







记录下当前常见的激活函数,方便查询
目录
7.ELU(Exponential Linear Unit)
| 激活函数分类 | 举例 | |
|---|---|---|
| 经典基础函数 | ReLU, Sigmoid, Tanh, Softmax | |
| 改进型函数 | Leaky ReLU, PReLU, ELU | |
| 新一代函数 | SiLU, Swish, GELU, Mish |
1.ReLU(Rectified Linear Unit)
公式:
ReLU(x)=max(0,x)
函数图像:
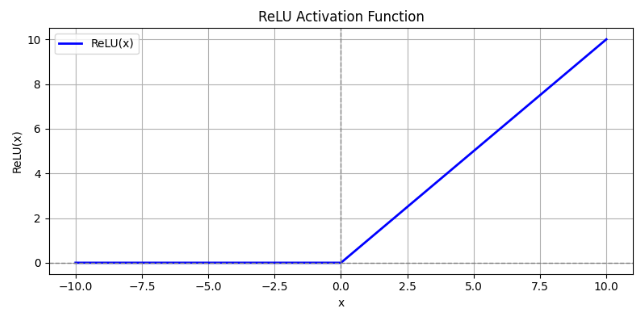
特点:
-
x<=0时,左侧为 0;
-
x>0 时为一条斜率为 1 的直线。
2.Sigmoid
公式:
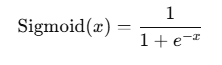
函数图像:
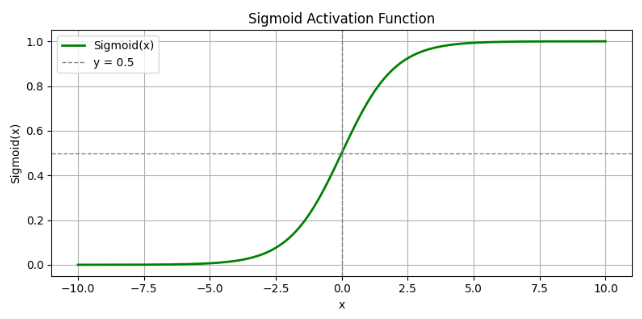
特点:
-
输出范围在 (0,1)
-
是一个 S 形曲线(S-curve)
-
在 x=0 处输出为 0.5
-
当 x过大或过小时梯度趋于 0,容易出现梯度消失问题
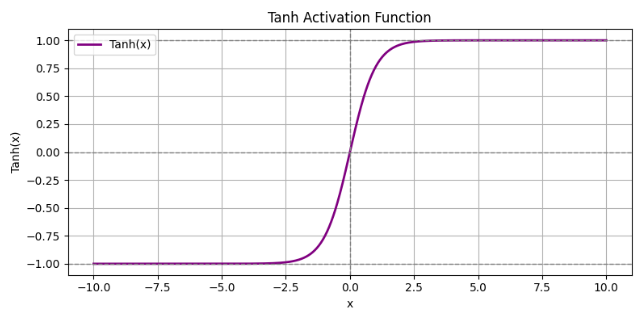
3.Tanh
公式:
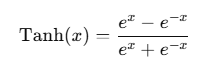
也可以写作:
![]()
函数图像:
特点:
| 特性 | 描述 |
|---|---|
| 输出范围 | (−1,1) |
| 零中心 | 比 Sigmoid 更适合隐藏层 |
| 饱和区 | |
| 平滑性 | S 形曲线,形状与 Sigmoid 相似,但上下对称 |
4.Softmax
公式:
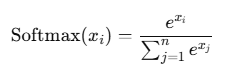
-
输出是一个概率分布:所有值在 (0,1)之间,且总和为 1。
-
会放大最大值对应的分量,其他变小。
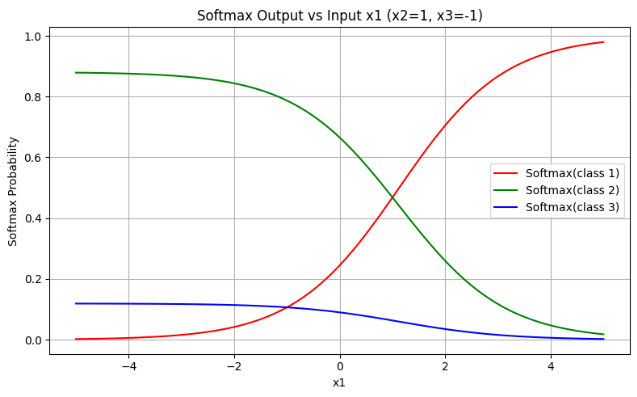
图像:
我们不能像 ReLU 那样画一个函数图,因为 Softmax 是作用于向量的,所以我们通常画出多个输入值的 Softmax 输出分布
特点:
| 特性 | 描述 |
|---|---|
| 输出范围 | 所有值 ∈(0,1),并且总和为 1 |
| 应用场景 | 多分类任务的输出层,结合交叉熵(Cross Entropy)使用 |
| 可解释性 | 每个输出表示属于某一类的“概率” |
| 饱和性 | 在输入差异很大时,接近 one-hot 编码 |
5.Leaky ReLU
公式:
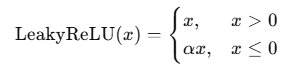
-
其中 α 是一个很小的常数,通常取值如 0.01 或 0.1。
-
与 ReLU 相比,在 x≤0 区域不会完全为 0,有 "泄露" 的梯度。
图像:
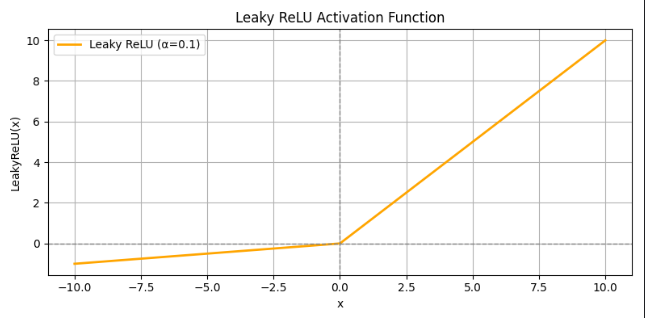
特点:
| 特性 | 描述 |
|---|---|
| 避免“神经元死亡” | ReLU 在负数区域的梯度为 0,可能使神经元永远无法激活,Leaky ReLU 通过保留一点梯度缓解这个问题。 |
| 简单高效 | 与 ReLU 类似的计算复杂度 |
| 可微(分段可导) | 适合用于反向传播 |
| 参数化版本 | 有 PReLU(可学习的 α) 是 Leaky ReLU 的推广 |
6.PReLU(Parametric ReLU)
公式:
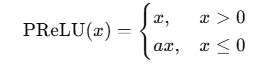
其中 a 是一个可学习的参数,不是固定值(不像 Leaky ReLU 的 α 通常固定为 0.01 或 0.1)
图像:
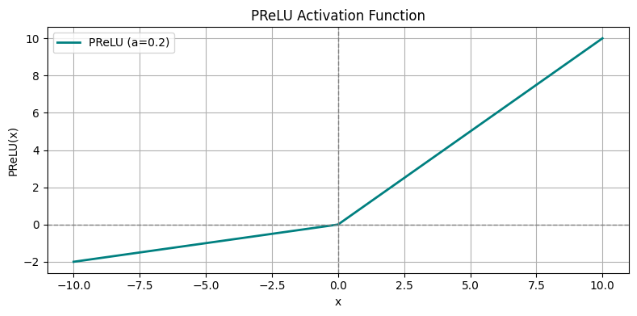
特点:
| 特性 | 描述 |
|---|---|
| 可学习参数 | a会通过梯度下降在训练中自动优化 |
| 提高模型灵活性 | 可针对不同神经元或层自适应调整负区响应 |
| 避免神经元“死亡”问题 | 保留负值的梯度传播通道 |
| 略增加模型复杂度 | 增加参数量,需正则化防过拟合(尤其在较小数据集上) |
7.ELU(Exponential Linear Unit)
公式:
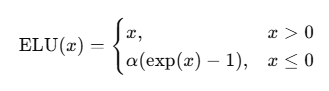
其中 α 是一个超参数(常用 α=1.0),控制负半轴的弯曲程度。
图像:

特点:
| 特性 | 描述 |
|---|---|
| 正区间线性 | 与 ReLU 一样,当 x>0 时直接输出 x |
| 负区间平滑渐近负常数 | 相比 ReLU、Leaky ReLU,更平滑地处理负值,避免硬折断 |
| 零均值输出 | 输出更接近 0 均值,有助于减小偏置偏移(bias shift) |
| 可导 & 稳定梯度 | 适合深层网络训练 |
8.SiLU(Sigmoid Linear Unit)
公式:
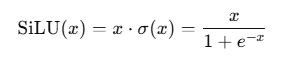
-
σ(x) 是 Sigmoid 函数。
-
也就是输入 x 乘以它自己的 sigmoid。
图像:
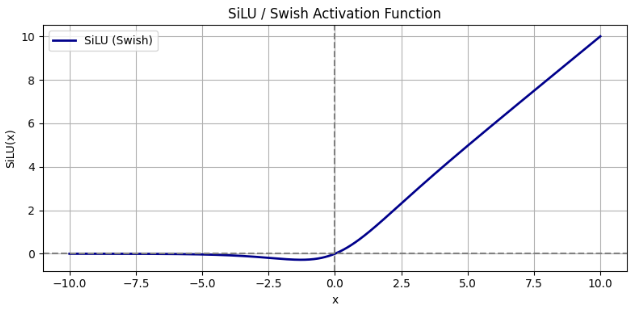
-
正区间类似 ReLU;
-
负区间输出为负值但非零,且有平滑曲线过渡;
-
在 x≈−1 附近存在一个微小的“下陷”;
-
有助于梯度流动,训练效果通常优于 ReLU
特点:
| 特性 | 描述 |
|---|---|
| 平滑且可导 | 全局光滑连续,梯度稳定,有利于训练深层网络 |
| 非单调 | 低于 0 的区域存在轻微“下陷”,有助于表达复杂关系 |
| 自门控机制 | 输出受自身值控制,形成“自调节抑制”效果 |
| 常用于现代架构 | 如 EfficientNet、Transformer 中的激活函数 |
| PyTorch 中名称 | SiLU 或 Swish,两者是等价的 |
9.Swish
