







http://xiaogui9317170.javaeye.com/blog/317478
大型网站架构不得不考虑的10个问题
来自CSDN:http://news.csdn.net/n/20090115/122497.html
这里的大型网站架构只包括高互动性高交互性的数据型大型网站,基于大家众所周知的原因,我们就不谈新闻类和一些依靠HTML静态化就可以实现的架构了,我们以高负载高数据交换高数据流动性的网站为例,比如海内,开心网等类似的web2.0系列架构。我们这里不讨论是PHP还是JSP或者.NET环境,我们从架构的方面去看问题,实现语言方面并不是问题,语言的优势在于实现而不是好坏,不论你选择任何语言,架构都是必须要面对的。
这里讨论一下大型网站需要注意和考虑的问题
1、海量数据的处理
众所周知,对于一些相对小的站点来说,数据量并不是很大,select和update就可以解决我们面对的问题,本身负载量不是很大,最多再加几个索引就可以搞定。对于大型网站,每天的数据量可能就上百万,如果一个设计不好的多对多关系,在前期是没有任何问题的,但是随着用户的增长,数据量会是几何级的增长的。在这个时候我们对于一个表的select和update的时候(还不说多表联合查询)的成本的非常高的。
2、数据并发的处理
在一些时候,2.0的CTO都有个尚方宝剑,就是缓存。对于缓存,在高并发高处理的时候也是个大问题。在整个应用程序下,缓存是全局共享的,然而在我们进行修改的时候就,如果两个或者多个请求同时对缓存有更新的要求的情况下,应用程序会直接的死掉。这个时候,就需要一个好的数据并发处理策略以及缓存策略。
另外,就是数据库的死锁问题,也许平时我们感觉不到,死锁在高并发的情况下的出现的概率是非常高的,磁盘缓存就是一个大问题。
3、文件存贮的问题
对于一些支持文件上传的2.0的站点,在庆幸硬盘容量越来越大的时候我们更多的应该考虑的是文件应该如何被存储并且被有效的索引。常见的方案是对文件按照日期和类型进行存贮。但是当文件量是海量的数据的情况下,如果一块硬盘存贮了500个G的琐碎文件,那么维护的时候和使用的时候磁盘的Io就是一个巨大的问题,哪怕你的带宽足够,但是你的磁盘也未必响应过来。如果这个时候还涉及上传,磁盘很容易就over了。
也许用raid和专用存贮服务器能解决眼下的问题,但是还有个问题就是各地的访问问题,也许我们的服务器在北京,可能在云南或者新疆的访问速度如何解决?如果做分布式,那么我们的文件索引以及架构该如何规划。
所以我们不得不承认,文件存贮是个很不容易的问题
4、数据关系的处理
我们可以很容易的规划出一个符合第三范式的数据库,里面布满了多对多关系,还能用GUID来替换INDENTIFY COLUMN 但是,多对多关系充斥的2.0时代,第三范式是第一个应该被抛弃的。必须有效的把多表联合查询降到最低。
5、数据索引的问题
众所周知,索引是提高数据库效率查询的最方面最廉价最容易实现的方案。但是,在高UPDATE的情况下,update和delete付出的成本会高的无法想想,笔者遇到过一个情况,在更新一个聚焦索引的时候需要10分钟来完成,那么对于站点来说,这些基本上是不可忍受的。
索引和更新是一对天生的冤家,问题A,D,E这些是我们在做架构的时候不得不考虑的问题,并且也可能是花费时间最多的问题,
6、分布式处理
对于2.0网站由于其高互动性,CDN实现的效果基本上为0,内容是实时更新的,我们常规的处理。为了保证各地的访问速度,我们就需要面对一个绝大的问题,就是如何有效的实现数据同步和更新,实现各地服务器的实时通讯有是一个不得不需要考虑的问题。
7、Ajax的利弊分析
成也AJAX,败也AJAX,AJAX成为了主流趋势,突然发现基于XMLHTTP的post和get是如此的容易。客户端get或者post 到服务器数据,服务器接到数据请求之后返回来,这是一个很正常的AJAX请求。但是在AJAX处理的时候,如果我们使用一个抓包工具的话,对数据返回和处理是一目了然。对于一些计算量大的AJAX请求的话,我们可以构造一个发包机,很容易就可以把一个webserver干掉。
8、数据安全性的分析
对于HTTP协议来说,数据包都是明文传输的,也许我们可以说我们可以用加密啊,但是对于G问题来说的话,加密的过程就可能是明文了(比如我们知道的QQ,可以很容易的判断他的加密,并有效的写一个跟他一样的加密和解密方法出来的)。当你站点流量不是很大的时候没有人会在乎你,但是当你流量上来之后,那么所谓的外挂,所谓的群发就会接踵而来(从qq一开始的群发可见端倪)。也许我们可以很的意的说,我们可以采用更高级别的判断甚至HTTPS来实现,注意,当你做这些处理的时候付出的将是海量的database,io以及CPU的成本。对于一些群发,基本上是不可能的。笔者已经可以实现对于百度空间和qq空间的群发了。大家愿意试试,实际上并不是很难。
9、数据同步和集群的处理的问题
当我们的一台databaseserver不堪重负的时候,这个时候我们就需要做基于数据库的负载和集群了。而这个时候可能是最让人困扰的的问题了,数据基于网络传输根据数据库的设计的不同,数据延迟是很可怕的问题,也是不可避免的问题,这样的话,我们就需要通过另外的手段来保证在这延迟的几秒或者更长的几分钟时间内,实现有效的交互。比如数据散列,分割,内容处理等等问题
10、数据共享的渠道以及OPENAPI趋势
Openapi已经成为一个不可避免的趋势,从google,facebook,myspace到海内校内,都在考虑这个问题,它可以更有效的留住用户并激发用户的更多的兴趣以及让更多的人帮助你做最有效的开发。这个时候一个有效的数据共享平台,数据开放平台就成为必不可少的途径了,而在开放的接口的情况保证数据的安全性和性能,又是一个我们必须要认真思考的问题了。
http://xiaogui9317170.javaeye.com/blog/311602
规划 SOA 参考架构
2007-12-03 09:14 作者:萧百龄 出处:比特网 责任编辑:方舟
SOA 参考架构 (Reference Architecture)是一个框架,使各个项目都有一个遵从的依据,借以促进一致性、最佳实践典范,和标准化。参考架构并不受限于目前的 IT 现况,而应该针对一个经过深思熟虑的愿景目标,可以说是 IT 指导未来所有的新开发工作,借以实现该目标的参考依据。一般来说,2-3 年的规划,是一个比较合适的涵盖范围,既能提供足够的时间来达成面向服务的转型,而又不至于过于长远而虚幻。因此,参考架构提供了一个沟通目标愿景的方法,协助部门和角色各异的 IT 人员,逐渐朝向该目标会合。
高效的 SOA 需要采用新的方法来对待 IT 基础设施,并且根据个别企业的需求来量身定做,并将服务基础架构、共享的技术服务、安全服务,以及信息/数据、和遗留系统访问服务等,全部定义在内。
为了满足 SOA 的要求,所有公司都需要 SOA 参考架构和路线图,来指导部署一套能随时间演进、而逐渐丰富的工业级服务基础设施,同时指导对面向服务应用的开发和管理。
