







http://xiaogui9317170.javaeye.com/blog/275572
以最少的Web服务器达到最大的性能──“互联”
网址:http://www.flashmov.com/blog_1632.html
引用
新浪科技讯 2007年5月17日,新浪与中国电信联合召开新闻发布会,正式宣布双方在播客业务上结为全面合作伙伴关系,新浪播客将以联合品牌“新浪-互联星空播客” 的全新形象跟网民见面。今后,网民不仅将体验到速度更流畅、内容更丰富的播客平台,而且无论在新浪网,还是互联星空网站都可使用播客的全部服务。
http://tech.sina.com.cn/i/2007-05-17/10091512192.shtml
报道第一段最后一句“还是互联星空网站都可使用播客的全部服务”派生的产品:互联星空播客(http://you.video.vnet.cn)于2007年12月17日正式上线。互联星空的用户可以用自己的帐号登录播客,上传视频。
我在设计系统架构时,进行了大胆的尝试,只用6台Web服务器(除开FLV视频存储服务器),达到了可承受4000万PV(页面访问量)的性能:
抛弃了 Apache,因为它能承受的并发连接相对较低;
抛弃了 Squid,因为它在内存利用、访问速度、并发连接、清除缓存等方面不如 Varnish;
抛弃了 PHP4,因为 PHP5 处理面向对象代码的速度要比 PHP4 快,另外,PHP4 已经不再继续开发;
抛弃了 F5 BIG-IP 负载均衡交换机,F5 虽然是个好东西,但由于价格不菲,多个部门多个产品都运行在其之上,流量大、负载高,从而导致性能大打折扣;
利用 Varnish cache 减少了90%的数据库查询,解决了MySQL数据库瓶颈;
利用 Varnish cache 的内存缓存命中加快了网页的访问速度;
利用 Nginx + PHP5(FastCGI) 的胜过Apache 10倍的高并发性能,以最少的服务器数量解决了PHP动态程序访问问题;
利用 Memcached 处理实时数据读写;
利用 HAProxy 做接口服务器健康检查;
经过压力测试,每台Web服务器能够处理3万并发连接数,承受4千万PV完全没问题。
保证4千万PV的并发连接数:(40000000PV / 86400秒 * 10个派生连接数 * 5秒内响应 * 5倍峰值) / 6台Web服务器 = 19290连接数
http://xiaogui9317170.javaeye.com/blog/276050
Facebook 海量数据处理
对着眼前黑色支撑的天空 / 我突然只有沉默了 我驾着最后一班船离开 / 才发现所有的灯塔都消失了 这是如此触目惊心的 / 因为失去了方向我已停止了 就象一个半山腰的攀登者 / 凭着那一点勇气和激情来到这儿 如此上下都不着地地喘息着 / 闭上眼睛疼痛的感觉溶化了 --达达乐队《黄金时代》
好几个地方看到这个 Facebook - Needle in a Haystack: Efficient Storage of Billions of Photos ,是 Facebook 的 Jason Sobel 做的一个 PPT,揭示了不少比较有参考价值的信息。【也别错过我过去的这篇Facebook 的PHP性能与扩展性 】
图片规模
作为世界上最大的 SNS 站点之一,Facebook 图片有多少? 65 亿张原始图片,每张图片存为 4-5 个不同尺寸,这样总计图片文件有 300 亿左右,总容量 540T,天! 峰值的时候每秒钟请求 47.5 万个图片 (当然多数通过 CDN ) ,每周上传 1 亿张图片。
图片存储
前一段时间说 Facebook 服务器超过 10000 台,现在打开不止了吧,Facebook 融到的大把银子都用来买硬件 了。图片是存储在 Netapp NAS上的,采用 NFS 方式。
图片写入
