







 本文深入探讨Spark RDD编程模型,解释RDD如何通过转换和行动来实现数据处理。介绍了Spark上下文环境、Driver和Executor的作用,以及计算抽象如Application、Job、Stage和Task的概念。此外,还详细说明了RDD在计算过程中的分区策略和资源分配。
本文深入探讨Spark RDD编程模型,解释RDD如何通过转换和行动来实现数据处理。介绍了Spark上下文环境、Driver和Executor的作用,以及计算抽象如Application、Job、Stage和Task的概念。此外,还详细说明了RDD在计算过程中的分区策略和资源分配。
RDD编程模型
在Spark中,RDD被表示为对象,通过对象上的方法调用来对RDD进行转换。经过一系列的transformations定义RDD之后,就可以调用actions触发RDD的计算,action可以是向应用程序返回结果(count, collect等),或者是向存储系统保存数据(saveAsTextFile等)。在Spark中,只有遇到action,才会执行RDD的计算(即延迟计算),这样在运行时可以通过管道的方式传输多个转换。
在使用Spark时,开发者需要编写一个Driver程序,它被提交到集群以调度运行Worker,如下图所示。Driver中定义了一个或多个RDD,并调用RDD上的action,Worker则执行RDD分区计算任务。

下面介绍几个术语:
- 上下文环境 SparkContext: Spark 的上下文环境,通过 SparkContext 对象可以创建RDDs
Driver 和 Executor 使用:
-
驱动程序 Dirver: 运行 Application 程序并且创建 SparkContext
-
执行单元 Executor: 执行 Task 的进程,每个 Application 都有各自独立的 Executors
- 一个Application会启动一个Driver
- 一个Driver负责跟踪管理该Application运行过程中所有的资源状态和任务状态
- 一个Driver会管理一组Executor
