







代码如下:
public static void mySaveAsFile(){
SparkConf conf=new SparkConf()
.setAppName("mySaveAsFile")
.setMaster("local");
JavaSparkContext sc=new JavaSparkContext(conf);
List<Integer> list=Arrays.asList(1,23,4,4,6,5,7);
JavaRDD<Integer> rdds= sc.parallelize(list,2);
JavaRDD<Integer> mapRdd=rdds.map(new Function<Integer,Integer>(){
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer arg0) throws Exception {
// TODO Auto-generated method stub
return arg0*2;
}
});
mapRdd.saveAsTextFile("E:\\2018\\a.txt");
sc.close();
}
错误原因如下:
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
16/05/03 23:22:18 INFO SparkContext: Running Spark version 1.6.1
16/05/03 23:22:36 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/05/03 23:22:37 INFO SecurityManager: Changing view acls to: admin
16/05/03 23:22:37 INFO SecurityManager: Changing modify acls to: admin
16/05/03 23:22:37 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(admin); users with modify permissions: Set(admin)
16/05/03 23:22:38 INFO Utils: Successfully started service 'sparkDriver' on port 56335.
16/05/03 23:22:39 INFO Slf4jLogger: Slf4jLogger started
16/05/03 23:22:39 INFO Remoting: Starting remoting
16/05/03 23:22:40 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriverActorSystem@192.168.213.1:56350]
16/05/03 23:22:40 INFO Utils: Successfully started service 'sparkDriverActorSystem' on port 56350.
16/05/03 23:22:40 INFO SparkEnv: Registering MapOutputTracker
16/05/03 23:22:40 INFO SparkEnv: Registering BlockManagerMaster
16/05/03 23:22:40 INFO DiskBlockManager: Created local directory at C:\Users\admin\AppData\Local\Temp\blockmgr-e139fc75-b5c0-4c14-93d1-8743faef385b
16/05/03 23:22:40 INFO MemoryStore: MemoryStore started with capacity 2.4 GB
16/05/03 23:22:40 INFO SparkEnv: Registering OutputCommitCoordinator
16/05/03 23:22:40 INFO Utils: Successfully started service 'SparkUI' on port 4040.
16/05/03 23:22:40 INFO SparkUI: Started SparkUI at http://192.168.213.1:4040
16/05/03 23:22:41 INFO Executor: Starting executor ID driver on host localhost
16/05/03 23:22:41 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 56359.
16/05/03 23:22:41 INFO NettyBlockTransferService: Server created on 56359
16/05/03 23:22:41 INFO BlockManagerMaster: Trying to register BlockManager
16/05/03 23:22:41 INFO BlockManagerMasterEndpoint: Registering block manager localhost:56359 with 2.4 GB RAM, BlockManagerId(driver, localhost, 56359)
16/05/03 23:22:41 INFO BlockManagerMaster: Registered BlockManager
16/05/03 23:22:43 WARN : Your hostname, Lenovo-PC resolves to a loopback/non-reachable address: fe80:0:0:0:35c6:7e0e:841a:22b4%25, but we couldn't find any external IP address!