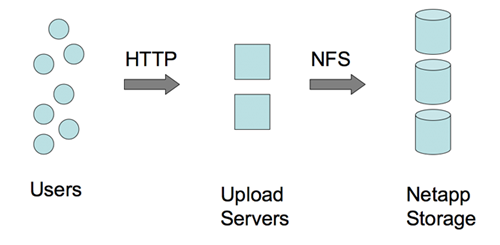
尽管这么大的量,似乎图片写入并不是问题。如上图,是直接通过 NFS 写的。
图片读取
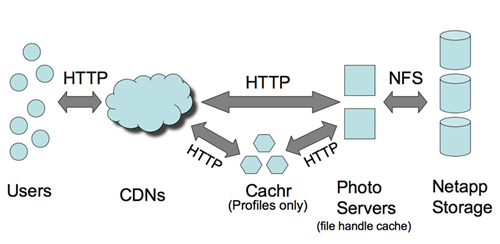
CDN 和 Cachr 承担了大部分访问压力。尽管 Netapp 设备不便宜,但基本上不承担多大的访问压力,否则吃不消。CDN 针对 Profile 图象的命中率有 99.8%,普通图片也有 92% 的命中率。命中丢失的部分采由 Netapp 承担。
图中的 Cachr 这个组件,应该是用来消息通知(基于调整过的 evhttp的嘛),Memcached 作为后端存储。Web 图片服务器是 Lighttpd,用于 FHC (文件处理 Cache),后端也是 Memcached。Facebook 的 Memcached 服务器数量差不多世界上最大了,人家连 MYSQL 服务器还有两千台呢。
Haystacks --大海捞针
这么大的数据量如何进行索引? 如何快速定位文件? 这是通过 Haystacks 来做到的。Haystacks 是用户层抽象机制,简单的说就是把图片元数据的进行有效的存储管理。传统的方式可能是通过 DB 来做,Facebook 是通过文件系统来完成的。通过 GET / POST 进行读/写操作,应该说,这倒也是个比较有趣的思路,如果感兴趣的话,看一下 GET / POST 请求的方法或许能给我们点启发。
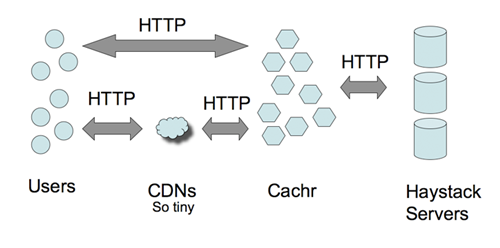
总体来看,Facebook 的图片处理还是采用成本偏高的方法来做的。技术含量貌似并不大。不清楚是否对图片作 Tweak,比如不影响图片质量的情况下减小图片尺寸。
http://xiaogui9317170.javaeye.com/blog/275567
Skype 用 PostgreSQL 支撑海量用户
网址: http://www.dbanotes.net/arch/skype_postgresql.html
自从 MySQL 被 Sun 收购 后,相信很多对该收购不放心的朋友会转而看好 PostgreSQL 的前途。虽然比较大的 Web 2.0 站点数据库方案基本都采用 MySQL ,不过也有用 PostgreSQL 并且跑的不错的。今天看到 Skype Plans for PostgreSQL to Scale to 1 Billion Users 这个帖子,对 PostgreSQL 在大型网站应用上的部署算是有了一点了解。
Skype 在数据库上的横向扩展能力以 PL/Proxy 为基础的。其实几乎所有部署 MySQL 的站点也都在考虑 Scale Out (相比 Scale Up) 的扩展方案,也有 MySQL Proxy 这样的产品推出来,只是看起来还不够成熟。PL/Proxy 的设计思想类似 Teradata 的 Hash 机制,数据存储对客户端是透明的,客户请求发送到 PL/Proxy 后,由这里分布式存储过程调用,统一分发,示意图如下:
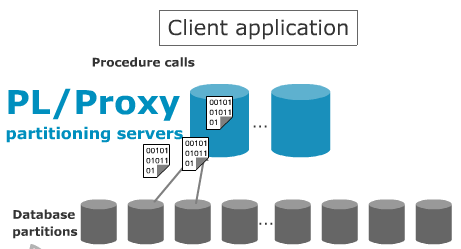
PL/Proxy 的设计初衷就是在这一层充当"数据总线"的职责,所以,当数据吞吐量支撑不住的时候,只需要增加更多的 PL/Proxy 服务器即可。(虽然随着服务器越多,通信的开销越大,但只要不大于某个规模,似乎还不足以成为比较大的问题)
随着数据总线层的水平扩展,连接池的问题就凸显出来。Skype 在连接池上的解决方案是采用 PgBouncer ,PgBouncer 极大地增强了 PostgreSQL 的连接数扩展能力。顺便说一下,"池"有三种级别:Session 池、事务池、语句池。
Skype 另外开发了一套工具包: SkyTools 来进行数据库的维护,主要是解决数据的复制与队列以及失败接管问题。