此外,企业也需要对参与 SOA 架构的各个个别系统的设计,进行监管,并在适当的地方,建立通用服务,透过协作来发挥更高的效率。对于这些举措,连接端点的标准化(通过建立定义清晰的契约和接口),是达成 IT 系统一致性的先决条件。
SOA 参考架构指导所有实施 SOA 的各个项目,能共同朝向企业级服务,和 SOA 基础架构标准方向的集中发展,尽早使企业从中获益。换句话说,参考架构规划的重点,在于开发一个特定于某个企业需要、切实可行的路线图,以填补当前和愿景目标之间的鸿沟;评估用于开发、部署和管理、监控的现有系统和技术,定义目标状态愿景,目标参考架构模型。
SOA 参考架构可说是指导 SOA 成功的蓝图 ,其作用包括:
促进 IT 与业务的紧密配合:参考架构的制定,以业务驱动力和 IT 目标为出发点,分析 SOA 解决方案能对这些驱动力带来多大的正面影响,进而为从目前 IT 现况演化到愿景架构,定出实现架构、相关规范及路线图。参考架构因此提供了从业务和 IT 目标,到实现架构间的可跟踪性,是业务与 IT 之间进行沟通的重要媒介,是企业实现业务灵活性、可管理性和变更规划的基础。
协助企业向重用、团队协作和资源共享的文化迁移:参考架构确立了 SOA 架构标准和技术部署的最佳实践,为日后各个 SOA 的实施项目,订立架构遵从性的度量标准和指标。
参考架构并非一成不变。在一个新的 SOA 策略与规划迭代中,SOA 的参考架构和规范标准,可能需要针对新的业务、IT 情况,和已实施的 SOA 项目中得到的反馈,进行调整,因此,SOA 参考架构不仅是 IT 模板,也是也描述 SOA 原则和标准的活文档。
我们可以将参考架构的内容,粗分为两大部分 :
对服务建立一套共同的词汇和做法,包括:
- 服务的正式定义 – 例如服务必须由契约 (contract)、接口 (interface),和实现 (implementation) 所组成
- 服务的分类(核心业务功能服务,数据服务,展现服务等),以及各类服务的设计原则和建议
- 接口标准 (JMS, RMI, HTTP 等),建议的接口样式(例如:尽量采用粗粒度、异步的服务调用模式),可靠性要求等
- 需要遵从的 WS-* 标准
- 安全策略
- 服务版本控制策略
- 服务和数据模型采用规范
- 服务生命周期定义
与服务基础设施,例如企业服务总线 (ESB)、业务流程管理 (BPM)、注册库 (Registry)、资产库 (Repository) 等相关的规范,包括:
- 必须支持什么样的部署配置
- 必须具备什么样的能力
各个部件的责任
部件之间的耦合关系和原则,应避免的事项,例如,展现服务和业务流程服务不可直接调用数据服务,而必须通过核心业务服务;换句话说,数据服务不可直接与展现服务和业务流程服务有耦合关系
各个部件应支持那些科技和标准(例如:SCA, SDO…)
有哪些安全顾虑需要考虑,如何管理权限
要采用哪些产品
由于在规划服务基础设施参考架构时,需要涵盖几类 SOA 参与者和干系人 (stakeholders)各自不同的顾虑,包括架构师、程序员、和负责部署、运营、监控的 IT 人员,我们可以采用一个针对服务基础设施参考架构调整过的 4+1 视图(如下),来协助我们分离顾虑,来将不同层面的规范和目标架构一一制定,通过逻辑、实现、部署,和进程等四个视图,配合最佳实践典范和模式,来对参考架构的各个层面,进行描述和规范,如附图。

图说:为 SOA 参考架构调整过的 4+1 视图,源于 Kruchten 在 1997 年发表的《Architectural Blueprints – the 4+1 view model of software architecture》

图说:服务基础设施参考架构的逻辑视图 (Logical View)
各个部件的责任
部件之间的耦合关系和原则,应避免的事项,例如,展现服务和业务流程服务不可直接调用数据服务,而必须通过核心业务服务;换句话说,数据服务不可直接与展现服务和业务流程服务有耦合关系
各个部件应支持那些科技和标准(例如:SCA, SDO…)
有哪些安全顾虑需要考虑,如何管理权限
要采用哪些产品
由于在规划服务基础设施参考架构时,需要涵盖几类 SOA 参与者和干系人 (stakeholders)各自不同的顾虑,包括架构师、程序员、和负责部署、运营、监控的 IT 人员,我们可以采用一个针对服务基础设施参考架构调整过的 4+1 视图(如下),来协助我们分离顾虑,来将不同层面的规范和目标架构一一制定,通过逻辑、实现、部署,和进程等四个视图,配合最佳实践典范和模式,来对参考架构的各个层面,进行描述和规范,如附图。

图说:为 SOA 参考架构调整过的 4+1 视图,源于 Kruchten 在 1997 年发表的《Architectural Blueprints – the 4+1 view model of software architecture》

图说:服务基础设施参考架构的逻辑视图 (Logical View)

图说:服务基础设施逻辑视图下的功能视图 (Functional View)

图说:服务基础设施参考架构的实现视图实例(场景为某电信客户的 provisioning service),描绘所计划采用的产品,以及如何通过这些产品间的交互,来实现解决方案。
各个部件的责任
http://xiaogui9317170.javaeye.com/blog/276135
|
厦门巨龙软件工程有限公司 卢琳生 2004-10-19 |
| 软件工程专家网 |
|
本文从程序的运行时结构和源代码的组织结构两个方面探讨了系统构架设计应考虑的各种因素,列举了系统构架设计文档应考虑的一些问题。
一、与构架有关的几个基本概念: 三、程序的运行时结构方面的考虑: 几点提示:算法优化及负载均衡是性能优化的方向。经常要调用的模块要特别注意优化。占用内存较多的变量在不用时要及时清理掉。需要下载的网页主题文件过大时应当分解为若干部分,让用户先把主要部分显示出来。 达到可移植性一定要注重标准化和开放性:只有广泛采用遵循国际标准,开发出开放性强的产品,才可以保证各种类型的系统的充分互联,从而使产品更具有市场竞争力,也为未来的系统移植和升级扩展提供了基础。 |
http://xiaogui9317170.javaeye.com/blog/276130
负载均衡--大型在线系统实现的关键(服务器集群架构的设计与选择)
作者:sodme
网站:http://blog.csdn.net/sodme/archive/2005/06/12/393165.aspx
要了解此篇文章中引用的本人写的另一篇文章,请到以下地址:
http://blog.csdn.net/sodme/archive/2004/12/12/213995.aspx
以上的这篇文章是早在去年的时候写的了,当时正在作休闲平台,一直在想着如何实现一个可扩充的支持百万人在线的游戏平台,后来思路有了,就写了那篇总结。文章的意思,重点在于阐述一个百万级在线的系统是如何实施的,倒没真正认真地考察过QQ游戏到底是不是那样实现的。
