null的区别
https://blog.csdn.net/longgeaisisi/article/details/90519690
2>/dev/null
意思就是把错误输出到“黑洞”
>/dev/null 2>&1
默认情况是1,也就是等同于1>/dev/null 2>&1。意思就是把标准输出重定向到“黑洞”,还把错误输出2重定向到标准输出1,也就是标准输出和错误输出都进了“黑洞”
2>&1 >/dev/null
2>&1 >> $LOG_FILE
意思就是把错误输出2重定向到标准出书1,也就是屏幕,标准输出进了“黑洞”,也就是标准输出进了黑洞,错误输出打印到屏幕
Linux系统预留三个文件描述符:0、1和2,他们的意义如下所示:
0——标准输入(stdin)
1——标准输出(stdout)
2——标准错误(stderr)
$(cd `dirname $0`;pwd)
在命令行状态下单纯执行 $ cd dirname $0 是毫无意义的。因为他返回当前路径的"."。
这个命令写在脚本文件里才有作用,他返回这个脚本文件放置的目录,并可以根据这个目录来定位所要运行程序的相对位置(绝对位置除外)。
/sbin/insmod ./$module.ko $* || exit 1
其中的 ||是或者的意思,因为“短路求值”的关系,若前者执行失败,那么就会执行 exit 1。总的效果就是,如果前者执行失败,脚本就以返回值1退出 。
对于||运算,只要能确定第一个值为true,后续计算也不再进行,而是直接返回true
$() and `` 和 ${}
在 bash shell 中,$()是将括号内命令的执行结果赋值给变量
$( )与``(反引号)都是用来作命令替换的。
是用来作变量替换。一般情况下, {} 是用来作变量替换。一般情况下, 是用来作变量替换。一般情况下,var 与 ${var} 并没有啥不一样。但是用 ${ } 会比较精确的界定变量名称的范围
| 运算符
管道符号,是unix一个很强大的功能,符号为一条竖线:“|”。
用法:
command 1 | command 2
他的功能是把第一个命令command 1执行的结果作为command2的输入传给command 2,例如:
l s − s ∣ s o r t − n r ( 请注意不要复制 ls -s|sort -nr (请注意不要复制 ls−s∣sort−nr(请注意不要复制符号进去哦)
-s 是file size,-n是numeric-sort,-r是reverse,反转
该命令列出当前目录中的文档(含size),并把输出送给sort命令作为输入,sort命令按数字递减的顺序把ls的输出排序。
tee 命令
Linux tee命令用于读取标准输入的数据,并将其内容输出成文件。
tee指令会从标准输入设备读取数据,将其内容输出到标准输出设备,同时保存成文件。
语法:
tee [-ai][--help][--version][文件...]
参数:
- -a或–append 附加到既有文件的后面,而非覆盖它.
- -i或–ignore-interrupts 忽略中断信号。
- –help 在线帮助。
- –version 显示版本信息。
实例:
使用指令"tee"将用户输入的数据同时保存到文件"file1"和"file2"中,输入如下命令:
tee file1 file2 # 在两个文件中复制内容
命令回车后需要输入要存储的内容,然后ctrl+d结束输入,两个文件都会输入相同的内容
echo “123” | tee -a file # 可以将输入的内容,写到file文件中
# 先在屏幕打印出来,然后写入file文件
modprobe 命令
用于自动处理可载入模块。
modprobe可载入指定的个别模块,或是载入一组相依的模块。modprobe会根据depmod所产生的相依关系,决定要载入哪些模块。若在载入过程中发生错误,在modprobe会卸载整组的模块。
参数:
- -a或–all 载入全部的模块。
- -c或–show-conf 显示所有模块的设置信息。
- -d或–debug 使用排错模式。
- -l或–list 显示可用的模块。
- -r或–remove 模块闲置不用时,即自动卸载模块。
- -t或–type 指定模块类型。
- -v或–verbose 执行时显示详细的信息。
- -V或–version 显示版本信息。
- -help 显示帮助。
实例:
安装软驱模块:
modprobe -v floppy
卸载软驱模块:
modprobe -v -r floppy
lsmod
lspci -vv -d baba:
会将baba设备和驱动绑定的信息打印出来
用于显示已载入系统的模块。
执行 lsmod 指令,会列出所有已载入系统的模块。Linux 操作系统的核心具有模块化的特性,因此在编译核心时,务须把全部的功能都放入核心。您可以将这些功能编译成一个个单独的模块,待需要时再分别载入。
#!/bin/sh
make clean; make;
if [ `lsmod | grep -o intel_fpga_pcie_drv` ]
then
./unload
fi
./load
rmmod
用于删除模块
执行 rmmod 指令,可删除不需要的模块。Linux 操作系统的核心具有模块化的特性,应此在编译核心时,务须把全部的功能都放如核心。你可以将这些功能编译成一个个单独的模块,待有需要时再分别载入它们。
#!/bin/sh
rmmod intel_fpga_pcie_drv
# Remove device manually in case udev isn't set up to do so.
rm -f /dev/intel_fpga_pcie_drv # 删除正在使用的模块,比较危险
insmod
用于载入模块
Linux有许多功能是通过模块的方式,在需要时才载入kernel。如此可使kernel较为精简,进而提高效率,以及保有较大的弹性。这类可载入的模块,通常是设备驱动程序。
insmod [-fkmpsvxX][-o <模块名称>][模块文件][符号名称 = 符号值]
# insmod led.o
//向内核加载模块
insmod ice.ko 加载驱动文件
make命令解释
1、make 在moc2.5项目中make可以生成**.ko**驱动文件
根据Makefile编译源代码,连接,生成目标文件,可执行文件。
2、make clean
清除上次的make命令所产生的object文件(后缀为“.o”的文件)及可执行文件。
3、make install
将编译成功的可执行文件安装到系统目录中,一般为/usr/local/bin目录。
4、make dist
产生发布软件包文件(即distribution package)。这个命令将会将可执行文件及相关文件打包成一个tar.gz压缩的文件用来作为发布软件的软件包。
它会在当前目录下生成一个名字类似“PACKAGE-VERSION.tar.gz”的文件。PACKAGE和VERSION,是我们在configure.in中定义的AM_INIT_AUTOMAKE(PACKAGE, VERSION)。
5、make distcheck
生成发布软件包并对其进行测试检查,以确定发布包的正确性。这个操作将自动把压缩包文件解开,然后执行configure命令,并且执行make,来确认编译不出现错误,最后提示你软件包已经准备好,可以发布了。
6、make distclean
make distclean类似make clean,会清除上次的make命令所产生的object文件(后缀为“.o”的文件)及可执行文件,但同时也将configure生成的文件全部删除掉,包括.config文件等。
Shell脚本中cd命令使用
可以切换目录
export 命令
Linux export 命令用于设置或显示环境变量。
在 shell 中执行程序时,shell 会提供一组环境变量。export 可新增,修改或删除环境变量,供后续执行的程序使用。export 的效力仅限于该次登陆操作。
-f参数为环境变量是函数
-p参数为显示全部环境变量
export MYENV=7 // 定义环境变量并赋值
command 命令
command命令在shell脚本里面,如果发现有个函数和我们需要执行的命令同名,我们可以用command用来强制执行命令,而不是同名函数,然后我们也可以在shell脚本里面判断某个命令是否存在,我们平时一般用which命令也行。
在Linux中,command -v 可以判断一个命令是否支持
command -v pwd # 这个命令是存在的所以执行这个命令
if command -v pwd > /dev/null; then # 所以这个结果为True
短路运算
true || command 这个不会执行后边command 因为 第一个已经正确,这个整体就是正确的了
false && command 这个也不会执行后边的命令因为已经是错误了,后边是对错整体都是错的
$0 函数和脚本
在脚本中是脚本名,在函数中是函数名(但是需要执行的时候是在子shell中,例bash test.sh,./test.sh)
shell echo
echo -n 表示不换行输出
echo -e “\n” 将后面引号中的内容,当做转义字符有特殊意思。
使用getopts处理多命令行选项
https://blog.csdn.net/wdz306ling/article/details/79974377
https://www.cnblogs.com/klb561/p/8933992.html
getopts的使用 语法格式:getopts [option[:]] [DESCPRITION] VARIABLE option:表示为某个脚本可以使用的选项 “:”:如果某个选项(option)后面出现了冒号(“:”),则表示这个选项后面可以接参数(即一段描述信息DESCPRITION) VARIABLE:表示将某个选项保存在变量VARIABLE中
OPTARG:就是将选项后面的参数(或者描述信息DESCPRITION)保存在这个变量当中。
OPTIND:这个表示命令行的下一个选项的索引(文件名不算选项,从1开始)
while getopts “:a:bc:” opt # 第一个冒号表示忽略错误;字符后面的冒号表示该选项必须有自己的参数。
getopts命令支持两种错误报告模式,详细错误报告模式和抑制错误报告模式。
在详细错误报告模式下:如果getopts检测到一个无效的选项,var的值会被设置为(?);如果getopts检测到一个后面需要跟参数的选项,后面没有参数,var的值也会被设置为(?)