整体看下来,围绕着 PostgreSQL 的解决方案其实蛮成熟的。BTW,看起来挺适合阿里旺旺 的 :)
http://xiaogui9317170.javaeye.com/blog/275566
Facebook 的 PHP 性能与扩展性
Facebook 的 PHP 性能与扩展性
网址: http://www.dbanotes.net/arch/facebook_php.html
炙手可热的 Facebook 是用 PHP 开发的。随着一些技术交流,逐渐能看到 Facebook 技术人员分享的经验。近期这个 geekSessions 站点上看到 Facebook 的 Lucas Nealan 分享的文档比较有参考价值。
Cache 为 王
任何一个成功的站点都有一套最合适自己的 Cache 策略。

Note:这个层次图画的稍微有点问题,不是严格从上到下的。
The Alternative PHP Cache , APC
Facebook 平均每个用户每天要访问超过 50 个页面,PHP的页面载入时间的优化就比较重要了。在 PHP Cache 层,Facebook 采用了 APC 。
Lucas Nealan 的 PPT 举了一个例子,一个页面显示的时间从 4000 多毫秒降到了 100 多 毫秒。在 apc.stat 关闭的模式下,性能还要更好一些。不过需要重启动或用apc_cache_clear() 来通知更新。
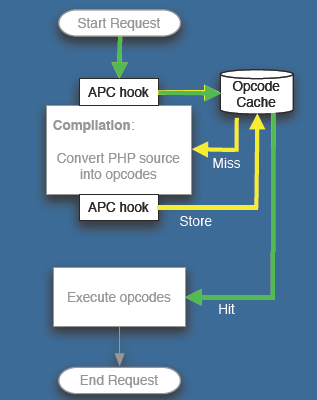
Memcached 层
APC Cache 的是非用户相关的信息,而用户相关的数据 Cache 当然是在 Memcached 中。
Facebook 部署了超过 400 台 Memcached 服务器,超过 5TB 的数据在 Memcached 中。这是当前世界上最大的 Memcached 集群了。也给 Memcached 贡献 了不少代码,包括 UDP 的支持和性能上的提升(性能提升超过 20%)。
程序 Profiling
Facebook 开发人员大量采用 Callgrind 、APD、 xdebug 、KCachegrind 等工具进行基准性能测试。任何一个 Web 项目,这也是不可或缺,也是比较容易忽略的一环。所有开发人员都应该具备熟练使用这些工具的能力才好。
补充一下:语言的选择
为什么 Facebook 选择 PHP 而不是其他语言? 用Flickr 的 Cal Henderson 这句话就能说明了: "Languages's don't Scale, Architecture Scale"。
从 80-20 的原则看,APC 和 Memcached 是最主要的。在这两个环节上下功夫,受益/开销比要大于另外几个环节。
(上面的图是从 Lucas Nealan 的文档截的,版权所有是他的)
http://www.dbanotes.net/database/craigslist_database_arch.html
(插播一则新闻:竞拍这本《Don’t Make Me Think》,我出价 RMB 85,留言的不算--不会有恶意竞拍的吧? 要 Ping 过去才可以,失败一次,再来)
Craigslist 绝对是互联网的一个传奇公司。根据以前的一则报道:
每月超过 1000 万人使用该站服务,月浏览量超过 30 亿次,(Craigslist每月新增的帖子近 10 亿条??)网站的网页数量在以每年近百倍的速度增长。Craigslist 至今却只有 18 名员工(现在可能会多一些了)。
Tim O'reilly 采访了 Craigslist 的 Eric Scheide ,于是通过这篇 Database War Stories #5: craigslist 我们能了解一下 Craigslist 的数据库架构以及数据量信息。