16/05/03 23:22:44 INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
16/05/03 23:22:44 INFO deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
16/05/03 23:22:44 INFO deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap
16/05/03 23:22:44 INFO deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition
16/05/03 23:22:44 INFO deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id
16/05/03 23:22:45 INFO SparkContext: Starting job: saveAsTextFile at ActionOperation.java:54
16/05/03 23:22:45 INFO DAGScheduler: Got job 0 (saveAsTextFile at ActionOperation.java:54) with 2 output partitions
16/05/03 23:22:45 INFO DAGScheduler: Final stage: ResultStage 0 (saveAsTextFile at ActionOperation.java:54)
16/05/03 23:22:45 INFO DAGScheduler: Parents of final stage: List()
16/05/03 23:22:45 INFO DAGScheduler: Missing parents: List()
16/05/03 23:22:45 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[2] at saveAsTextFile at ActionOperation.java:54), which has no missing parents
16/05/03 23:22:45 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 48.1 KB, free 48.1 KB)
16/05/03 23:22:45 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 16.6 KB, free 64.8 KB)
16/05/03 23:22:45 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:56359 (size: 16.6 KB, free: 2.4 GB)
16/05/03 23:22:45 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1006
16/05/03 23:22:45 INFO DAGScheduler: Submitting 2 missing tasks from ResultStage 0 (MapPartitionsRDD[2] at saveAsTextFile at ActionOperation.java:54)
16/05/03 23:22:45 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
16/05/03 23:22:45 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, partition 0,PROCESS_LOCAL, 2150 bytes)
16/05/03 23:22:45 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
16/05/03 23:22:45 INFO deprecation: mapred.output.dir is deprecated. Instead, use mapreduce.output.fileoutputformat.outputdir
16/05/03 23:22:45 INFO deprecation: mapred.output.key.class is deprecated. Instead, use mapreduce.job.output.key.class
16/05/03 23:22:45 INFO deprecation: mapred.output.value.class is deprecated. Instead, use mapreduce.job.output.value.class
16/05/03 23:22:45 INFO deprecation: mapred.working.dir is deprecated. Instead, use mapreduce.job.working.dir
16/05/03 23:22:46 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:278)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:300)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:293)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:639)
at org.apache.hadoop.fs.FilterFileSystem.setPermission(FilterFileSystem.java:468)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:456)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:424)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:905)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:798)
at org.apache.hadoop.mapred.TextOutputFormat.getRecordWriter(TextOutputFormat.java:123)
at org.apache.spark.SparkHadoopWriter.open(SparkHadoopWriter.scala:91)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1$$anonfun$13.apply(PairRDDFunctions.scala:1193)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1$$anonfun$13.apply(PairRDDFunctions.scala:1185)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:66)
at org.apache.spark.scheduler.Task.run(Task.scala:89)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:214)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
16/05/03 23:22:46 ERROR Executor: Exception in task 0.0 in stage 0.0 (TID 0)
java.lang.NullPointerException
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1010)
at org.apache.hadoop.util.Shell.runCommand(Shell.java:404)
at org.apache.hadoop.util.Shell.run(Shell.java:379)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:589)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:678)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:661)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:639)
at org.apache.hadoop.fs.FilterFileSystem.setPermission(FilterFileSystem.java:468)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:456)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:424)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:905)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:798)
at org.apache.hadoop.mapred.TextOutputFormat.getRecordWriter(TextOutputFormat.java:123)
at org.apache.spark.SparkHadoopWriter.open(SparkHadoopWriter.scala:91)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1$$anonfun$13.apply(PairRDDFunctions.scala:1193)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1$$anonfun$13.apply(PairRDDFunctions.scala:1185)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:66)
at org.apache.spark.scheduler.Task.run(Task.scala:89)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:214)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
16/05/03 23:22:46 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, partition 1,PROCESS_LOCAL, 2160 bytes)
16/05/03 23:22:46 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
