







目录
一、图的实现。
邻接表:是一种图的表示方法,常用于表示稀疏图(即边数相对于顶点数较少的图)。邻接表通常由一个一维数组和若干个链表组成。
一维数组中的每个元素对应图中的一个顶点,而每个元素所对应的链表则存储了与该顶点有直接连接边的所有顶点。链表中的节点一般包含两个部分,一个是指向邻接点的指针,一个是存储权值(如果图是带权图的话)。
因此,可以说邻接表中包含了一个一维数组和多个链表。这些链表可以是普通的单向链表,也可以是其他类型的链表,如双向链表等。在实现时,通常采用指针来实现链表结构。

package 图的入门.无向图;
import 线性表.线性表_队列.Queue;
public class Graph {
//顶点数目
private final int V;
//边的数目
private int E;
//邻接表
private Queue<Integer>[] adj;
public Graph(int V){
//初始化顶点的数量
this.V = V;
//初始化边的数量
this.E = 0;
//初始化邻接表
this.adj = new Queue[V];
for (int i = 0; i < adj.length; i++) {
adj[i] = new Queue<Integer>();
}
}
//获取顶点数目
public int V(){
return V;
}
//获取边的数目
public int E(){
return E;
}
//向图中添加一条边v-w
public void addEdge(int v,int w){
//在无向图中,边是没有方向的,所以该边既可以说是从v到w的边,又可以说是从w到v的边,因此,需要让w出现在v的邻接表中,并且还要让v出现在w的邻接表中
adj[v].enqueue(w);
adj[w].enqueue(v);
//边的数量+1
E++;
}
//获取和顶点v相邻的所有顶点
public Queue<Integer> adj(int v){
return adj[v];
}
}
二、深度优先搜索。
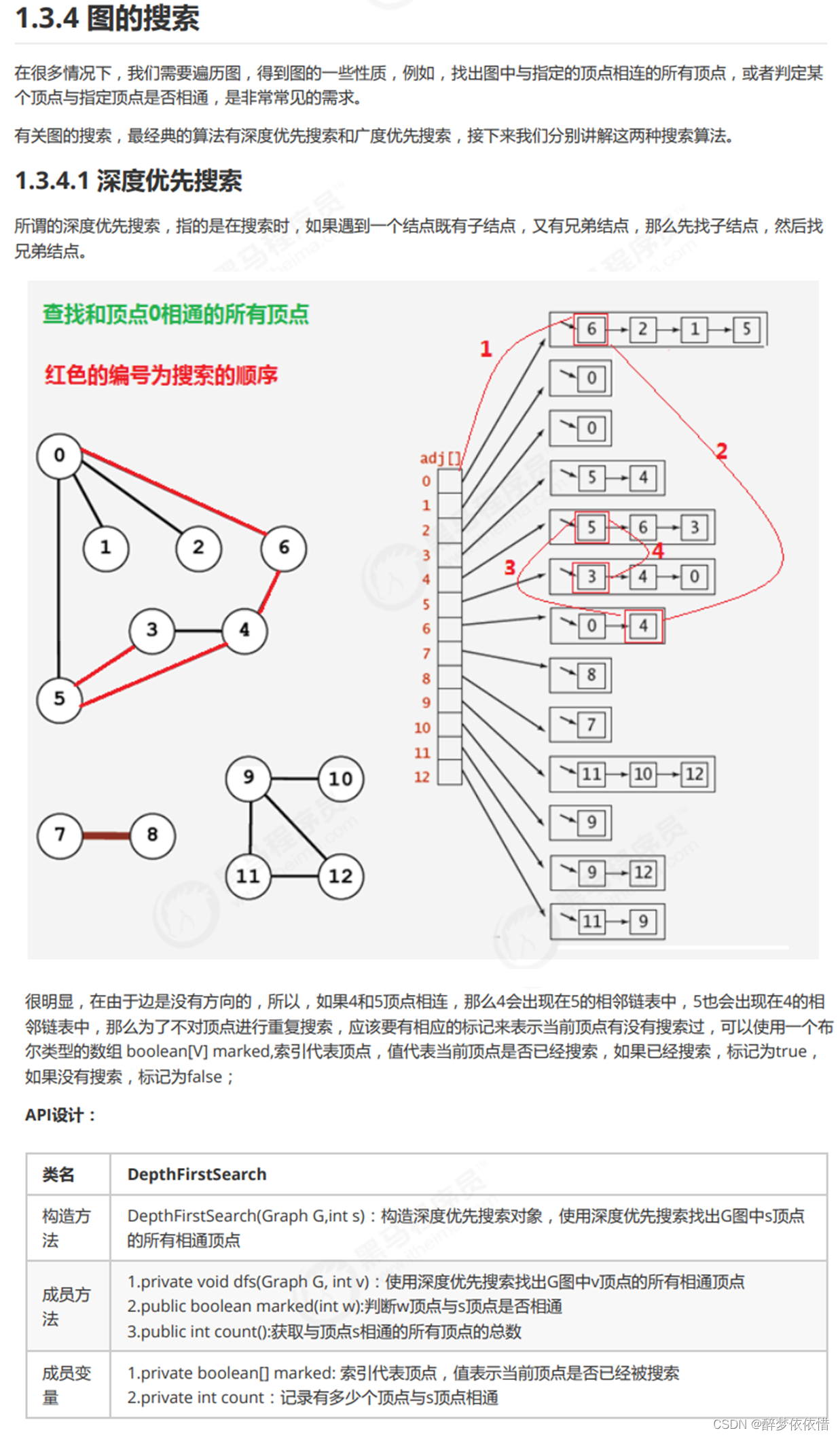
package 图的入门.无向图.深度优先搜索;
import 图的入门.无向图.Graph;
public class DepthFirstSearch {
//索引代表顶点,值代表当前顶点是否已经被搜索
private boolean[] marked;
//记录有多少个顶点与s顶点相通
private int count;
//构造深度优先搜索对象,使用深度优先搜索找出G图中s顶点的所有相邻顶点
public DepthFirstSearch(Graph G,int s){
//初始化marked数组
this.marked = new boolean[G.V()];
//初始化跟顶点s相通的顶点的数量
this.count = 0;
dfs(G,s);
}
//使用深度优先搜索找出G图中v顶点的所有相通顶点
private void dfs(Graph G,int v){
//把v顶点标识为已搜索
marked[v] = true;
for (Integer w : G.adj(v)) {
//判断当前w顶点有没有被搜索过,如果没有被搜索过,则递归调用dfs方法进行深度搜索
if (!marked(w)){
dfs(G,w);
}
}
//相通顶点数量+1
count++;
}
//判断w顶点与s顶点是否相通
public boolean marked(int w){
return marked[w];
}
//获取与顶点s相通的所有顶点的总数
public int count(){
return count;
}
}
代码测试:
package 图的入门.无向图.深度优先搜索;
import 图的入门.无向图.Graph;
public class DepthFirstSearchTest {
public static void main(String[] args) {
//准备Graph对象
Graph G = new Graph(13);
G.addEdge(0,5);
G.addEdge(0,1);
G.addEdge(0,2);
G.addEdge(0,6);
G.addEdge(5,3);
G.addEdge(5,4);
G.addEdge(3,4);
G.addEdge(4,6);
G.addEdge(7,8);
G.addEdge(9,10);
G.addEdge(9,11);
G.addEdge(9,12);
G.addEdge(11,12);
//准备深度优先搜索对象