近日在与业内人士讨论时,提到QQ游戏的实现方式并不是我原来所想的那样,于是,今天又认真抓了一下QQ游戏的包,结果确如这位兄弟所言,QQ游戏的架构与我当初所设想的那个架构相差确实不小。下面,我重新给出QQ百万级在线的技术实现方案,并以此展开,谈谈大型在线系统中的负载均衡机制的设计。
从QQ游戏的登录及游戏过程来看,QQ游戏中,也至少分为三类服务器。它们是:
第一层:登陆/账号服务器(Login Server),负责验证用户身份、向客户端传送初始信息,从QQ聊天软件的封包常识来看,这些初始信息可能包括“会话密钥”此类的信息,以后客户端与后续服务器的通信就使用此会话密钥进行身份验证和信息加密;
第二层:大厅服务器(估且这么叫吧, Game Hall Server),负责向客户端传递当前游戏中的所有房间信息,这些房间信息包括:各房间的连接IP,PORT,各房间的当前在线人数,房间名称等等。
第三层:游戏逻辑服务器(Game Logic Server),负责处理房间逻辑及房间内的桌子逻辑。
从静态的表述来看,以上的三层结构似乎与我以前写的那篇文章相比并没有太大的区别,事实上,重点是它的工作流程,QQ游戏的通信流程与我以前的设想可谓大相径庭,其设计思想和技术水平确实非常优秀。具体来说,QQ游戏的通信过程是这样的:
1.由Client向Login Server发送账号及密码等登录消息,Login Server根据校验结果返回相应信息。可以设想的是,如果Login Server通过了Client的验证,那么它会通知其它Game Hall Server或将通过验证的消息以及会话密钥放在Game Hall Server也可以取到的地方。总之,Login Server与Game Hall Server之间是可以共享这个校验成功消息的。一旦Client收到了Login Server返回成功校验的消息后,Login Server会主动断开与Client的连接,以腾出socket资源。Login Server的IP信息,是存放在QQGame/config/QQSvrInfo.ini里的。
2.Client收到Login Server的校验成功等消息后,开始根据事先选定的游戏大厅入口登录游戏大厅,各个游戏大厅Game Hall Server的IP及Port信息,是存放在QQGame/Dirconfig.ini里的。Game Hall Server收到客户端Client的登录消息后,会根据一定的策略决定是否接受Client的登录,如果当前的Game Hall Server已经到了上限或暂时不能处理当前玩家登录消息,则由Game Hall Server发消息给Client,以让Client重定向到另外的Game Hall Server登录。重定向的IP及端口信息,本地没有保存,是通过数据包或一定的算法得到的。如果当前的Game Hall Server接受了该玩家的登录消息后,会向该Client发送房间目录信息,这些信息的内容我上面已经提到。目录等消息发送完毕后,Game Hall Server即断开与Client的连接,以腾出socket资源。在此后的时间里,Client每隔30分钟会重新连接Game Hall Server并向其索要最新的房间目录信息及在线人数信息。
3.Client根据列出的房间列表,选择某个房间进入游戏。根据我的抓包结果分析,QQ游戏,并不是给每一个游戏房间都分配了一个单独的端口进行处理。在QQ游戏里,有很多房间是共用的同一个IP和同一个端口。比如,在斗地主一区,前50个房间,用的都是同一个IP和Port信息。这意味着,这些房间,在QQ游戏的服务器上,事实上,可能是同一个程序在处理!!!QQ游戏房间的人数上限是400人,不难推算,QQ游戏单个服务器程序的用户承载量是2万,即QQ的一个游戏逻辑服务器程序最多可同时与2万个玩家保持TCP连接并保证游戏效率和品质,更重要的是,这样可以为腾讯省多少money呀!!!哇哦!QQ确实很牛。以2万的在线数还能保持这么好的游戏品质,确实不容易!QQ游戏的单个服务器程序,管理的不再只是逻辑意义上的单个房间,而可能是许多逻辑意义上的房间。其实,对于服务器而言,它就是一个大区服务器或大区服务器的一部分,我们可以把它理解为一个庞大的游戏地图,它实现的也是分块处理。而对于每一张桌子上的打牌逻辑,则是有一个统一的处理流程,50个房间的 50*100张桌子全由这一个服务器程序进行处理(我不知道QQ游戏的具体打牌逻辑是如何设计的,我想很有可能也是分区域的,分块的)。当然,以上这些只是服务器作的事,针对于客户端而言,客户端只是在表现上,将一个个房间单独罗列了出来,这样作,是为便于玩家进行游戏以及减少服务器的开销,把这个大区中的每400人放在一个集合内进行处理(比如聊天信息,“向400人广播”和“向2万人广播”,这是完全不同的两个概念)。
4.需要特别说明的一点。进入QQ游戏房间后,直到点击某个位置坐下打开另一个程序界面,客户端的程序,没有再创建新的socket,而仍然使用原来大厅房间客户端跟游戏逻辑服务器交互用的socket。也就是说,这是两个进程共用的同一个socket!不要小看这一点。如果你在创建桌子客户端程序后又新建了一个新的socket与游戏逻辑服务器进行通信,那么由此带来的玩家进入、退出、逃跑等消息会带来非常麻烦的数据同步问题,俺在刚开始的时候就深受其害。而一旦共用了同一个socket后,你如果退出桌子,服务器不涉及释放socket的问题,所以,这里就少了很多的数据同步问题。关于多个进程如何共享同一个 socket的问题,请去google以下内容:WSADuplicateSocket。
以上便是我根据最新的QQ游戏抓包结果分析得到的QQ游戏的通信流程,当然,这个流程更多的是客户端如何与服务器之间交互的,却没有涉及到服务器彼此之间是如何通信和作数据同步的。关于服务器之间的通信流程,我们只能基于自己的经验和猜想,得出以下想法:
1.Login Server与Game Hall Server之前的通信问题。Login Server是负责用户验证的,一旦验证通过之后,它要设法让Game Hall Server知道这个消息。它们之前实现信息交流的途径,我想可能有这样几条:a. Login Server将通过验证的用户存放到临时数据库中;b. Login Server将验证通过的用户存放在内存中,当然,这个信息,应该是全局可访问的,就是说所有QQ的Game Hall Server都可以通过服务器之间的数据包通信去获得这样的信息。
2.Game Hall Server的最新房间目录信息的取得。这个信息,是全局的,也就是整个游戏中,只保留一个目录。它的信息来源,可以由底层的房间服务器逐级报上来,报给谁?我认为就如保存的全局登录列表一样,它报给保存全局登录列表的那个服务器或数据库。
3.在QQ游戏中,同一类型的游戏,无法打开两上以上的游戏房间。这个信息的判定,可以根据全局信息来判定。
以上关于服务器之间如何通信的内容,均属于个人猜想,QQ到底怎么作的,恐怕只有等大家中的某一位进了腾讯之后才知道了。呵呵。不过,有一点是可以肯定的,在整个服务器架构中,应该有一个地方是专门保存了全局的登录玩家列表,只有这样才能保证玩家不会重复登录以及进入多个相同类型的房间。
