一、Flume是什么
Flume是一个分布式、可靠、和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
二 、Fulme 有什么特点
Fulme 特点如下:
1、可靠性
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为:end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。),Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送),Best effort(数据发送到接收方后,不会进行确认)。
2、可扩展性
Flume采用了三层架构,分别为agent,collector和storage,每一层均可以水平扩展。其中,所有agent和collector由master统一管理,这使得系统容易监控和维护,且master允许有多个(使用ZooKeeper进行管理和负载均衡),这就避免了单点故障问题。
3、可管理性
所有agent和colletor由master统一管理,这使得系统便于维护。多master情况,Flume利用ZooKeeper和gossip,保证动态配置数据的一致性。用户可以在master上查看各个数据源或者数据流执行情况,且可以对各个数据源配置和动态加载。Flume提供了web 和shell script command两种形式对数据流进行管理。
4、功能可扩展性
用户可以根据需要添加自己的agent,collector或者storage。此外,Flume自带了很多组件,包括各种agent(file, syslog等),collector和storage(file,HDFS等)。
5、文档丰富,社区活跃
Flume 已经成为 Hadoop 生态系统的标配,它的文档比较丰富,社区比较活跃,方便我们学习。
三、Flume NG基本架构
Flume NG是一个分布式、可靠、可用的系统,它能够将不同数据源的海量日志数据进行高效收集、聚合、移动,最后存储到一个中心化数据存储系统中。由原来的Flume OG到现在的Flume NG,进行了架构重构,并且现在NG版本完全不兼容原来的OG版本。经过架构重构后,Flume NG更像是一个轻量的小工具,非常简单,容易适应各种方式日志收集,并支持failover和负载均衡。
Flume NG 的架构图如下所示。
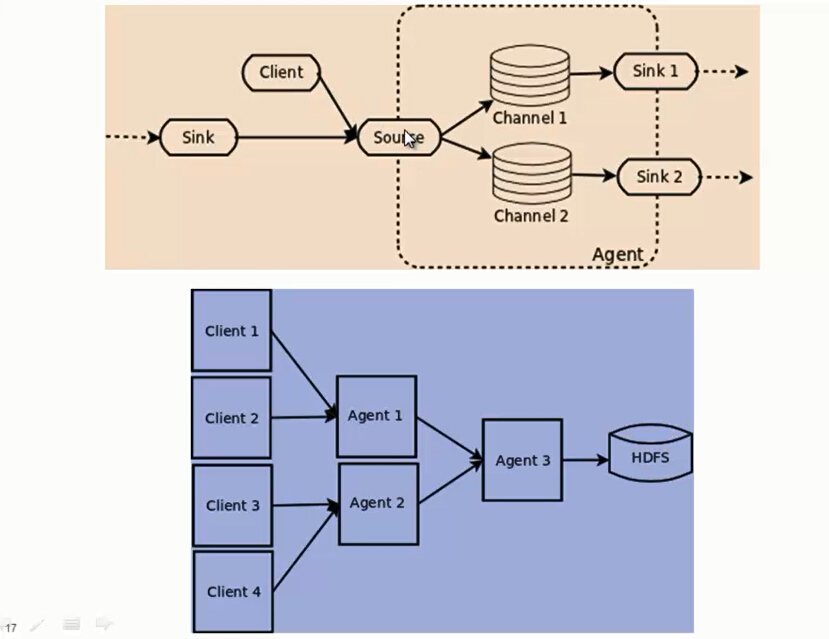
根据上图我们可以了解到Flume 的一些核心概念:
1、Event:一个数据单元,带有一个可选的消息头。
2、Flow:Event从源点到达目的点的迁移的抽象。
3、Client:操作位于源点处的Event,将其发送到Flume Agent。
4、Agent:一个独立的Flume进程,包含组件Source、Channel、Sink。
5、Source:用来消费传递到该组件的Event。
6、Channel:中转Event的一个临时存储,保存有Source组件传递过来的Event。
7、Sink:从Channel中读取并移除Event,将Event传递到Flow Pipeline中的下一个Agent(如果有的话)
在了解了Flume的核心概念之后,下面我们对各个核心概念进行深入剖析:
Event
1、Event 是Flume数据传输的基本单元。
2、Flume 以事件的形式将数据从源头传输到最终的目的。
3、Event 由可选的header和载有数据的一个byte array构成。
1)载有的数据对Flume是不透明的。
2)Header 是容纳了key-value字符串对的无序集合,key在集合内是唯一的。
3)Header 可以在上下文路由中使用扩展。
Client
1、Client 是一个将原始log包装成events并且发送它们到一个或者多个agent的实体。
2、Client 在Flume的拓扑结构中不是必须的,它的目的是从数据源系统中解耦Flume
Agent
1、一个Agent包含Source、Channel、Sink和其他组件。
2、它利用这些组件将events从一个节点传输到另一个节点或最终目的地。
3、agent是Flume流的基础部分。
4、Flume 为这些组件提供了配置、生命周期管理、监控支持。
Agent之Source
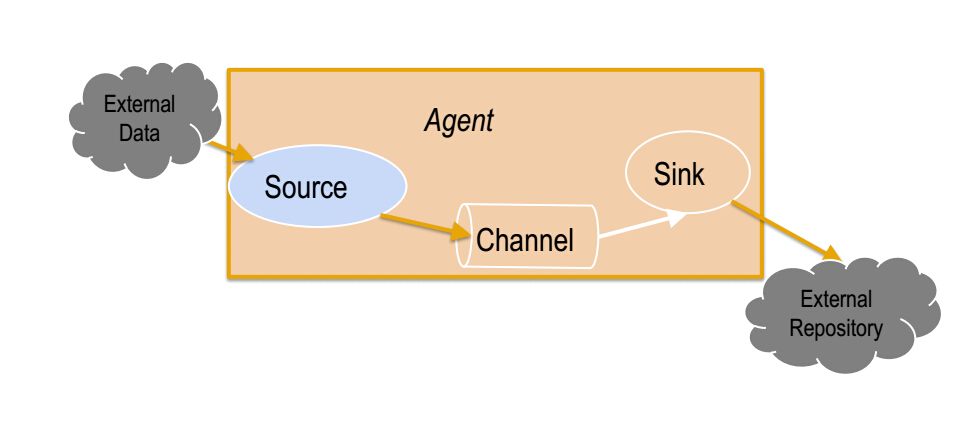
1、Source负责接收event或通过特殊机制产生event,并将events批量的放到一个或多个Channel。
2、Source包含event驱动和轮询两种类型。
3、Source 有不同的类型。
1)与系统集成的Source:Syslog,NetCat。
2)自动生成事件的Source:Exec
3)用于Agent和Agent之间的通信的IPC Source:Avro、Thrift。
4、Source必须至少和一个Channel关联。
Agent之Channel与Sink
Agent之Channel与Sink 的结构图如下所示:
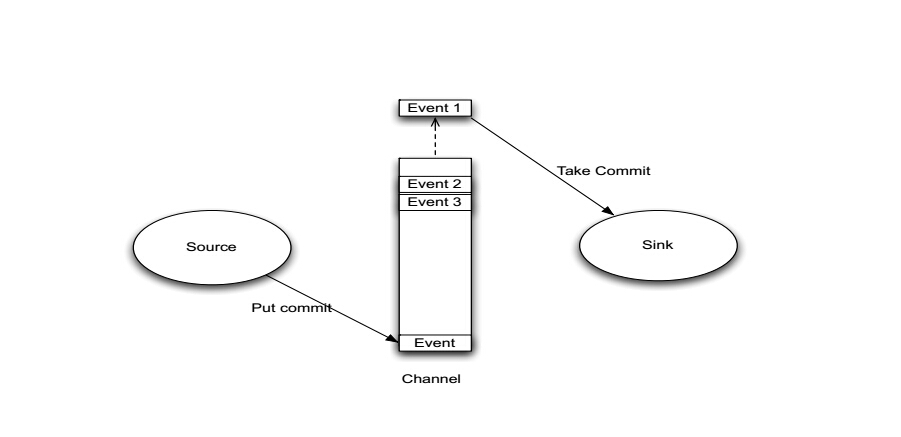
Agent之Channel
1、Channel位于Source和Sink之间,用于缓存进来的event。