DepthFirstSearch search = new DepthFirstSearch(G, 0);
//测试与某个顶点相通的数量
int count = search.count();
System.out.println("与起点0相通的顶点的数量为:"+count);
//测试某个顶点与起点是否相同
boolean marked1 = search.marked(5);
System.out.println("顶点5与顶点0是否相通:"+marked1);
boolean marked2 = search.marked(7);
System.out.println("顶点7与顶点0是否相通:"+marked2);
}
}
三、广度优先搜索。
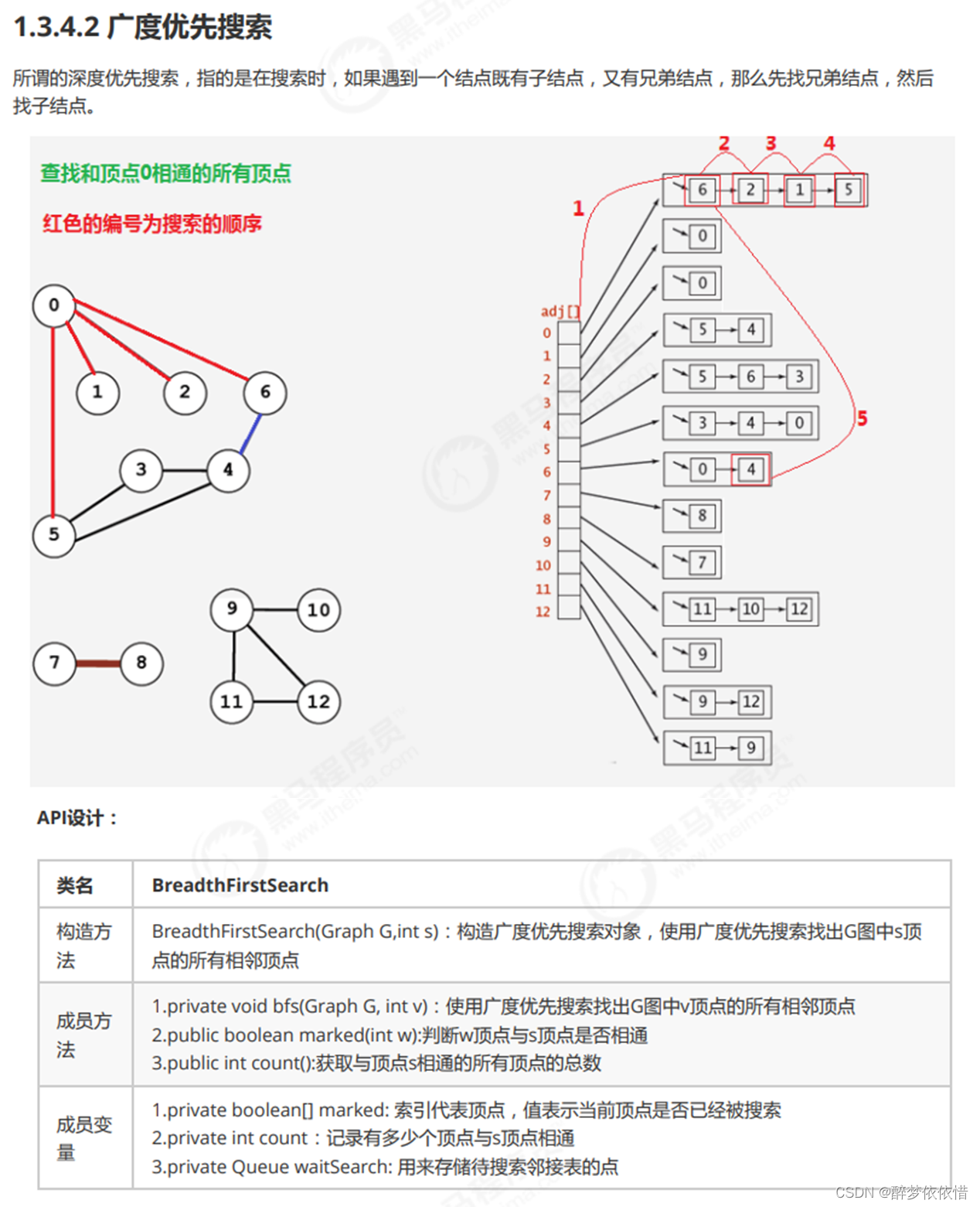
package 图的入门.无向图.广度优先搜索;
import 图的入门.无向图.Graph;
import 线性表.线性表_队列.Queue;
public class BreadthFirstSearch {
//索引代表顶点,值表示当前顶点是否已经被搜索
private boolean[] marked;
//记录有多少个顶点与s顶点相通
private int count;
//用来存储待搜索邻接表的点
private Queue<Integer> waitSearch;
//构造广度优先搜索对象,使用广度优先搜索找出G图中s顶点的所有相邻顶点
public BreadthFirstSearch(Graph G,int s){
this.marked = new boolean[G.V()];
this.count = 0;
this.waitSearch = new Queue<Integer>();
bfs(G,s);
}
//使用广度优先搜索找出G图中v顶点的所有相邻顶点
private void bfs(Graph G,int v){
//把当前顶点v标识为已搜索
marked[v] = true;
//让顶点v进入队列
waitSearch.enqueue(v);
//通过循环,如果队列不为空,则从队列中弹出一个待搜索的顶点进行搜索
while (!waitSearch.isEmpty()) {
//弹出一个待搜索的顶点
Integer wait = waitSearch.dequeue();
//遍历wait顶点的邻接表
for (Integer w : G.adj(wait)) {
if (!marked(w)){
marked[w] = true;
waitSearch.enqueue(w);
//让相通的顶点数量+1
count++;
}
}
}
}
//判断w顶点与s顶点是否相通
public boolean marked(int w){
return marked[w];
}
//获取与顶点s相通的所有顶点的总数
public int count(){
return count;
}
}
代码测试:
package 图的入门.无向图.广度优先搜索;
import 图的入门.无向图.Graph;
import 图的入门.无向图.深度优先搜索.DepthFirstSearch;
public class BreadthFirstSearchTest {
public static void main(String[] args) {
//准备Graph对象
Graph G = new Graph(13);
G.addEdge(0,5);
G.addEdge(0,1);
G.addEdge(0,2);
G.addEdge(0,6);
G.addEdge(5,3);
G.addEdge(5,4);
G.addEdge(3,4);
G.addEdge(4,6);
G.addEdge(7,8);
G.addEdge(9,10);
G.addEdge(9,11);
G.addEdge(9,12);
G.addEdge(11,12);
//准备广度优先搜索对象
BreadthFirstSearch search = new BreadthFirstSearch(G, 0);
//测试与某个顶点相通的数量
int count = search.count();
System.out.println("与起点0相通的顶点的数量为:"+count);
//测试某个顶点与起点是否相同
boolean marked1 = search.marked(5);
System.out.println("顶点5与顶点0是否相通:"+marked1);
boolean marked2 = search.marked(7);
System.out.println("顶点7与顶点0是否相通:"+marked2);