在抑制错误报告模式下:如果getopts检测到一个无效的选项,var的值会被设置为(?),变量OPTARG会被设置为这个无效的选项;如果getopts检测到一个后面需要跟参数的选项,后面没有参数,var的值会被设置为(:),变量OPTARG会被设置为这个无效的选项
#shell cmd input
while getopts "t:m:a:" arg
do
case $arg in
t)
log "test time arg:TEST_TIME=$OPTARG s"
TEST_TIME=$OPTARG
;;
m)
log "test mode arg:TEST_MODE=$OPTARG "
TEST_MODE=$OPTARG
;;
?) #arg is unkonw
log "ERROR unkonw argument"
exit 1
;;
esac
done
lscpu 显示cpu架构信息
grep 参数
在多个文件中搜索一个单词,命令会返回一个包含test的文本行
语法:
grep "test" file1 file2
输出除test之外的所有行 -v 选项
grep -v "test" file1 file2
grep -v "^#"
^ 意思是"开始行"
# 是字面意思 #
-v表示在grep中"反转匹配",换句话说,返回所有不匹配的行.
把它们放在一起,你的表达是"选择所有不以#" 开头的行"
标记匹配颜色 --color=auto 选项
grep "match_pattern" file_name --color=auto
使用正则表达式 -E 选项
grep -E "[1-9]+" file
只输出文件中匹配到的部分 -o 选项
grep -o "test" file_name
grep -o “-” | wc -l 可以找到指定字符出现的个数
-a或–text 不要忽略二进制的数据。
**-A<显示列数>或–after-context=<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之后的内容。 ** 后边多少行内容
-b或–byte-offset 在显示符合范本样式的那一列之前,标示出该列第一个字符的位编号。
-B<显示列数>或–before-context=<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前的内容。
-c或–count 计算符合范本样式的列数。 就是行数
-C<显示列数>或–context=<显示列数>或-<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-d<进行动作>或–directories=<进行动作> 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
-e<范本样式>或–regexp=<范本样式> 指定字符串做为查找文件内容的范本样式。
-E或–extended-regexp 将范本样式为延伸的普通表示法来使用。
-f<范本文件>或–file=<范本文件> 指定范本文件,其内容含有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每列一个范本样式。
-F或–fixed-regexp 将范本样式视为固定字符串的列表。
-G或–basic-regexp 将范本样式视为普通的表示法来使用。
-h或–no-filename 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
-H或–with-filename 在显示符合范本样式的那一列之前,表示该列所属的文件名称。
-i或–ignore-case 忽略字符大小写的差别。
-l或–file-with-matches 列出文件内容符合指定的范本样式的文件名称。
-L或–files-without-match 列出文件内容不符合指定的范本样式的文件名称。
-n或–line-number 在显示符合范本样式的那一列之前,标示出该列的列数编号。
-q或–quiet或–silent 不显示任何信息。
-r或–recursive 此参数的效果和指定"-d recurse"参数相同。
-s或–no-messages 不显示错误信息。
-v或–revert-match 反转查找。
-V或–version 显示版本信息。
-w或–word-regexp 只显示全字符合的列。
-x或–line-regexp 只显示全列符合的列。
-y 此参数的效果和指定"-i"参数相同。
–help 在线帮助。
grep "需要查询的关键字" ./ -R 会在当前目录下所有文件以及目录下的目录下的文件,在每一个文件中查询关键字 并打出关键所在的一行
和上边一样的效果
grep -rn 关键字 目录
grep -m 1 可以取出第一个匹配项
w 查看登录到本台机器的当前用户
多用户,都是使用root登录到当前机器的
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vKimkJNJ-1665227748262)(shell.assets/image-20210930171051881.png)]
第一个是在操作 第二个是使用命令 第三个什么都不做是 -bash 其中第一个FROM S.O是screen
还有类似命令 ‘who’ ‘who am i’ ‘whoami’
wc -l
统计行数
wc -l 位置
exit
用来退出当前 Shell 进程,并返回一个退出状态;使用$?可以接收这个退出状态,
exit 命令可以接受一个整数值作为参数,代表退出状态。如果不指定,默认状态值是 0。
#!/bin/bash
echo "befor exit"
exit 8
echo "after exit"
[mozhiyan@localhost ~]$ bash ./test.sh
befor exit
[mozhiyan@localhost ~]$ echo $?
8
格式问题
/bin/sh^M: bad interpreter: No such file or directory
windows中换行符为 回车换行(\r\n)(CR回车LF换行) Unix中为换行(\n)(LF换行) 所以会出现问题 MAC是回车(\r)(CR回车)
很可能是你在windows下编写的脚本文件,放到Linux中无法识别格式。
1.用vi打开脚本文件,在命令模式下输入
set ff=unix
2.对需要执行的shell脚本文件执行下面的操作:
如果没有需要安装yum install dos2unix
dos2unix <shell file>
例如: dos2unix test.sh
bc 精度计算器
语法
bc(选项)(参数)
选项值
- -i:强制进入交互式模式;
- -l:定义使用的标准数学库
- ; -w:对POSIX bc的扩展给出警告信息;
- -q:不打印正常的GNU bc环境信息;
- -v:显示指令版本信息;
- -h:显示指令的帮助信息。
参数
文件:指定包含计算任务的文件。
在Linux命令行下直接输bc可以进入交互界面进行计算,quit退出
通过管道符
$ echo "15+5" | bc
20
scale=2 设小数位,2 代表保留两位:
$ echo 'scale=2; (2.777 - 1.4744)/1' | bc
1.30
bc 除了 scale 来设定小数位之外,还有 ibase 和 obase 来其它进制的运算:
$ echo "ibase=2;111" |bc
7
进制转换
#!/bin/bash
abc=192
echo "obase=2;$abc" | bc
<pre>
<p>
执行结果为:11000000,这是用bc将十进制转换成二进制。</p>
<pre>
#!/bin/bash
abc=11000000
echo "obase=10;ibase=2;$abc" | bc 要先转换为10 进制在转换为2进制 ((16#123))
执行结果为:192,这是用bc将二进制转换为十进制。
ibase代表是当前的进制,obase代表要转换的进制
计算平方和平方根:
$ echo "10^10" | bc
10000000000
$ echo "sqrt(100)" | bc
10
let 计算
let 命令是 BASH 中用于计算的工具,用于执行一个或多个表达式,变量计算中不需要加上 $ 来表示变量。如果表达式中包含了空格或其他特殊字符,则必须引起来。
自加操作:let no++
自减操作:let no–
简写形式 let no+=10,let no-=20,分别等同于 let no=no+10,let no=no-20。
let a=5+4
let b=9-3
echo $a $b
9 6
$[] and $(()) and `` 其中只可以计算整数
$((16#a)) 进制转换
$(( ))可以将其他进制转成十进制数显示出来。用法如下:
echo $((N#xx))
其中,N为进制,xx为该进制下某个数值,命令执行后可以得到该进制数转成十进制后的值。
[root@localhost ~]# echo $((2#110))
6
[root@localhost ~]# echo $((16#2a))
42
[root@localhost ~]# echo $((8#11))
9
(())
双小括号 (( )) 是 Bash Shell 中专门用来进行整数运算的命令,它的效率很高,写法灵活,是企业运维中常用的运算命令。
((表达式))
将数学运算表达式放在((和))之间。
表达式可以只有一个,也可以有多个,多个表达式之间以逗号,分隔。对于多个表达式的情况,以最后一个表达式的值作为整个 (( )) 命令的执行结果。
可以使用$获取 (( )) 命令的结果,这和使用$获得变量值是类似的。
在 (( )) 中使用变量无需加上$前缀,(( )) 会自动解析变量名,这使得代码更加简洁,也符合程序员的书写习惯。
[ -n 参数 ] 可以用来判断该参数是否已被赋值
如果赋值返回True 否则false
awk的用法
https://blog.csdn.net/wdz306ling/article/details/80383824
AWK 是一种处理文本文件的语言,是一个强大的文本分析工具。
语法
awk [选项] '指令' 要操作文件
常用选项
-F 指定分隔符,分隔符用""引起来
-v:var=value在awk程序开始之前指定一个值valu给变量var,这些变量值用于awk程序的BEGIN快
-f:后面跟一个保存了awk程序的文件,代替在命令行指定awk程序
awk ‘{print}’ 1.txt # 逐行读取文件1.txt内容并打印
awk ‘{print $0}’ 1.txt # 逐行读取文件内容,并打印该行,$0保存的是当前行的内容
awk ‘{print “hello”}’ 1.txt # 逐行读取1.txt文件内容,每行结束后打印一个hello,文件1.txt有多少行就打印多少个hello
awk ‘{print $1}’ 1.txt # 打印1.txt的第一列内容,在不指定分割符的情况下,awk默认使用空白做分割符
awk -F “:” ‘{print $1}’ /etc/passwd # 以":"为分隔符打印/etc/passwd文件的第一例内容
特殊用法:
a0=cat i2c.log | awk 'NR==2{print $1}'
其中在NR==2 的意思是去这个文件中的第二行进行分析
$(./moc_i2c_st.sh r 0 0 | awk -F ’ ’ ‘{print $NF}’ ) NF就是一行数据最后一列的那个值
ps ux |awk ‘{sum+=$6}END{print sum}’ 将分割出来的这一行 统计求和
ss -an |awk ‘NR>1{state[$2]++}END{for (i in state) print i,state[i] }’ 分组求和
LISTEN() 23 ESTAB 34 UNCONN 68
sed的用法
sed 命令是利用脚本来处理文本文件。
sed 可依照脚本的指令来处理、编辑文本文件。
Sed 主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。
sed [-hnV][-e<script>][-f<script文件>][文本文件]
参数说明:
-
-e
动作说明 命令:
- a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
- c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
- d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚; 使用 /11/d
- i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行); 使用 1i\22 在第一行新增一行 内容是22
- p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
- s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!