在前面的描述中,我曾经提到过一个问题:当登录当前Game Hall Server不成功时,QQ游戏服务器会选择让客户端重定向到另位的服务器去登录,事实上,QQ聊天服务器和MSN服务器的登录也是类似的,它也存在登录重定向问题。
那么,这就引出了另外的问题,由谁来作这个策略选择?以及由谁来提供这样的选择资源?这样的处理,便是负责负载均衡的服务器的处理范围了。由QQ游戏的通信过程分析派生出来的针对负责均衡及百万级在线系统的更进一步讨论,将在下篇文章中继续。
在此,特别感谢网友tilly及某位不便透露姓名的网友的讨论,是你们让我决定认真再抓一次包探个究竟。
在网络应用中,“负载均衡”已经不能算是什么新鲜话题了,从硬件到软件,也都有了很多的方法来实现负载均衡。我们这里讨论的负载均衡,并不是指依靠DNS转向或其它硬件设备等所作的负载均衡,而是指在应用层所作的负载均衡。
一般而言,只有在大型在线系统当中才有必要引入负载均衡,那么,多大的系统才能被称为大型系统呢?比如动辄同时在线数十万的网络游戏,比如同时在线数在10万以上的WEB应用,这些我们都可以理解为大型系统,这本身就是一个宽泛的概念。
设计再好的服务器程序,其单个程序所能承载的同时访问量也是有限的,面对一个庞大且日益增长的网络用户群,如何让我们的架构能适应未来海量用户访问,这自然就牵涉到了负载均衡问题。支持百万级以上的大型在线系统,它的架构核心就是如何将“百万”这么大的一个同时在线量分摊到每个单独的服务器程序上去。真正的逻辑处理应该是在这最终的底层的服务器程序(如QQ游戏平台的游戏房间服务器)上的,而在此之前所存在的那些服务器,都可以被称为“引路者”,它们的作用就是将客户端一步步引导到这最终的负责真正逻辑的底层服务器上去,我们计算“百万级在线”所需要的服务器数量,也是首先考虑这底层的逻辑服务器单个可承载的客户端连接量。
比如:按上篇我们所分析QQ游戏架构而言,假设每个服务器程序最高支持2W的用户在线(假设一台机子只运行一个服务器程序),那么实现150万的在线量至少需要多少台服务器呢?如果算得简单一点的话,就应该是:150/2=75台。当然,这样算起来,可能并不能代表真正的服务器数量,因为除了这底层的服务器外,还要包括登录/账号服务器以及大厅服务器。但是,由于登录/账号服务器和大厅服务器,它们与客户端的连接都属于短连接(即:取得所需要信息后,客户端与服务器即断开连接),所以,客户端给这两类服务器带来的压力相比于长连接(即:客户端与服务器始终保持连接)而言就要轻得多,它们的压力主要在处理瞬间的并发访问上。
“短连接”,是实现应用层负载均衡的基本手段!!!如果客户端要始终与登录/账号服务器以及大厅服务器保持连接,那么这样作的分层架构将是无意义的,这也没有办法从根本上解决用户量不断增长与服务器数量有限之间的矛盾。
当然,短连接之所以可以被使用并能维护正常的游戏逻辑,是因为在玩家看不到的地方,服务器与服务器之间进行了大量的数据同步操作。如果一个玩家没有登录到登录服务器上去而是直接连接进了游戏房间服务器并试图进行游戏,那么,由于游戏房间服务器与大厅服务器和登录/账号服务器之间都会有针对于玩家登录的逻辑维护,游戏房间服务器会检测出来该玩家之前并没有到登录服务器进行必要的账号验证工作,它便会将玩家踢下线。由此看来,各服务器之间的数据同步,又是实现负载均衡的又一必要条件了。
服务器之间的数据同步问题,依据应用的不同,也会呈现不同的实现方案。比如,我们在处理玩家登录这个问题上。我们首先可以向玩家开放一些默认的登录服务器(服务器的IP及PORT信息),当玩家连接到当前的登录服务器后,由该服务器首先判断自己同时连接的玩家是不是超过了自定义的上限,如果是,由向与该服务器连接着的“登录服务器管理者”(一般是一个内部的服务器,不直接向玩家开放)申请仲裁,由“登录服务器管理者”根据当前各登录服务器的负载情况选择一个新的服务器IP和PORT信息传给客户端,客户端收到这个IP和PORT信息之后重定向连接到这个新的登录服务器上去,完成后续的登录验证过程。
这种方案的一个特点是,在面向玩家的一侧,会提供一个外部访问接口,而在服务器集群的内部,会提供一个“服务器管理者”及时记录各登录服务器的负载情况以便客户端需要重定向时根据策略选择一个新的登录接口给客户端。
采用分布式结构的好处是可以有效分摊整个系统的压力,但是,不足点就是对于全局信息的索引将会变得比较困难,因为每个单独的底层逻辑服务器上都只是存放了自己这一个服务器上的用户数据,它没有办法查找到其它服务器上的用户数据。解决这个问题,简单一点的作法,就是在集群内部,由一个中介者,提供一个全局的玩家列表。这个全局列表,根据需要,可以直接放在“服务器管理者”上,也可以存放在数据库中。
对于逻辑相对独立的应用,全局列表的使用机会其实并不多,最主要的作用就是用来检测玩家是不是重复登录了。但如果有其它的某些应用,要使用这样的全局列表,就会使数据同步显得比较复杂。比如,我们在超大无缝地图的MMORPG里,如果允许跨服操作(如跨服战斗、跨服交易等)的话,这时的数据同步将会变得异常复杂,也容易使处理逻辑出现不可预测性。
我认为,对于休闲平台而言,QQ游戏的架构已经是比较合理的,也可以称之为休闲平台的标准架构了。那么,MMORPG一般的架构是什么样的呢?
MMORPG一般是把整个游戏分成若干个游戏世界组,每个组内其实就是一个单独的游戏世界。而不同的组之间,其数据皆是相互独立的,并不象QQ休闲平台一样所有的用户都会有一个集中的数据存放点,MMORPG的游戏数据是按服务器组的不同而各自存放的。玩家在登录QQ游戏时,QQ游戏相关的服务器会自动为玩家的登录进行负载均衡,选择相对不忙的服务器为其执行用户验证并最终让用户选择进入哪一个游戏房间。但是,玩家在登录MMORPG时,却没有这样的自动负载均衡,一般是由玩家人为地去选择要进入哪一个服务器组,之所以这样,是因为各服务器组之间的数据是不相通的。其实,细致想来,MMORPG的服务器架构思想与休闲平台的架构思想有异曲同工之妙,MMORPG的思想是:可以为玩家无限地开独立的游戏世界(即服务器组),以满足大型玩家在线;而休闲平台的思想则是:可以为玩家无限地开游戏房间以满足大量玩家在线。这两种应用,可以无限开的都是“具有完整游戏性的游戏世界”,对于MMORPG而言,它的一个完整的游戏地图就是一个整体的“游戏世界”,而对于休闲平台,它的一个游戏房间就可以描述为一个“游戏世界”。如果MMORPG作成了休闲平台那样的全服皆通,也不是不可以,但随之而来的,就是要解决众多跨服问题,比如:好友、组队、帮派等等的问题,所有在传统MMORPG里所定义的这些玩家组织形式的规则可能都会因为“全服皆通”而改变。
架构的选择是多样性的,确实没有一种可以称得上是最好的所谓的架构,适合于当前项目的,不一定就适合于另一个项目。针对于特定的应用,会灵活选用不同的架构。但有一点,是可以说的:不管你如何架构,你所要作的就是--要以尽可能简单的方案实现尽可能的稳定、高效!
