







背景
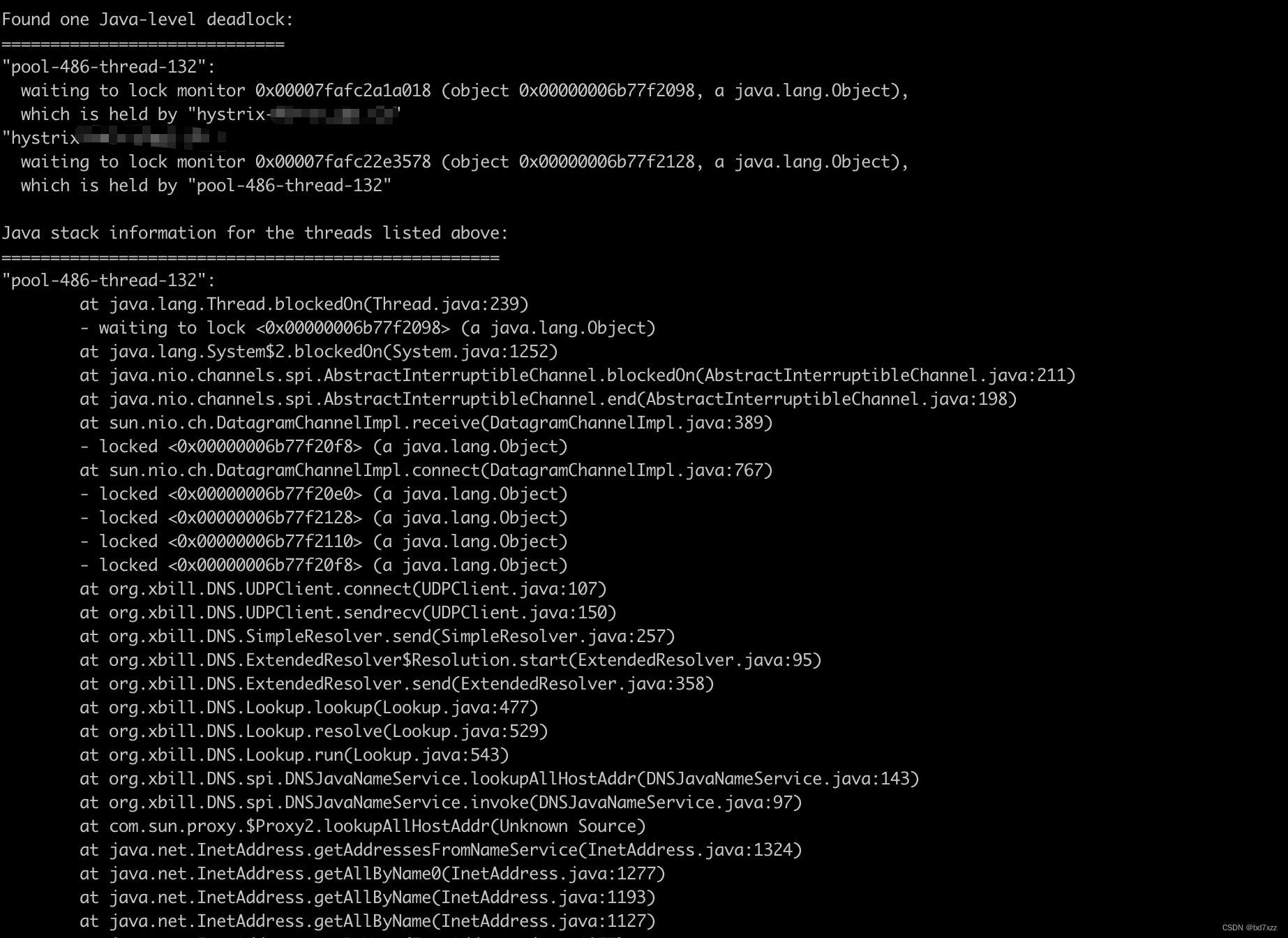
线上业务在热点流量大的情况下(业务采用Java编程语言实现),单机偶发出现Hystrix熔断,接口无法提供服务。如下图所示:

Hystrix circuit short-circuited and is OPEN 代表Hystrix在一个窗口时间内失败了N次,发生短路。短路时间默认为 5 秒,5秒之内拒绝所有的请求,之后开始运行。

统计了一下1个小时内居然有5w多条。
最初怀疑依赖下游的某个rpc接口出现问题,但从监控来看,异常时间点多个rpc接口异常率都有所上升。所以考虑是自身单机存在什么问题,导致调用依赖的rpc接口失败,产生了大量的熔断。
这里还有很重要的一点:在单机出现问题第一时间,摘掉了流量,过半小时后恢复流量,依旧熔断无法恢复
- 若摘掉流量后,静置一段时间放开流量,服务恢复,证明可能是由于流量过载导致的问题,如:JVM内存不够,gc回收不过来,频繁gc。这样的话流量掐掉后,gc一段时间后内存够用,服务恢复正常。
- 若摘掉流量后,静置一段时间放开流量,服务依旧熔断,在单机出现问题的场景下,很可能是JVM内部的问题(包括应用自身问题或者JVM的一些问题,如:死锁)
排查
通常排查这种自身问题可从几个方面入手:
- CPU load、使用率、内存使用率是否过高
- 网卡出入速率是否有抖动,包括TCP重传
- 磁盘IOPS是否过高,导致一些sys call阻塞
- JVM是否出现stw动作,包括不限于:gc、JIT等
- 是否有oom、stack overflow、死锁等现象
- 代码出现bug
- 虚拟化对应用进行stw动作
根据这些逐一分析:
-
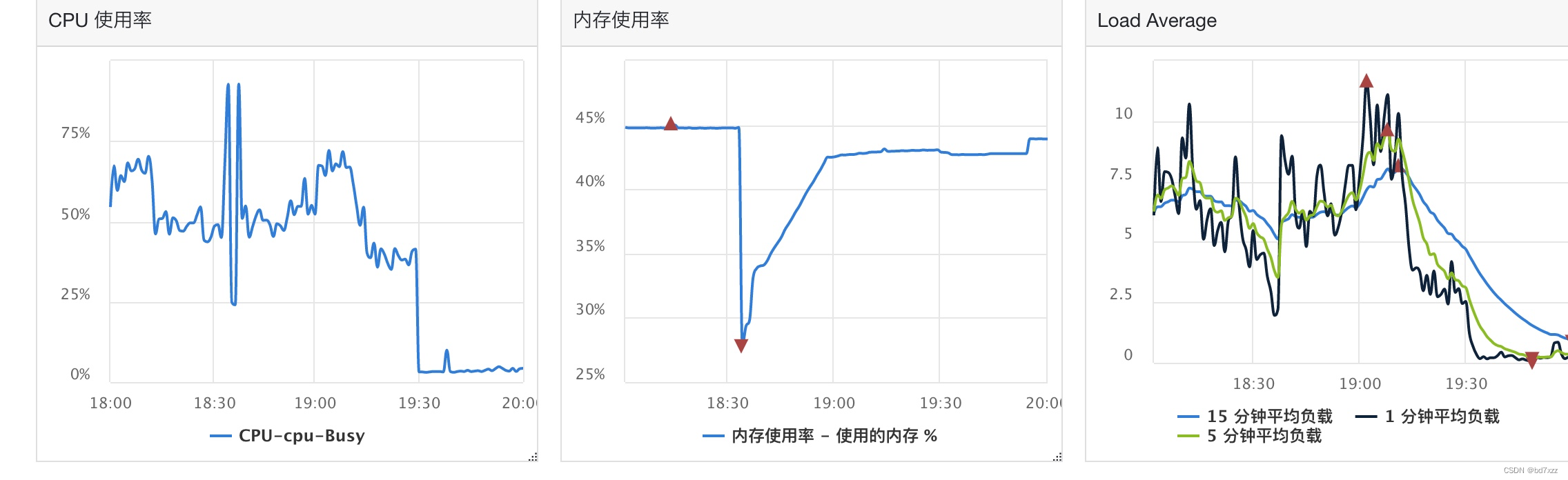
监控CPU和内存如下图所示:CPU有明显的抖动,内存使用率正常(18:30断崖式下滑是对服务进行了上线,可忽略不管),注意问题发生在19:00以后,可以看到CPU在出问题时间段内有明显的波动。
-
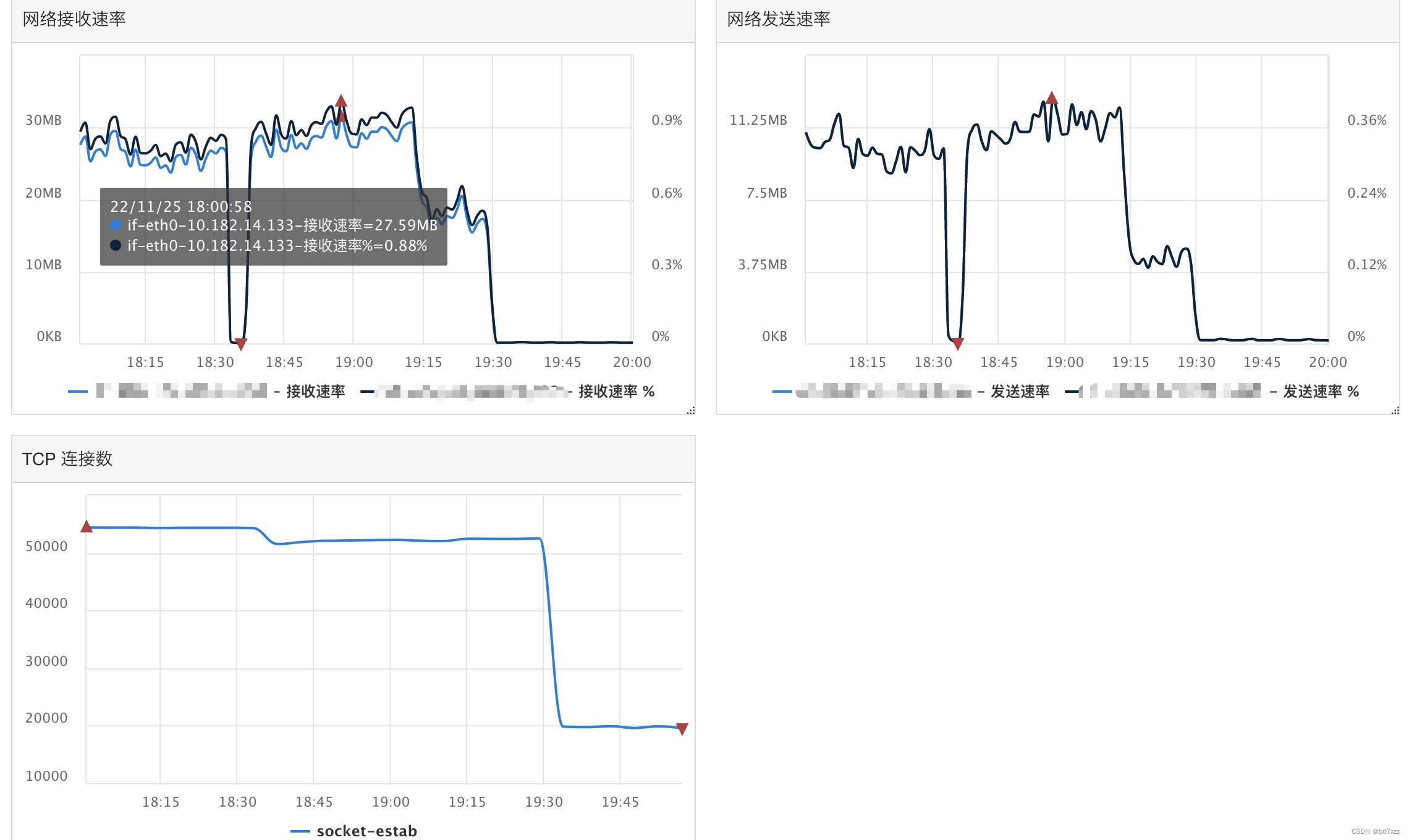
查看监控网卡如下图所示:在19:00之后出问题的时间段网卡出入速率略有波动,可忽略。
-
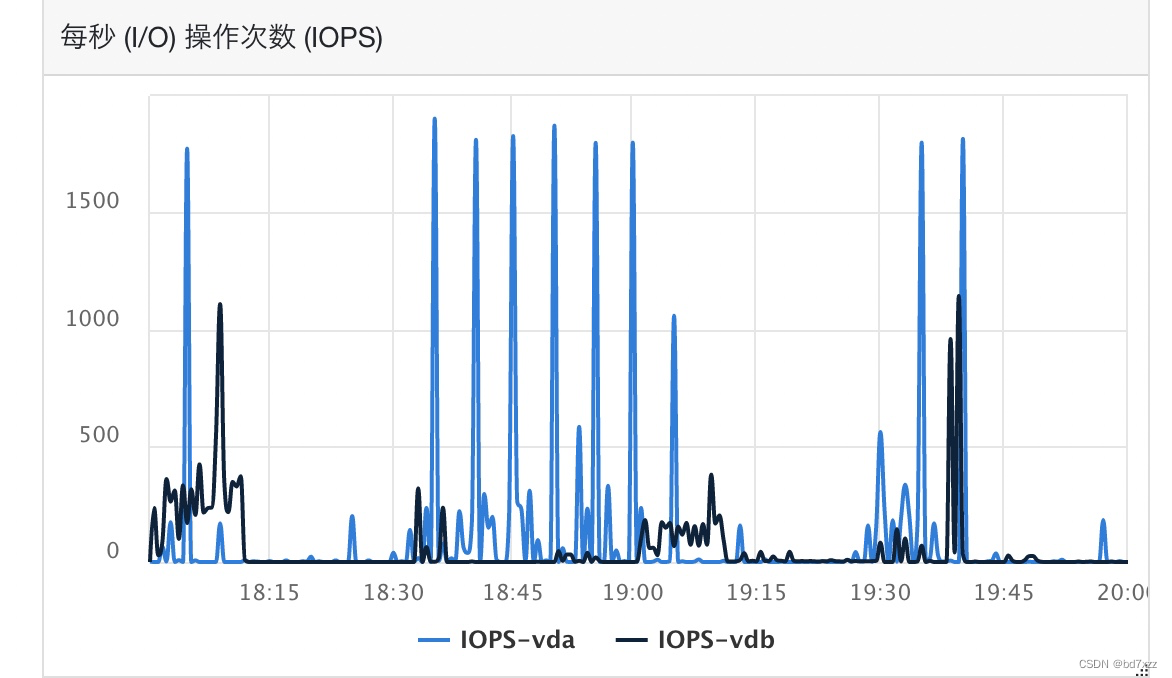
查看磁盘IOS如下图所示:磁盘IOPS虽然比较高,但19:00前后都比较平均。
-
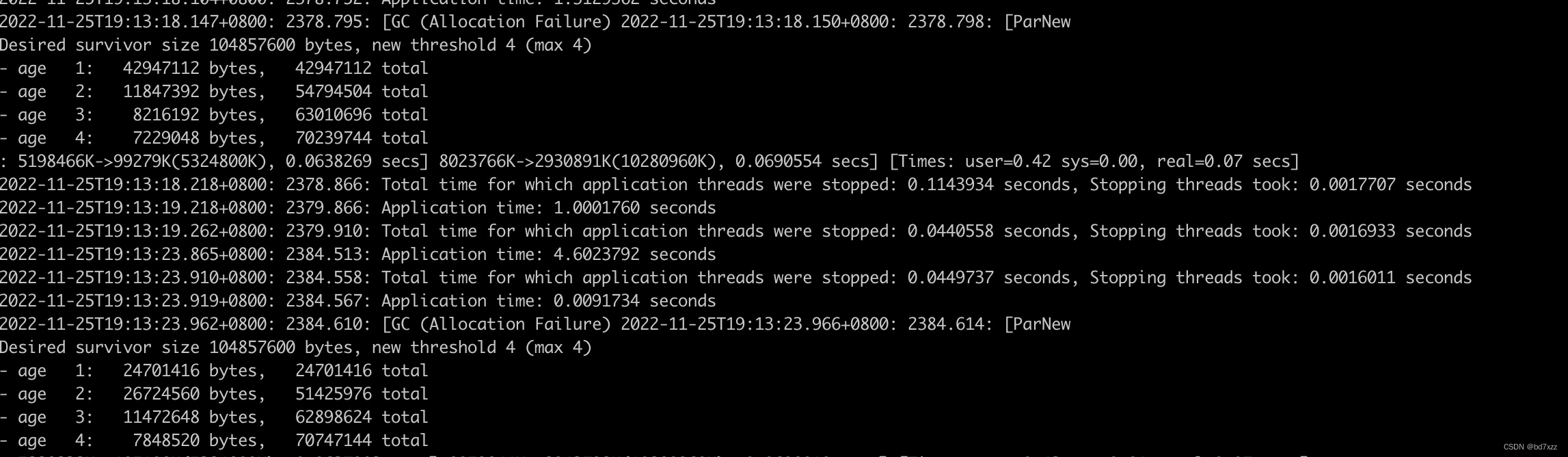