参数和命令 是分开的 -i 是参数代表会修改源文件 1i \11 是命令 代表会在当前文件的第一行新增11这行
实例
在testfile文件的第四行后添加一行,并将结果输出到标准输出,在命令行提示符下输入如下命令:
sed -e 4a\newLine testfile
sed -e 1c\789 a.py 替换文件a.py中第一行的内容为789
tail
tail 命令可用于查看文件的内容,有一个常用的参数 -f 常用于查阅正在改变的日志文件。
tail -f filename 会把 filename 文件里的最尾部的内容显示在屏幕上,并且不断刷新,只要 filename 更新就可以看到最新的文件内容。
命令格式:
tail [参数] [文件]
参数:
- -f 循环读取
- -q 不显示处理信息
- -v 显示详细的处理信息
- -c<数目> 显示的字节数
- -n<行数> 显示文件的尾部 n 行内容
- –pid=PID 与-f合用,表示在进程ID,PID死掉之后结束
- -q, --quiet, --silent 从不输出给出文件名的首部
- -s, --sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒
要显示 notes.log 文件的最后 10 行,请输入以下命令:
tail notes.log # 默认显示最后 10 行
显示文件 notes.log 的内容,从第 20 行至文件末尾:
tail -n +20 notes.log
exec命令
使用 exec 命令可以永久性地重定向,后续命令的输入输出方向也被确定了,直到再次遇到 exec 命令才会改变重定向的方向;换句话说,一次重定向,永久有效。
对代码的说明:
exec >log.txt将当前 Shell 进程的所有标准输出重定向到 log.txt 文件,它等价于exec 1>log.txt。
exec >&2用来恢复重定向,让标准输出重新回到显示器,它等价于exec 1>&2。2 是标准错误输出的文件描述符,它也是输出到显示器,并且没有遭到破坏,我们用 2 来覆盖 1,就能修复 1,让 1 重新指向显示器。
以输出重定向为例,手动恢复的方法有两种:
/dev/tty 文件代表的就是显示器,将标准输出重定向到 /dev/tty 即可,也就是 exec >/dev/tty。
如果还有别的文件描述符指向了显示器,那么也可以用别的文件描述符来恢复标号为 1 的文件描述符,例如 exec >&2。注意,如果文件描述符 2 也被重定向了,那么这种方式就无效了。
如果exec 跟的是其他命令,则其他命令结束后,本shell也随之停止 。 exec 1>file.lock 这个不会停止shell
https://www.jianshu.com/p/60a3dae7694f
local 局部变量
只在当前作用范围内有用。
dmesg uptime
dmesg 和 messages 都在/var/log目录下
dmesg:显示开机信息
dmesg 命令用于显示开机信息。kernel 会将开机信息存储在 ring buffer 中。您若是开机时来不及查看信息,可利用 dmesg来查看。开机信息亦保存在 /var/log 目录中,名称为 dmesg 的文件里。
| 参数选项 | 解释说明 |
|---|---|
| -c | 显示信息后,清除ring buffer中的内容。 |
| -s | 预设置为8196,刚好等于ring buffer的大小。 |
| -n | 设置记录信息的层级。 |
dmesg -c > /dev/null 显示开机信息,并且清除ring buffer,然后将内容重定向到扔了。
uptime:示系统运行时间信息
uptime 是 Linux 系统最基本的统计命令。uptime 会提供一些我们要用到的不同基本信息:
- 当前时间
- 系统运行的天数、小时数、分钟数
- 当前登录到系统上的用户数
- 一分钟、五分钟、十五分钟的平均负载
lspci命令
lspci,顾名思义,就是显示所有的pci设备信息。pci是一种总线,而通过pci总线连接的设备就是pci设备了。如今,我们常用的设备很多都是采用pci总线了,如:网卡、存储等。isa另一种总线
lspci:显示所有的pci设备信息。包括设备的BDF,设备类型,厂商信息等。
lspci -t [BDF]:显示指定BDF号的设备信息。
lspci -m/-mm:以一种机器可读的格式来显示pci设备信息。
lspci -t:以树的形式显示pci设备信息。
lspci -v/-vv/-vvv:显示详细的pci设备信息,v越多,越详细,当然,上限3个。
lspci -x/-xxx/-xxxx:-x以16进制信息显示pci配置空间;-xxx显示部分读配置空间会crash的设备;-xxxx显示PCI-x2.0或者PCI-e总线扩展的配置空间。
lspci -b:以总线的角度来显示所有的IRQ和地址。根据我的观察,大部分信息和不带参数时显示一致,除了SR-IOV设备分配出的Virtual Function设备。
lspci -D:显示PCI domain号,默认的不加参数命令并不显示该值。
lspci -n/-nn:显示设备的vendor厂商号和device设备号;显示厂商等信息和名称。
lspci -D:显示设备的厂商号、设备号、Class号。
lspci -s 03:02.0 -vv // -s后面接的是每个设备的总线、插槽与相关函数功能
LD_LIBRARY_PATH
是Linux环境变量名,该环境变量主要用于指定查找共享库(动态链接库)时除了默认路径之外的其他路径。
ldconfig
echo “/usr/local/lib” >> /etc/ld.so.conf ;ldconfig
ldconfig是一个动态链接库管理命令,其目的为了让动态链接库为系统所共享。
ldconfig通常在系统启动时运行,而当用户安装了一个新的动态链接库时,就需要手工运行这个命令。
export LD_LIBRARY_PATH=/usr/local/lib:$LD_LIBRARY_PATH
sudo ldconfig
1. 将这个目录 加载到 LD_LIBRARY_PATH
2. 类似刷新这个LD_LIBRARY_PATH
test [] [[]]
加单括号是为了变为一行 就是 test也可以 使用**[]**也可以
双括号是为了不带引号,功能也比较多 可以用正则
find命令
用来在指定目录下查找文件
语法:find path -option [ -print ] [ -exec -ok command ] {} ;
将当前目录及其子目录下所有文件后缀为 .c 的文件列出来:
# find . -name "*.c"
将目前目录其其下子目录中所有一般文件列出
# find . -type f
which命令
会在环境变量$PATH设置的目录里查找符合条件的文件
which [文件...]