- 一个Executor只执行属于一个Driver的Task
Master 和 Worker 负责资源的管理
Spark的计算抽象
下面说说在Spark中经常用到的术语:可以把它们理解为计算抽象,因为它们的存在就是完整的运行spark程序的计算任务
-
Application: 用户编写的Spark程序,完成一个计算任务的处理。它是由一个Driver程序和一组运行于Spark集群上的Executor组成。
-
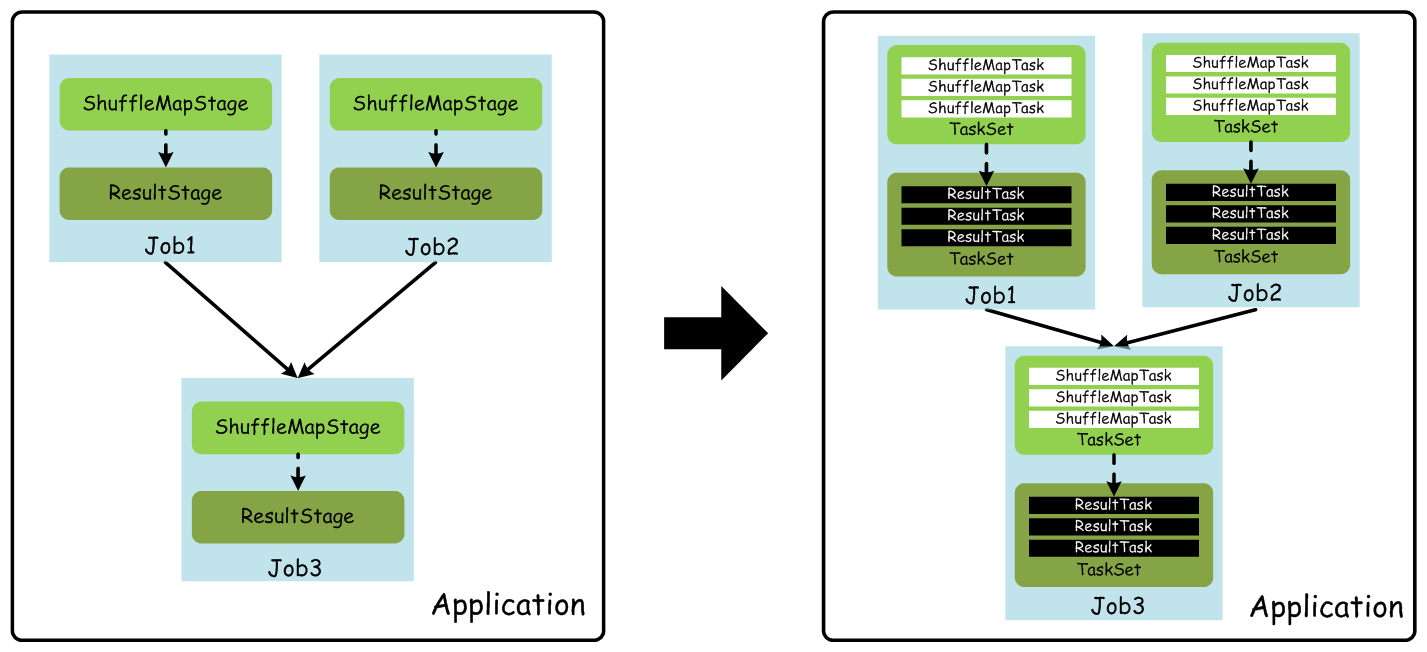
job: 用户程序中,每次调用Action时,逻辑上会生成一个Job,一个Job包含了多个Stage。
-
Stage: Stage包括两类:ShuffleMapStage和ResultStage,如果用户程序中调用了需要进行Shuffle计算的Operator,如groupByKey等,就会以Shuffle为边界分成ShuffleMapStage和ResultStage。
-
TaskSet: 基于Stage可以直接映射为TaskSet,一个TaskSet封装了一次需要运算的、具有相同处理逻辑的Task,这些Task可以并行计算,粗粒度的调度是以TaskSet为单位的。
-
Task: Task是在物理节点上运行的基本单位,Task包含两类:ShuffleMapTask和ResultTask,分别对应于Stage中ShuffleMapStage和ResultStage中的一个执行基本单元。
下图表示了这几个概念之间的基本关系:
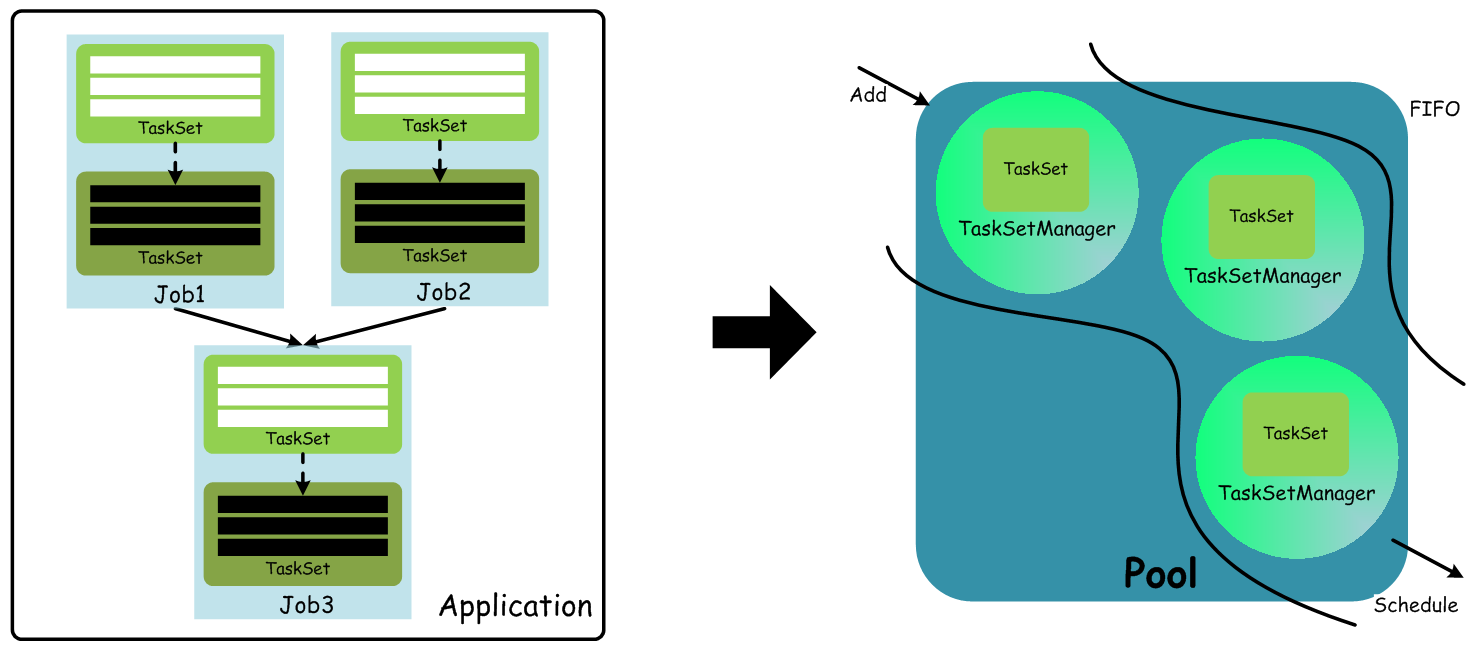
在 Standalone 模式下,默认采用的调度策略是FIFO,调度流程如下:
RDD相关概念间的关系
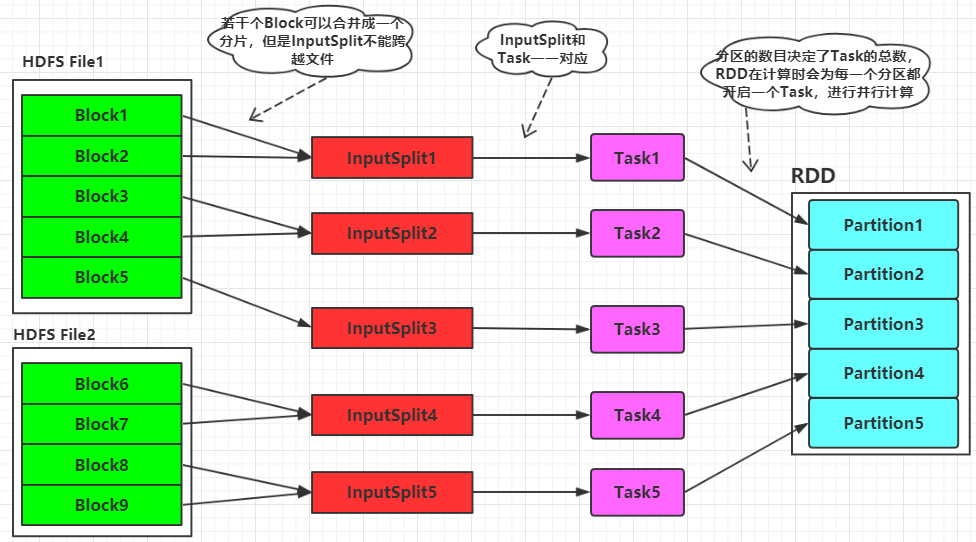
如上图所示,Spark的计算所需的数据可以来自于HDFS,这些数据文件在HDFS上是分块存存储的。当Spark读取这些文件作为输入时,会根据具体数据格式对应的InputFormat进行解析,一般是将若干个Block合并成一个输入分片,称为InputSplit,注意InputSplit不能跨越文件。然后将为这些输入分片生成具体的Task。InputSplit与Task是一一对应的关系。接下来