查看gclog如下图所示:虽然young gc比较频繁,但回收的比例还是比较大,耗时也不高。没有明显的其他原因导致stw占用时间长的迹象。
-
打印线程栈如下图所示:jstack打出的线程栈就很明显了,最下面直接显示了死锁!
-
review了最近上线的代码,改动很小没有问题。
-
由于打印线程栈出现死锁,问题很明显,不用排查虚拟化了。
问题很明显了,JVM出现了死锁,导致Hystirx熔断。
从死锁的日志来看,似乎跟DNS相关。难道Java的DNS有啥Bug?
分析
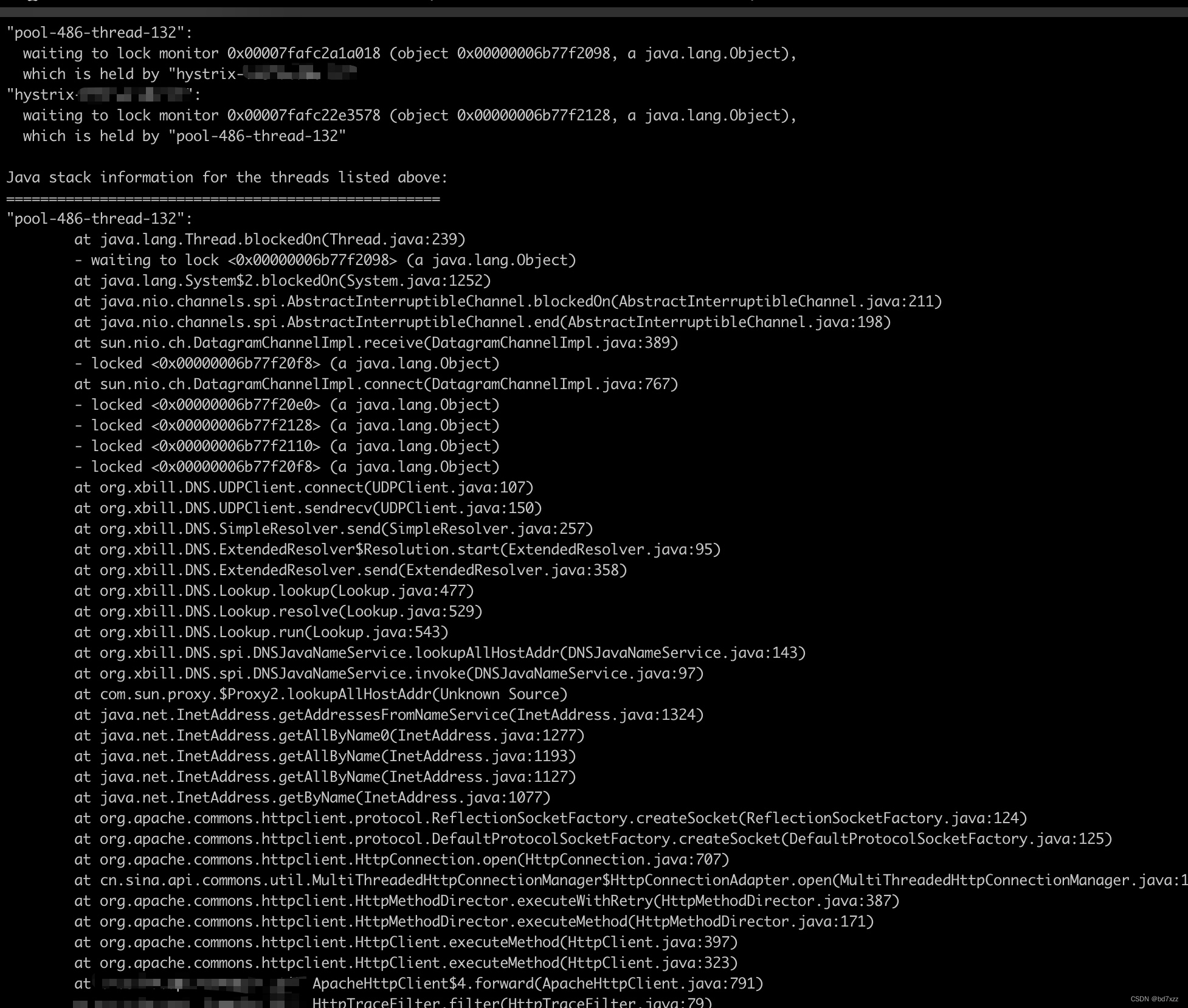
在死锁线程栈中很明显地标记出了 pool-486-thread-132 在等 0x00000006b77f2098 这把锁,
并且这把锁被 hstirx-*** 线程持有着,同时 hstirx-*** 在等待 0x00000006b77f2128 这把锁,并且这把锁被 pool-486-thread-132 线程持有着。
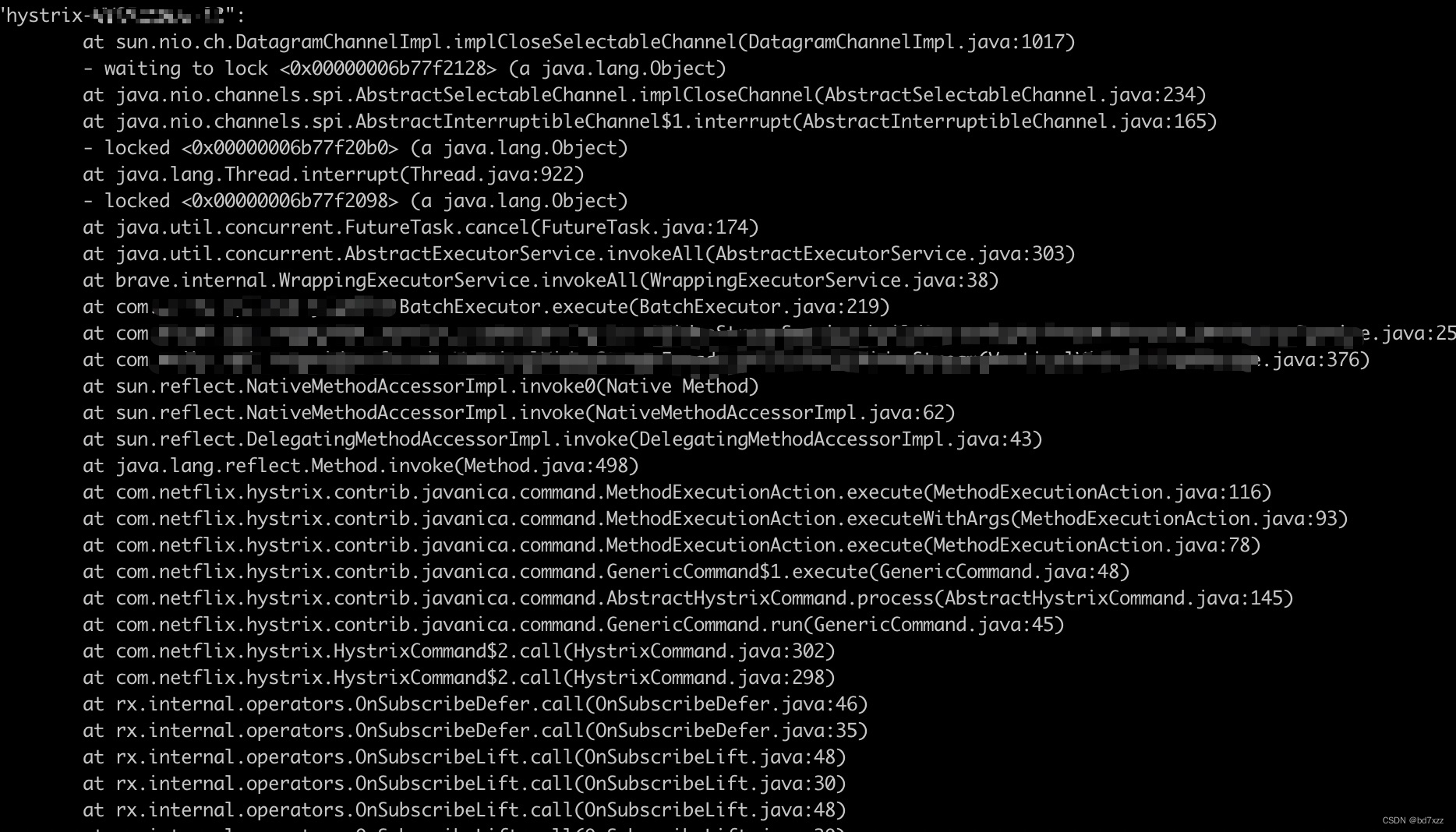
这俩个线程栈中同时出现了DNS和DatagramChannel相关的类,证明死锁很大一部分原因是由DNS在发UDP包的情况下产生了死锁。我们知道死锁是俩个线程对相同临界区资源竞争时,加锁不当产生的。复习下死锁的四个必要条件:
- 互斥条件:进程要求对所分配的资源进行排它性控制,即在一段时间内某资源仅为一进程所占用。
- 请求和保持条件:当进程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:进程已获得的资源在未使用完之前,不能剥夺,只能在使用完时由自己释放。
- 环路等待条件:在发生死锁时,必然存在一个进程–资源的环形链。
那我们使用的DNS为啥会出现这样的问题?难道是JDK或者是dnsjava(我们使用了dnsjava)的bug?
排查bug的最好方法就是阅读源码,我们可以通过死锁的线程栈自底向上逐层跟踪代码。
先看 histirx-***的死锁线程栈 :
-
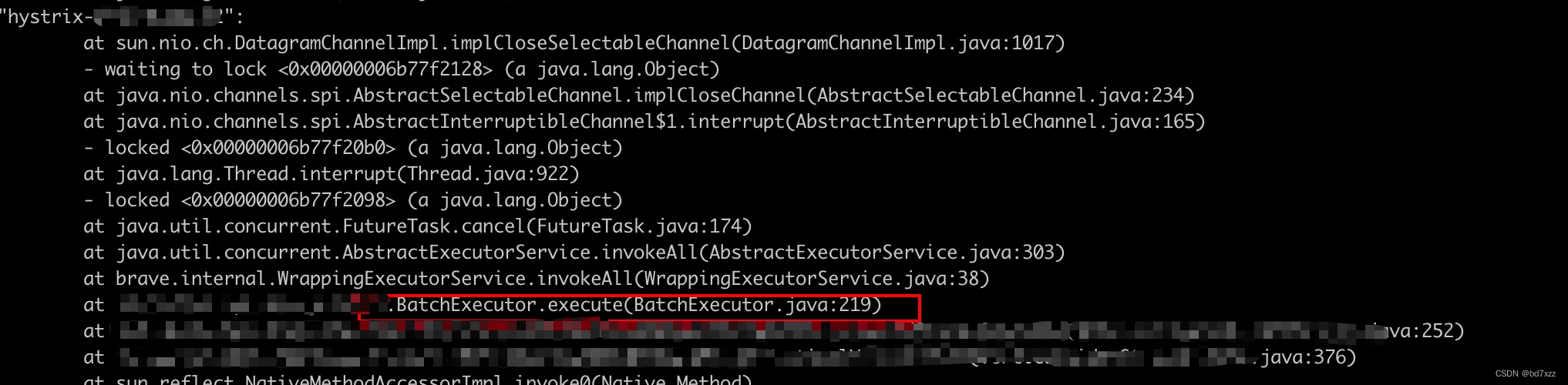
从业务调用点开始,这里我们的业务向BatchExecutor(公司内部封装的线程池操作)提交了线程

-
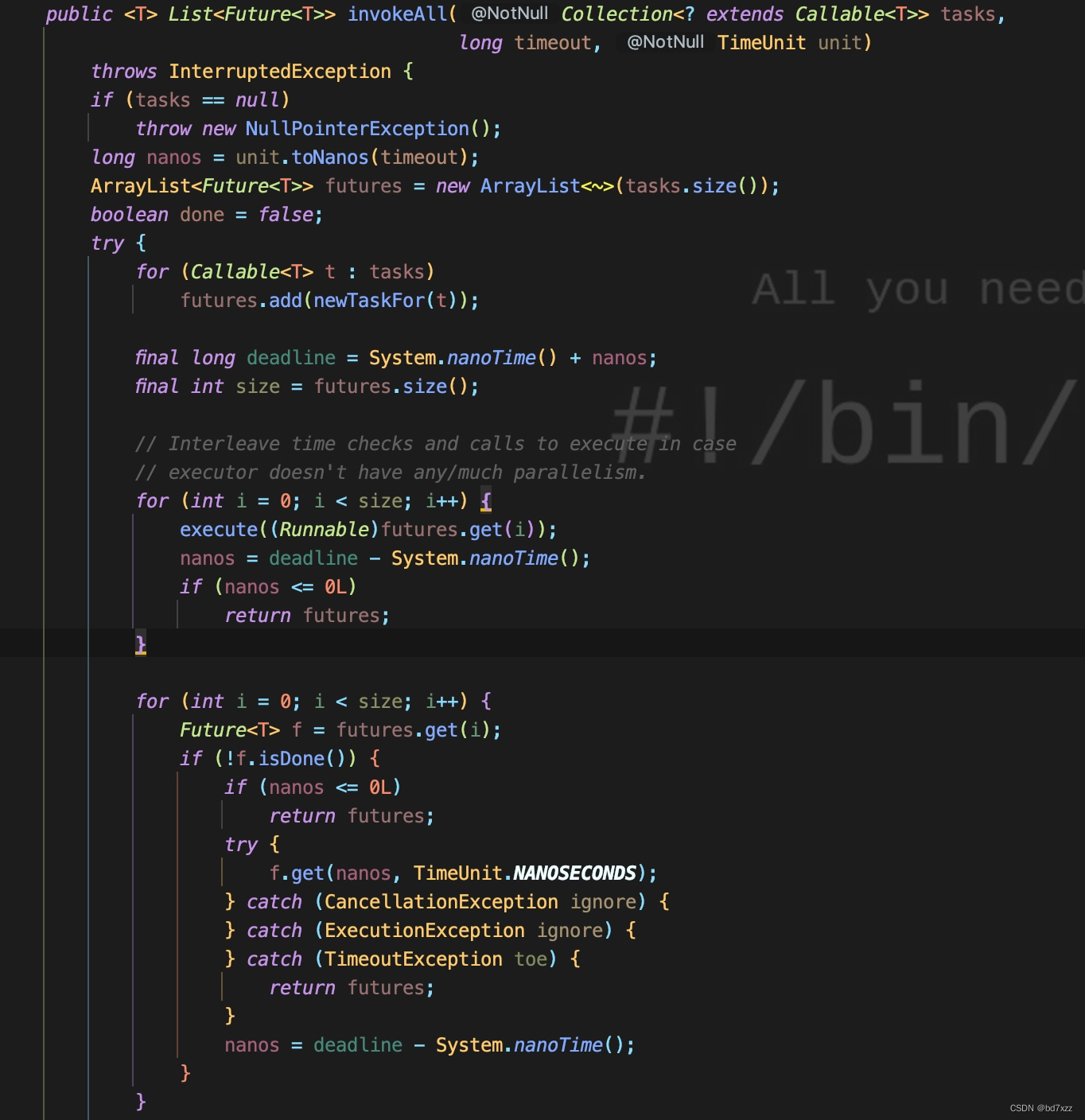