会输出找到的文件的地址
#*-
删掉第一个 - 及其左边的字符串
${file##*/}:删掉最后一个/ 及其左边的字符串 删的多
${file%/*}:删掉最后一个 / 及其右边的字符串
${file%%/*}:删掉第一个/ 及其右边的字符串 删的多
ls /sys/class/net
可以获取到网卡名
可以获取到 ifconfig -a 全部的网卡名
ethtool 网口
Ethtool是用于查询及设置网卡参数的命令。
ethtool ethX //查询ethX网口基本设置
ethtool –h //显示ethtool的命令帮助(help)
ethtool –i ethX //查询ethX网口的相关信息
ethtool –d ethX //查询ethX网口注册性信息
ethtool –r ethX //重置ethX网口到自适应模式
ethtool –S ethX //查询ethX网口收发包统计
ethtool –s ethX [speed 10|100|1000]\ //设置网口速率10/100/1000M
[duplex half|full]\ //设置网口半/全双工
[autoneg on|off]\ //设置网口是否自协商
[port tp|aui|bnc|mii]\ //设置网口类型
cut -b
cut是以每一行为一个处理对象的,这种机制和sed一样。
cut命令如果使用-b选项,执行时会先把-b后面所有的定位进行从小到大排序,然后再提取,不能颠倒顺序。
-3 表示从第一字节到第三字节;
3- 表示从第三字节到结尾。
对于中文提取,-c 会以字符为单位,输出正常;-b以字节(8位二进制)计算。
-d 参数是使用指定一个字符分割
-f n 是取到分割之后的第几列 配合指定字符分割
tr
配合cut使用,cut在遇到多个空格的时候,不方便切割,可以使用tr -s “ ” 将多个空格压缩为一个空格
可以将多个相同字符,压缩为一个字符
进制表示
正常表示的就是 十进制 dec
以‘0’零开头的就是 八进制 oct
let “oct = 032”
echo “octal number = $oct” # 26
以‘0x’or‘0X’开头的是 十六进制 hex
let “hex = 0x32”
echo “hexadecimal number = $hex” # 50
其他进制: BASE#NUMBER BASE范围在2到64之间 NUMBER的值必须是BASE范围内的符号
let “bin = 2#111100111001101”
echo “binary number = $bin” # 31181 最终都会转换为十进制
$* $@
$* 和 $@ 都表示传递给函数或脚本的所有参数,
- 不被双引号(” “)包含时,都以”$1” “2 ” … “ 2” … “2”…“n” 的形式输出所有参数。 二者都是返回传入的参数
- 但是当它们被双引号(” “)包含时,
- ”$*” 会将所有的参数作为一个整体,以”$1 $2 … $n”的形式输出所有参数; 整体
- ”$@” 会将各个参数分开,以”$1″ “2 ” … “ 2” … “2”…“n” 的形式输出所有参数。 分开
ping 从指定网口发包
ping -c 1 -l 128 192.168.10.2 -I 192.168.10.1
-c 次数
-l 128 包的大小
-I 从那个网卡发包
ping www.baidu.com -I eth0 大写的i
登录ssh
yum -y install sshpass
sshpass -p 0 ssh root@10.96.65.147 ‘touch aa’
-p 后跟的是ssh的密码 ip后跟的引号内的是 在登录到服务器之后要执行的命令
a=`sshpass -p 0 ssh root@10.96.65.147 'ls'`
也可以将在服务器执行的命令的返回值 赋值给a
ifconfig
设置网卡 up down
ifconfig 网卡名 up
修改ip
ifconfig ens33 192.168.1.21 netmask 255.255.255.0
或者 ifconfig ens33 192.168.1.21/24 24就是子网掩码相当于255.255.255.0 前面3个255二进制都是8个1 一共是24个1
设置mac地址
ifconfig eth0(网卡名) hw ether 54:BF:64:92:FB:B3 quartus 21.2
ifconfig enp49s0f0 hw ether 00:1e:67:f8:78:dd vivado
ifconfig enp49s0f0 hw ether 00:1e:67:f8:78:dd quartus 21.4 (6月14最新的mac地址)
ifconfig enp49s0f0 hw ether 54:bf:64:92:fb:b3 quartus 21.4
1.关闭网卡设备
ifconfig eth0 down
2.修改MAC地址
ifconfig eth0 hw ether MAC地址
3.重启网卡
ifconfig eth0 up
设置DNS
/etc/resovle.conf
/etc/sysconfig/network-scripts/ifcfg-enp3s0 如果没有上面那个文件,就是使用这个文件中的dns配置

netns
ip link set enp netns nstest$i 将enp设备移动到namespace的网络命名空间
ip netns 命令是用来管理 网络命名空间 的,网络命名空间可以实现 网络隔离。每个网络命名空间都提供了一个完全独立的网络协议栈,包括网络设备接口、IPV4 和 IPV6 协议栈、IP路由表、防火墙规则、端口、sockets 等。像 docker 就是利用 Linux 的网络命名空间来实现容器网络的隔离。
ip netns list 列出网络命名空间。此命令显示的是 “/var/run/netns” 中的所有网络命名空间。
ip netns add NAME 添加网络命名空间
ip [-all] netns delete [NAME] 删除网络命名空间
ip [-all] netns exec [NAME] cmd … 在指定的网络命名空间中执行命令
ip netns set NAME NETNSID 给网络命名空间分配id
ip netns identify [PID] 查看进程的网络命名空间
ip netns monitor 监控对网络命名空间的操作
ip netns pids NAME 查找使用此网络命名空间并将其作为主要网络命名空间的进程。此命令会从 /proc 目录中遍历。
md5查看两个文件是否是同一个
md5sum 文件名 会返回文件的md5值 只要两个文件的md5值是一样的就可以确定是一个文件了
windows使用md5
certutil -hashfile filename MD5
xargs
xargs是给命令传递参数的一个过滤器,也是组合多个命令的一个工具
xargs 可以将管道或标准输入(stdin)数据转换成命令行参数,也能够从文件的输出中读取数据。
xargs 也可以将单行或多行文本输入转换为其他格式,例如多行变单行,单行变多行。
xargs 默认的命令是 echo,这意味着通过管道传递给 xargs 的输入将会包含换行和空白,不过通过 xargs 的处理,换行和空白将被空格取代。
xargs 是一个强有力的命令,它能够捕获一个命令的输出,然后传递给另外一个命令。
之所以能用到这个命令,关键是由于很多命令不支持|管道来传递参数,而日常工作中有有这个必要,所以就有了 xargs 命令,例如:
find /sbin -perm +700 |ls -l #这个命令是错误的
find /sbin -perm +700 |xargs ls -l #这样才是正确的
find /sbin -perm +700 |xargs -n 1 ls -l #每次传一个过去(-i也可以)
sort 排序
用法:sort [选项]… [文件]…
串联排序所有指定文件并将结果写到标准输出。
排序选项:
-b, --ignore-leading-blanks 忽略前导的空白区域
-d, --dictionary-order 只考虑空白区域和字母字符
-f, --ignore-case 忽略字母大小写
-g, --general-numeric-sort 按照常规数值排序
-i, --ignore-nonprinting 只排序可打印字符
-n, --numeric-sort 根据字符串数值比较
-r, --reverse 逆序输出排序结果
其他选项:
-c, --check, --check=diagnose-first 检查输入是否已排序,若已有序则不进行操作
-k, --key=位置1[,位置2] 在位置1 开始一个key,在位置2 终止(默认为行尾)
-m, --merge 合并已排序的文件,不再进行排序
-o, --output=文件 将结果写入到文件而非标准输出
-t, --field-separator=分隔符 使用指定的分隔符代替非空格到空格的转换
-u, --unique 配合-c,严格校验排序;不配合-c,则只输出一次排序结果
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rBpxZCTg-1665227748264)(shell.assets/image-20210901155738505.png)]
cp
普通文件复制
cp -rf /usr /root :将 /usr 文件夹复制到 /root 文件夹下。 (会形成: /root/usr 文件夹)
cp -rf /usr/** /root :将 /usr 文件夹下的全部文件复制到 /root文件夹下。 (会形成: /root/usr文件夹下的内容)
强制覆盖、替换文件
\cp Hello.java World.java : 将 Hello.java 文件强制替换到 World.java下。 (相当于: World.java 删除,Hello.java 文件复制过来,改名 World.java)
\cp -rf /usr /root : 将 /usr 文件夹复制到 /root 文件夹下,遇到相同,会强制覆盖掉!
\cp -rf /usr/** /root :将 /usr 文件夹下的全部文件复制到 /root 文件夹下,遇到相同,会强制覆盖掉!
== 和 =
== 可用于判断变量是否相等,= 除了可用于判断变量是否相等外,还可以表示赋值。
= 与 == 在 [ ] 中表示判断(字符串比较)时是等价的,例如:
s1="foo"
s2="foo"
[ $s1=$2 ] && echo "equal"
[ $s1==$2 ] && echo "equal"
最后两个语句是等价的
在 (( )) 中 = 表示赋值, == 表示判断(整数比较),它们不等价,比如
((n=5))
echo $n
((n==5)) && echo "equal"
((n=5)) 表示赋值,((n==5)) 表示判断。
数字比较带不带引号
都可以
elif [[ $crc_err -gt 0 ]];then # 不带
log "for $dev $crc_err rx_crc_errors recorded, please check hardware..."
exit 1
if [ $pcs != "11" ] # 带
then
log "100G 物理没有link up..."