Web站点数据库分布存储浅谈
作者:heiyeluren
网址:http://blog.csdn.net/heiyeshuwu/archive/2007/11/18/1891639.aspx
【 前言 】
网 站在Web 2.0时代,时常面临迅速增加的访问量(这是好事情),但是我们的应用如何满足用户的访问需求,而且基本上我们看到的情况都是性能瓶颈都是在数据库上,这个不怪数据库,毕竟要满足很大访问量确实对于任何一款数据库都是很大的压力,不论是商业数据库Oracle、MS SQL Server、DB2之类,还是开源的MySQL、PostgreSQL,都是很大的挑战,解决的方法很简单,就是把数据分散在不同的数据库上(可以是硬件上的,也可以是逻辑上的),本文就是主要讨论如何数据库分散存储的的问题。
目前主要分布存储的方式都是按照一定的方式进行切分,主要是垂直切分(纵向)和水平切分(横向)两种方式,当然,也有两种结合的方式,达到更到的切分粒度。
1. 垂直切分 (纵向)数据是数据库切分按照网站业务、产品进行切分,比如用户数据、博客文章数据、照片数据、标签数据、群组数据等等每个业务一个独立的数据库或者数据库服务器。
2. 水平切分 (横向)数据是把所有数据当作一个大产品,但是把所有的平面数据按照某些Key(比如用户名)分散在不同数据库或者数据库服务器上,分散对数据访问的压力,这种方式也是本文主要要探讨的。
本 文主要针对的的 MySQL/PostgreSQL 类的开源数据库,同时平台是在 Linux/FreeBSD,使用 PHP/Perl/Ruby/Python 等脚本语言,搭配 Apache/Lighttpd 等Web服务器的平台下面的Web应用,不讨论静态文件的存储,比如视频、图片、CSS、JS,那是另外一个话题。
说明:下面将会反复提到的一个名次“节点”(Node),指的是一个数据库节点,可能是物理的一台数据库服务器,也可能是一个数据库,一般情况是指一台数据库服务器,并且是具有 Master/Slave 结构的数据库服务器,我们查看一下图片,了解这样节点的架构:
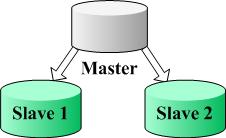 (图1)
(图1)
【 一、基于散列的分布方式 】
1. 散列方式介绍
基于散列(Hash)的分布存储方式,主要是依赖主要Key和散列算法,比如以用户为主的应用主要的角色就是用户,那么做Key的就可以是用户ID或者是用户名、邮件地址之类(该值必须在站点中随处传递),使用这个唯一值作为Key,通过对这个Key进行散列算法,把不同的用户数据分散在不同的数据库节点(Node)上。
我们通过简单的实例来描述这个问题:比如有一个应用,Key是用户ID,拥有10个数据库节点,最简单的散列算法是我们用户ID数模以我们所有节点数,余数就是对应的节点机器,算法:所在节点 = 用户ID % 总节点数,那么,用户ID为125的用户所在节点:125 % 10 = 5,那么应该在名字为5的节点上。同样的,可以构造更为强大合理的Hash算法来更均匀的分配用户到不同的节点上。
我们查看一下采用散列分布方式的数据结构图:
![]()
![]()
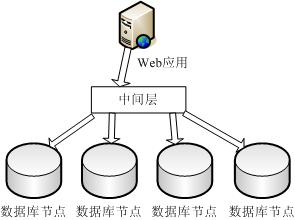
(图2)
2. 散列分布存储方式的扩容
我们知道既然定义了一个散列算法,那么这些Key就会按部就班的分散到指定节点上,但是如果目前的所有节点不够满足要求怎么办?这就存在一个扩容的问题,扩容首当其冲的就是要修改散列算法,同时数据也要根据散列算法进修迁移或者修改。
(1) 迁移方式扩容: 修改散列算法以后,比如之前是10个节点,现在增加到20个节点,那么Hash算法就是[模20],相应的存在一个以前的节点被分配的数据会比较多,但是新加入的节点数据少的不平衡的状态,那么可以考虑使用把以前数据中的数据按照Key使用新的Hash算法进行运算出新节点,把数据迁移到新节点,缺点但是这个成本相应比较大,不稳定性增加;好处是数据比较均匀,并且能够充分利用新旧节点。
(2) 充分利用新节点: 增加新节点以后,Hash算法把新加入的数据全部Hash到新节点上,不再往旧节点上分配数据,这样不存在迁移数据的成本。优点是只需要修改Hash算法,无须迁移数据就能够简单的增加节点,但是在查询数据的时候,必须使用考虑到旧Key使用旧Hash算法,新增加的Key使用新的Hash算法,不然无法查找到数据所在节点。缺点很明显,一个是Hash算法复杂度增加,如果频繁的增加新节点,算法将非常复杂,无法维护,另外一个方面是旧节点无法充分利用资源了,因为旧节点只是单纯的保留旧Key数据,当然了,这个也有合适的解决方案。
总结来说,散列方式分布数据,要新增节点比较困难和繁琐,但是也有很多适合的场合,特别适合能够预计到未来数据量大小的应用,但是普遍 Web2.0 网站都无法预计到数据量。
【 二、基于全局节点分配方式 】
1. 全局节点分配方式介绍
就是把所有Key信息与数据库节点之间的映射关系记录下来,保存到全局表中,当需要访问某个节点的时候,首先去全局表中查找,找到以后再定位到相应节点。全局表的存储方式一般两种:
(1) 采用节点数据库本身(MySQL/PostgreSQL)存储节点信息,能够远程访问,为了保证性能,同时配合使用 Heap(MEMORY) 内存表,或者是使用 Memcached 缓存方式来缓存,加速节点查找
(2) 采用 BDB(BerkeleyDB)、DBM/GDBM/NDBM 这类本地文件数据库,基于 key=>value 哈希数据库,查找性能比较高,同时结合 APC、Memcached 之类的缓存加速。
第一种存储方式是容易查询(包括远程查询),缺点是性能不太好(这个是所有关系型数据库的通病);第二种方式的有点是本地查询速度很快(特别是hash型数据库,时间复杂度是O(1),比较快),缺点是无法远程使用,并且无法在多台机器中间同步共享数据,存在数据一致的情况。
我们来描述实施 大概结构:假如我们有10个数据库节点,一个全局数据库用于存储Key到节点的映射信息,假设全局数据库有一个表叫做 AllNode ,包含两个字段,Key 和 NodeID,假设我们继续按照上面的案例,用户ID是Key,并且有一个用户ID为125的用户,它对应的节点,我们查询表获得:
| Key | NodeID |
| 13 | 2 |
| 148 | 5 |
| 22 | 9 |
| 125 | 6 |
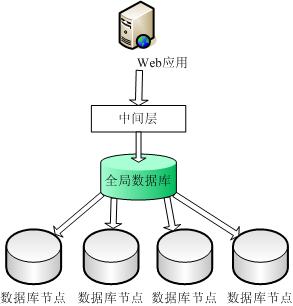
(图3)
2. 全局节点分布方式的扩容
全局节点分配方式同样存在扩容的问题,不过它早就考虑到这个问题,并且这么设计就是为了便于扩容,主要的扩容方式是两种:
(1) 通过节点自然增加来分配Key到节点的映射扩容
这种是最典型、最简单、最节约机器资源的扩容方式,大致就是按照每个节点分配指定的数据量,比如一个节点存储10万用户数据,第一个节点存储0-10w用户数据,第二个节点存储10w-20w用户数据,第三个节点存储20w-30w用户信息,依此类推,用户增加到一定数据量就增加节点服务器,同时把Key分配到新增加的节点上,映射关系记录到全局表中,这样可以无限的增加节点。存在的问题是,如果早期的节点用户访问频率比较低,而后期增加的节点用户访问频率比较高,则存在节点服务器负载不均衡的现象,这个也是可以想方案解决的。