本质上调用AbstractExecutorService.invokeAll方法,该方法在线程池中的线程执行结束时,finally会触发FutureTask.cancel方法
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TS07UH2X-1669825910323)(resources/D72F2F916B826C3B1A9F3E87839BA5CC.jpg =563x184)]](https://img-blog.csdnimg.cn/405464b395e64a3e95b070f242ff7ba1.png)
-
由于在调用cancel方法对mayInterruptIfRunning实参传递的是true,所以会执行Thread.interrupt方法
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Sp08IWKv-1669825910323)(resources/81DA619959EFD816E3E5F8312AFD2BF3.jpg =623x366)]](https://img-blog.csdnimg.cn/8d99da8d6d864c48b3f8ba8522ef79c0.png)
-
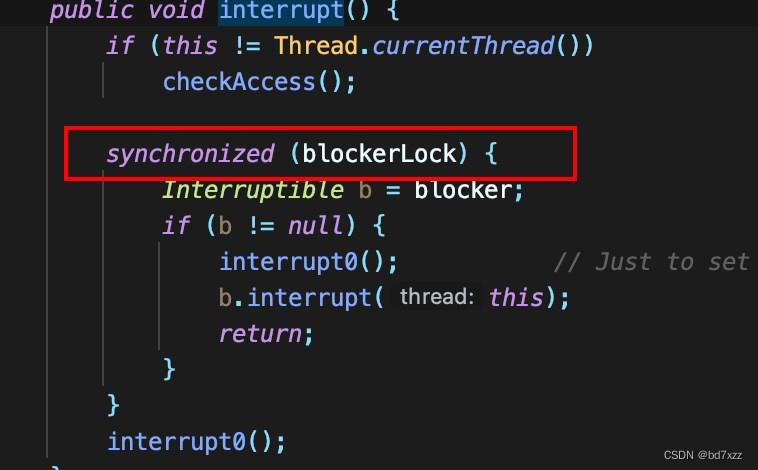
Thread.interrupt会对blockerlock加锁,根据线程栈,我们看到intterupt后会执行DatagramChannelImpl.implCloseSelectableChannel方法关闭UDP链接。
-
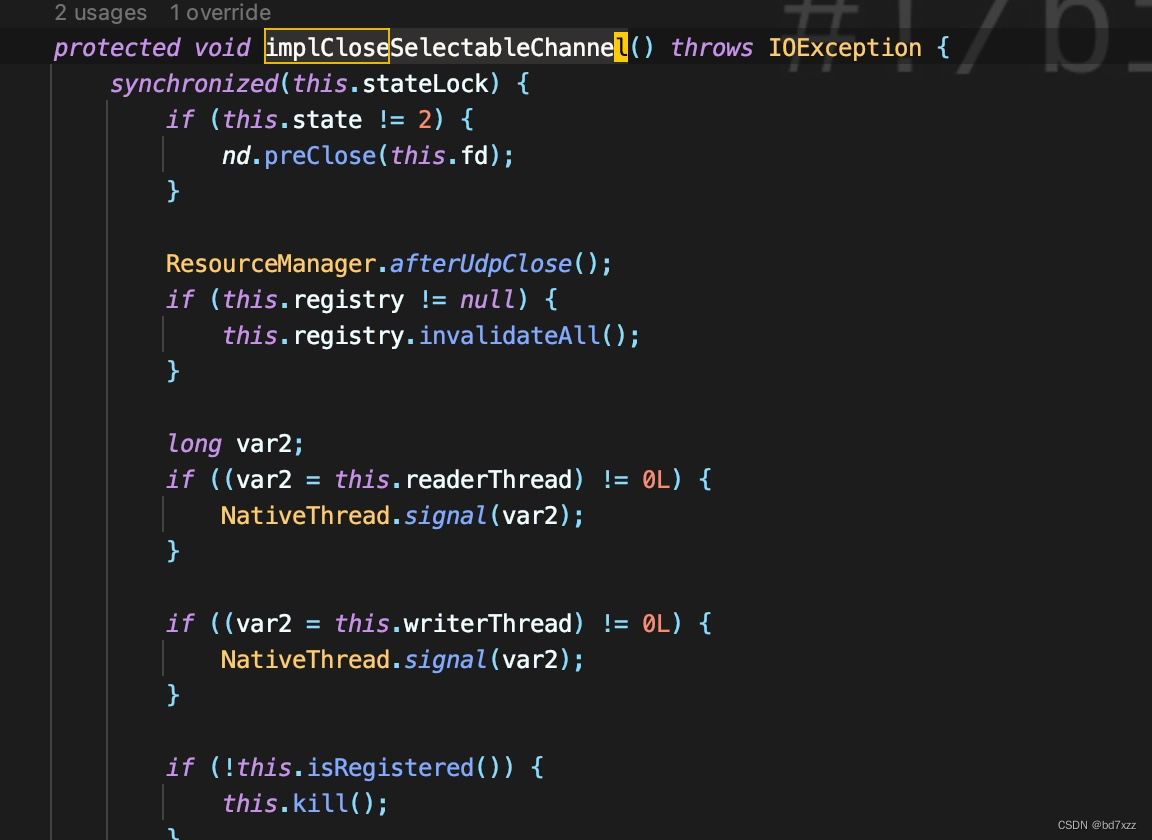
而implCloseSelectableChannel方法要拿到stateLock的锁,根据线程栈,此时出现锁等待。
再看pool-486-thread-132 的死锁线程栈:
-
这个线程栈比较长,直接从
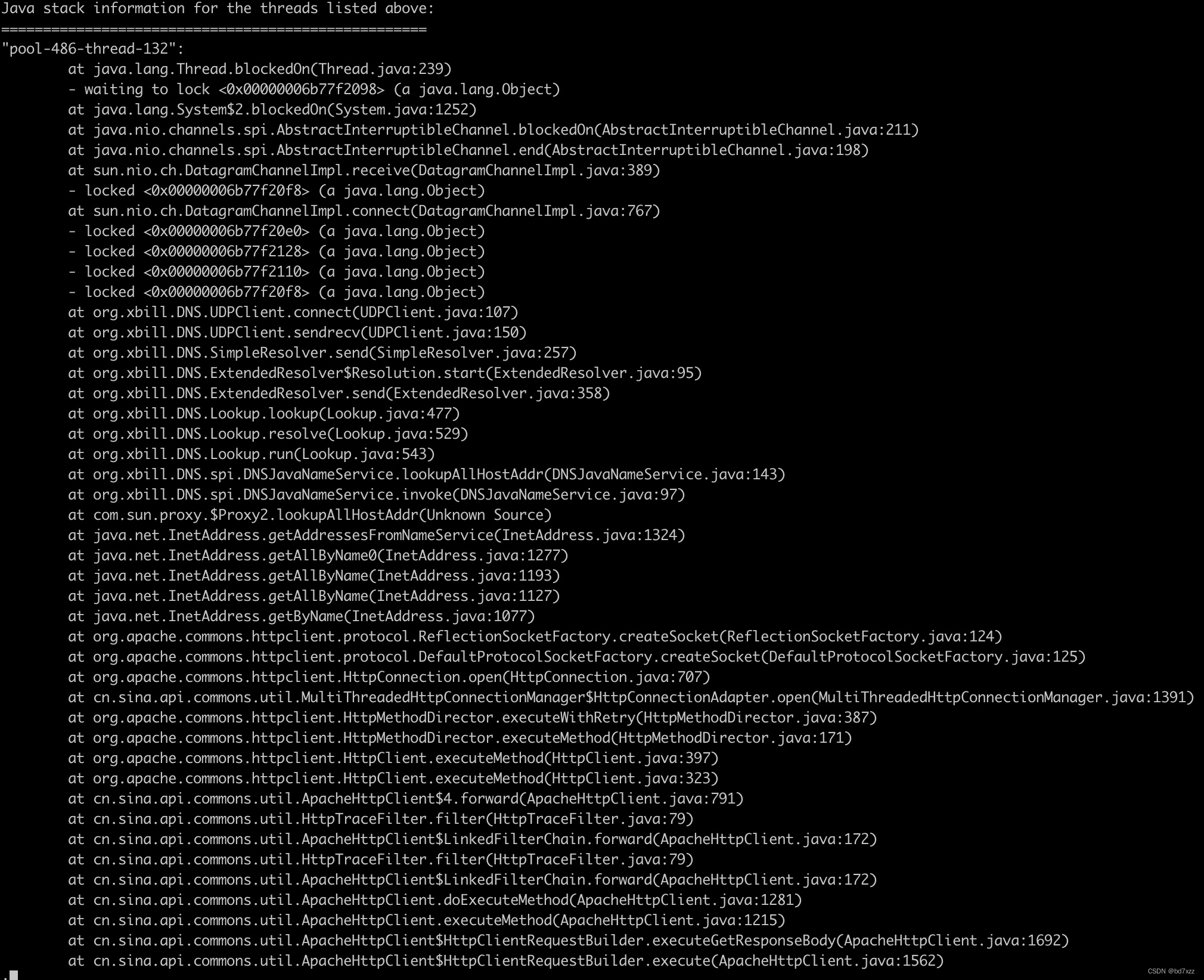
at org.xbill.DNS.UDPClient.connect(UDPClient.java:107)开始看,可以从包名看出,这是做dnsjava向DNS server发起UDP请求。
-
connect方法通过DatagramChannel.connect开启UDP链接。

-
DatagramChannel.connect中会锁住readLock、writeLock、stateLock,即线程栈中的:
- readLock