exit 1
fi
date
datetime=$(date +%Y%m%d-%H:%M:%S) 获取到当前时间
${#1}
执行shell脚本 如果没有参数返回 0
如果有一个以上参数 则返回 1
nowrap
在vim编辑器里如果一行内容过多,会出现换行
使用 :set norwap 就会不换行
top
实时监控系统的状态,默认五秒刷新一次。
僵尸态:该进程已经结束,但是其父进程没有收到通知,导致不能及时回收该进程所占用的系统资源
tasks 进程总数 zombie僵尸态
PID - 进程标示号
USER - 进程所有者
PR - 进程优先级
NI - 进程优先级别数值
VIRT - 进程占用的虚拟内存值
RES - 进程占用的物理内存值
SHR - 进程使用的共享内存值
S - 进程的状态,其中S表示休眠,R表示正在运行,Z表示僵死
%CPU - 进程占用的CPU使用率
%MEM - 进程占用的物理内存百分比
TIME+ - 进程启动后占用的总的CPU时间
Command - 进程启动的启动命令名称
ps process state
默认会列出当前终端下当前用户运行起来的进程
图形界面下每打开一个终端窗口,都相当于系统中登录了一个新的用户,只不过这几个终端窗口默认登录的用户名是相同的。
多用户允许相同的用户名以不同的终端同时登录系统。
**注意:**刚刚使用的ps命令,本身就是一个进程,当前终端里面运行命令的环境bashshell本身也是一个进程。
选项:
-
u
显示进程所属的用户名,启动时间等详细信息
-
a
全部进程(所有用户进程) 一般和上边的组合使用 ps -au
-
e
会列出所有终端的进程 f显示信息详细一点 一般组合使用 ps -ef 显示进程最多
-
l
和ls -l相似 pid 本进程编号 ppid父进程编号 s sleep睡眠态 r run运行态
-
x
显示所有程序,不以终端机来区分。
最常用的方法是ps -aux,然后再利用一个管道符号导向到grep去查找特定的进程,然后再对特定的进程进行操作。
-
ps -ux
代表当前用户的所有进程 RSS是进程占用的物理内存大小
tty pts
在虚拟机图形化界面下打开的终端是tty
使用mobaxterm终端工具打开的命令行是pts
du 查看文件大小
du 列出当前目录下的每个子目录使用的磁盘情况
du -h 文件大小显示友好
du -h 位置 该位置下每个子目录使用情况
du -hs 位置 该位置目录下总的使用情况
du -hs * 可以看出当前目录下所有文件的大小 (好用)
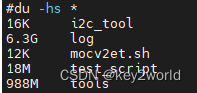
du -h -d 1 查看文件 1为查看的深度 可以改变深度
df 显示磁盘中每个分区的空间使用情况
df -h 显示大小之前为block,现在为m。
df -Th 会显示磁盘的类型 比上边多的地方
vim
-
批量操作多行
https://blog.csdn.net/cd15109139570/article/details/79685618
使用ctrl + v 进入 visual block(可视化)模式 方向键向下选择多行,方向键左右选择多列
使用 shift + i (大写i)进入插入模式 输入需要插入的字符 按esc 从而完成批量操作
shift + g 到文件最后一行
-
查找
:%s/Print//n 只能匹配到每一行的第一个匹配项
:%s/Print//gn 可以匹配全部
-
查找替换
:%s/print/write/g 第一个是查找的关键字(Print) 第二个是替换为(write)
-
取消查找的高亮显示
:noh 或 :nohlsearch
大小写转换
UPPERCASE=$(echo $VARIABLE | tr ‘[a-z]’ ‘[A-Z]’) (把VARIABLE的小写转换成大写)
LOWERCASE=$(echo $VARIABLE | tr ‘[A-Z]’ ‘[a-z]’) (把VARIABLE的大写转换成小写)
tr 压缩重复字符
https://blog.csdn.net/zhuying_linux/article/details/6825568
1.用途
tr,translate的简写,主要用于压缩重复字符,删除文件中的控制字符以及进行字符转换操作。
2.语法
语法:tr [–c/d/s/t] [SET1] [SET2]
SET1: 字符集1
SET2:字符集2
-c:complement, 用SET2替换SET1中没有包含的字符
-d:delete, 删除SET1中所有的字符,不转换
-s: squeeze-repeats, 压缩SET1中重复的字符
-t: truncate-set1, 将SET1用SET2转换, 一般缺省为-t
- 去除重复的字符
#将连续的几个相同字符压缩为一个字符
$ echo aaacccddd | tr -s [a-z]
acd
$ echo aaacccddd | tr -s [abc]
acddd
/proc
可以看到很多信息
从window粘贴到linux格式不改变
:set paste
crontab 定时任务
https://www.runoob.com/w3cnote/linux-crontab-tasks.html
crontab [-u username] //省略用户表表示操作当前用户的crontab
-e (编辑工作表)
-l (列出工作表里的命令)
-r (删除工作作)
flock文件锁
https://www.jianshu.com/p/e1c55ffea1cb
flock [-sxun][-w #]
flock [-sxon][-w #] file [-c] command
-s, --shared: 获得一个共享锁
-x, --exclusive: 获得一个独占锁/排他锁
-u, --unlock: 移除一个锁,通常是不需要的,脚本执行完会自动丢弃锁
-n, --nonblock: 如果没有立即获得锁,直接失败而不是等待
-w, --timeout: 如果没有立即获得锁,等待指定时间
-o, --close: 在运行命令前关闭文件的描述符号。用于如果命令产生子进程时会不受锁的管控
-c, --command: 在shell中运行一个单独的命令
-h, --help 显示帮助
-V, --version: 显示版本
-w 等待时间,秒
exec 3>filename (为了自定义文件的句柄) 打开文件句柄 这个file的文件句柄就是3 这个3文件句柄可以在 /proc/$$/fd 中看到
flock -x 3 锁定文件句柄,会阻塞
这中间对这个文件操作是独立,别的进程不能操作到这个文件
exec 3>&- 关闭文件描述符(句柄)
如果使用4.2以上的bash,文件的句柄可以交由系统选择,不用自己控制。
exec {lock_fd}>filename 这个lock_fd就是系统自己选择 文件句柄是 10
flock -X "$lock_fd"
exec {lock_fd}>&- 关闭文件描述符 之后别的进程就可以操作这个文件了
&-固定命令 配合 fd>&-就是关闭文件描述符
flock -u "$lock_fd" 移除一个锁,通常是不需要的,脚本执行完会自动丢弃锁
独占锁/排他锁
- 设置锁
使用计划任务执行sleep.sh,文件锁使用独占锁,如果锁定则失败不等待。这样当任务未执行完成,下一任务判断到/tmp/mytest.lock被锁定,则结束当前的任务,下一周期再判断。参数为-xn
2/* * * * * flock -xn /tmp/sleep.lock -c /opt/sleep.sh >> /tmp/sleep.log
- 创建独占锁/排他锁,加上等待超时/秒
启动的定时任务等待了20秒后,上一个任务释放了锁,任务可以马上拿到锁,并继续执行
2/* * * * * flock -x -w 20 /tmp/sleep.lock -c /opt/sleep.sh >> /tmp/sleep.log
read
read是shell中获取输入的关键字
-d : 表示delimiter,即定界符,一般情况下是以IFS为参数的间隔,但是通过-d,我们可以定义一直读到出现执行的字符位置。例如read –d madfds value,读到有m的字符的时候就不在继续向后读,例如输入为 hello m,有效值为“hello”,请注意m前面的空格等会被删除。这种方式可以输入多个字符串,例如定义“.”作为结符号等等。
-e :只用于互相交互的脚本,它将readline用于收集输入行。读到这几句话不太明白什么意思,先跳过。
-n : 用于限定最多可以有多少字符可以作为有效读入。例如echo –n 4 value1 value2,如果我们试图输入12 34,则只有前面有效的12 3,作为输入,实际上在你输入第4个字符‘3’后,就自动结束输入。这里结果是value为12,value2为3。
-p :用于给出提示符,在前面的例子中我们使用了echo –n “…“来给出提示符,可以使用read –p ‘… my promt?’value的方式只需一个语句来表示。
-r :在参数输入中,我们可以使用’/’表示没有输入完,换行继续输入,如果我们需要行最后的’/’作为有效的字符,可以通过-r来进行。此外在输入字符中,我们希望/n这类特殊字符生效,也应采用-r选项。
-s : 对于一些特殊的符号,例如箭头号,不将他们在terminal上打印,例如read –s key,我们按光标,在回车之后,如果我们要求显示,即echo,光标向上,如果不使用-s,在输入的时候,输入处显示^[[A,即在terminal上 打印,之后如果要求echo,光标会上移。
-t :用于表示等待输入的时间,单位为秒,等待时间超过,将继续执行后面的脚本,注意不作为null输入,参数将保留原有的值
while read
while read line
do
…
done < file
read通过输入重定向,把file的第一行所有的内容赋值给变量line,循环体内的命令一般包含对变量line的处理;然后循环处理file的第二行、第三行。。。一直到file的最后一行。还记得while根据其后的命令退出状态来判断是否执行循环体吗?是的,read命令也有退出状态,当它从文件file中读到内容时,退出状态为0,循环继续惊醒;当read从文件中读完最后一行后,下次便没有内容可读了,此时read的退出状态为非0,所以循环才会退出。