}
}
四、畅通工程。

package 图的入门.无向图.图_案例_畅通工程续;
import 图的入门.无向图.Graph;
import 图的入门.无向图.深度优先搜索.DepthFirstSearch;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
public class Traffic_Project_Test2 {
public static void main(String[] args) throws IOException {
//构建一个缓冲读取流BufferedReader
BufferedReader br = new BufferedReader(new FileReader("D:\\数据结构与算法资料\\代码\\algorithm\\src\\traffic_project.txt"));
//读取第一行数据20
Integer totalNumber = Integer.valueOf(br.readLine());
//构建一个Graph对象
Graph G = new Graph(totalNumber);
//读取第二行数据7
Integer roadNumber = Integer.valueOf(br.readLine());
//循环读取有限次(7),读取已经修建好的道路
for (Integer i = 1; i <= roadNumber; i++) {
String road = br.readLine();//"0 1"
String[] str = road.split(" ");
Integer v = Integer.valueOf(str[0]);
Integer w = Integer.valueOf(str[1]);
//调用图的addEdge方法,把边添加到图中,表示已经修建好的道路
G.addEdge(v,w);
}
//构建一个深度优先搜索对象,起点设置为顶点9
DepthFirstSearch search = new DepthFirstSearch(G, 9);
//调用marked方法,判断8顶点和10顶点是否与起点9相同
System.out.println("顶点8和顶点9是否相通:"+search.marked(8));
System.out.println("顶点10和顶点9是否相通:"+search.marked(10));
}
}
五、路径查找。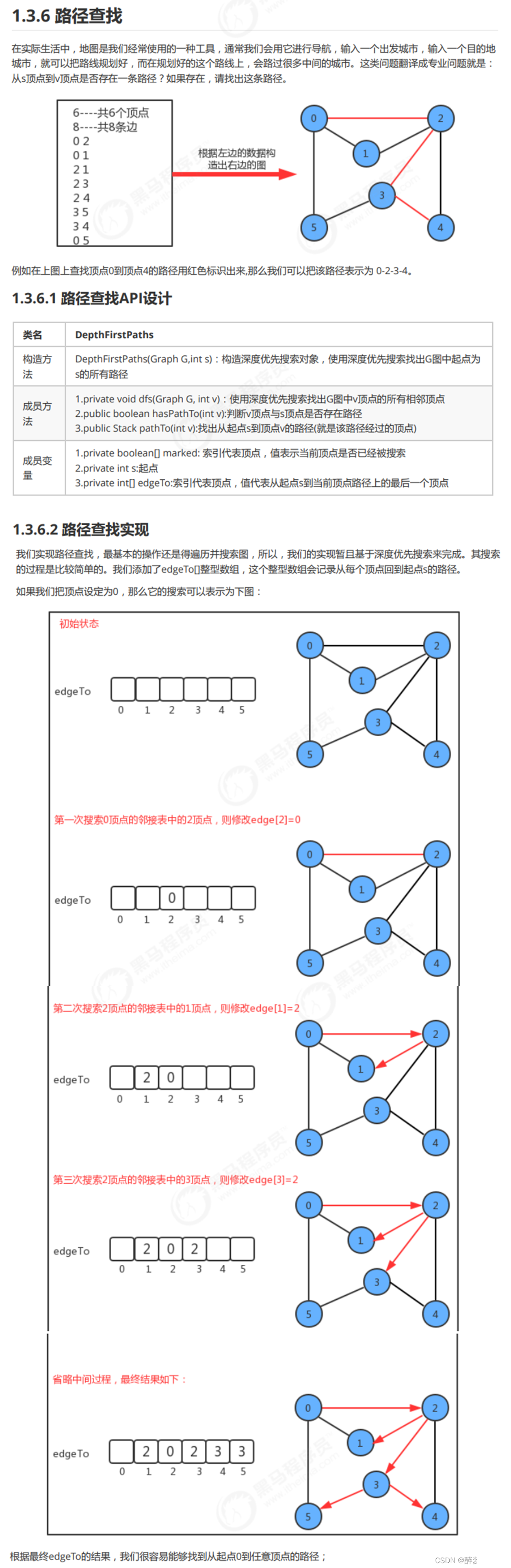
package 图的入门.无向图.图_路径查找;
import 图的入门.无向图.Graph;
import 线性表.线性表_栈.Stack;
public class DepthFirshPaths {
//索引代表顶点,值标识当前顶点是否已经被搜索
private boolean[] marked;
//起点
private int s;
//索引代表顶点,值代表从起点s到当前顶点路径上的最后一个顶点
private int[] edgeTo;
//构造深度优先搜索对象,使用深度优先搜索找出G图中起点为s的所有路径
public DepthFirshPaths(Graph G,int s){
//初始化marked数组
this.marked = new boolean[G.V()];
//初始化起点
this.s = s;
//初始化dgeTo数组
this.edgeTo = new int[G.V()];
dfs(G,s);
}
//使用深度优先搜索找出G图中v顶点的所有相邻顶点
private void dfs(Graph G,int v){
//把v表示为已搜索
marked[v] = true;
//遍历顶点v的邻接表,拿到每一个相邻的顶点,继续递归搜索
for (Integer w : G.adj(v)) {
//如果顶点w没有被搜索,则继续递归搜索
if (!marked[w]){
edgeTo[w] = v;//到达顶点w的路径上的最后一个顶点是v
dfs(G,w);
}
}
}
//判断w顶点与s顶点是否存在路径
public boolean hasPathTo(int v){
return marked[v];
}
//找出从起点s到顶点v的路径(就是该路径经过的顶点)
public Stack<Integer> pathTo(int v){
//判断是否有路径,如果没有,则直接返回null
if (!hasPathTo(v)){
return null;
}
//创建一个栈对象,保存路径中的所有顶点
Stack<Integer> path = new Stack<>();
//通过循环,从顶点v开始,一直往前找,到找到起点位置