16/05/03 23:22:46 WARN TaskSetManager: Lost task 0.0 in stage 0.0 (TID 0, localhost): java.lang.NullPointerException
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1010)
at org.apache.hadoop.util.Shell.runCommand(Shell.java:404)
at org.apache.hadoop.util.Shell.run(Shell.java:379)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:589)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:678)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:661)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:639)
at org.apache.hadoop.fs.FilterFileSystem.setPermission(FilterFileSystem.java:468)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:456)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:424)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:905)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:798)
at org.apache.hadoop.mapred.TextOutputFormat.getRecordWriter(TextOutputFormat.java:123)
at org.apache.spark.SparkHadoopWriter.open(SparkHadoopWriter.scala:91)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1$$anonfun$13.apply(PairRDDFunctions.scala:1193)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1$$anonfun$13.apply(PairRDDFunctions.scala:1185)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:66)
at org.apache.spark.scheduler.Task.run(Task.scala:89)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:214)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
16/05/03 23:22:46 ERROR TaskSetManager: Task 0 in stage 0.0 failed 1 times; aborting job
16/05/03 23:22:46 INFO TaskSchedulerImpl: Cancelling stage 0
16/05/03 23:22:46 INFO TaskSchedulerImpl: Stage 0 was cancelled
16/05/03 23:22:46 INFO DAGScheduler: ResultStage 0 (saveAsTextFile at ActionOperation.java:54) failed in 0.386 s
16/05/03 23:22:46 INFO Executor: Executor is trying to kill task 1.0 in stage 0.0 (TID 1)
16/05/03 23:22:46 INFO DAGScheduler: Job 0 failed: saveAsTextFile at ActionOperation.java:54, took 1.073280 s
Exception in thread "main" org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 1 times, most recent failure: Lost task 0.0 in stage 0.0 (TID 0, localhost): java.lang.NullPointerException
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1010)
at org.apache.hadoop.util.Shell.runCommand(Shell.java:404)
at org.apache.hadoop.util.Shell.run(Shell.java:379)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:589)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:678)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:661)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:639)
at org.apache.hadoop.fs.FilterFileSystem.setPermission(FilterFileSystem.java:468)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:456)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:424)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:905)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:798)
at org.apache.hadoop.mapred.TextOutputFormat.getRecordWriter(TextOutputFormat.java:123)
at org.apache.spark.SparkHadoopWriter.open(SparkHadoopWriter.scala:91)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1$$anonfun$13.apply(PairRDDFunctions.scala:1193)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1$$anonfun$13.apply(PairRDDFunctions.scala:1185)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:66)
at org.apache.spark.scheduler.Task.run(Task.scala:89)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:214)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1431)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1419)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1418)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1418)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:799)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:799)
at scala.Option.foreach(Option.scala:236)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:799)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:1640)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1599)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1588)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:48)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:620)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:1832)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:1845)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:1922)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1.apply$mcV$sp(PairRDDFunctions.scala:1213)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1.apply(PairRDDFunctions.scala:1156)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1.apply(PairRDDFunctions.scala:1156)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:150)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:111)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:316)
at org.apache.spark.rdd.PairRDDFunctions.saveAsHadoopDataset(PairRDDFunctions.scala:1156)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopFile$4.apply$mcV$sp(PairRDDFunctions.scala:1060)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopFile$4.apply(PairRDDFunctions.scala:1026)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopFile$4.apply(PairRDDFunctions.scala:1026)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:150)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:111)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:316)