另一种也很常见的用法:
command | while read line
do
…
done
如果你还记得管道的用法,这个结构应该不难理解吧。command命令的输出作为read循环的输入,这种结构长用于处理超过一行的输出,当然awk也很擅长做这种事
系统启动就执行指定脚本
/etc/rc.local 文件的作用是系统启动就执行 可以将启动要执行的脚本加到这个文件中
beyond compare
使用命令 bcompare 文件夹1 文件夹2 进行对比两个文件
compare to F7 代表 将当前目录和 你需要的目录进行对齐 (出现问好) 点击之后两个目录就会进行对比
文件里 对齐方式 选择一些内容 右键align with F7 可以在对比文件中选择要对齐的地方
绑核
https://blog.csdn.net/zhangmingcai/article/details/84823847
所谓绑核,其实就是设定某个进程/线程与某个CPU核的亲和力(affinity)。设定以后,Linux调度器就会让这个进程/线程只在所绑定的核上面去运行。但并不是说该进程/线程就独占这个CPU的核,其他的进程/线程还是可以在这个核上面运行的。如果想要实现某个进程/线程独占某个核,就要使用cpuset命令去实现。
其实,很多情况下,为了提高性能,Linux调度器会自动实现尽量让某个进程/线程在同样的CPU上去运行。所以,除非必须,我们没有必要显式的去进行进程绑核操作。
如何绑核
查出进程pid现在的绑核情况
taskset -p pid
taskset用于将某个进程/线程绑定到CPU的某个或某几个核上面,有两种方法
-
掩码形式
将掩码转换为二进制形式,从最低位到最高位代表物理CPU的#0、#1、……、#n号核。某位的值为0表示不绑该核,1表示绑。比如:0x00000001的二进制为
0000...0001,只有第0号核的位置是1,所以表示只绑0号核;0x00000003的二进制为0000...0011,第0和1号核的位置是1,所以表示绑CPU的0号和1号核;再比如0xFFFFFFFF的二进制为1111...1111,所有32个核的位置都为1,所以表示绑CPU的0~31核。需要注意的是,并非掩码中给出的CPU核就一定会存在,比如0x00000400理论上代表CPU的第10号核,但是该核在真正的计算机上面并不一定是存在的。而且,如果我们试图将物理上并不存的核绑定给某个进程时,会返回错误。掩码形式的绑核命令为:
taskset -p mask pid -
列表形式
列表形式指直接指定要绑的CPU核的列表,列表中可以有一个或多个核。具体语法如下:
taskset -cp cpu-list pid taskset -cp 0-7 3306其中
cpu-list是数字化的cpu列表,从0开始。多个不连续的cpu可用逗号连接,连续的可用短现连接,比如0,2,5-11等。比如
taskset -cp 0,2,5-11 9865命令表示将进程9865绑定到#0、#2、#5~#11号核上面。最后要说的是:只要
taskset成功返回了,那就表示绑核一定成功了,即该进程已被绑到指定的核上面,而且taskset命令会显示原来的绑核(原来的可能是系统默认分配的核)情况,以及新的绑核情况。
pid 26334's current affinity list: 0-15 原来情况
pid 26334's new affinity list: 0-7 新情况
sort
sort命令将文件的每一行作为比较对象,通过将不同行进行相互比较,从而得到最终结果。比较原则是从首字符开始,向后依次按ASCII码值进行比较,最后将结果按升序输出
sort命令默认的排序方式是升序,如果想改成降序,就需要加上 -r
比较前的结果:
[rocrocket@rocrocket programming]$ cat seq.txt
banana
apple
pear
orange
比较后的结果:
[rocrocket@rocrocket programming]$ sort seq.txt
apple
banana
orange
pear
1.1 定义变量
定义变量时,变量名不加美元符号($,PHP语言中变量需要)
your_name="lyt"
- 变量名和等号之间不能有空格
- 命名只能使用英文字母,数字和下划线,首个字符不能以数字开头
- 中间不能有空格,可以使用下划线(_)
- 不能使用标点符号
- 不能使用bash里的关键字(可用help命令查看保留关键字)
1.2 使用变量
使用一个定义过的变量,只要在变量名前面加美元符号即可,
your_name="lyt"
echo $your_name
echo ${your_name}
变量名外面的花括号是可选的,加不加都行,加花括号是为了帮助解释器识别变量的边界,比如下面这种情况:
for skill in Ada Coffe Action Java; do
echo "I am good at ${skill}Script"
done
如果不给skill变量加花括号,写成echo "I am good at s k i l l S c r i p t " ,解释器就会把 skillScript",解释器就会把 skillScript",解释器就会把skillScript当成一个变量(其值为空),代码执行结果就不是我们期望的样子了。
1.3 变量重新赋值
已定义的变量,可以被重新定义,如:
your_name="tom"
echo $your_name
your_name="alibaba"
echo $your_name
这样写是合法的,但注意,第二次赋值的时候不能写 y o u r n a m e = " a l i b a b a " ,使用变量的时候才加美元符( your_name="alibaba",使用变量的时候才加美元符( yourname="alibaba",使用变量的时候才加美元符()。
1.4 只读变量
使用 readonly命令可以将变量定义为只读变量,只读变量的值不能被改变。
下面的例子尝试更改只读变量,结果报错:
#!/bin/bash
myUrl="https://www.google.com"
readonly myUrl
myUrl="https://www.runoob.com"
1.5 删除变量
使用unset命令可以删除变量。语法:
unset variable_name
变量被删除后不能再次使用。unset命令不能删除只读变量。
#!/bin/sh
myUrl="https://www.runoob.com"
unset myUrl
echo $myUrl
# 没有任何输出
1.6 变量类型 作用域
运行shell时,会同时存在三种变量:
- 局部变量 局部变量在脚本或命令中定义,仅在当前shell实例中有效,其他shell启动的程序不能访问局部变量。
- 环境变量 所有的程序,包括shell启动的程序,都能访问环境变量,有些程序需要环境变量来保证其正常运行。必要的时候shell脚本也可以定义环境变量。
- shell变量 shell变量是由shell程序设置的特殊变量。shell变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了shell的正常运行
http://c.biancheng.net/view/773.html
在函数内部的变量也是全局变量不是局部变量,需要局部变量的时候需要在定义变量的时候加上local a=1;这个才是局部变量
全局变量的作用范围是当前的 Shell 进程,而不是当前的 Shell 脚本文件,它们是不同的概念。打开一个 Shell 窗口就创建了一个 Shell 进程,打开多个 Shell 窗口就创建了多个 Shell 进程,每个 Shell 进程都是独立的,拥有不同的进程 ID。
在一个 Shell 进程中可以使用 source 命令执行多个 Shell 脚本文件,此时全局变量在这些脚本文件中都有效。
全局变量只在当前 Shell 进程中有效,对其它 Shell 进程和子进程都无效。如果使用export命令将全局变量导出,那么它就在所有的子进程中也有效了,这称为“环境变量”。**export a #将a导出为环境变量 **
环境变量也是临时的
通过 export 导出的环境变量只对当前 Shell 进程以及所有的子进程有效,如果最顶层的父进程被关闭了,那么环境变量也就随之消失了,其它的进程也就无法使用了,所以说环境变量也是临时的。
需要永久的环境变量需要写入到配置文件中。/etc/profile
2. shell字符串
字符串是shell编程中最常用最有用的数据类型(除了数字和字符串,也没啥其它类型好用了),字符串可以用单引号,也可以用双引号,也可以不用引号。
2.1 单引号
str='this is a string'
单引号字符串的限制:
- 单引号里的任何字符都会原样输出,单引号字符串中的变量是无效的;
- 单引号字串中不能出现单独一个的单引号(对单引号使用转义符后也不行),但可成对出现,作为字符串拼接使用。
2.2 双引号
your_name='runoob'
str="Hello, I know you are \"$your_name\"! \n"
echo -e $str
# 输出
Hello, I know you are "runoob"!
双引号的优点:
- 双引号里可以有变量
- 双引号里可以出现转义字符
2.3 拼接字符串
your_name="runoob"
# 使用双引号拼接
greeting="hello, "$your_name" !"
greeting_1="hello, ${your_name} !"
echo $greeting $greeting_1
# 使用单引号拼接
greeting_2='hello, '$your_name' !'
greeting_3='hello, ${your_name} !'
echo $greeting_2 $greeting_3
# 输出为
hello, runoob ! hello, runoob !
hello, runoob ! hello, ${your_name} !