for (int x = v; x != s; x = edgeTo[x]) {
path.push(x);
}
//把起点s放到栈中
path.push(s);
return path;
}
}
代码测试:
package 图的入门.无向图.图_路径查找;
import 图的入门.无向图.Graph;
import 线性表.线性表_栈.Stack;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class DepthFirshPathsTest {
public static void main(String[] args) throws IOException {
//构建缓冲读取流BufferedReader
BufferedReader br = new BufferedReader(new InputStreamReader(DepthFirshPathsTest.class.getClassLoader().getResourceAsStream("road_find.txt")));
//读取第一行数据6
Integer total = Integer.valueOf(br.readLine());
//根据第一行数据构建一幅图Graph
Graph G = new Graph(total);
//读取第二行数据8
Integer edgeNumbers = Integer.valueOf(br.readLine());
//继续通过循环读取每一条关联的两个顶点,调用addEdge方法,添加边
for (Integer i = 1; i <= edgeNumbers; i++) {
String edge = br.readLine();
String[] str = edge.split(" ");
int v = Integer.parseInt(str[0]);
int w = Integer.parseInt(str[1]);
G.addEdge(v,w);
}
//构建路径查找对象,并设置起点为0
DepthFirshPaths paths = new DepthFirshPaths(G, 0);
//调用pathTo(4),找到从起点0到终点4的路径,返回Stack
Stack<Integer> path = paths.pathTo(4);
StringBuilder sb = new StringBuilder();
//遍历栈对象
for (Integer v : path) {
sb.append(v+"-");
}
sb.deleteCharAt(sb.length()-1);
System.out.println(sb);
}
}
六、加权无向图。
(1)加权无向边。
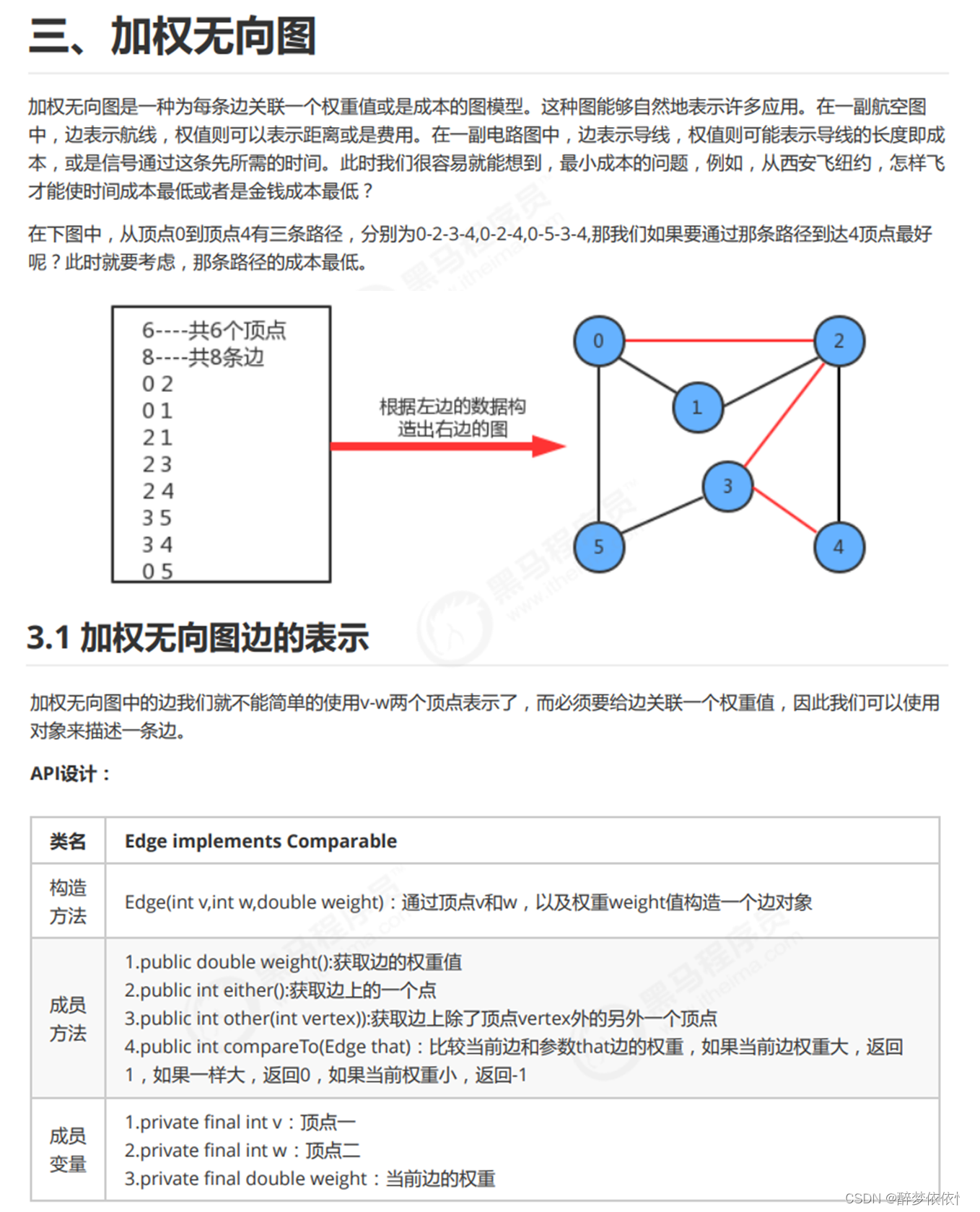
package 图的入门.无向图.加权无向图;
public class Edge implements Comparable<Edge>{
private final int v;//顶点一
private final int w;//顶点二
private final double weight;//当前边的权重
//通过顶点v和w,以及权重weight值构造一个边对象
public Edge(int v,int w,double weight){
this.v = v;
this.w = w;
this.weight = weight;
}
//获取边的权重值
public double weight(){
return weight;
}
//获取边上的一个点
public int either(){
return v;
}
//获取边上除了顶点vertex外的另外一个顶点
public int other(int vertex){
if (vertex == v){
return w;
}else {
return v;
}
}
@Override
public int compareTo(Edge o) {
//使用一个遍历记录比较结果
int cmp;
if (this.weight > o.weight){
//如果当前边的权重值大,则让cmp=1;
cmp = 1;
}else if (this.weight < o.weight){
//如果当前边的权重值小,则让cmp=-1;
cmp = -1;
}else {
//如果当前的权重值和o边的权重值一样大,则让cmp=0;
cmp = 0;
}
return cmp;
}
}
(2)加权无向图。

package 图的入门.无向图.加权无向图;
import 线性表.线性表_队列.Queue;