2、当Sink成功的将event发送到吓一跳的Channel或最终目的地,event才Channel中移除。
3、不同的Channel提供的持久化水平也是不一样的:
1)Memory Channel:volatile。
2)File Channel:基于WAL实现。
3)JDBC Channel:基于嵌入Database实现。
4、Channel支持事物,提供较弱的顺序保证。
5、Channel可以和任何数量的Source和Sink工作。
Agent之Sink
1、Sink负责将event传输到吓一跳或最终目的,成功完成后将event从Channel移除。
2、有不同类型的Sink:
1)存储event到最终目的的终端Sink。比如HDFS,Hbase。
2)自动消耗的Sink。比如:Null Sink。
3)用于Agent间通信的IPC sink:Avro。
3、Sink必须作用于一个确切的Channel。
四、Flume NG安装部署
下面我们来安装部署 Flume NG,这里我们安装配置两个节点cloud003、cloud004,以Avro Source+Memory Channel+HDFS Sink结合方式为例:
1、下载flume安装包。
apache-flume-1.6.0-bin.tar.gz安装包分别解压到cloud003、cloud004节点上的/usr/Java/hadoop/app/目录下。这里我们以cloud003为例,cloud004同样操作。
[hadoop@cloud003 app]$ tar -zxvf apache-flume-1.6.0-bin.tar.gz
[hadoop@cloud003 app]$ mv apache-flume-1.6.0-bin flume
2、在cloud003节点上,进入flume/conf目录。
[hadoop@cloud003 app]$ cd flume/conf
[hadoop@cloud003 conf]$ ls
flume-conf.properties.template flume-env.ps1.template flume-env.sh.template log4j.properties
需要通过flume-conf.properties.template复制一个flume-conf.properties配置文件。
[hadoop@cloud003 conf]$ cp flume-conf.properties.template flume-conf.properties
[hadoop@cloud003 conf]$ ls
flume-conf.properties flume-conf.properties.template flume-env.ps1.template flume-env.sh.template log4j.properties
修改cloud003节点上的flume-conf.properties配置文件。这里收集日志文件到收集端。配置参数的详细说明可以参考官方文档。
[hadoop@cloud003 conf]$ vi flume-conf.properties
#定义source、channel、sink 名称
a1.sources = r1 //这里的a1命名可以自定义,但需要跟后面启动配置名称一致就可以
a1.sinks = k1
a1.channels = c1
#定义并配置r1
a1.sources.r1.channels = c1
a1.sources.r1.type = avro //source类型
a1.sources.r1.bind = 0.0.0.0 //默认绑定本机
a1.sources.r1.port=41414 //默认端口
# 定义并配置k1
a1.sinks.k1.channel = c1
a1.sinks.k1.type = avro //sink类型
a1.sinks.k1.hostname = cloud004 //将数据传递给cloud004
a1.sinks.k1.port = 41414 //默认端口号
#定义并配置c1
a1.channels.c1.type=FILE //channel类型
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
3、在cloud004节点上,进入flume/conf目录。
[hadoop@cloud004 app]$ cd flume/conf
[hadoop@cloud004 conf]$ ls
flume-conf.properties.template flume-env.ps1.template flume-env.sh.template log4j.properties
需要通过flume-conf.properties.template复制一个flume-conf.properties配置文件。
[hadoop@cloud004 conf]$ cp flume-conf.properties.template flume-conf.properties
[hadoop@cloud004 conf]$ ls
flume-conf.properties flume-conf.properties.template flume-env.ps1.template flume-env.sh.template log4j.properties