2.4 获取字符串长度
string="abcd"
echo ${#string} #输出 4
2.5 提取子字符串
# 从字符串左边开始计数
string="runoob is a great site"
echo ${sting:1:4} # 输出unoo 索引值从0开始 从第一个开始,往后数四个length
# 从右边开始计数
${string: 0-start :length}
#这里需要强调两点:
# 从左边开始计数时,起始数字是 0(这符合程序员思维);从右边开始计数时,起始数字是 1(这符合常人思维)。计数方向不同,起始数字也不同。
# 不管从哪边开始计数,截取方向都是从左到右。
url="c.biancheng.net"
echo ${url: 0-13: 9}
# 结果biancheng
2.6 查找子字符串
查找字符 i 或 o 的位置(哪个字母先出现就计算哪个):
string="runoob is a great site"
echo `expr index "$string" io` # 输出 4
3. 数组
bash支持一维数组(不支持多维数组),并且没有限定数组的大小。
类似于 C 语言,数组元素的下标由 0 开始编号。获取数组中的元素要利用下标,下标可以是整数或算术表达式,其值应大于或等于 0。
3.1 定义数组
在shell中,用括号来表示数组,数组元素用空格符号分割开。定义数组的一般形式为:
数组名=(值1 值2)
3.2 读取数组
${数组名[下标]}
使用@符号可以获取数组中的所有元素,例如:
echo ${数组名[@]}
3.3 获取数组的长度
获取数组长度的方法与获取字符串长度的方法相同,例如:
# 取得数组元素的个数
length=${#array_name[@]}
# 或者
length=${#array_name[*]}
# 取得数组单个元素的长度
lengthn=${#array_name[n]}
3.4 数组中插入数据
a=(1 2)
a[2]=3
echo ${a[@]} # 1 2 3
4. shell 注释
以#开头的行就是注释,会被解释器忽略。
4.1 多行注释
:<<EOF
lll
lll
lll
EOF
# 另一种方式
:<<!
qqq
qqq
qqq
!
5. shell传递参数
我们可以在执行shell脚本时,向脚本传递参数,脚本内获取参数的格式为:$n。n代表一个数字,1为执行脚本的第一个参数,2为执行脚本的第二个参,一次类推。。。 $0为执行的文件名(包含文件路径)
$# 传递到脚本的参数个数
#!/bin/bash
# author:菜鸟教程
# url:www.runoob.com
echo "Shell 传递参数实例!";
echo "执行的文件名:$0";
echo "第一个参数为:$1";
echo "第二个参数为:$2";
echo "第三个参数为:$3";
运行结果
$ chmod +x test.sh
$ ./test.sh 1 2 3
Shell 传递参数实例!
执行的文件名:./test.sh
第一个参数为:1
第二个参数为:2
第三个参数为:3
6. shell 基本运算符
原生bash不支持简单的数学运算,但是可以通过其他命令来实现,例如 awk 和 expr,expr 最常用。
expr 是一款表达式计算工具,使用它能完成表达式的求值操作。
例如,两个数相加(注意使用的是反引号 *`* 而不是单引号 *'*):
#!/bin/bash
val=`expr 2 + 2`
echo "两数之和为 : $val"
# 结果
两数之和为 : 4
注意:
- 表达式和运算符之间要有空格,例如 2+2 是不对的,必须写成 2 + 2,这与我们熟悉的大多数编程语言不一样。
- 完整的表达式要被**`**包含,注意这个字符不是常用的单引号,在 Esc 键下边。
- 在MAC中 shell 的 expr 语法是:$((表达式)),此处表达式中的 “*” 不需要转义符号 “
\” 。
6.1 关系运算符
关系运算符只支持数字,不支持字符串,除非字符串的值是数字。
| 运算符 | 说明 | 举例 |
|---|---|---|
| -eq | 检测两个数是否相等,相等返回 true。 | [ $a -eq $b ] 返回 false。 |
| -ne | 检测两个数是否不相等,不相等返回 true。 | [ $a -ne $b ] 返回 true。 |
| -gt | 检测左边的数是否大于右边的,如果是,则返回 true。 | [ $a -gt $b ] 返回 false。 |
| -lt | 检测左边的数是否小于右边的,如果是,则返回 true。 | [ $a -lt $b ] 返回 true。 |
| -ge | 检测左边的数是否大于等于右边的,如果是,则返回 true。 | [ $a -ge $b ] 返回 false。 |
| -le | 检测左边的数是否小于等于右边的,如果是,则返回 true。 | [ $a -le $b ] 返回 true。 |
6.2 布尔运算符
| 运算符 | 说明 | 举例 |
|---|---|---|
| ! | 非运算,表达式为 true 则返回 false,否则返回 true。 | [ ! false ] 返回 true。 |
| -o | 或运算,有一个表达式为 true 则返回 true。 | [ $a -lt 20 -o $b -gt 100 ] 返回 true。 |
| -a | 与运算,两个表达式都为 true 才返回 true。 | [ $a -lt 20 -a $b -gt 100 ] 返回 false。 |
6.3 逻辑运算符
| 运算符 | 说明 | 举例 |
|---|---|---|
| && | 逻辑的 AND | [[ $a -lt 100 && $b -gt 100 ]] 返回 false |
| || | 逻辑的 OR | [[ $a -lt 100 || $b -gt 100 ]] 返回 true |
6.4 字符串运算符
| 运算符 | 说明 | 举例 |
|---|---|---|
| = | 检测两个字符串是否相等,相等返回 true。 | [ $a = $b ] 返回 false。 |
| != | 检测两个字符串是否不相等,不相等返回 true。 | [ $a != $b ] 返回 true。 |
| -z | 检测字符串长度是否为0,为0返回 true。 | [ -z $a ] 返回 false。 |
| -n | 检测字符串长度是否不为 0,不为 0 返回 true。 | [ -n “$a” ] 返回 true。 |
| $ | 检测字符串是否为空,不为空返回 true。 | [ $a ] 返回 true。 |
6.5文件表达式
-e filename 如果 filename存在,则为真
-d filename 如果 filename为目录,则为真
-f filename 如果 filename为常规文件,则为真
-L filename 如果 filename为符号链接,则为真
-r filename 如果 filename可读,则为真
-w filename 如果 filename可写,则为真
-x filename 如果 filename可执行,则为真
-s filename 如果文件长度不为0,则为真
-h filename 如果文件是软链接,则为真
filename1 -nt filename2 如果 filename1比 filename2新,则为真。
filename1 -ot filename2 如果 filename1比 filename2旧,则为真。
if [ ! -d $logdir ];then
mkdir $logdir
fi
7. Shell echo命令
Shell 的 echo 指令与 PHP 的 echo 指令类似,都是用于字符串的输出。命令格式:
echo string
7.1 显示普通字符串:
echo "It is a test"
这里的双引号完全可以省略,以下命令与上面实例效果一致:
echo It is a test
8. Shell printf 命令
默认 printf 不会像 echo 自动添加换行符,我们可以手动添加 \n。
printf 命令的语法:
printf format-string [arguments...]
参数说明:
- format-string: 为格式控制字符串
- arguments: 为参数列表。
printf "%-10s %-8s %-4s\n" 姓名 性别 体重kg
printf "%-10s %-8s %-4.2f\n" 郭靖 男 66.1234
printf "%-10s %-8s %-4.2f\n" 杨过 男 48.6543
printf "%-10s %-8s %-4.2f\n" 郭芙 女 47.9876
# 输出
姓名 性别 体重kg
郭靖 男 66.12
杨过 男 48.65
郭芙 女 47.99
%s %c %d %f 都是格式替代符,%s 输出一个字符串,%d 整型输出,%c 输出一个字符,%f 输出实数,以小数形式输出。
%-10s 指一个宽度为 10 个字符(- 表示左对齐,没有则表示右对齐),任何字符都会被显示在 10 个字符宽的字符内,如果不足则自动以空格填充,超过也会将内容全部显示出来。
%-4.2f 指格式化为小数,其中 .2 指保留2位小数。
8.1 printf 的转义序列
| 序列 | 说明 |
|---|---|
| \a | 警告字符,通常为ASCII的BEL字符 |
| \b | 后退 |
| \c | 抑制(不显示)输出结果中任何结尾的换行字符(只在%b格式指示符控制下的参数字符串中有效),而且,任何留在参数里的字符、任何接下来的参数以及任何留在格式字符串中的字符,都被忽略 |
| \f | 换页(formfeed) |
| \n | 换行 |
| \r | 回车(Carriage return) |
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \ | 一个字面上的反斜杠字符 |
| \ddd | 表示1到3位数八进制值的字符。仅在格式字符串中有效 |
| \0ddd | 表示1到3位的八进制值字符 |
9. shell test命令
Shell中的 test 命令用于检查某个条件是否成立,它可以进行数值、字符和文件三个方面的测试。
num1=100
num2=100
if test $[num1] -eq $[num2]
then
echo '两个数相等!'
else
echo '两个数不相等!'
fi
# 输出
两个数相等
代码中的 [] 执行基本的算数运算
10. shell流程控制
10.1 if
和 Java、PHP 等语言不一样,sh 的流程控制不可为空。
在 sh/bash 里可不能这么写,如果 else 分支没有语句执行,就不要写这个 else。
if 语句语法格式:
if condition
then
command1
command2
...
commandN
fi
写成一行(适用于终端命令提示符):
if [ $(ps -ef | grep -c "ssh") -gt 1 ]; then echo "true"; fi
加但括号是为了变为一行 双括号是为了不带引号,功能也比较多 可以用正则
if else 语法格式:
if condition
then
command1
command2
...
commandN
else
command
fi
if else-if else 语法格式:
if condition1
then
command1
elif condition2
then
command2
else
commandN
fi
if 特殊知识点
if ps -ax |grep iperf |grep $s_pid > /dev/null; then
kill -15 $s_pid 2>&1>/dev/null
在shell中if可以查找进程 如果存在就是true
10.2 for
https://www.cnblogs.com/EasonJim/p/8315939.html
for循环一般格式为:
1.
for var in item1 item2 ... itemN
do
command1
command2
...
commandN
done
2.
for((i=1;i<=10;i++));
do
echo $(expr $i \* 3 + 1);
done
3.
for i in $(seq 1 10)
do
echo $(expr $i \* 3 + 1);
done
4.