public class EdgeWeightedGraph {
//顶点总数
private final int V;
//边的总数
private int E;
//邻接表
private Queue<Edge>[] adj;
//创建一个含有V个顶点的空加权无向图
public EdgeWeightedGraph(int V){
//初始化顶点数量
this.V = V;
//初始化边的数量
this.E = 0;
//初始化邻接表
this.adj = new Queue[V];
for (int i = 0; i < adj.length; i++) {
adj[i] = new Queue<>();
}
}
//获取图中顶点的数量
public int V(){
return V;
}
//获取图中边的数量
public int E(){
return E;
}
//向加权无向图中添加一条边e
public void addEdge(Edge e){
//需要让边e同时出现在e这个边的两个顶点的邻接表中
int v = e.either();
int w = e.other(v);
adj[v].enqueue(e);
adj[w].enqueue(e);
//边的数量+1
E++;
}
//获取和顶点v关联的所有边
public Queue<Edge> adj(int v){
return adj[v];
}
//获取加权无向图的所有边
public Queue<Edge> edges(){
//创建一个队列对象,存储所有的边
Queue<Edge> allEdges = new Queue<>();
//遍历图中的每一个顶点,找到该顶点的邻接表,邻接表中存储了该顶点关联的每一条边
//因为这是无向图,所以同一条边同时出现在它关联的两个顶点的邻接表中,需要让一条边只记录一次
for (int v = 0; v < V; v++) {
//遍历v顶点的邻接表,找到每一条和v关联的边
for (Edge e : adj[v]) {
if (e.other(v) < v){
allEdges.enqueue(e);
}
}
}
return allEdges;
}
}
七、最小生成树-贪心算法思想。
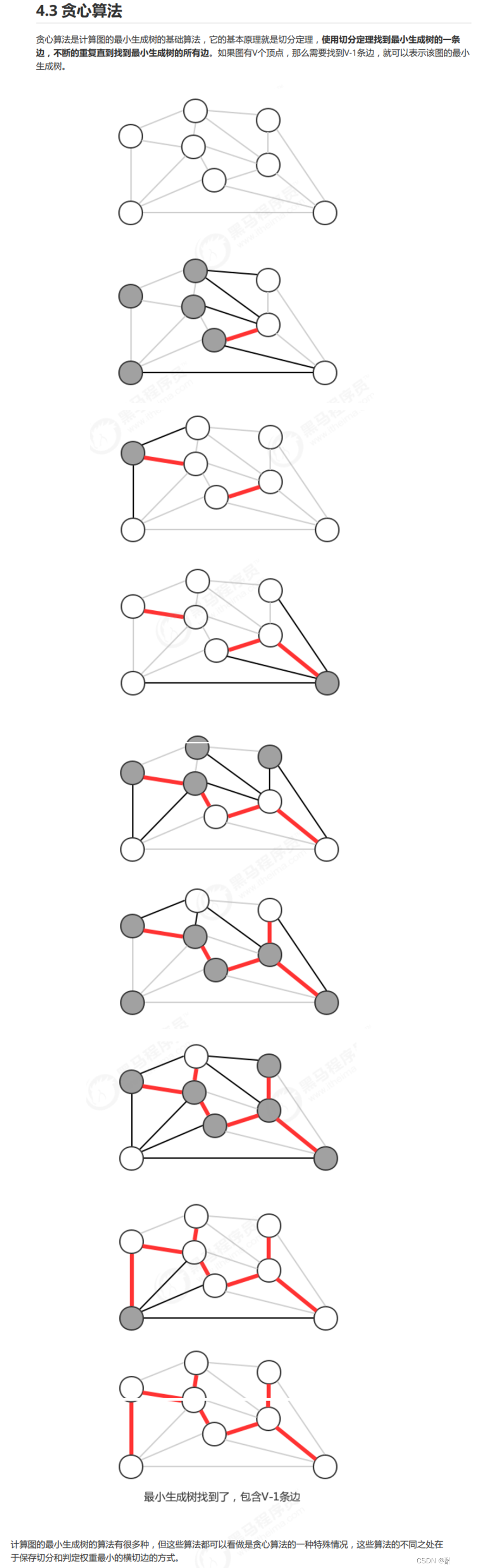
最小生成树:指的是一种图论中的问题,即在给定的带权无向图中找到一棵生成树,使得所有树边的边权之和最小。因此,最小生成树是一种算法,用于解决带权无向图的最优化问题。其中,常见的最小生成树算法有Prim算法和Kruskal算法。
最小生成树:是一种特殊的无向图,其中包含 n 个顶点和 n-1 条边,保证这些边连接所有顶点,并且没有环,即是一棵树。因此,最小生成树可以看作是一种二叉树,每个非叶节点有两个子节点。
需要注意的是,最小生成树本身不是二叉树或者其他几叉树,而是在一张完全图中取出某些边,使得剩余的边构成最小生成树。在最小生成树的构建过程中,可能会出现度数大于2的节点,因此最小生成树并不是一个具有固定度数的树。
因此,对于最小生成树来说,并不能明确的说它是几叉树。

(1)贪心算法。
1、贪心算法是一种在每一步都选择当前最优解的策略,以期望获得全局最优解的算法思想。以下是一些常见的贪心算法:
贪心选择活动:贪心选择活动问题是指有n个活动(每个活动定义为一个开始时间和结束时间),如何安排这些活动,才能保证参加活动的数量最大。
最小生成树:求解一个带权无向图的最小生成树。
最短路问题:在一个有向图或无向图中,从源节点到目标节点之间查找路径的问题。
部分背包问题:在权值和物品容量分别为w和v的n个物品中选择若干个放入容量为C的背包,目标是让背包中物品的总权值最大。
哈夫曼编码:一种针对字符出现频率的编码方式,将出现频率较高的字符用较少的位数进行编码,从而达到通过编码和解码的过程压缩数据的目的。
2、是的,贪心算法只是一种算法思想,没有具体的通用实现方法。实际上,对于不同的问题,我们需要根据问题本身的特点和要求,设计具体的贪心算法。
通常情况下,设计贪心算法需要以下几个步骤:
确定问题的优化目标以及具体的限制条件。
将问题划分为多个子问题,并考虑如何利用最优子结构性质实现贪心选择。
通过贪心选择策略确定每个子问题的最优解。
将每个子问题的最优解合并为原问题的最优解。
在实际应用中,设计贪心算法需要有一定的算法分析和设计能力。对于一些经典问题,比如背包问题、最小生成树问题等,已经有了一些基于贪心思想的经典算法,可以供参考。同时,也可以结合其他算法思想,比如动态规划、分治算法、回溯算法等,对贪心算法进行优化和改进。
3、是的,Kruskal算法和Prim算法都属于贪心算法。