修改cloud004节点上的flume-conf.properties配置文件。从cloud003端接收数据,然后写入到HDFS文件系统中。配置参数的详细说明可以参考官方文档。
[hadoop@cloud004 conf]$ vi flume-conf.properties
# 定义source、channel、sink 名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#定义并配置 r1
a1.sources.r1.type = avro //这里要跟cloud003端的sink类型一致
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 41414
a1.sources.r1.channels = c1
#定义并配置k1
a1.sinks.k1.channel = c1
a1.sinks.k1.type=hdfs //sink的输出类型为hdfs
a1.sinks.k1.hdfs.path=hdfs://cloud001:9000/data/flume //hdfs上传文件路径
a1.sinks.k1.hdfs.fileType=DataStream
#定义并配置c1
a1.channels.c1.type=File
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
4、首先要保证 Hadoop 集群正常运行,这里cloud001是Namenode。
[hadoop@cloud001 hadoop]$ jps
2625 JournalNode
1563 QuorumPeerMain
18808 NameNode
26146 Jps
3583 ResourceManager
5、首先在cloud004节点上启动Agent,保证能接受传过来的数据,然后传递给hdfs。
[hadoop@cloud003 flume]$ bin/flume-ng agent -c ./conf/ -f conf/flume-conf.properties -Dflume.root.logger=INFO,console -n a1
Info: Including Hadoop libraries found via (/usr/java/hadoop/bin/hadoop) for HDFS access
Info: Excluding /usr/java/hadoop/share/hadoop/common/lib/slf4j-api-1.7.5.jar from classpath
Info: Excluding /usr/java/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar from classpath
Info: Including Hive libraries found via () for Hive access
2015-08-25 08:54:22,018 (conf-file-poller-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:133)] Reloading configuration file:conf/flume-conf.properties
2015-08-25 08:54:22,033 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:1017)] Processing:k1
2015-08-25 08:54:22,829 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:96)] Component type: CHANNEL, name: c1 started
2015-08-25 08:54:22,830 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:173)] Starting Sink k1
2015-08-25 08:54:22,830 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:184)] Starting Source r1
2015-08-25 08:54:22,832 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.source.AvroSource.start(AvroSource.java:228)] Starting Avro source r1: { bindAddress: 0.0.0.0, port: 41414 }...
2015-08-25 08:54:22,835 (lifecycleSupervisor-1-1) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:120)] Monitored counter group for type: SINK, name: k1: Successfully registered new MBean.