这些具体的Task每个都会被分配到集群上的某个节点的某个Executor去执行。
-
每个节点可以起一个或多个Executor。
-
每个Executor由若干core组成,每个Executor的每个core一次只能执行一个Task
-
每个Task执行的结果就是生成了目标RDD的一个partiton。
注意: 这里的core是虚拟的core而不是机器的物理CPU核,可以理解为就是Executor的一个工作线程。
-
Task被执行的并发度 = Executor数目 * 每个Executor核数
-
partition的数目:
- 对于数据读入阶段,例如sc.textFile,输入文件被划分为多少InputSplit就会需要多少初始Task
- 在Map阶段partition数目保持不变
- 在Reduce阶段,RDD的聚合会触发shuffle操作,聚合后的RDD的partition数目跟具体操作有关,例如repartition操作会聚合成指定分区数,还有一些算子是可配置的
RDD在计算的时候,每个分区都会起一个task,所以rdd的分区数目决定了总的的task数目。申请的计算节点(Executor)数目和每个计算节点核数,决定了你同一时刻可以并行执行的task。比如:
-
RDD有100个分区,那么计算的时候就会生成100个task,你的资源配置为10个计算节点,每个2个核,同一时刻可以并行的task数目为20,计算这个RDD就需要5个轮次
-
如果计算资源不变,你有101个task的话,就需要6个轮次,在最后一轮中,只有一个task在执行,其余核都在空转。
-
如果资源不变,你的RDD只有2个分区,那么同一时刻只有2个task运行,其余18个核空转,造成资源浪费。这就是在spark调优中,增大RDD分区数目,增大任务并行度的做法

















 1975
1975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