locked <0x00000006b77f20f8> (a java.lang.Object) - writeLock
locked <0x00000006b77f2110> (a java.lang.Object) - stateLock
locked <0x00000006b77f2128> (a java.lang.Object)
并锁住bloackingLock 即线程栈中的 locked <0x00000006b77f20e0> (a java.lang.Object)
然后分配Buffer并执行receive方法。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DKx6gIOS-1669825910324)(resources/110FF85914FB4D9A75DD8F8F677F8B0A.jpg =817x682)]](https://img-blog.csdnimg.cn/b47ff70cd9574588bbed2f4802d1139f.png)
- 在receive方法并根据线程栈逐层往下,recevie方法finally最后会执行end方法,end方法调用到最后实际上调用了Thread.blockedOn,bockedOn需要拿到blockerLock锁。此时这个锁
<0x00000006b77f2098>正在被histirx-***线程持有着。

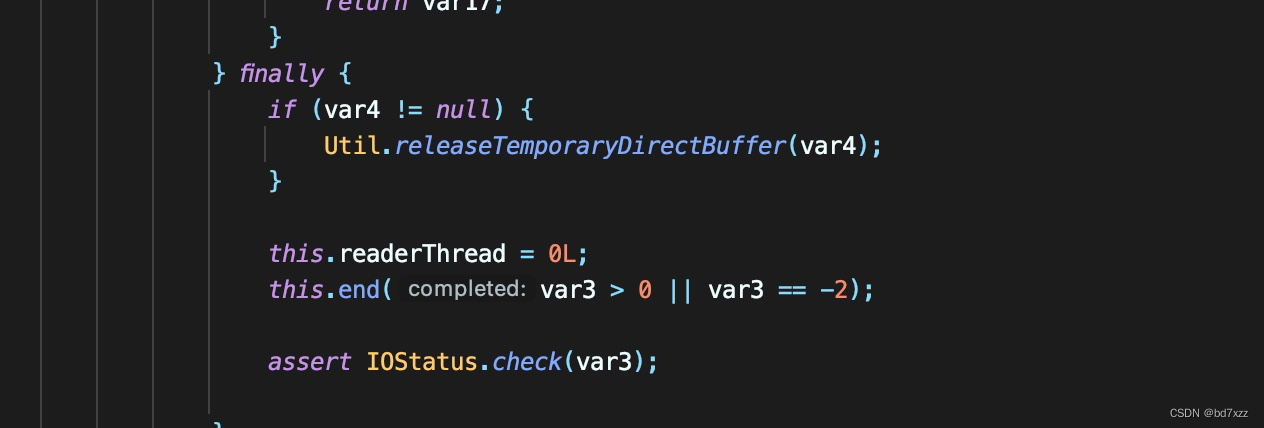
这个链路看起来,似乎是由一个线程建立UDP并发包,一个线程对该线程进行interrupt,就会产生死锁。
这一点,也有人在openjdk的bug列表中提出, JDK-8228765

那么线上为啥会出现hystrix线程对另外一个http请求正在DNS解析线程进行interrupt的动作?这里简单说明下:我们的业务中会通过BatchExecutor提交一个异步的业务逻辑,并且超时时间为300ms。若300ms以后未正常返回结果,自然会执行finally。

由于在异步业务逻辑比较复杂,请求多个rpc或其他资源,若一个请求超过300ms,其他业务逻辑也会被超时终止,即被interrupt,当有DNS时,便会触发这个bug。业务流量大的情况下触发概率比较大。
复现
经过上面的分析并参考JDK-8228765,我们可以构造2个线程,一个发UDP包,一个对其进行interrupt操作,参考如下代码:
import java.io.IOException;
import java.net.InetSocketAddress;
import java.net.StandardSocketOptions;
import java.nio.channels.DatagramChannel;
import java.util.concurrent.ThreadLocalRandom;
public class UDPReceiver {
public static void main(String[] args) throws IOException, InterruptedException {
DatagramChannel receiver = DatagramChannel.open();
receiver.setOption(StandardSocketOptions.SO_REUSEADDR, true);
receiver.bind(new InetSocketAddress("localhost",8000));//监听UDP 8000端口
UDPSender sender = new UDPSender();
new Thread(sender).start(); //启动一个线程开始发UDP包
while (true) {
System.out.println("before interrupt");
sender.interruptThis(); //这里会触发死锁
System.out.println("after interrupt");
Thread.sleep(ThreadLocalRandom.current().nextLong(0,100));
}
}
}
import java.net.InetSocketAddress;
import java.net.StandardSocketOptions;
import java.nio.ByteBuffer;
import java.nio.channels.DatagramChannel;
import java.util.concurrent.ThreadLocalRandom;
public class UDPSender implements Runnable {
private static final InetSocketAddress target = new InetSocketAddress("localhost", 8000);
private Thread thisThread;
public void interruptThis() {
if (null != thisThread) {
thisThread.interrupt(); //引发死锁的源头2
}
}
@Override
public void run() {
thisThread = Thread.currentThread(); //保存一下sender的当前线程
while (true) {
try {
DatagramChannel sender = DatagramChannel.open();
sender.setOption(StandardSocketOptions.SO_REUSEADDR, true);
sender.connect(target); //连接本地8000端口发包
System.out.println("sending...");
sender.send(ByteBuffer.allocate(100).putInt(1), target);//引发死锁的源头1
System.out.println("sending success...");
Thread.sleep(ThreadLocalRandom.current().nextLong(0, 100));
} catch (Exception e) {
}
}
}
}
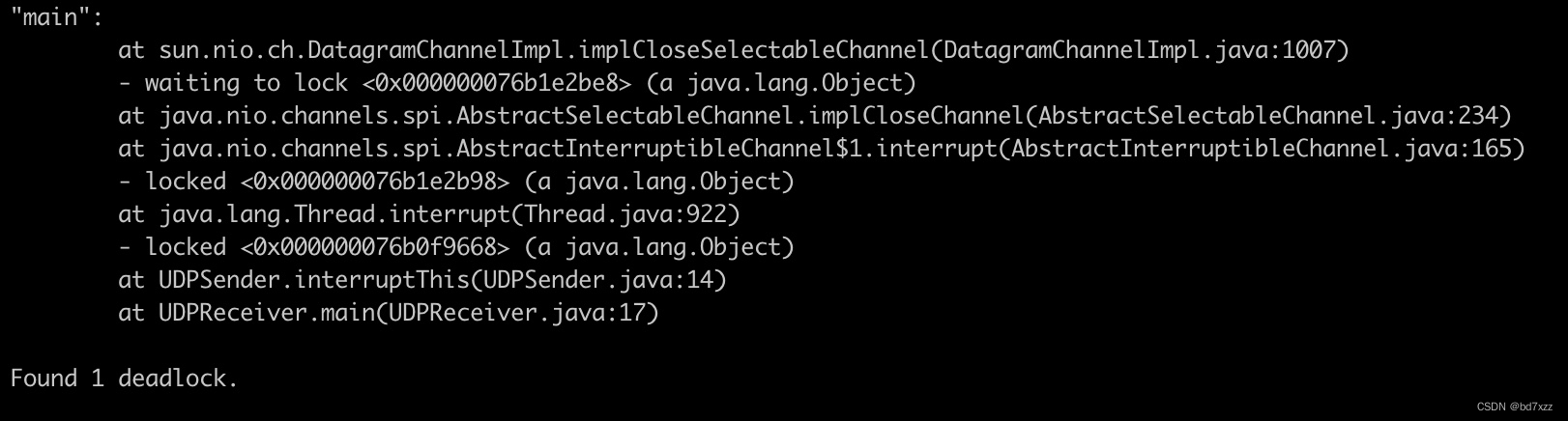
如下图所示,在跑几轮后before interrupt的时候出现死锁。
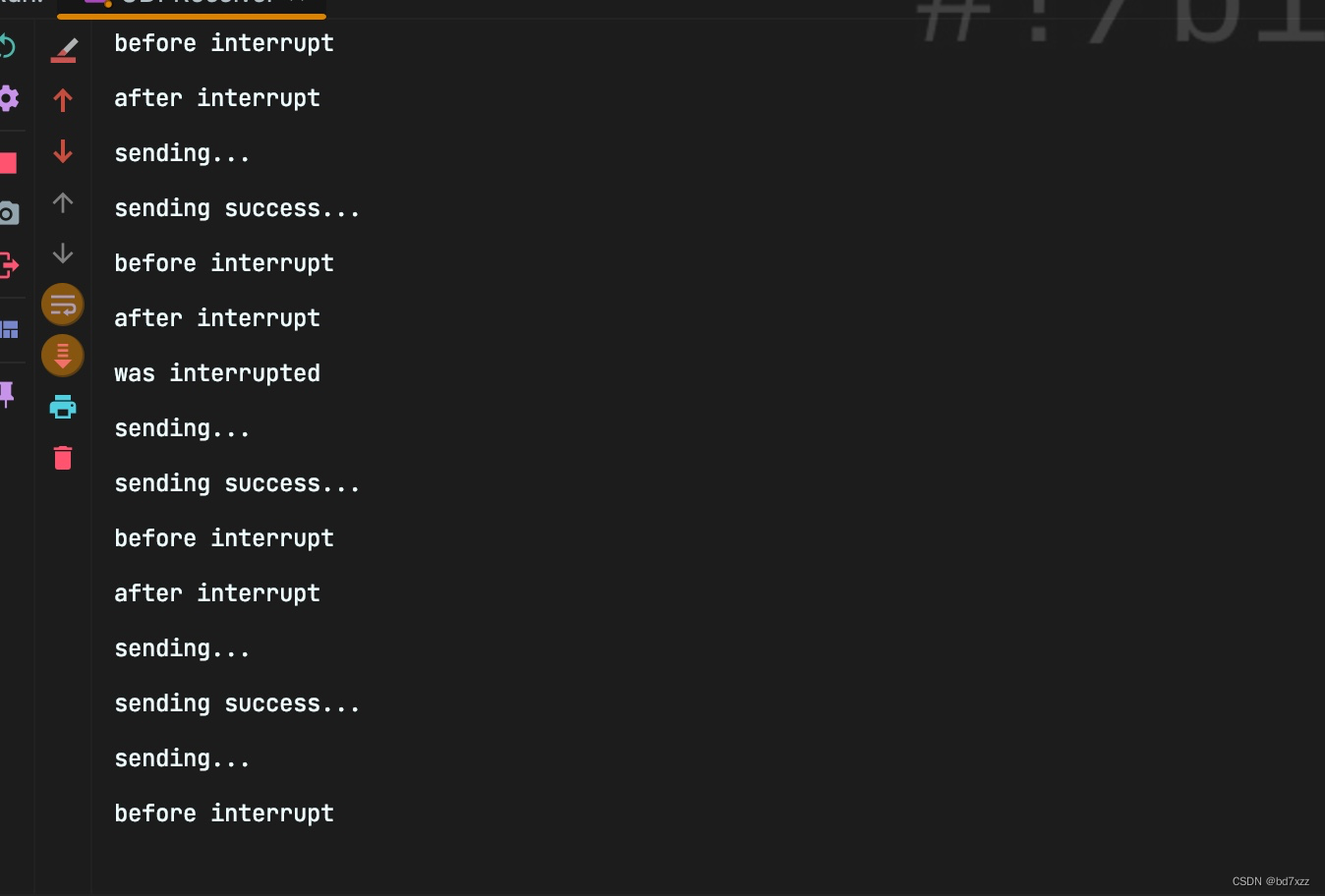
jstack -l <pid>
打印线程栈,最后可看到死锁信息。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hCx73oRV-1669825910326)(resources/0BCA07EE03E87EFAD3963670B36C5CB4.jpg =882x628)]](https://img-blog.csdnimg.cn/c4b45c2826264b788022c472dd04ab45.png)
线程Thread-0等待的锁对象 0x000000076b0f9668由主线程在执行UDPSender.interruptThis时锁住,即对Thread-0线程进行interrupt。根据Thread.interrupt方法的描述,若当前线程处于IO方法阻塞时,通道会被关闭,会抛出 ClosedByInterruptException 异常并设置中断状态为 true。