2015-08-25 08:54:22,835 (lifecycleSupervisor-1-1) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:96)] Component type: SINK, name: k1 started
2015-08-25 08:54:23,326 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:120)] Monitored counter group for type: SOURCE, name: r1: Successfully registered new MBean.
2015-08-25 08:54:23,327 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:96)] Component type: SOURCE, name: r1 started
2015-08-25 08:54:23,328 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.source.AvroSource.start(AvroSource.java:253)] Avro source r1 started.
需要注意的是:-n a1中的参数值a1必须与flume-conf.properties配置文件的a1名称一致。
6、在cloud003节点上,启动Avro Client,发送数据给cloud004节点的agent。
[hadoop@cloud003 flume]$ bin/flume-ng avro-client -c ./conf/ -H cloud004 -p 41414 -F /usr/java/hadoop/app/flume/mydata/2.log -Dflume.root.logger=DEBUG,console
Info: Including Hadoop libraries found via (/usr/java/hadoop/bin/hadoop) for HDFS access
Info: Excluding /usr/java/hadoop/share/hadoop/common/lib/slf4j-api-1.7.5.jar from classpath
Info: Excluding /usr/java/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar from classpath
Info: Including Hive libraries found via () for Hive access
2015-08-25 09:10:42,629 (main) [DEBUG - org.apache.flume.api.NettyAvroRpcClient.configure(NettyAvroRpcClient.java:499)] Batch size string = 5
2015-08-25 09:10:42,672 (main) [WARN - org.apache.flume.api.NettyAvroRpcClient.configure(NettyAvroRpcClient.java:634)] Using default maxIOWorkers
2015-08-25 09:10:43,548 (main) [DEBUG - org.apache.flume.client.avro.AvroCLIClient.run(AvroCLIClient.java:234)] Finished
2015-08-25 09:10:43,548 (main) [DEBUG - org.apache.flume.client.avro.AvroCLIClient.run(AvroCLIClient.java:237)] Closing reader
2015-08-25 09:10:43,550 (main) [DEBUG - org.apache.flume.client.avro.AvroCLIClient.run(AvroCLIClient.java:241)] Closing RPC client
2015-08-25 09:10:43,567 (main) [DEBUG - org.apache.flume.client.avro.AvroCLIClient.main(AvroCLIClient.java:84)] Exiting
需要注意:-H cloud004中的cloud004是agent节点地址,-F /usr/java/hadoop/app/flume/mydata/2.log 是发送的日志文件内容。
7、查看HDFS上同步过来的数据。
[hadoop@cloud001 hadoop]$ hadoop fs -ls /data/flume/
Found 1 items
-rw-r























 270
270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