数据库软件使用 MySQL 。为充分发挥 MySQL 的能力,数据库都使用 64 位 Linux 服务器, 14 块 本地磁盘(72*14=1T ?), 16G 内存。
不同的服务使用不同方式的数据库集群。
论坛
1 主(master) 1 从(slave)。Slave 大多用于备份. myIsam 表. 索引达到 17G。最大的表接近 4200 万行。分类信息
1 主 12 从。 Slave 各有个的用途. 当前数据包括索引有 114 G , 最大表有 5600 万行(该表数据会定期归档)。 使用 myIsam。分类信息量有多大? "Craigslist每月新增的帖子近 10 亿条",这句话似乎似乎有些夸张,Eric Scheide 说昨日就超过 330000 条数据,如果这样估计的话,每个月的新帖子信息大约在 1 亿多一些。归档数据库
1 主 1 从. 放置所有超过 3 个月的帖子。与分类信息库结构相似但是更大, 数据有 238G, 最大表有 9600 万行。大量使用 Merge 表,便于管理。搜索数据库
4 个 集群用了 16 台服务器。活动的帖子根据 地区/种类划分,并使用 myIsam 全文索引,每个只包含一个子集数据。该索引方案目前还能撑住,未来几年恐怕就不成了。Authdb
1 主 1 从,很小。目前 Craigslist 在 Alexa 上的排名是 30,上面的数据只是反映采访当时(April 28, 2006)的情况,毕竟,Craigslist 数据量还在每年 200% 的速度增长。
Craigslist 采用的数据解决方案从软硬件上来看还是低成本的。优秀的 MySQL 数据库管理员对于 Web 2.0 项目是一个关键因素。
--EOF--
http://www.dbanotes.net/review/second_life.html
Matrix 似乎提前来到我们身边。从 06 年开始,陆续看到多次关于 Second Life(SL) 的报道。因为自己的笔记本跑不起来 SL 的客户端,所以一直没有能体会这个虚拟世界的魅力。今天花了一点时间,读了几篇相关的文档。
RealNetworks 前 CTO Philip Rosedale 通过 Linden 实验室创建了 Second Life,2002 年这个项目开始 Alpha 版测试,当时叫做 LindenWorld。
2007 年 2 月 24 日号称已经达到 400 万用户(用户在游戏中被称为 "Residents",居民)。 2001 年 2 月 1 日,并发用户达到 3 万。并发用户每月的增长是 20%。这个 20%现在看起来有些保守了,随着媒体的关注,增长的会有明显的变化。系统的设计目标是 10 万并发用户,系统的复杂度不小,但 Linden 实验室对SL 的可扩展能力信心满满。
目前在旧金山与达拉斯共有 2000 多台(现在恐怕3000也不止了吧) Intel/AMD 服务器来支撑整个虚拟世界(refer here)。64 位的 AMD 服务器居多。操作系统选用的 Debian Linux, 数据库是 MySQL。通过 Tim O'relly 的这篇 Web 2.0 and Databases Part 1: Second Life ,可以了解到一点关于 SL 数据库建设的信息。在 Second Life 中每个地理区域都是运行在服务器软件单一实例上的,叫做"模拟器"或者简称是 "sim",每个 Sim 负责 16 英亩的虚拟土地。当用户在相邻的 Sim 间移动,实际上是从一个处理器(或是服务器)移动到另一个。根据这篇访谈,用户当前所在 Sim 的信息,以及用户本身的账户信息是存储在一个中心数据库上的。
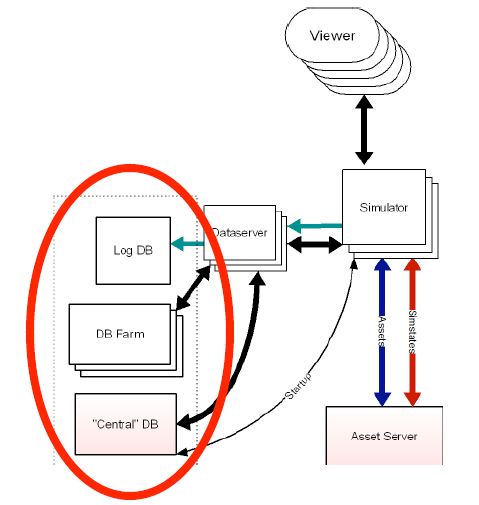
SL 的客户端软件的下载使用了 Amazon 的 S3 服务。
一点感想:MySQL 真是这波 Web 2.0 大潮中最大赢家之一啊