at org.apache.spark.rdd.PairRDDFunctions.saveAsHadoopFile(PairRDDFunctions.scala:1026)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopFile$1.apply$mcV$sp(PairRDDFunctions.scala:952)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopFile$1.apply(PairRDDFunctions.scala:952)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopFile$1.apply(PairRDDFunctions.scala:952)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:150)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:111)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:316)
at org.apache.spark.rdd.PairRDDFunctions.saveAsHadoopFile(PairRDDFunctions.scala:951)
at org.apache.spark.rdd.RDD$$anonfun$saveAsTextFile$1.apply$mcV$sp(RDD.scala:1457)
at org.apache.spark.rdd.RDD$$anonfun$saveAsTextFile$1.apply(RDD.scala:1436)
at org.apache.spark.rdd.RDD$$anonfun$saveAsTextFile$1.apply(RDD.scala:1436)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:150)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:111)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:316)
at org.apache.spark.rdd.RDD.saveAsTextFile(RDD.scala:1436)
at org.apache.spark.api.java.JavaRDDLike$class.saveAsTextFile(JavaRDDLike.scala:507)
at org.apache.spark.api.java.AbstractJavaRDDLike.saveAsTextFile(JavaRDDLike.scala:46)
at com.ctsi.test.rddtest.ActionOperation.mySaveAsFile(ActionOperation.java:54)
at com.ctsi.test.rddtest.ActionOperation.main(ActionOperation.java:27)
Caused by: java.lang.NullPointerException
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1010)
at org.apache.hadoop.util.Shell.runCommand(Shell.java:404)
at org.apache.hadoop.util.Shell.run(Shell.java:379)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:589)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:678)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:661)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:639)
at org.apache.hadoop.fs.FilterFileSystem.setPermission(FilterFileSystem.java:468)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:456)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:424)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:905)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:798)
at org.apache.hadoop.mapred.TextOutputFormat.getRecordWriter(TextOutputFormat.java:123)
at org.apache.spark.SparkHadoopWriter.open(SparkHadoopWriter.scala:91)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1$$anonfun$13.apply(PairRDDFunctions.scala:1193)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1$$anonfun$13.apply(PairRDDFunctions.scala:1185)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:66)
at org.apache.spark.scheduler.Task.run(Task.scala:89)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:214)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
16/05/03 23:22:46 INFO SparkContext: Invoking stop() from shutdown hook
16/05/03 23:22:46 ERROR Executor: Exception in task 1.0 in stage 0.0 (TID 1)
java.lang.NullPointerException
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1010)
at org.apache.hadoop.util.Shell.runCommand(Shell.java:404)
at org.apache.hadoop.util.Shell.run(Shell.java:379)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:589)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:678)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:661)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:639)
at org.apache.hadoop.fs.FilterFileSystem.setPermission(FilterFileSystem.java:468)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:456)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:424)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:905)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:798)
at org.apache.hadoop.mapred.TextOutputFormat.getRecordWriter(TextOutputFormat.java:123)
at org.apache.spark.SparkHadoopWriter.open(SparkHadoopWriter.scala:91)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1$$anonfun$13.apply(PairRDDFunctions.scala:1193)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1$$anonfun$13.apply(PairRDDFunctions.scala:1185)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:66)
at org.apache.spark.scheduler.Task.run(Task.scala:89)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:214)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
16/05/03 23:22:46 INFO TaskSetManager: Lost task 1.0 in stage 0.0 (TID 1) on executor localhost: java.lang.NullPointerException (null) [duplicate 1]
16/05/03 23:22:46 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
16/05/03 23:22:46 INFO SparkUI: Stopped Spark web UI at http://192.168.213.1:4040
16/05/03 23:22:46 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
16/05/03 23:22:46 INFO MemoryStore: MemoryStore cleared
16/05/03 23:22:46 INFO BlockManager: BlockManager stopped
16/05/03 23:22:46 INFO BlockManagerMaster: BlockManagerMaster stopped
