







算法分析:
先穷举长度L,然后求长度为L的子串最多能连续出现几次。首先连续出现1次是肯定可以的,所以这里只考虑至少2次的情况。假设在原字符串中连续出现2次,记这个子字符串为S,那么S肯定包括了字符r[0],r[L],r[L*2],r[L*3],……中的某相邻的两个。所以只须看字符r[L*i]和r[L*(i+1)]往前和往后各能匹配到多远,记这个总长度为K,那么这里连续出现了K/L+1次。最后看最大值是多少。如图7所示。
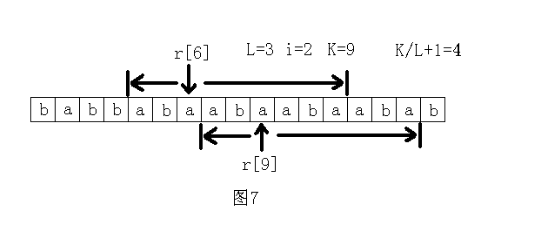
穷举长度L的时间是n,每次计算的时间是n/L。所以整个做法的时间复杂度是O(n/1+n/2+n/3+……+n/n)=O(nlogn)。
以上就是IOI09集训队中罗神的论文中的算法分析
这个题我做了好几遍。。。 找了许多博客。
恍然醒悟。
其实,当枚举到合适的子串长度时,我们在枚举r[len*i]和r[len*(i+1)]的过程中,必然可以出现r[len*i]在第一个循环节里,而r[len*(i+1)]在第二个循环节里的这种情况,如果此时r[len*i]是第一个循环节的首字符,这样直接用公共前缀k除以i并向下取整就可以得到最后结果。但如果r[len*i]如果不是首字符,这样算完之后结果就有可能偏小,因为r[len*i]前面可能还有少许字符也能看作是第一个循环节里的。
从r[i*len] 开始, 除了匹配了 k/len + 1个循环节 , 还可能剩余了几个字符,(k%len个)。
如果r[i*len]前还有len – k%len个字符可以完成匹配 这样就可以再多一个循环节。
所以我们只要检查一下从r[ i*len - ( len – k%len) ] 和r[i*len – (len – k%len) + len] 开始是否有len-k%len个字符能够完成匹配即可,
也就是说去检查这两个后缀的最长公共前缀是否比len-k%len大即可。后边多了k%len个字符, 所以前边应该也要多 len - k%len 个字符才对。
所以才要去检查上边所说的两个后缀的最长公共前缀是否比len-k%len大。
CODE:
#include <iostream>
#include <cstdio>
#include <cstring>
#include <algorithm>
#include <cmath>
#include <vector>
#define inf 0x3f3f3f3f
#define ms(x) memset(x, 0, sizeof(x))
#define ll long long
using namespace std;
const int N = 200100;
int t1[N], t2[N], c[N];
int str[N], sa[N];
int ran[N], height[N];
bool cmp(int *r, int a, int b, int l)
{
return r[a] == r[b] && r[a+l] == r[b+l];
}
void da(int str[], int n, int m)
{
int i, j, p, *x = t1, *y = t2;
for(i=0; i<m; i++) c[i] = 0;
for(i=0; i<n; i++) c[x[i] = str[i]]++;
for(i=1; i<m; i++) c[i]+=c[i-1];
for(i=n-1; i>=0; i--) sa[--c[x[i]]] = i;
for(j=1; j<=n; j<<=1)
{
p = 0;
for(i = n-j; i<n; i++) y[p++] = i;
for(i = 0; i<n; i++) if(sa[i]>=j) y[p++] = sa[i] - j;
for(i = 0; i<m; i++) c[i] = 0;
for(i = 0; i<n; i++) c[x[y[i]]]++;
for(i = 1; i<m; i++) c[i]+=c[i-1];
for(i=n-1; i>=0; i--) sa[--c[x[y[i]]]] = y[i];
swap(x, y);
p = 1;
x[sa[0]] = 0;
for(i = 1; i<n; i++)
x[sa[i]] = cmp(y, sa[i-1], sa[i], j) ? p-1:p++;
if(p>=n) break;
m = p;
}
int k = 0;
n--;
for(i=0; i<=n; i++) ran[sa[i]] = i;
for(i=0; i<n; i++)
{
if(k) k--;
j = sa[ran[i]-1];
while(str[i+k] == str[j+k]) k++;
height[ran[i]] = k;
}
}
int best[20][N];
int RMQ[N], mm[N];
void initRMQ(int n)
{
mm[0] = -1;
for(int i=1; i<=n; i++)
mm[i] = ((i&(i-1)) == 0)?mm[i-1]+1:mm[i-1];
for(int i=1; i<=n; i++) best[0][i] = i;
for(int i=1; i<=mm[n]; i++)
for(int j=1; j+(1<<i)-1<=n; j++)
{
int a = best[i-1][j];
int b = best[i-1][j+(1<<(i-1))];
if(height[a] < height[b]) best[i][j] = a;
else best[i][j] = b;
}
}
int askRMQ(int a, int b)
{
int t;
t = mm[b-a+1];
b-=(1<<t)-1;
a = best[t][a];
b=best[t][b];
return height[a] < height[b]?a:b;
}
int lcp(int a, int b)
{
a = ran[a], b = ran[b];
if(a>b) swap(a, b);
return height[askRMQ(a+1, b)];
}
int main()
{
int T;
scanf("%d", &T);
while(T--)
{
int n;
scanf("%d", &n);
for(int i=0;i<n;i++)
{
char tmp[2];
scanf("%s", tmp);
str[i] = tmp[0];
}
str[n] = 0;
da(str, n+1, 130);
initRMQ(n);
int ans = 0;
for(int len = 1;len<n;len++)
{
for(int i=0; i+len<n;i+=len)
{
int st = lcp(i, i+len);
int now = st/len+1;
int ti = i - (len-st%len);
if(ti>=0 && lcp(ti, ti+len)/len > len - st%len) now++;
ans = max(ans , now);
}
}
cout<<ans<<endl;
}
return 0;
}















 357
357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









