






前言
本文主要讲神经网络的下半部分。
其实就是结合之前学习的全部内容,进行一次神经网络的训练。
神经网络
下面是使用MNIST数据集进行的手写数字识别的神经网络训练和使用。
MNIST 数据集,是一个常用的手写数字识别数据集。MNIST 数据集包含 60,000 张 28x28 像素的灰度训练图像和 10,000 张测试图像,每张图像都表示一个手写的数字(0-9)。
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
# device config
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# hyper parameters
input_size = 784 # 28x28
hidden_size = 100
num_classes = 10 #有 10 个类别的数字(从 0 到 9),所以输出层需要有 10 个神经元,分别对应这 10 个类别
batch_size = 100
learning_rate = 0.001
# MNIST
# torchvision.datasets.MNIST: 这是一个用于加载MNIST数据集的类。 MNIST 数据集,它包含灰度的手写数字图像。每张图像的尺寸是 28x28 像素,灰度图像只有一个通道(channels=1)
# root='./data': root 参数指定了数据集的存储位置 './data' 表示一个相对路径,表示数据集将存储在当前工作目录下的 data 文件夹中。如果这个文件夹不存在,PyTorch 会自动创建它。
# train=True: 表示加载的是训练集数据。
# transform=transforms.ToTensor(): 将图像转换为PyTorch张量,并归一化为[0, 1]的范围。
# download=True: 如果指定的 root 路径下没有找到数据集,会自动从互联网下载MNIST数据集。
train_dataset = torchvision.datasets.MNIST(
root='./data', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = torchvision.datasets.MNIST(
root='./data', train=False, transform=transforms.ToTensor())
# torchvision.datasets.MNIST 是内置的数据集,所以不用去像之前内容中,要搞一个csv文件
# 这里直接把MNIST导入进DataLoader
# batch_size 指定了一次输入模型的数据量。指定batch_size为100,那就是一批次读取100个,利用数据集的索引就可以读取,因为下面还有个参数shuffle=True,所以读取的时候,数据是被打乱的。
train_loader = torch.utils. data.DataLoader(
dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
dataset=test_dataset, batch_size=batch_size, shuffle=False)
print('每份100个,被分成多了份',len(train_loader))
examples = iter(train_loader) # 转换为迭代器,这样可以调用next,一行一行的取数据,只不过他这一行,是一组数据
samples, labels = examples.__next__() # 这里取出 x和y
print(samples.shape, labels.shape) # samples即x,是一个批次,即100个图像
# 这里输出的是torch.Size([100, 1, 28, 28]) torch.Size([100])
# 其中x是的数据维度是下面这样的。
# 第一个维度 (64): 表示批次中包含的样本数量,即 batch_size。在这个例子中,一次输入模型的有 100 张图像。
# 第二个维度 (1): 表示图像的通道数。对于灰度图像,通道数是 1,彩色图像则通常有 3 个通道(对应 RGB)。
# 第三个维度 (28): 表示图像的高度。MNIST 图像的高度为 28 像素。
# 第四个维度 (28): 表示图像的宽度。MNIST 图像的宽度也是 28 像素。
# y只有一个维度,就是100张图像
# x里都数据都是手写的数字,这里可以用图像把他们展示出来看一看
for i in range(6):
plt.subplot(2, 3, i+1) # 在图像窗口中创建一个 2 行 3 列的子图布局,并选择第 i+1 个子图位置。
plt.imshow(samples[i][0], cmap='gray')
# plt.show()
class NeuralNet(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(NeuralNet, self).__init__()
self.linear1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.linear2 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
out = self.linear1(x)
out = self.relu(out)
out = self.linear2(out)
# no softmax at the end
return out