16/05/03 23:22:46 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
16/05/03 23:22:46 INFO SparkContext: Successfully stopped SparkContext
16/05/03 23:22:46 INFO ShutdownHookManager: Shutdown hook called
16/05/03 23:22:46 INFO ShutdownHookManager: Deleting directory C:\Users\admin\AppData\Local\Temp\spark-5d438e9b-97e2-4209-9a7c-23b8129c322d
看日志文件主要报了两个错误:
1.16/05/03 23:22:46 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.、
2.Caused by: java.lang.NullPointerException
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1010)
对于第一个错误,所示缺少了hadoop的winutils.exe,saveAsText方法只是比其他的方法多了保存到本地的操作而已,难道用了java的api还不能,还要hadoop的文件?看样子是了,对于第二个错误,说ProcessBuilder为空,这个操作时在启动executor的时候出现的错误。
下面的解决方法是在网上找的:
问题:找不到winutils.exe,hadoop.dll 文件。系统变量未设置HADOOP_HOME,
解决:系统环境变量设置HADOOP_HOME,(参数为window下的hadoop安装或存放目录),或者在配置job参数的方法中直接加一句代码指定路径地址:
System.setProperty("hadoop.home.dir", "E:/hadoop/hadoop-2.5.1");
把这两个文件拷贝到本地的hadoop下的bin目录下。(同下)
5.报错信息
Exception in thread "main" org.apache.hadoop.util.Shell$ExitCodeException:•
接上面错误,缺少winutils.exe,hadoop.dll文件,配好环境变量后,把hadoop2.2.0 版本的bin文件夹拷贝合并到系统中的hadoop版本中来,同时把bin下的hadoop.dll 复制到系统Windows下system32 文件夹下。 (hadoop2.5.1/2.5.2/2.6.0 均缺少这两个文件)
根本就没有这两个文件啊。难道是版本的问题?我的版本是2.6的版本
再找解决方法:
1)下载需要的文件 winutils.exe
2) 将此文件放置在某个目录下,比如C:\winutils\bin\中。
3)在程序的一开始声明:System.setProperty("hadoop.home.dir", "c:\\winutil\\")
下了一个文件,很开心的以为解决了,然并卵,错误依旧:
16/05/03 23:50:08 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:278)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:300)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:293)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:639)
at org.apache.hadoop.fs.FilterFileSystem.setPermission(FilterFileSystem.java:468)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:456)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:424)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:905)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:798)
at org.apache.hadoop.mapred.TextOutputFormat.getRecordWriter(TextOutputFormat.java:123)
at org.apache.spark.SparkHadoopWriter.open(SparkHadoopWriter.scala:91)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1$$anonfun$13.apply(PairRDDFunctions.scala:1193)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1$$anonfun$13.apply(PairRDDFunctions.scala:1185)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:66)
at org.apache.spark.scheduler.Task.run(Task.scala:89)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:214)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
16/05/03 23:50:08 ERROR Executor: Exception in task 0.0 in stage 0.0 (TID 0)
java.lang.NullPointerException
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1010)
at org.apache.hadoop.util.Shell.runCommand(Shell.java:404)
at org.apache.hadoop.util.Shell.run(Shell.java:379)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:589)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:678)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:661)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:639)
at org.apache.hadoop.fs.FilterFileSystem.setPermission(FilterFileSystem.java:468)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:456)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:424)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:905)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:798)
at org.apache.hadoop.mapred.TextOutputFormat.getRecordWriter(TextOutputFormat.java:123)
at org.apache.spark.SparkHadoopWriter.open(SparkHadoopWriter.scala:91)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1$$anonfun$13.apply(PairRDDFunctions.scala:1193)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1$$anonfun$13.apply(PairRDDFunctions.scala:1185)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:66)
at org.apache.spark.scheduler.Task.run(Task.scala:89)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:214)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
16/05/03 23:50:08 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, partition 1,PROCESS_LOCAL, 2160 bytes)
16/05/03 23:50:08 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
但是看到了生成了文件夹,但是没有内容。
哦,上面的那种方式是有效的,但是为什么要新建bin目录呢?
而且还不能直接指到bin目录,这个肯定跟hadoop扯上关系了。
代码设置:
System.setProperty("hadoop.home.dir", "E:\\hadoop\\");
成功目录:
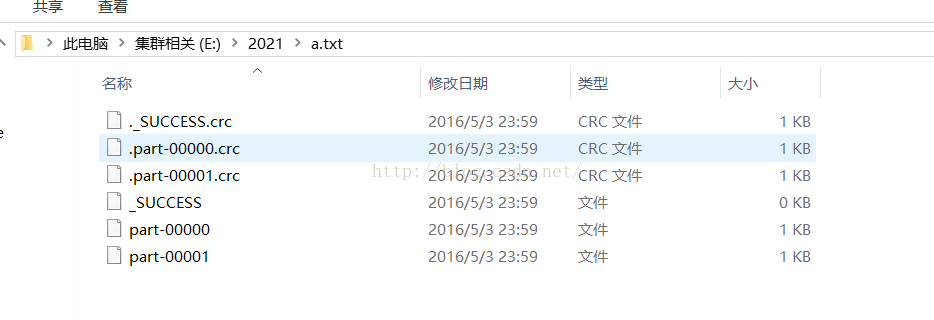
为什么会有两个文件呢?part-00000,part-00001
这个是因为我设置了分区数为2:
JavaRDD<Integer> rdds= sc.parallelize(list,2);
2
46
8
和
8
12
10
14
可以看到两个分区的内容,分区数据不等是我的数据不能平均分配吗?再试试
2
46
8
8
12
和
10
14
16
4
6
果然是平均分配的
看看成功的日志:
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
16/05/04 00:09:50 INFO SparkContext: Running Spark version 1.6.1
16/05/04 00:10:10 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/05/04 00:10:11 INFO SecurityManager: Changing view acls to: admin
16/05/04 00:10:11 INFO SecurityManager: Changing modify acls to: admin
16/05/04 00:10:11 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(admin); users with modify permissions: Set(admin)
16/05/04 00:10:14 INFO Utils: Successfully started service 'sparkDriver' on port 58891.