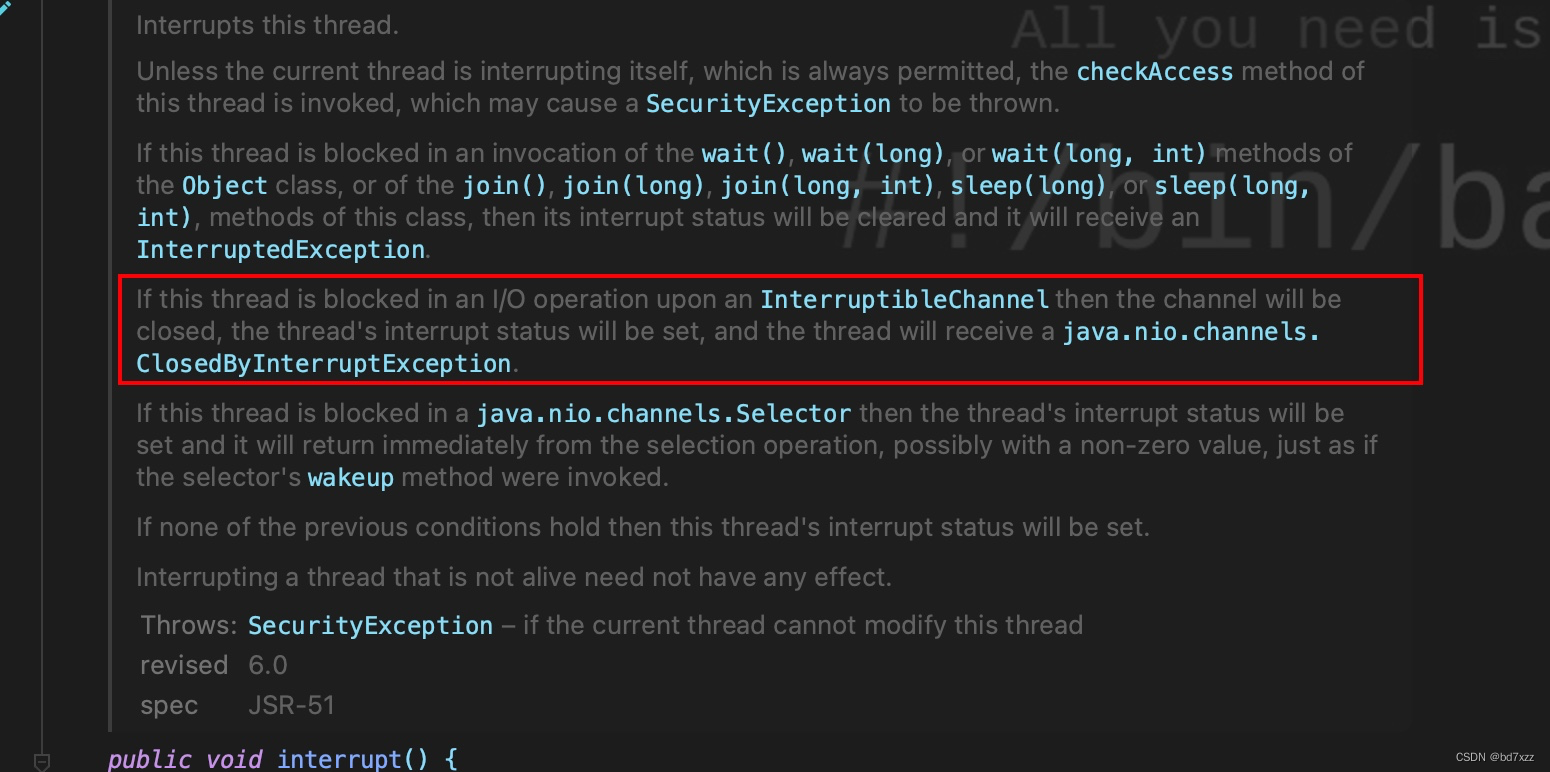
死锁的整个过程如下:
先看new Thread(sender).start()即Thread-0的执行。
可以看死锁的线程栈调用链路执行情况,参考代码推导:
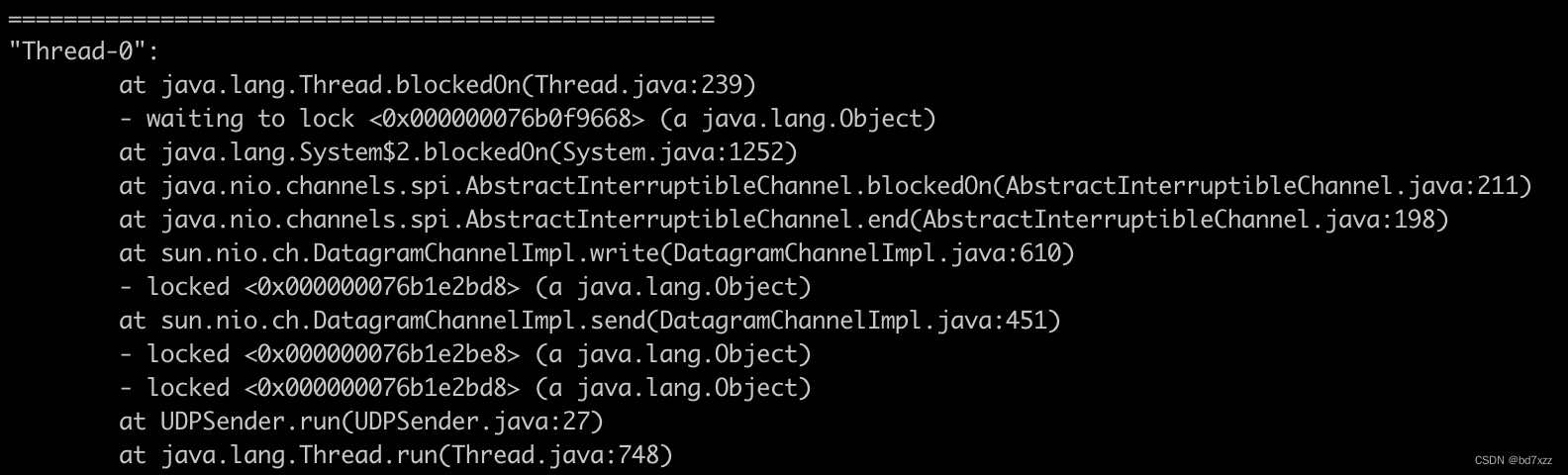
-
DatagramChannelImpl实现了AbstractInterruptibleChannel。在DatagramChannelImpl.send方法中会拿到两把锁,注意其中一把为stateLock,即线程中的
- locked <0x000000076b1e2be8> (a java.lang.Object)
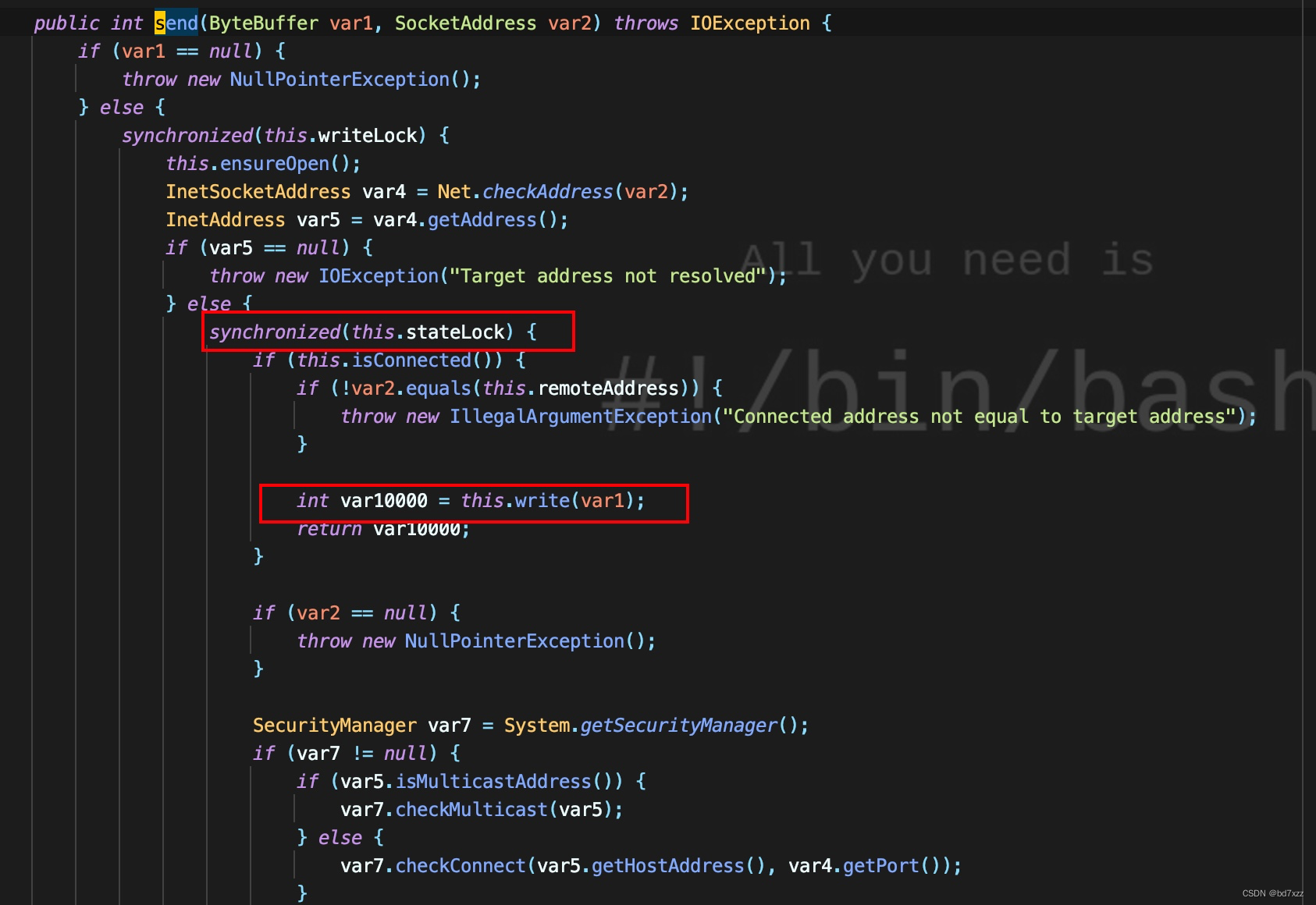
-
在write方法中,可以看到调用this.begin方法,即AbstracInterruptibleChannel.begin。在IOUtil.write真正发包完成后,会执行finally中的this.end方法。
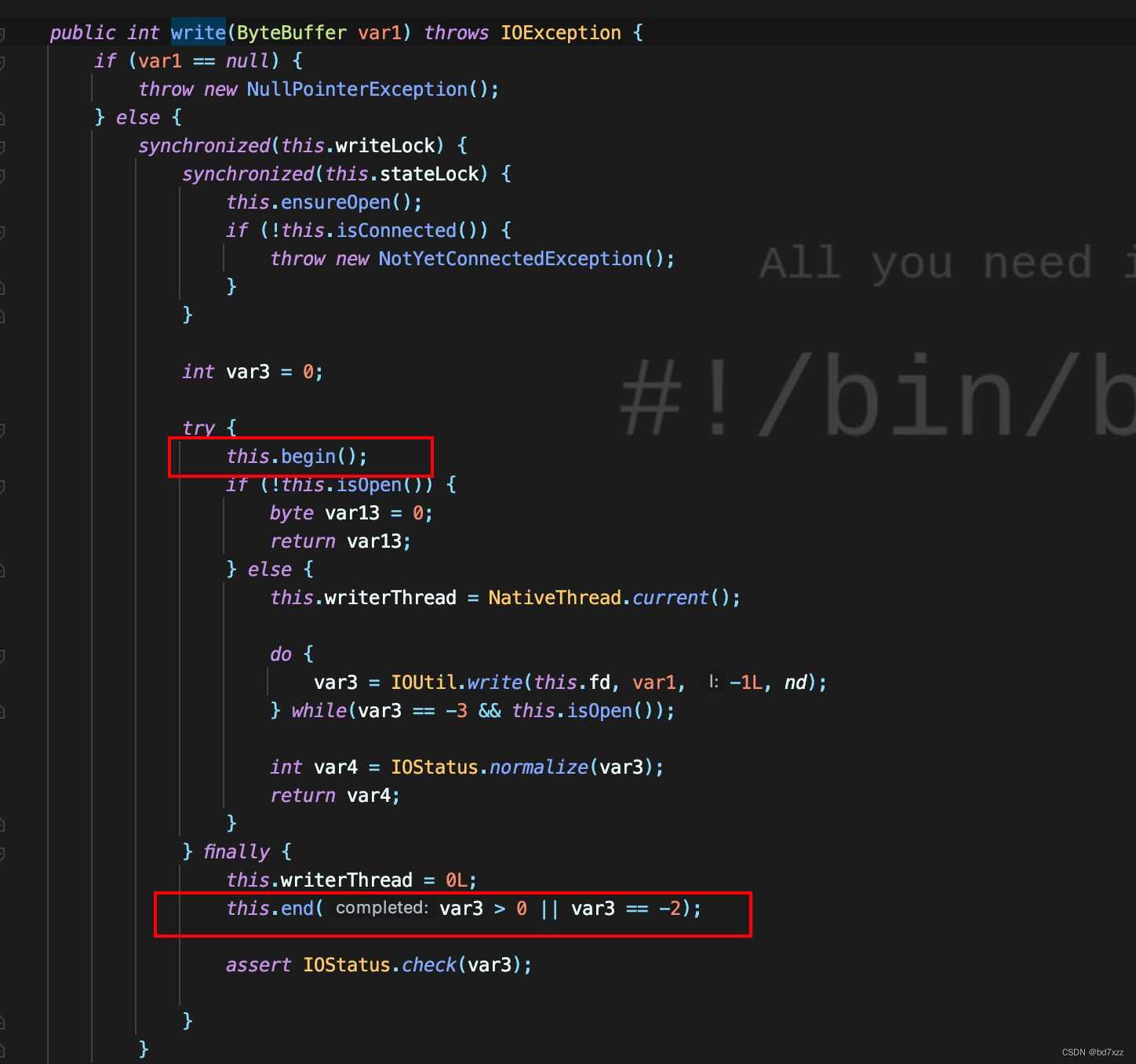
AbstracInterruptibleChannel.begin注册了收到interrupt后要执行的逻辑,注意这里,下面会用。
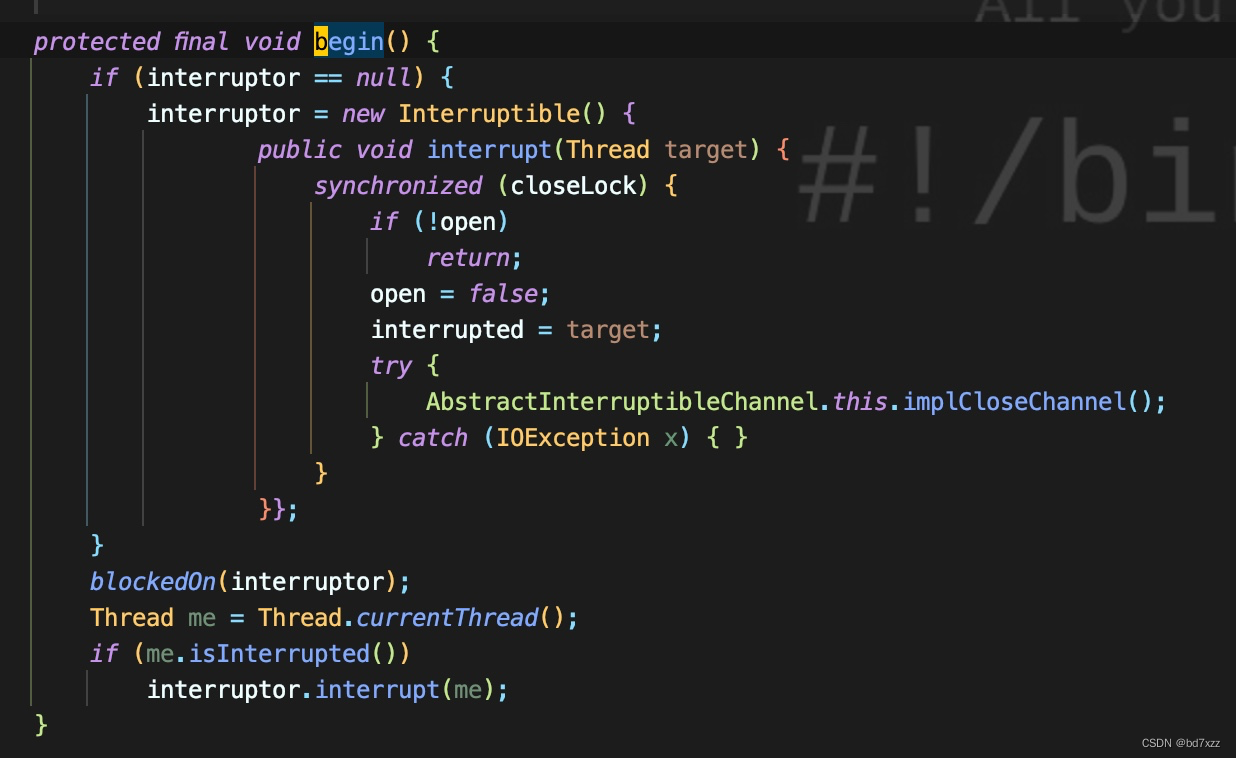
-
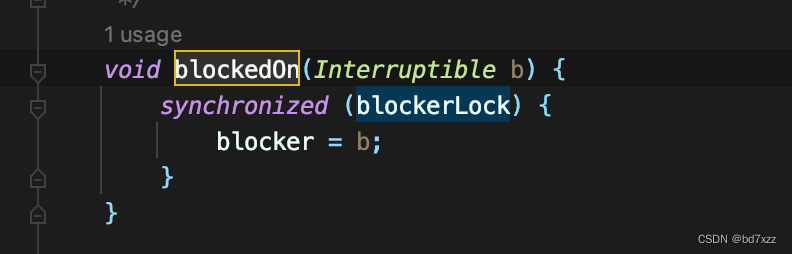
在AbstractInterruptibleChannel.end方法中通过blockedOn方法标记block状态
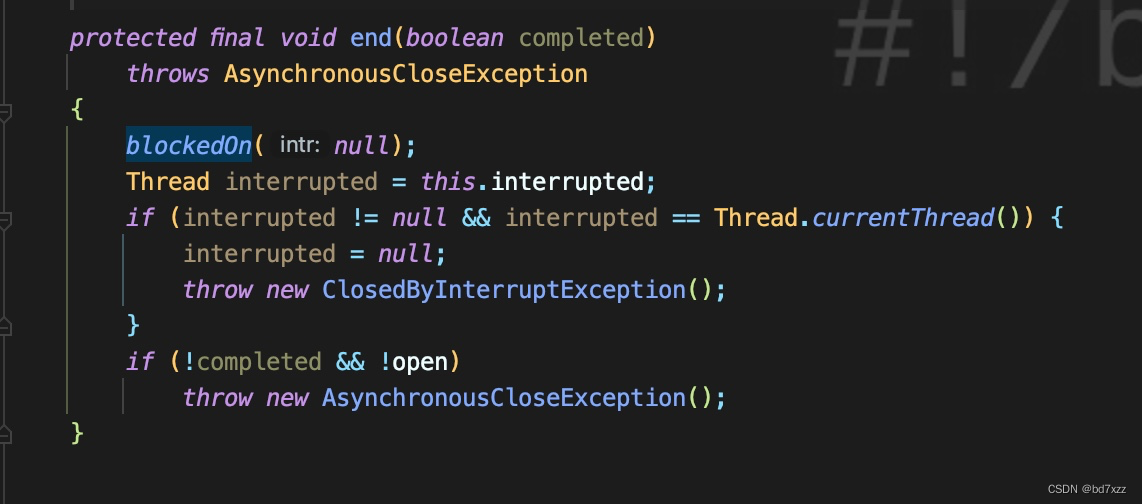
-
blockedOn会最终调到Thread.blockedOn方法,且实参为当前Thread-0线程。注意这里,要拿到blockerlock,即线程栈中的
- waiting to lock <0x000000076b0f9668> (a java.lang.Object)。

再看sender.interruptThis()的执行:
可以看死锁的线程栈调用链路执行情况,参考代码推导:
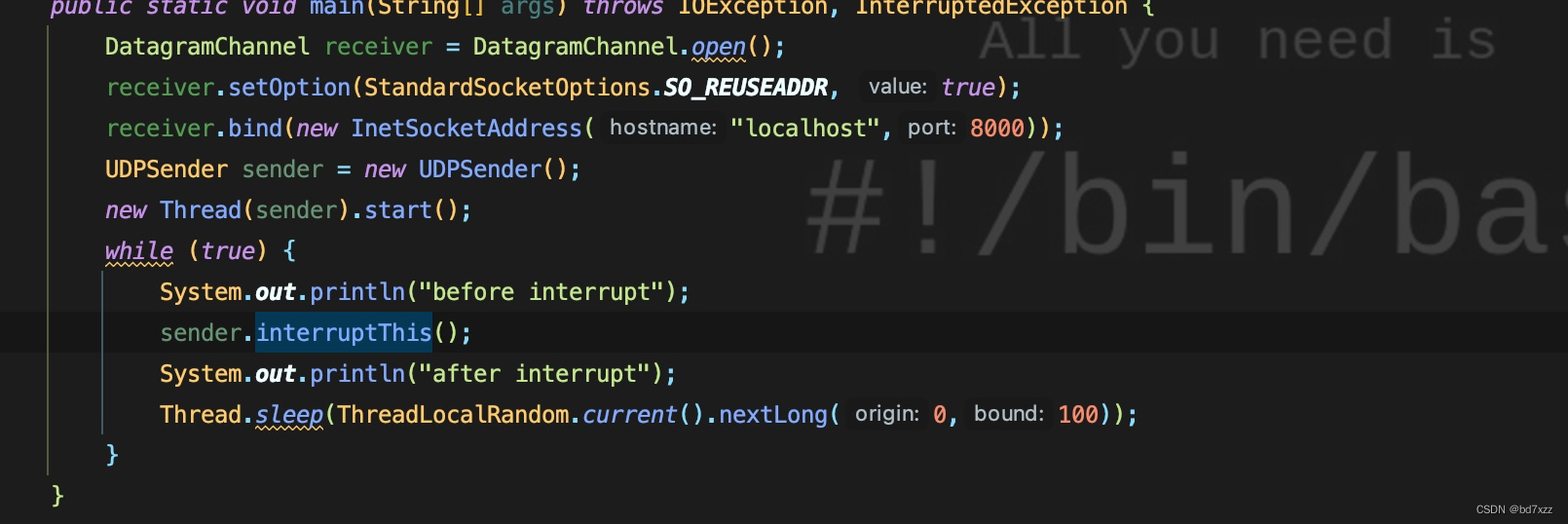
-