Kruskal算法用于构建一个加权无向图的最小生成树,其基本思想是在所有边中选择权值最小且不形成环的边,直至构建出一棵生成树。在每一步中,Kruskal算法都会选择权值最小的边,并利用并查集来判断是否形成环。由于Kruskal算法每次选取的都是满足最优子结构的边,所以它也是一种贪心算法。
Prim算法用于构建一个加权无向连通图的最小生成树,其基本思想是从一个顶点开始,逐步将其与权值最小的邻接顶点加入生成树中,直至所有顶点都被包含在生成树中。在每一步中,Prim算法都会选择当前与生成树相连的权值最小的边,以构建最小生成树。由于Prim算法每次选取的也是满足最优子结构的边,所以它也是一种贪心算法。
(2)Prim算法。

package 图的入门.无向图.加权无向图_prim算法;
import 优先队列.IndexMinPrioirityQueue;
import 图的入门.无向图.加权无向图.Edge;
import 图的入门.无向图.加权无向图.EdgeWeightedGraph;
import 线性表.线性表_队列.Queue;
public class primMST {
//索引代表顶点,值表示当前顶点和最小生成树之间的最短边(最小生成树的所有边)
private Edge[] edgeTo;
//索引代表顶点,值表示当前顶点和最小生成树之间的最短边的权重(与最小生成树之间的最小权重)
// (比如a就是当前顶点,而a顶点与最小生成树的权重为5,当最小生成树加入某个顶点,该顶点与a顶点的权重是1(a顶点还没进入最小生成树的时候),就需要改变了)
//而这个数组的作用就是比较当前顶点与最小生成树之间的权重是否小于原本当前顶点与最小生成树之间的权重,
// 如果小于,则修改,然后把pq最小索引优先队列里面的权重改掉(在pq中),把该顶点加入pq中(不在pq中),和更新这里的数组中数据,
private double[] distTo;
//索引代表顶点,如果当前顶点已经在树中,则值为true,否则为false
private boolean[] marked;
//存放在数中顶点与非树中顶点之间的有效横切边
private 优先队列.IndexMinPrioirityQueue<Double> pq;
//根据一副加权无向图,创建最小生成树计算对象
public primMST(EdgeWeightedGraph G){
//初始化edgeTo
this.edgeTo = new Edge[G.V()];
//初始化distTo
this.distTo = new double[G.V()];
for (int i = 0; i < distTo.length; i++) {
distTo[i] = Double.POSITIVE_INFINITY;
}
//初始化marked
this.marked = new boolean[G.V()];
//初始化pq
this.pq = new IndexMinPrioirityQueue<>(G.V());
//默认让顶点0进入到树中,但是树中只有一个顶点0,因此0顶点默认没有和其他的顶点相连,所以让distTo对应位置的值存储0.0
distTo[0] = 0.0;
pq.insert(0,0.0);
//遍历索引最小优先队列,拿到最小横切边对应的顶点,把该顶点加入到最小生成树中
while (!pq.isEmpty()){
visit(G,pq.delMin());//pq.delMin()方法返回的是第几个顶点,而不是里面的元素(相当于是这里的顶点i,而不是加入的item权重)
}
}
//将顶点v添加到最小生成树中,并且更新数据
private void visit(EdgeWeightedGraph G,int v){
//把顶点v添加到最小生成树中
this.marked[v] = true;
//更新数据
for (Edge e : G.adj(v)) {
//获取e边的另外一个顶点(当前顶点是v)
int w = e.other(v);
//判断另外一个顶点是不是已经在树中,如果在树中,则不做任何处理,如果不在树中,更新数据
if (marked[w]){
continue;
}
//判断边e的权重是否小于从w顶点到树中已经存在的最小边的权重(初始化值为double类型的最大值)
if (e.weight() < distTo[w]){
//更新数据
edgeTo[w] = e;//w顶点与最小生成树的最小边是e边(因为一个顶点和最小生成树之间可能不止一条边)
//修改该顶点与最小生成树之间的距离,因为最小距离发生了改变 或 还没设置真正的最小权重
distTo[w] = e.weight();
//如果最小索引队列中已经存在,则修改发生改变的权重值(可能改变,看当前顶点与树的最小权重是否发生改变)