16/05/04 00:10:16 INFO Slf4jLogger: Slf4jLogger started
16/05/04 00:10:16 INFO Remoting: Starting remoting
16/05/04 00:10:17 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriverActorSystem@192.168.213.1:58904]
16/05/04 00:10:17 INFO Utils: Successfully started service 'sparkDriverActorSystem' on port 58904.
16/05/04 00:10:17 INFO SparkEnv: Registering MapOutputTracker
16/05/04 00:10:17 INFO SparkEnv: Registering BlockManagerMaster
16/05/04 00:10:17 INFO DiskBlockManager: Created local directory at C:\Users\admin\AppData\Local\Temp\blockmgr-3416c33b-d1b3-4676-b8e4-4cedb81974ac
16/05/04 00:10:17 INFO MemoryStore: MemoryStore started with capacity 2.4 GB
16/05/04 00:10:18 INFO SparkEnv: Registering OutputCommitCoordinator
16/05/04 00:10:19 INFO Utils: Successfully started service 'SparkUI' on port 4040.
16/05/04 00:10:19 INFO SparkUI: Started SparkUI at http://192.168.213.1:4040
16/05/04 00:10:19 INFO Executor: Starting executor ID driver on host localhost
16/05/04 00:10:19 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 58911.
16/05/04 00:10:19 INFO NettyBlockTransferService: Server created on 58911
16/05/04 00:10:19 INFO BlockManagerMaster: Trying to register BlockManager
16/05/04 00:10:19 INFO BlockManagerMasterEndpoint: Registering block manager localhost:58911 with 2.4 GB RAM, BlockManagerId(driver, localhost, 58911)
16/05/04 00:10:19 INFO BlockManagerMaster: Registered BlockManager
16/05/04 00:10:23 WARN : Your hostname, Lenovo-PC resolves to a loopback/non-reachable address: fe80:0:0:0:35c6:7e0e:841a:22b4%25, but we couldn't find any external IP address!
16/05/04 00:10:24 INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
16/05/04 00:10:24 INFO deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
16/05/04 00:10:24 INFO deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap
16/05/04 00:10:24 INFO deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition
16/05/04 00:10:24 INFO deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id
16/05/04 00:10:25 INFO SparkContext: Starting job: saveAsTextFile at ActionOperation.java:55
16/05/04 00:10:25 INFO DAGScheduler: Got job 0 (saveAsTextFile at ActionOperation.java:55) with 2 output partitions
16/05/04 00:10:25 INFO DAGScheduler: Final stage: ResultStage 0 (saveAsTextFile at ActionOperation.java:55)
16/05/04 00:10:25 INFO DAGScheduler: Parents of final stage: List()
16/05/04 00:10:25 INFO DAGScheduler: Missing parents: List()
16/05/04 00:10:25 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[2] at saveAsTextFile at ActionOperation.java:55), which has no missing parents
16/05/04 00:10:26 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 48.1 KB, free 48.1 KB)
16/05/04 00:10:26 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 16.6 KB, free 64.8 KB)
16/05/04 00:10:26 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:58911 (size: 16.6 KB, free: 2.4 GB)
16/05/04 00:10:26 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1006
16/05/04 00:10:26 INFO DAGScheduler: Submitting 2 missing tasks from ResultStage 0 (MapPartitionsRDD[2] at saveAsTextFile at ActionOperation.java:55)
16/05/04 00:10:26 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
16/05/04 00:10:26 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, partition 0,PROCESS_LOCAL, 2165 bytes)
16/05/04 00:10:26 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
16/05/04 00:10:26 INFO deprecation: mapred.output.dir is deprecated. Instead, use mapreduce.output.fileoutputformat.outputdir
16/05/04 00:10:26 INFO deprecation: mapred.output.key.class is deprecated. Instead, use mapreduce.job.output.key.class
16/05/04 00:10:26 INFO deprecation: mapred.output.value.class is deprecated. Instead, use mapreduce.job.output.value.class
16/05/04 00:10:26 INFO deprecation: mapred.working.dir is deprecated. Instead, use mapreduce.job.working.dir
