







AfterShip 是一家服务国际电商赛道的 B2B SaaS 公司,自 2012 年成立,近几年业务持续高速增长,目前公司的 Go 应用监控系统每秒已超过百万数据点,其系统如何从 0 到 1 的演进过程,对大量公司和开发者都有参考意义。
在近日,AfterShip 与 GoCN 联合举办的 GopherDay 技术交流会上,AfterShip 高级 SRE 工程师 Alan Zhang 进行了《每秒百万数据点 Go 应用监控系统演进》的主题分享。

以下是根据现场演讲所编辑的技术文章,希望对大家有所帮助。
1. AfterShip 监控架构概览
在当前云原生时代,可观测技术建设可以帮助我们跟踪,了解,诊断业务应用的问题,所以我们的监控系统建设也是基于可观测技术去建设的,下图便是 AfterShip 的监控系统架构。
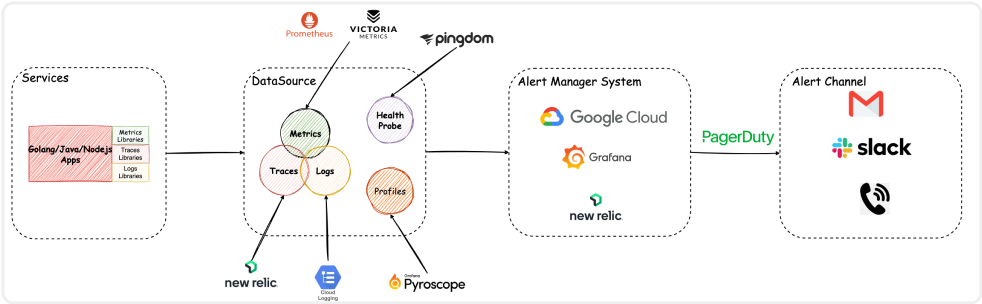
首先我们来看一下 Metrics 系统,由于 Metrics 系统是最重要的基石,它不仅为业务监控和系统监控提供基础数据,还是构建告警系统的核心,所以这对 Metrics 体系的稳定、高性能提出了更多的要求。
我们的 Metrics 系统主要是基于 Prometheus 来实现的,由于业务,指标爆发式的增长,面临了很多问题,所以 2023 年我们对 Metrics 系统进行了架构升级,指标查询速度,稳定性上得到了大幅性能提升,同时还降低了资源成本和运维成本,我会在后续的部分做详细的分享。
由于我们的业务服务是分布式的微服务架构, Traces 系统可以帮助我们了解远程方法调用的执行过程和耗时,对于排查问题和服务性能提供了很大的帮助。
我们主要是通过使用 NewRelic 来帮助我们实现链路的跟踪。New Relic 是美国的一家软件服务供应商的产品,它是一个全栈可观测平台,提供了基础设施监控,应用性能监控,链路跟踪等能力。
而对于可观测三大支柱之一的日志,我们的日志系统主要是使用 Google Cloud Platform 的产品 Cloud Logging。他提供实时的 EB 级的存储、搜索、分析、告警等服务,他的日志路由功能可以很方便地过滤,排除我们不需要的日志。这些能力很好的满足了我们的需求。
可观测三大支柱 Metrics,Traces,Logs 很好的帮助研发同学排查问题,但是研发同学有时还需要深入应用程序本身,找到性能瓶颈点。
那么三大支柱就不能提供更多的细节,所以这个时候他们就需要一种更有效的办法 —— Profiling,当然仅仅有 Profiling 还是不够的,可持续的 Profiling 才能更好的使用于现在的应用场景中。
我们在 2023 年引入了 Grafana Pyroscope 来提供 Continuous Profiling 能力,它可以为我们的 Go 应用提供火焰图和根据时间线对比应用性能,内存使用情况的能力。
监控告警部分我们主要有 3 大告警来源,Google Cloud Platform ,Grafana Alerting,NewRelic。都是通过 Pagerduty 来管理发送通道,按照级别发送到需要的通道中。
以上便是支撑我们整个监控系统的工具。
2. 如何监控 Go 应用?
下面我们一起来看看,在 AfterShip 我们是如何监控一个 Go 应用的。
下图便是我们的指标接入的流程:
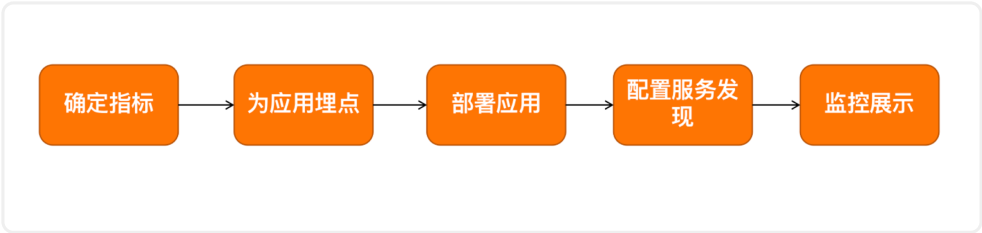
首先我们一般会确认相关的监控指标,通常有以下 3 大类:
Go 运行时指标(必备)
-
Goroutine 数量
-
GC Duration
-
Panic
应用层指标(必备)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