(2) 通过概率算法来映射Key到节点的的扩容
这种方式是在既然有的节点基础上,给每个节点设定一个被分配到Key的概率,然后分配Key的时候,按照每个节点被指定的概率进行分配,如果每个节点平均的数据容量超过了指定的百分比,比如50%,那么这时候就考虑增加新节点,那么新节点增加Key的概率要大于旧节点。
一般情况下,对于节点的被分配的概率也是记录在数据库中的,比如我们把所有的概率为100,共有10个节点,那么设定每个节点被分配的数据的概率为10,我们查看数据表结构:
| NodeID | Weight |
| 1 | 10 |
| 2 | 10 |
| 3 | 10 |
现在新加入了一个节点,新加入的节点,被分配Key的几率要大于旧节点,那么就必须对这个新加入的节点进行概率计算,计算公式:10х+у=100, у>х,得出:у{10...90},х{1...9},x是单个旧节点的概率,旧节点的每个节点的概率是一样的,y是新节点的概率,按照这个计算公式,推算出新节点y的概率的范围,具体按照具体不同应用的概率公式进行计算。
【 三、存在的问题 】
现在我们来分析和解决一下我们上面两种分布存储方式的存在的问题,便于在实际考虑架构的时候能够避免或者是融合一些问题和缺点。
1. 散列和全局分配方式都存在问题
(1) 散列方式扩容不是很方便,必须修改散列算法,同时可能还需要对数据进行迁移,它的优点是从Key定位一个节点非常快,O(1)的时间复杂度,而且基本不需要查询数据库,节约响应时间。
(2) 全局分配方式存在的问题最明显的是单点故障,全局数据库down掉将影响所有应用。另外一个问题是查询量大,对每个Key节点的操作都必须经过全局数据库,压力很大,优点是扩容方便,增加节点简单。
2. 分布存储带来的搜索和统计问题
(1) 一般搜索或统计都是对所有数据进行处理,但因为拆分以后,数据分散在不同节点机器上,无法进行全局查找和统计。解决方案一是对主要的基础数据存储在全局表中,便于查找和统计,但这类数据不宜太多,部分核心数据。
(2) 采用站内搜索引擎来索引和记录全部数据,比如采用 Lucene 等开源索引系统进行所有数据的索引,便于搜索。 对于统计操作可以采用后台非实时统计,可采用遍历所有节点的方式,但效率低下。
3. 性能优化问题
(1) 散列算法,节点概率和分配等为了提高性能都可以使用编译语言开发,做成lib或者是所有php扩展形式。
(2) 对于采用 MySQL 的情况,可以采用自定义的数据库连接池,采用 Apache Module 形式加载,能够自由定制的采用各种连接方式。
(3) 对于全局数据或都频繁访问的数据,可以采用APC、Memcache、DBM、BDB、共享内存、文件系统等各种方式进行缓存,减少数据库的访问压力。
(4) 采用数据本身的强大处理机制,比如 MySQL5 的表分区或者是 MySQL5 的Cluster 。另外建议在实际架构中采用InnoDB表引擎作为主要存储引擎,MyISAM作为一些日志、统计数据等场合,不论在安全、可靠性、速度都有保障。
【 总结 】
本文泛泛的分析了在网站项目(特别是Web2.0)中关于数据库分布存储的一些方式方法,基本上上面提到的两种分布方案笔者都经过实验或者是使用过类似成型的项目,所以在实践性方面是有保障的,至于在具体实施过程中,可以按照具体的应用和项目进行选择性处理,这样,让你的网站速度飞快,用户体验一流。同时本文有些概念和描述不一定准确,如果有不足之处,请谅解并且提出来,不胜感谢。另外,如果有更好的方案或者更完善的解决方式,非常希望能够分享一下,本文更希望起到抛砖引玉的作用。(转载本文,敬请注明出处为:http://blog.csdn.net/heiyeshuwu,谢谢! :-) )
http://xiaogui9317170.javaeye.com/blog/275575
大型Web2.0站点构建技术初探
作者:heiyeshuwu
网址:http://blog.csdn.net/heiyeshuwu/archive/2007/11/18/1890793.aspx
一、 web2.0网站常用可用性功能模块分析
二、 Flickr的幕后故事
三、 YouTube 的架构扩展
四、 mixi.jp:使用开源软件搭建的可扩展SNS网站
五、 Technorati的后台数据库架构
六、 通过了解MySpace的六次重构经历,来认识分布式系统到底该如何创建
七、 从LiveJournal后台发展看大规模网站性能优化方法
八、 说说大型高并发高负载网站的系统架构
一、 web2.0 网站常用可用性功能模块分析
Web 2.0网站是指将传统的网站构架(平台、内容源、用户、传播方式等)转化到以用户为核心的网站构架上来,包括一系列体现web2.0概念的元素、定位和创意。web2.0网站在构架上须体现两大宗旨,即强大的后台系统和简单的前台页面,也即提供良好的用户体验,体现以人为本,技术服务人类的宗旨。
web2.0网站常用功能块通常包括以下几大项:
1. Tag 标签功能块
Tag(中文叫做"标签") 是一种新的组织和管理在线信息的方式。它不同于传统的、针对文件本身的关键字检索,而是一种模糊化、智能化的分类。
网页使用Tag标签的好处:
为页面设置一个或者多个Tag标签可以引导读者阅读更多相关文章,为别人带去流量同理也为自己带来流量。
可以帮助读者及时了解一些未知的概念和知识点,提高用户体验。
Tag是人的意志和趋向的体现,Tag可以帮助你找到兴趣相投的人。
基于以上优势,Tag标签代替了传统的分类法,成为web2.0网站使用率最高的功能块(与其说是功能块倒不如说是一种内容导航和内容组织形式)。
一句话:Tag标签是一种更灵活的分类方法,功能在于引导,特点是无处不在,体现智能性、模糊性和趋向性。
2. RSS 订阅功能块
RSS是在线共享内容的一种简易方式(也叫聚合内容,Really Simple Syndication)。通常在时效性比较强的内容上使用RSS订阅能更快速获取信息,网站提供RSS输出,有利于让用户获取网站内容的最新更新。网络用户可以在客户端借助于支持RSS的聚合工具软件(例如SharpReader,NewzCrawler、FeedDemon),在不打开网站内容页面的情况下阅读支持RSS输出的网站内容。
RSS订阅的方式:
订阅到客户端软件如周伯通、遨游浏览器RSS阅读、Foxmail RSS阅读等,此方式使用者较多
订阅到在线阅读(聚合类)门户网站如Google Reader,Yahoo Reader,抓虾、Gougou等,省去了安装RSS阅读器的麻烦
订阅到在线单用户聚合器如Lilina等,比较灵活
RSS订阅功能的最大好处是定向投递,也就是说RSS机制更能体现用户的意愿和个性,获取信息的方式也最直接和简单,这是RSS订阅功能备受青睐的一大主要原因。
3. 推荐和收藏功能块