model = NeuralNet(input_size=input_size,
hidden_size=hidden_size, num_classes=num_classes)
criterion = nn.CrossEntropyLoss() # (applies Softmax) 这里会调用激活函数,所以上面不调用激活函数了
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# training loop
n_total_steps = len(train_loader)
num_epochs = 2
#下面这个循环就走2次,意思是在训练完集合里的全部数据后,在重新来一遍
for epoch in range(num_epochs): #for——range模式=其他语言的for
#下面这个循环是训练集合里的全部数据
for i, (images, labels) in enumerate(train_loader): #for——enumerate模式=其他语言的foreach
# 这里的images是100个图像,也就是一个批次
# 将100,1,28,28 这个四维数组 转换成2维数组,转换结果应该是 100,784
# to(device) 是指将数据转移到这个设备上计算,如果有GPU,这个计算会被加速
images = images.reshape(-1, 28*28).to(device)
labels = labels.to(device)
# forward
outputs = model(images)
loss = criterion(outputs, labels)
# backwards
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print(
f'epoch {epoch+1} / {num_epochs}, step {i+1}/{n_total_steps}, loss = {loss.item}')
# test
with torch.no_grad():
n_correct = 0
n_samples = 0
for images, labels in test_loader:
images = images.reshape(-1, 28*28).to(device) #转二维数组
labels = labels.to(device)
outputs = model(images) # 通过我们训练的模型,我们得到了y_predicted
# value,index
_, predictions = torch.max(outputs, 1) #torch.max(outputs, 1) 会在 outputs 的每一行(对应每个样本)中找到最大值及其索引。由于模型输出的是每个类别的概率分布,所以最大值的索引代表模型对该图像的预测类别。
n_samples += labels.shape[0] #labels.shape[0]会返回y的行数,就是100,因为一个批次100个图像
print("y行数",labels.shape[0])
#predictions == labels 会生成一个布尔张量(True 表示预测正确,False 表示预测错误)
#sum() 计算正确预测的数量并加到 n_correct 上
n_correct += (predictions == labels).sum().item()
acc = 100.0*n_correct/n_samples #计算正确率
print(f'accuracy ={acc}')这里我们要有个概念转换,我们输出的Y_predicted不再是1列,而是十列了。
我们要根据十列中输出的最大的索引判断他是哪个类型的数字。
图形
现在我们学会了使用神经网络开发,我们在来看一些图形,就能看懂了。
比如这个M-P神经元模型。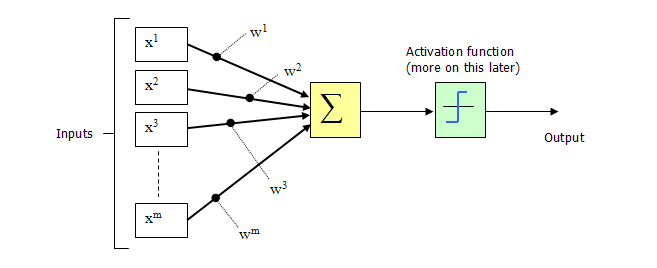
在比如这个神经网络结构图。
下面粉色是输入层,绿色是隐藏层,蓝色是输出层。虽然下面画的隐藏层节点比输入层多,但实际情况并不一定,这只是个示意图,比如我们上面,输入的x是784列,隐藏层计算后,就剩100列。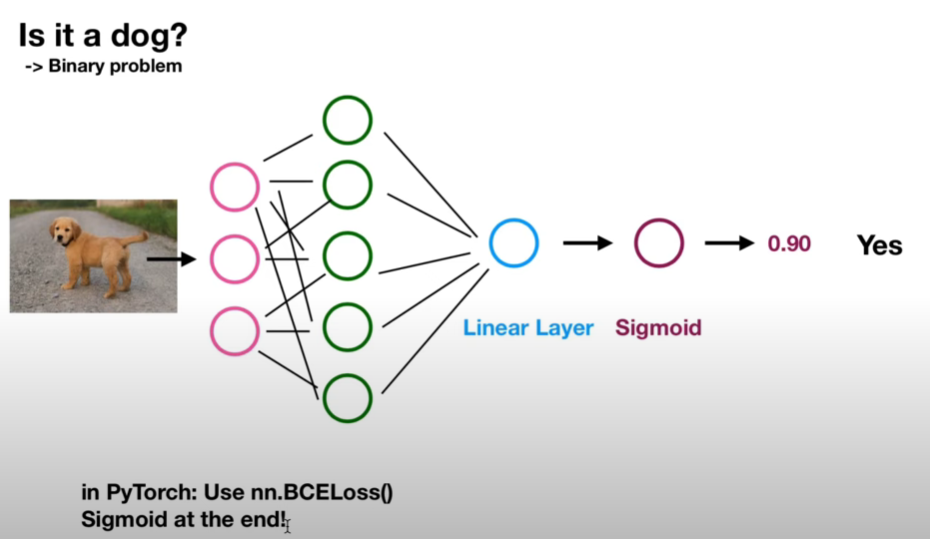
结语
本质上我并不是python程序员,其实看我的注释就应该能感觉到吧,比如我对python的for循环都会加注释。
我之所以写这个系列,就是因为我不是python开发,这个系列是为了当我间隔超长时间重新使用python时,唤起死去的记忆用的。
不过,我感觉我写的顺序还不错,如果大家反复的仔细的阅读,应该也能掌握神经网络开发。
而且,正因为我不是python开发,反正更好的证明了,python的学习和人工智能的学习,并没有想象中那么难,相信大家只有认真研究,一定都能学会。
传送门:零基础学习人工智能—Python—Pytorch学习(一)零基础学习人工智能—Python—Pytorch学习(二)零基础学习人工智能—Python—Pytorch学习(三)零基础学习人工智能—Python—Pytorch学习(四)零基础学习人工智能—Python—Pytorch学习(五)零基础学习人工智能—Python—Pytorch学习(六)零基础学习人工智能—Python—Pytorch学习(七)
注:此文章为原创,任何形式的转载都请联系作者获得授权并注明出处!

若您觉得这篇文章还不错,请点击下方的【推荐】,非常感谢!

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