#!/bin/bash
for i in {1..10} # 特殊语法 直接打印1到10
do
echo $(expr $i \* 3 + 1);
done
写成一行:
for var in item1 item2 ... itemN; do command1; command2… done;
10.3 while 语句
while 循环用于不断执行一系列命令,也用于从输入文件中读取数据。其语法格式为:
while condition
do
command
done
let 命令
let 命令是 BASH 中用于计算的工具,用于执行一个或多个表达式,变量计算中不需要加上 $ 来表示变量。
实例:
自加操作:let no++
自减操作:let no–
简写形式 let no+=10,let no-=20,分别等同于 let no=no+10,let no=no-20。
10.4 无限循环
无限循环语法格式:
while :
do
command
done
或者
while true
do
command
done
或者
for (( ; ; ))
10.5 until 循环
until 循环执行一系列命令直至条件为 true 时停止。
until 循环与 while 循环在处理方式上刚好相反。
一般 while 循环优于 until 循环,但在某些时候—也只是极少数情况下,until 循环更加有用。
until 语法格式:
until condition
do
command
done
condition 一般为条件表达式,如果返回值为 false,则继续执行循环体内的语句,否则跳出循环。
10.6 case … esac
case … esac 为多选择语句,与其他语言中的 switch … case 语句类似,是一种多分枝选择结构,每个 case 分支用右圆括号开始,用两个分号 ;; 表示 break,即执行结束,跳出整个 case … esac 语句,esac(就是 case 反过来)作为结束标记。
可以用 case 语句匹配一个值与一个模式,如果匹配成功,执行相匹配的命令。
case … esac 语法格式如下:
case 值 in
模式1)
command1
command2
...
commandN
;;
模式2)
command1
command2
...
commandN
;;
esac
case 工作方式如上所示,取值后面必须为单词 in,每一模式必须以右括号结束。取值可以为变量或常数,匹配发现取值符合某一模式后,其间所有命令开始执行直至 ;;。
取值将检测匹配的每一个模式。一旦模式匹配,则执行完匹配模式相应命令后不再继续其他模式。
如果无一匹配模式,使用星号 * 捕获该值,再执行后面的命令。
每一个模式后面都必须要有;;
11. Shell 函数
shell中函数的定义格式如下:
[ function ] funname [()]
{
action;
[return int;]
}
说明:
- 可以带function fun() 定义,也可以直接fun() 定义,不带任何参数。
- 参数返回,可以显示加:return 返回,如果不加,将以最后一条命令运行结果,作为返回值。 return后跟数值n(0-255)
函数返回值在调用该函数后通过 $? 来获得。
注意:所有函数在使用前必须定义。这意味着必须将函数放在脚本开始部分,直至shell解释器首次发现它时,才可以使用。调用函数仅使用其函数名即可。
11.1 函数参数
在Shell中,调用函数时可以向其传递参数。在函数体内部,通过 $n 的形式来获取参数的值,例如,$1表示第一个参数,$2表示第二个参数…
带参数的函数示例:
#!/bin/bash
# author:菜鸟教程
# url:www.runoob.com
funWithParam(){
echo "第一个参数为 $1 !"
echo "第二个参数为 $2 !"
echo "第十个参数为 $10 !"
echo "第十个参数为 ${10} !"
echo "第十一个参数为 ${11} !"
echo "参数总数有 $# 个!"
echo "作为一个字符串输出所有参数 $* !"
}
funWithParam 1 2 3 4 5 6 7 8 9 34 73
输出结果:
第一个参数为 1 !
第二个参数为 2 !
第十个参数为 10 !
第十个参数为 34 !
第十一个参数为 73 !
参数总数有 11 个!
作为一个字符串输出所有参数 1 2 3 4 5 6 7 8 9 34 73 !
注意, 10 不能获取第十个参数,获取第十个参数需要 10 不能获取第十个参数,获取第十个参数需要 10不能获取第十个参数,获取第十个参数需要{10}。当n>=10时,需要使用${n}来获取参数。
| 参数处理 | 说明 |
|---|---|
| $# | 传递到脚本或函数的参数个数 |
| $* | 以一个单字符串显示所有向脚本传递的参数 |
| $$ | 脚本运行的当前进程ID号 |
| $! | 后台运行的最后一个进程的ID号 |
| $@ | 与$*相同,但是使用时加引号,并在引号中返回每个参数。 |
| $- | 显示Shell使用的当前选项,与set命令功能相同。 |
| $? | 显示最后命令的退出状态。0表示没有错误,其他任何值表明有错误。 |
11.2 使用``的方式执行函数
tg_ver=`tg_read 1 $TG_VERSION` 其中 tg_read 是一个函数 1和$TG_VERSION是参数
会将函数中的全部echo(echo重定向的不算)赋值给tg_ver 并且那个echo不会打印
脚本文件
cat /home/admin/wb-st846375/virt-test-scripts/testscripts/time-test.sh
vm_name=$1
times=$2
project_path=$(cd $(dirname ${BASH_SOURCE[0]})/..; pwd)
. $project_path/config.sh
. $project_path/houyi_commands/instance.sh
image_type=$(get_image_type $vm_name)
if [[ $image_type == Windows* ]]; then
user=Administrator
else
user=root
fi
ip=$(go2which $vm_name | grep '172.16' | sed 's/.*ip_addr=\(.*\)|status.*/\1/')
vgw_ip=$(go2hyapi detail_vm vm_name=$vm_name | grep -i vgw_vip | awk -F'/' '{print $1}' | awk -F'>' '{print $2}')
echo $vgw_ip
tunnel_id=$(go2which $vm_name | grep 'tunnel_id' | awk -F'|' '{print $2}' | awk -F'=' '{print $2}')
echo $tunnel_id
function start_vm() {
echo "begin to start vm"
date0=$(date +'%s')
res=$(go2hyapi start_vm vm_name=$vm_name reschedule_mode=forbidden)
if [ $? -ne 0 ] ;then
echo "start vm failed: " $res
exit 1
fi
ret=$(echo "$res" | grep -c ">200<")
if [ $ret -ne 1 ] ;then
echo "start vm failed: " $res
exit 1
fi
while true
do
ret=$(sudo LD_PRELOAD=/usr/lib/libvsock.so VID=$tunnel_id VGWIP=$vgw_ip sshpass -p aliyunecs520! ssh $user@$ip ls -al)
if [ $? -eq 0 ];then
date1=$(date +'%s')
break
#if sudo LD_PRELOAD=/usr/lib/libvsock.so VID=$tunnel_id VGWIP=$vgw_ip ping $ip -c 2; then
# date1=$(date +'%s')
# break
else
sleep 5
continue
fi
done
echo "end start vm"
start_time=$(($date1-$date0))
start_time_all=$(($start_time_all+$start_time))
msg="vm:$vm_name start_vm with check_ping succeed in $start_time s. $(date)"
echo "$msg"
}
function stop_vm() {
echo "begin to stop vm"
date0=$(date +'%s')
res=$(go2hyapi stop_vm vm_name=$vm_name)
ret=$?
if [ $ret -ne 0 ] ;then
echo "stop vm failed: " $res
exit 1
fi
ret=$(echo "$res" | grep -c ">200<")
if [ $ret -ne 1 ] ;then
echo "stop vm failed: " $res
exit 1
fi
# 等待虚拟机停止完成
while true
do
if go2which $vm_name | grep instance_info | grep 'status' | grep -i 'stopped'; then
echo "vm:$vm_name is stopped"
date1=$(date +'%s')
break
else
sleep 3
continue
fi
done
stop_time=$(($date1-$date0))
stop_time_all=$(($stop_time_all+$stop_time))
echo "vm:$vm_name start_vm with check_ping succeed in $stop_time s. $(date)"
}
start_time_all=0
stop_time_all=0
for i in $(seq 1 $times)
do
echo "=============$i test============="
start_vm
stop_vm
done
echo "stat-all: $start_time_all"
echo "stop-all: $stop_time_all"

















 548
548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