Swish 是一个近年来表现优异的激活函数,由 Google Brain 团队提出,在一些深度网络(如 EfficientNet)中表现比 ReLU 更好。它与 SiLU 函数是等价的
公式:
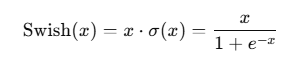
-
其中 σ(x) 是 Sigmoid 函数。
-
Swish 会根据输入自动调节激活强度,属于一种“自门控激活函数”。
图像:
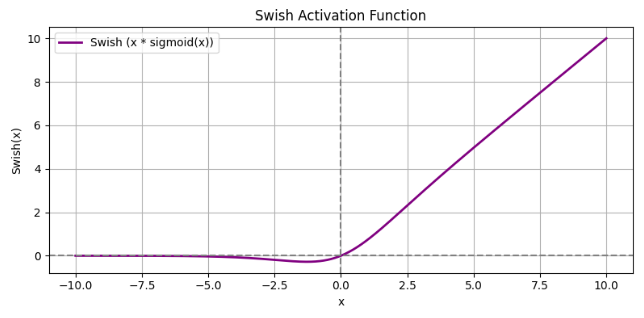
特点:
| 特性 | 描述 |
|---|---|
| 平滑可导 | 适合用于深层网络的反向传播 |
| 非单调 | 提供更丰富的非线性表达能力(比 ReLU 更复杂) |
| 弱抑制负值 | 不是简单地把负值截断为 0,而是保留一定负值 |
| 零中心趋近 | 输出值更接近 0 均值,有利于收敛 |
| 自门控特性 | 输出由自己控制(x⋅σ(x)) |
Swish 适合用在什么时候?
-
训练较深网络时(如 Transformer、EfficientNet)
-
对性能要求高时(Swish 通常略优于 ReLU)
-
需要平滑激活函数时
10.GELU
目前非常流行并广泛用于 Transformer 模型(如 BERT、GPT)的激活函数 —— GELU(Gaussian Error Linear Unit,高斯误差线性单元)。
GELU 将输入乘以高斯累积分布函数(非线性平滑):
![]()
其中 Φ(x) 是标准正态分布的累积分布函数(CDF):
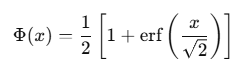
简化后的近似版本(更常用):
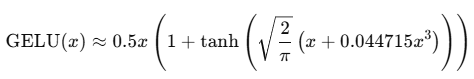
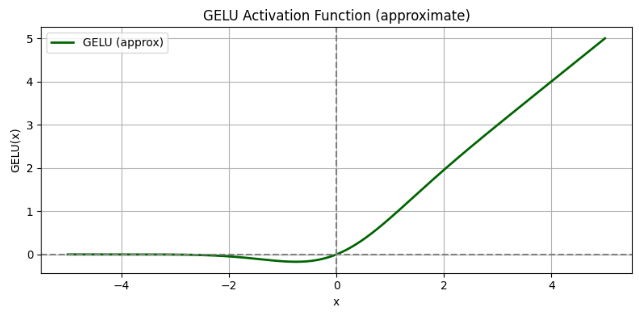
图像:
使用近似公式
特点:
| 特性 | 描述 |
|---|---|
| 平滑且可导 | 输出连续平滑,有利于梯度传播 |
| 非单调 | 更复杂非线性表达能力(比 ReLU 更强) |
| 高斯建模思想 | 类似于对输入“做概率性保留”,在负区间并非直接清零 |
| 大量用于 Transformer / BERT 等预训练模型中 |
11.Mish
Mish,它是由 Diganta Misra 提出的,在一些计算机视觉和自然语言处理任务中被证明优于 ReLU、Swish 等激活函数
公式:
![]()
也可以写成:
![]()
图像:
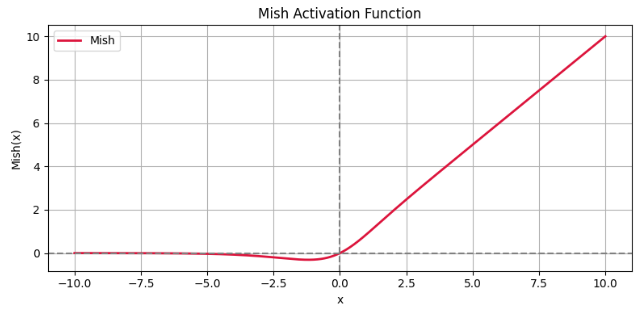
特点:
| 特性 | 描述 |
|---|---|
| 平滑连续 | 类似于 Swish / GELU,全域可导 |
| 非单调 | 表达能力强,适合复杂函数建模 |
| 零均值输出趋势 | 有助于训练更深的网络 |
| 负值保留 | 和 GELU 类似,能缓解“神经元死亡” |
| 在许多任务上优于 ReLU、Swish |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