在Thread.interrupt方法中会调用b.interrupt,注意这里会拿到blokcerLock,即线程栈中的
- locked <0x000000076b0f9668> (a java.lang.Object)
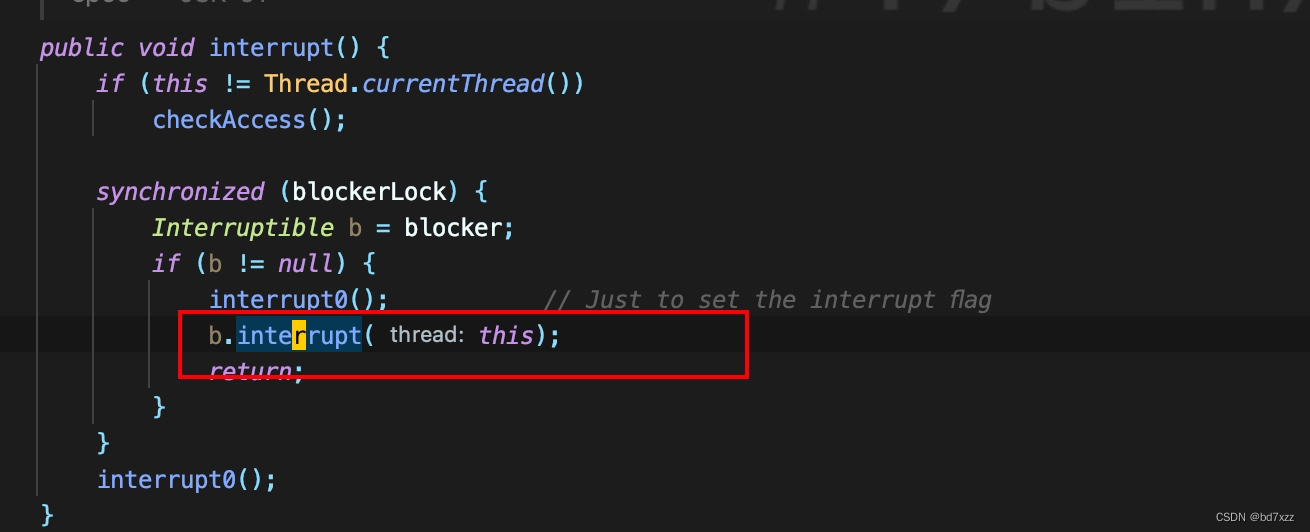
-
b.interrupt会触发AbstracInterruptibleChannel在begin方法中实现的interrupt方法
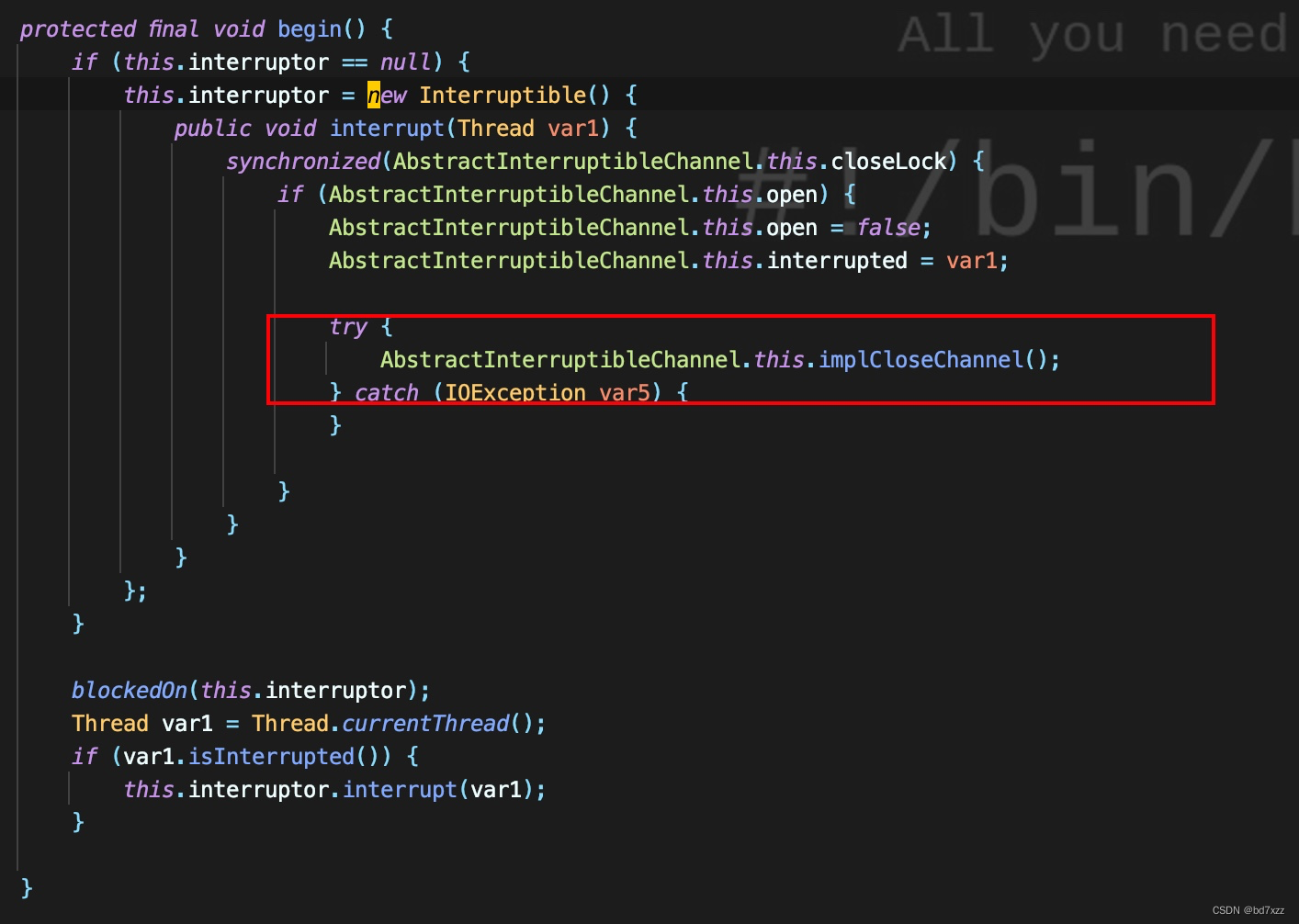
-
通过AbstracInterruptibleChannel.implCloseChannel关闭通道。
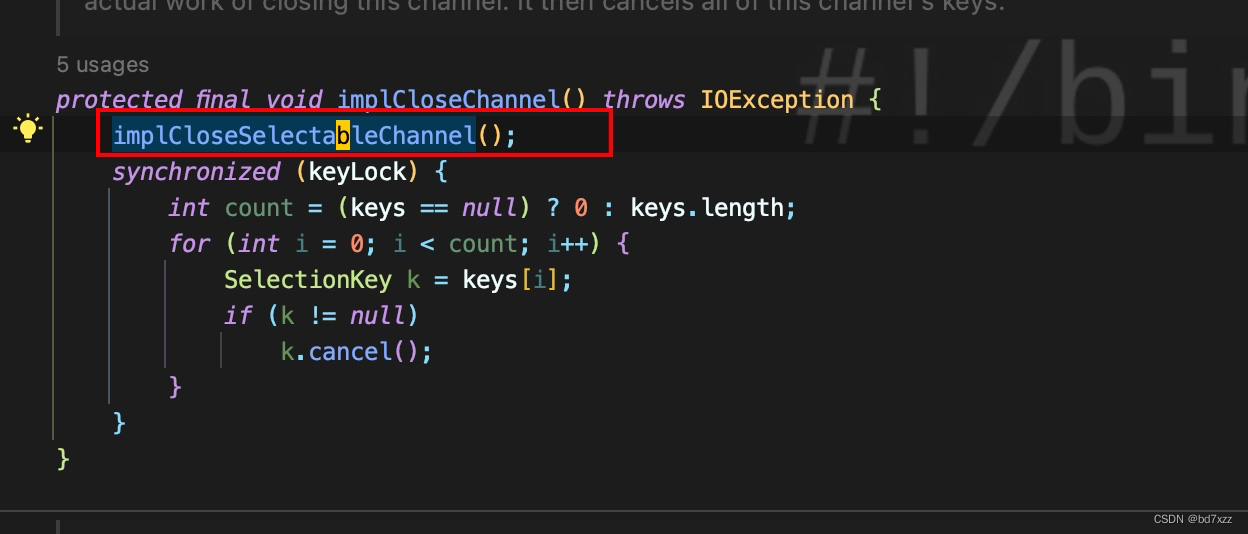
-
在DatagramChannelImpl.implCloseChannel的实现中,要拿到stateLock这把锁。注意这里就是线程栈中的
- waiting to lock <0x000000076b1e2be8> (a java.lang.Object)
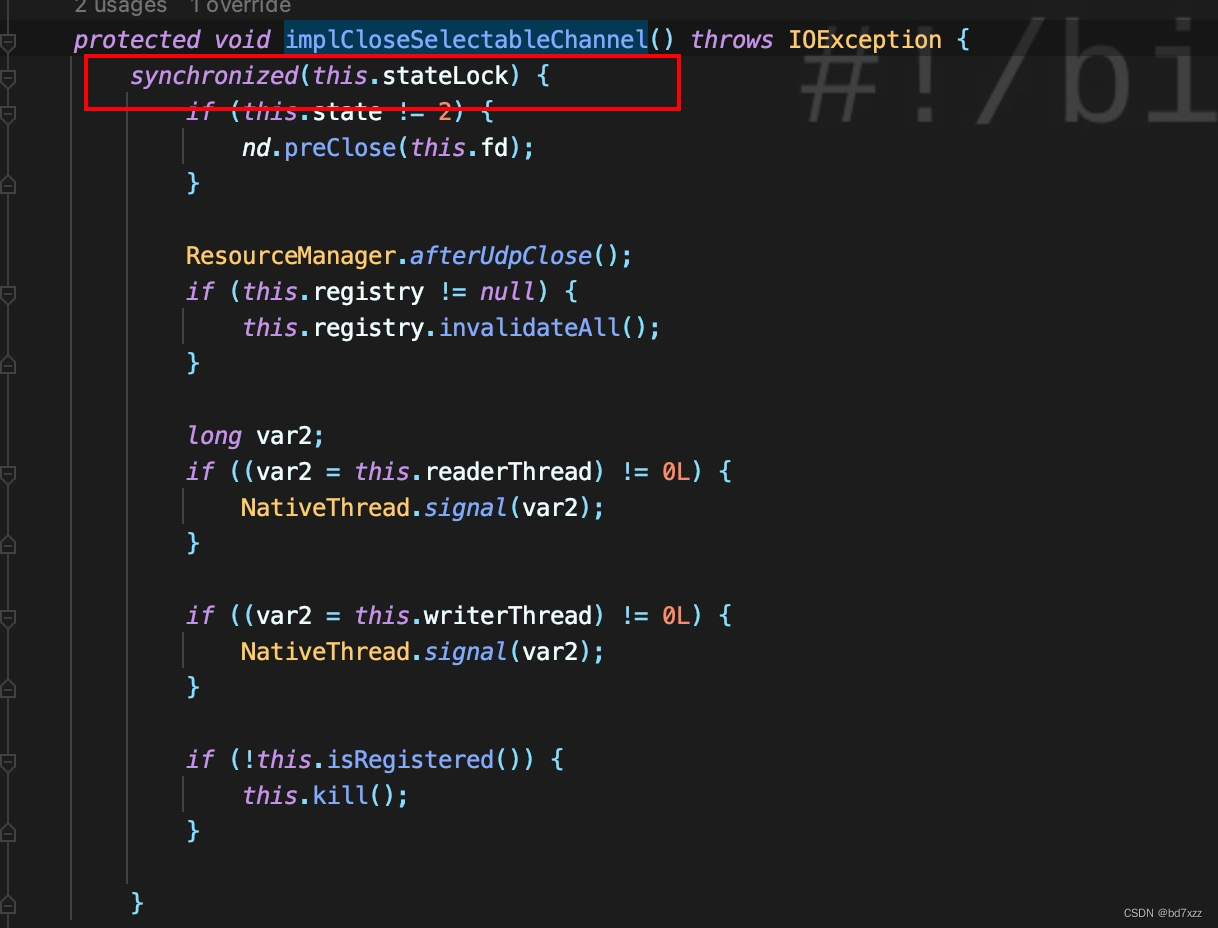
从上面的分析可以很明显的看出,主线程触发Thread-0的interrupt动作时,在执行interupt方法持有了blockerLock锁,关闭通道要拿stateLock锁,而Thread-0在发包时先拿到了stateLock锁,并且设置block状态时要拿blockerLock锁,此时出现死锁!
解决方法
- 根据OpenJDK的bug列表中的说明 JDK-8228765 ,这个bug从JDK-8039509就开始有了,一直到jdk13才修复。所以,要么升级jdk到13,要么死!我选择了死。
- 我们项目中使用了dnsjava,在dnsjava的github上 issues#69 里也是有报这个bug的。另外在logstash中也有类似的问题 issues#117。
- 当然如果选择了死,那就是遇到了重启服务器了。
总结
- JVM的bug也很多,同时也很诡异,需要仔细观察运行时状态+阅读源码才能分析出原因,如果你不想分析原因,可以用google搜搜看,很可能已经有了答案。
- 排查问题思路很重要,由于业务环境通常比较复杂,在大流量、大数据量的情况下会有各种千奇百怪的问题,需要有足够的耐心和较广的知识面。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