说到推荐功能,不仅web2.0网站在大量使用,传统的以cms平台为代表的内容模式的网站也在大量使用,推荐功能主要是指向一些网摘或者聚合类门户网站推荐自己所浏览到的网页。当然,一种变相的推荐就是阅读者的自我收藏行为,在共享的模式下也能起到推荐的作用。
比较有名的推荐目标有以del.icio.us为代表的网摘类网站包括国内比较有名气的365key、和讯网摘、新浪vivi、天极网摘等。这里值得一提的是前段时间曾涌现了大批网摘类网站,但他们坚持活下来的好像没有几个了,推荐使用前面提到的这几个网摘门户,人气基本上是使最旺的。
4. 评论和留言功能块
web2.0强调参与性,强调发挥用户的主导作用,这里的参与性除了所谓的订阅、推荐功能外更多地体现在用户对内容的评价和态度,这就要靠评论功能块来完成。一个典型的web2.0网站或者说一个能体现人气的web2.0网站都会花大量篇幅来体现用户的观点和视觉。这里尤其要提到web2.0中的带头老大web blog,评论功能已经成为博客主人与浏览者交流的主要阵地,是体现网站人气的最直观因素。
评论功能块应用在博客系统中实际上已经和博客内容相分离,而更好的应用恰恰是一些以点评为主的web2.0网站比如豆瓣、点评网等,这里的评论功能块直接制造了内容也极大地体现了网站的人气,所以说评论功能块是web2.0网站最有力的武器。
5. 站内搜索功能块
搜索是信息来源最直接的方式之一,无论你的网站是否打上web2.0的烙印,搜索对于一个体系庞大、内容丰富的大型网站都是非常必要的。Tag 标签在某种程度上起到搜索的作用,它能够有效聚合以此Tag为关键词的内容,但这种情况的前提是此Tag标签对浏览者是可见的,也就是说当Tag标签摆在浏览者的眼前时才成立,而对于那些浏览者想要的信息却没有Tag标签来引导时搜索就是达到此目的的最好方法。
对于web2.0网站,站内搜索以标题或者Tag为搜索域都能起到好的效果,但本人不建议使用内容搜索域,因为这不符合搜索的高效性原则。同时,具有突出关键词的内容往往都可以用Tag标签来引导,因此使用内容域来搜索实际上是一种浪费服务器资源的行为,而且搜索结果的准确性将大打折扣。
6. 群组功能块
我为什么要把群组作为web2.0网站的功能块来分析呢,因为群组是web2.0网站的一大特点,也是web2.0所要体现的服务宗旨所在。一个web2.0网站,博客也好、播客也好、点评也好,抑或是网摘、聚合门户,他们都强调人的参与性。物以类聚、人以群分,每个参与者都有自己的兴趣趋向,web2.0网站的另一主要功能就是帮助这些人找到同样兴趣的人并形成一个活跃的群体,这是web2.0网站的根本。
总结:web2.0网站倡导的是集体创作、共享资源,靠的是人气,体现的是参与性,一个没有参与性的web2.0网站都不足以成为web2.0。以上提到的这几个功能块就是以吸引用户参与和引导用户参与为目的的,真正的web2.0不是什么深奥的东西,只有一点,那就是如何让浏览者沸腾起来。
http://xiaogui9317170.javaeye.com/blog/275568
闲谈 Web 图片服务器
网址: http://www.dbanotes.net/web/web_image_server.html
现在很多中小网站(尤其是 Web 2.0 站点) 都允许用户上传图片,如果前期没有很好的规划,那么随着图片文件的增多,无论是管理还是性能上都带来很多问题。就自己的一点理解,抛砖引玉,以期能引出更具价值的信息。
事关图片的存储
把图片存储到什么介质上? 如果有足够的资金购买专用的图片服务器硬件或者 NAS 设备,那么简单的很;如果有能力自己开发单独存储图片的文件系统,那么也不用接着往下看了。
如果上述条件不具备,只想在普通的硬盘上存储,首先还是要考虑一下物理硬盘的实际处理能力。是 7200 转的还是 15000 转的,实际表现差别就很大。是选择 ReiserFS 还是 Ext3 ,怎么也要测试一下吧? 创建文件系统的时候 Inode 问题也要加以考虑,选择合适大小的 inode size ,在空间和速度上做取舍,同时防患于未然,注意单个文件系统下文件个数别达到极限。
独立,独立的服务器
无论从管理上,还是从性能上看,只要有可能,尽量部署独立的图片服务器。这几乎成为常识了(不过在我做过面向 Web 的项目之前就这个问题也被人笑话过)。具备独立的图片服务器或者服务器集群后,在 Web 服务器上就可以有针对性的进行配置优化。比如采用传说中更有效率的 Lighttpd 。
如果不想在几台机器间同步所有图片,只用 NFS 模式共享一下即可。注意软、硬连接可能带来的问题,以及 NFS 特定的传输速度。
独立,独立的域名
如果大部分 Web 页面必须要载入很多图片,那么需要注意 IE 浏览器的连接数 问题(参见对该问题的测试 )。
前几天有个朋友在线上问我,"一些大网站,图片服务器为什么都用另外一个域名? 比如yahoo.com 图片服务器用了 yimg.com 的域名?" ,粗糙一点的答案:除了管理方便,便于CDN 同步处理,上面说的 IE 连接数限制也是个考虑因素吧(其他原因我也不知,有请 Yahoo!的同学发言) 【还有一个我没考虑到的是 Cookie 的因素,参加楼下高春辉 的留言】
雅虎 Web 优化 14 条
关于雅虎 YSlow 工具倡导的 优化 14 条规则 ,建议每个 Web 维护人员必须倒背如流,当然也应该辩证来看--介绍这 14 条规则的页面本身也只能得到 70 多分...其中的第九条和上面说的独立域名之间多少有些矛盾。实际情况要根据自己的 Benchmark 与具体需求而确定了。
有效利用客户端 Cache
很多网站的 UI 设计人员为了达到某些视觉效果,会在一些用户需要频繁访问的页面模块上应用大量的图片。这样的情况,研究表明 ,对于用户粘度比较高的站点, 在Web 服务器上对这一类对象设置 Expires Header 就是十分有必要的,大量带宽就这么节省下来,费用也节省了下来。顺便说一下,对于验证码这样的东西,要加个简单的规则过滤掉。
服务器端的 Cache
在国内,CDN 也是有钱才能玩得起。而类似 Amazon S3 这样的一揽子存储服务,国内还没有出现。所以,充分利用服务器端的 Cache 也是有必要的。Squid 作为反向代理服务器,缓冲图片效果应该说尚可,新浪技术团队贡献的 Ncache 据评测,效果更佳。
高解析图片问题
如果网站存在大量高解析度的图片,那么有必要考虑部署 IIPImage 或者类似的软件。
运营问题
很多比较有规模的网站对于用户上传的图片不做任何处理,结果页面上还能看到很多 BMP 格式的图片(个人觉得任何网站出现 BMP 格式的图片都是可耻的)...这完全是运营上的策略之误了。找个程序员投入一点时间写个图片处理模块,对那些"截屏"得来的图片做个转换,投入成本可能远比存储上的开销小,而用户再访问该图片,质量未必能有什么损失,浏览速度无疑好多了。哪种处理方式更让人接受,不言而喻。
--EOF--
图片处理工具的选择
可能大多数网站都是选择 ImageMagick 做为基础库,不过这里也有一篇 GraphicsMagick 1.2 vs ImageMagick 6.3.6 Benchmark Report ,如果图片处理量巨大,性能问题又怎能不考虑?