16/05/04 00:10:26 INFO FileOutputCommitter: Saved output of task 'attempt_201605040010_0000_m_000000_0' to file:/E:/2022/a.txt/_temporary/0/task_201605040010_0000_m_000000
16/05/04 00:10:26 INFO SparkHadoopMapRedUtil: attempt_201605040010_0000_m_000000_0: Committed
16/05/04 00:10:27 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 915 bytes result sent to driver
16/05/04 00:10:27 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, partition 1,PROCESS_LOCAL, 2170 bytes)
16/05/04 00:10:27 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
16/05/04 00:10:27 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 727 ms on localhost (1/2)
16/05/04 00:10:27 INFO FileOutputCommitter: Saved output of task 'attempt_201605040010_0000_m_000001_1' to file:/E:/2022/a.txt/_temporary/0/task_201605040010_0000_m_000001
16/05/04 00:10:27 INFO SparkHadoopMapRedUtil: attempt_201605040010_0000_m_000001_1: Committed
16/05/04 00:10:27 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 915 bytes result sent to driver
16/05/04 00:10:27 INFO DAGScheduler: ResultStage 0 (saveAsTextFile at ActionOperation.java:55) finished in 1.204 s
16/05/04 00:10:27 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 422 ms on localhost (2/2)
16/05/04 00:10:27 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
16/05/04 00:10:27 INFO DAGScheduler: Job 0 finished: saveAsTextFile at ActionOperation.java:55, took 2.184585 s
16/05/04 00:10:27 INFO SparkUI: Stopped Spark web UI at http://192.168.213.1:4040
16/05/04 00:10:27 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
16/05/04 00:10:27 INFO MemoryStore: MemoryStore cleared
16/05/04 00:10:27 INFO BlockManager: BlockManager stopped
16/05/04 00:10:27 INFO BlockManagerMaster: BlockManagerMaster stopped
16/05/04 00:10:27 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
16/05/04 00:10:27 INFO SparkContext: Successfully stopped SparkContext
16/05/04 00:10:28 INFO RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.
16/05/04 00:10:28 INFO ShutdownHookManager: Shutdown hook called
16/05/04 00:10:28 INFO ShutdownHookManager: Deleting directory C:\Users\admin\AppData\Local\Temp\spark-ff707bd8-fcd7-48a9-abb7-575b73a937cd
分区为1的情况:
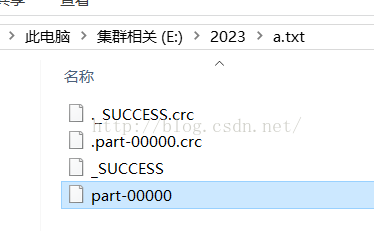
数据情况:
2
46
8
8
12
10
14
16
4
6
后记:
今天突然间以前运行的好好的程序又报这个错了:
16/11/19 01:12:42 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable E:\hadoop\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:278)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:300)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:293)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:76)
at org.apache.hadoop.mapred.FileInputFormat.setInputPaths(FileInputFormat.java:362)
at org.apache.spark.SparkContext$$anonfun$hadoopFile$1$$anonfun$33.apply(SparkContext.scala:1015)
at org.apache.spark.SparkContext$$anonfun$hadoopFile$1$$anonfun$33.apply(SparkContext.scala:1015)
at org.apache.spark.rdd.HadoopRDD$$anonfun$getJobConf$6.apply(HadoopRDD.scala:176)
at org.apache.spark.rdd.HadoopRDD$$anonfun$getJobConf$6.apply(HadoopRDD.scala:176)
at scala.Option.map(Option.scala:145)
at org.apache.spark.rdd.HadoopRDD.getJobConf(HadoopRDD.scala:176)
at org.apache.spark.rdd.HadoopRDD.getPartitions(HadoopRDD.scala:195)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:239)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:237)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:237)
at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:239)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:237)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:237)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:1929)
at org.apache.spark.rdd.RDD.count(RDD.scala:1157)
at machinelearning.MoviesLens$.main(MoviesLens.scala:14)
at machinelearning.MoviesLens.main(MoviesLens.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:147)
而且已经设置了E:\hadoop\bin\winutils.exe的目录了,这到底是为什么呢??















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