if (pq.contains(w)){
pq.changeItem(w,e.weight());
}else {
pq.insert(w,e.weight());
}
}
}
}
//获取最小生成树的所有边
public Queue<Edge> edges(){
//创建队列对象
Queue<Edge> allEdges = new Queue<>();
//遍历edgeTo数组,拿到每一条边,如果不为null,则添加到队列中
for (int i = 0; i < edgeTo.length; i++) {
if (edgeTo[i] != null){
allEdges.enqueue(edgeTo[i]);
}
}
return allEdges;
}
}
代码测试:
package 图的入门.无向图.加权无向图_prim算法;
import 图的入门.无向图.加权无向图.Edge;
import 图的入门.无向图.加权无向图.EdgeWeightedGraph;
import 线性表.线性表_队列.Queue;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
public class primMSTTest {
public static void main(String[] args) throws IOException {
//1准备一副加权无向图
/**
* 如果刚把min_create_tree_test.txt文件复制进来,那么要把
*/
BufferedReader br = new BufferedReader(new InputStreamReader(primMST.class.getClassLoader().getResourceAsStream("min_create_tree_test.txt")));
//1.1读取顶点的数量
int total = Integer.parseInt(br.readLine());
//1.2创建图
EdgeWeightedGraph G = new EdgeWeightedGraph(total);
//1.3读取边的数量
int edgeNumbers = Integer.parseInt(br.readLine());
//1.4添加边
for (int i = 0; i < edgeNumbers; i++) {
String line = br.readLine();
String[] strs = line.split(" ");
int v = Integer.parseInt(strs[0]);
int w = Integer.parseInt(strs[1]);
double weight = Double.parseDouble(strs[2]);
//构建加权无向边
Edge edge = new Edge(v, w, weight);
G.addEdge(edge);
}
//2.创建primMST对象,计算加权无向图中的最小生成树
primMST primMST = new primMST(G);
//3.获取最小生成树中的所有边
Queue<Edge> edges = primMST.edges();
//4.遍历打印所有的边
for (Edge e : edges) {
int v = e.either();
int w = e.other(v);
double weight = e.weight();
System.out.println(v+"-"+w+" :: "+weight);
}
}
}
(3)Kruskal算法。

package 图的入门.无向图.加权无向图_kruskal算法;
import 优先队列.MinPriorityQueue;
import 图的入门.无向图.加权无向图.Edge;
import 图的入门.无向图.加权无向图.EdgeWeightedGraph;
import 并查集.UF_Tree_Weighted;
import 线性表.线性表_队列.Queue;
public class KruskalMST {
//保存最小生成树的所有边
private Queue<Edge> mst;
//索引代表顶点,使用uf.connect(v,w)可以判断顶点v和顶点w是否在同一颗树中,使用uf.union(v,w)可以把顶点v所在的树和顶点w所在的树合并
private UF_Tree_Weighted uf;
//存储图中所有的边,使用最小优先队列,对边按照权重进行排序
private 优先队列.MinPriorityQueue<Edge> pq;
//根据一副加权无向图,创建最小生成树计算对象