http://xiaogui9317170.javaeye.com/blog/275561
性能扩展问题要趁早
网址: http://www.dbanotes.net/arch/scaling_an_early_stage_startup.html
与国内的 Web 2.0 Startup 技术人员相比,国外技术人员更乐于分享。分享也是一种更好的宣传手段,如果不是看到了这篇 Scaling an early stage startup , 或许我就不会知道这位 Mark Maunder (他还有个中文名字:马孟德) 以及他的 FeedJet 。
一般来说,一个刚刚发布的 Web 应用,因为用户量并不多,性能问题可能并不是很明显。可一旦宣传展开,用户增长或许不是线性的而是暴增(从几十个到几万个,相比之下怎不是暴增?),这时候如果遇到性能问题,毫无疑问会影响初期用户的信任。
Maunder 文档中列举了一个扩展过程,相信这些例子也是他实际遇到的。毕竟 Startup 都是一两个人打通关,不可能所有技术都面面俱到的精通。下面记录一点。
错误的设置
数据库服务器的参数配置问题:导致 MySQL 消耗了大量资源。Apache Keepalive 的设置为不合理,修改为 off。我想这个前提应该还是要选择自己最擅长的技术路线。如果错误的选择另一条不熟悉的技术路线,那么遇到技术时解决问题的速度怕是更让用户恼火。对于 Apache 还应该知道 Httpd.Worker 比 Prefork 消耗更多内存 (httperf 来进行 Benchmark) ,内存也是蛮贵的。
尽可能的缓存动态内容
尽可能的利用数据库的 Cache,利用其他 Cache 工具,如 MemCacheD ,来减轻对磁盘的 IO 压力。为了节省成本,很多站点都是用的低速大容量的磁盘,所以,充分利用 Cache 是一个网站成功的必然条件。这样的软件BerkeleyDB 的最高事务处理记录是 90000 事务/秒。
剥离图片与CSS 到单独的服务器
说白了,也是为了减轻磁盘的压力。现在很多 Web 2.0 站点都把图片放到 Amazon S3 上,省心了不少。当然,国内还没这样的服务。
阻止内容引用"窃贼"
现在连那些大站点都在阻止图片被第三方引用 ,小站点更要提防被大站引用,很容易耗光网站的容量。另外一个要注意的是网络爬虫的频率。
在线观看这篇 Scaling an early stage startup 。顺便说一下,最近在 Scribd 上看到了不少有意思的文档。
http://blog.yening.cn/2007/03/25/226.html#more-226
主题:大型、高负载网站架构和应用初探
时间:30-45分钟
开题:163,sina,sohu等网站他们有很多应用程序都是PHP写的,为什么他们究竟是如何能做出同时跑几千人甚至上万同时在线应用程序呢?
挑选性能更好web服务器
单台 Apache web server 性能的极限
选用性能更好的web server TUX,lighttpd,thttpd …
动,静文件分开,混合使用
应用程序优化,Cache的使用和共享
常见的缓存技术
生成静态文件
对象持久化 serialize & unserialize
Need for Speed ,在最快的地方做 cache
Linux 系统下的 /dev/shm
tmpfs/ramdisk
php内置的 shared memory function /IPC
memcached
MySQL的HEAP表
多台主机共享cache
NFS,memcached,MySQL 优点和缺点比较
MySQL数据库优化
配置 my.cnf,设置更大的 cache size
利用 phpMyAdmin 找出配置瓶颈,榨干机器的每一点油
集群(热同步,mysql cluster)
集群,提高网站可用性
最简单的集群,设置多条A记录,DNS轮询,可用性问题
确保高可用性和伸缩性能的成熟集群解决方案
通过硬件实现,如路由器,F5 network
通过软件或者操作系统实现
基于内核,通过修改TCP/IP数据报文负载均衡,并确保伸缩性的 LVS以及 确保可用性守护进程ldirectord
基于 layer 7,通过URL分发的 HAproxy
数据共享问题
NFS,Samba,NAS,SAN
案例
解决南北互通,电信和网通速度问题
双线服务器
CDN
根据用户IP转换到就近服务器的智能DNS,dnspod …
Squid 反向代理,(优点,缺点)
案例
--------------------------------------------------------------------------------
附记:
pea上海的负责人h058在3月1日就邀请我希望我在pea上能说点什么,虽然我觉得我还是算健谈,但是觉得需要在如此正规的场合做演讲我还是真没有经验的,就连ppt我都不会做。一开始h058叫我说说linux下svn的部署,但是我觉得这个题目太浅了,也没有什么花头可以说。于是就想说点其它的。正好这段时间自己对服务器部署方面和应用程序优化这方面非常感兴趣,也想认真归纳了一下,于是就敲定这个题目了。
写大纲非常快10号左右基本上要说的话题都定下来了,虽然要说的东西基本上都非常熟悉如MySQL,Apache,包括集群的两个应用LVS和Haproxy自己也亲自做过试验,但是还是考虑到演讲的过程中会有些朋友提出一些比较刁难的问题,自己不懂,于是还是做了认认真真地对每个细节做足了功课,并且在每天睡醒地时候自己默默地在脑子里面像电影那样过一片。
3月24日,交大惠谷创业中心,shopex 407 培训教室….. PEA Shanghai 第七次聚会开始,与会人数约30人,还是10多名php的培训学员.
一开始是无喱头同学演讲的”PHPCMS系统的设计”,可能是对与会人员参与的情况了解不足,在系统宏观讲解和一些程序处理细节上觉得重点没有突出,到处着墨,洋洋洒洒18页Word文档,近1小时的演讲我已经听得已经云里雾里了,环顾四周,身边来培训php的一位小mm已经在偷偷睡觉了…..
15:55 分,无喱头同学觉得自己说得实在有点深了,主动提出中止演讲,休息十分钟,到我上场。
演讲意外的顺利,35分钟,从开题到留homework,行云流水,一气呵成,连水都没有喝一口,其中加入了不少极兴发挥,那时候觉得情绪非常激昂,浑身充满力量,唯一不爽的就是喉咙有点痛,呵呵:)
当我宣布“好好学习 天天向上”演讲结束后,同学们爆出热烈地掌声,那时,我深深地吐了一口气,压在心里的多日的大石终于落下来了,演讲看起来非常成功。
在演讲的过程中,我发现刚才睡觉的小MM居然也在聚集汇神地听我说话,让我值得感动的是发现还有不少同学在记笔记,没有人打瞌睡,结束还是很多人问我拿ppt。我问马哥我说得如何,马哥评价说“条例清晰,思路明确,语速平稳,真的不错!”,h058也称赞道我把现场的气氛调动起来了。嗯,那基本上可以肯定这次演讲还是做得不错了,自己给自己打分的话,88分!
回想一下,其实还觉得有一些不足的,觉得语速还是偏快了,没有抑扬顿挫感觉。并且声音太大,弄得自己喉咙不舒服。情绪还不是太稳定,稍微有点激动了。还有不知道是大家全都熟悉我说的话题还是我说得很透彻,基本上没有人提出问题。而我觉得好一个好的讲师,应该能调动大家的积极性,让大家一起参与话题的讨论中来,这点看来还需要继续锻炼。
通过这次演讲,发现自己在做一些即兴发挥的话题还有演讲方面等还是有点天赋和潜力可挖,以后一定要多多参加锻炼。并总结出要将一个演讲做好,要准备以下几点:
1) 精心的准备(包括选题和对听众的了解)
2) 稳定的心态和平稳的情绪
3) 热诚,全付身心的投入
4) 平时语言和谈吐技巧的积累
5) 想办法让听众参与到你的话题中.
演讲使用的ppt:peash-2007-3-25.ppt















 1513
1513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