public KruskalMST(EdgeWeightedGraph G){
//初始化mst
this.mst = new Queue<>();
//初始化uf
this.uf = new UF_Tree_Weighted(G.V());
//初始化pq
this.pq = new MinPriorityQueue<>(G.E());
//把图中所有的边存储到pq中
for (Edge e : G.edges()) {
pq.insert(e);
}
//遍历pq队列,拿到最小权重的边,进行处理
while (!pq.isEmpty() && mst.size() < G.V() - 1){
//找到权重最小的边
Edge e = pq.delMin();
//找到该边的两个顶点
int v = e.either();
int w = e.other(v);
//判断这两个顶点是否已经在同一颗树中,如果在同一颗树中,则不对该边做处理,如果不在一颗树中,则让这两个顶点属于两棵树合并成一棵树
if (uf.connected(v,w)){//uf.connected(v,w)是查看两个顶点的父顶点是否相同,相同则在同一颗树中
continue;
}
//只要这两个元素有一个不在树中(也可以说不在同一颗树中),那么它就不可能形成环
uf.union(v,w);
//让边e进入到mst队列中
mst.enqueue(e);
}
}
//获取最小生成树的所有边
public Queue<Edge> edges(){
return mst;
}
}
测试代码:
package 图的入门.无向图.加权无向图_kruskal算法;
import 图的入门.无向图.加权无向图.Edge;
import 图的入门.无向图.加权无向图.EdgeWeightedGraph;
import 图的入门.无向图.加权无向图_prim算法.primMST;
import 线性表.线性表_队列.Queue;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class KruskalMSTTest {
public static void main(String[] args) throws IOException {
//1准备一副加权无向图
/**
* 如果刚把min_create_tree_test.txt文件复制进来,那么要把
*/
BufferedReader br = new BufferedReader(new InputStreamReader(primMST.class.getClassLoader().getResourceAsStream("min_create_tree_test.txt")));
//1.1读取顶点的数量
int total = Integer.parseInt(br.readLine());
//1.2创建图
EdgeWeightedGraph G = new EdgeWeightedGraph(total);
//1.3读取边的数量
int edgeNumbers = Integer.parseInt(br.readLine());
//1.4添加边
for (int i = 0; i < edgeNumbers; i++) {
String line = br.readLine();
String[] strs = line.split(" ");
int v = Integer.parseInt(strs[0]);
int w = Integer.parseInt(strs[1]);
double weight = Double.parseDouble(strs[2]);
//构建加权无向边
Edge edge = new Edge(v, w, weight);
G.addEdge(edge);
}
//2.创建primMST对象,计算加权无向图中的最小生成树
KruskalMST MST = new KruskalMST(G);
//3.获取最小生成树中的所有边
Queue<Edge> edges = MST.edges();
//4.遍历打印所有的边
for (Edge e : edges) {
int v = e.either();
int w = e.other(v);
double weight = e.weight();
System.out.println(v+"-"+w+" :: "+weight);
}
}
}














 817
817











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