--EOF--
http://xiaogui9317170.javaeye.com/blog/275555
有关 Alexa 与 AOL 部署集群文件系统
网址: http://www.dbanotes.net/arch/alexa_ibrix_san_file_system.html
这两天关注了一下基于 SAN/NAS 的集群文件系统的产品。找到了关于 Alexa 的一则旧闻 ,之后又发现了一篇关于 AOL 部署 SAN 文件系统的文章。
Alexa 的相关数据
Alexa 超过 1000 台 Linux 服务器 Farm,每半年增长 300T 新数据。经过了同类产品的选型后,最后选择了 Ibrix 融合文件系统。
SAN 使用的是 HP Modular Smart Array (MSA1000) ,最大支持 12T ,Cache I/O 最大 3 万个,算是个中低端的阵列。Amazon 没有透漏这套系统的吞吐能力,只是说 Ibrix 这套系统能达到 1T 的 I/O 聚合能力,单个 NameSpace 可达 16PB 容量。
不过从现在的一些迹象上来看,Amazon 对存储层重新做了改造 。这套解决方案被替换掉了也说不定.
AOL 的相关数据
原有状况:3000 台主机通过 10000 多个光纤通道端口连接到传统的 SAN 上。其中有 8PB 的非结构化数据,分布在大约 1000 台 文件服务器上。管理维护的复杂度可想而知。
解决方案:文件服务器采用直连的磁盘,每个 12 块 700GB 的 ATA 磁盘,然后通过 Ibrix 融合文件系统进行集群化。
看起来,Ibrix 提供的解决方案很有竞争力。现在一些比较大的用户对于存储层的集群的需求越来越多,快成为趋势,一揽子解决方案还是有必要的,毕竟不是每家技术能力都强如 Amazon、Google ,有的时候用第三方的成本是能小于自己动手 DIY 的。
http://xiaogui9317170.javaeye.com/blog/275554
Yahoo!社区架构
网址: http://www.dbanotes.net/arch/yahoo_arch.html
旧金山举行的 QCon 会议带给我们很多新鲜的信息。虽然没机会参加,但是看看各个网站"晒架构"也是个比较过瘾的事情。请参观并收藏这个页面:Architectures you've always wondered about 。
eBay 的架构 和去年相比基本是换汤不换药,倒是 Yahoo! 的 Ian Flint (这位老兄是 Bix 的运营总监. Bix 已被雅虎收购) 这个 PPT Yahoo! Communities Architecture: Unlikely Bedfellows 挺有意思,披露了一些鲜为人知的信息。
Yahoo! 社区包括我们比较熟悉的 del.icio.us 、Flickr 、Yahoo!群组、Yahoo! Mail、Bix 等。相当于 Yahoo!把这些属性相近的应用放到一起运营。这个思路倒是和盛大对游戏的运营有些相近。
架构特点
有两点值得注意:1)层次化 2)模块化。这也是大规模作业下的比较经济的途径。
软件架构
首先是操作系统已经从 FreeBSD 逐渐迁移到 RHEL。这怕是雅虎不得已作出来的决定吧。FreeBSD 的开发力量的确不如 Linux,这也是不争的事实。数据库上 MySQL 与 Oracle 都有。Yahoo! 在 DW/BI 用的是 Oracle,构建了一个超大数据库 。诸如 yapache、yts(反向代理服务器)、yfor(提供快速失败接管)、 ymon(监控),还有还有ysquid、ypan(cpan的 Yahoo! 克隆) 这些组件都是通过 yinst 来统计部署。关于 Yapache,请参考我以前写的 Yapache-Yahoo! Apache 的秘密
这是 Bix 与 DB 有关的部署架构: 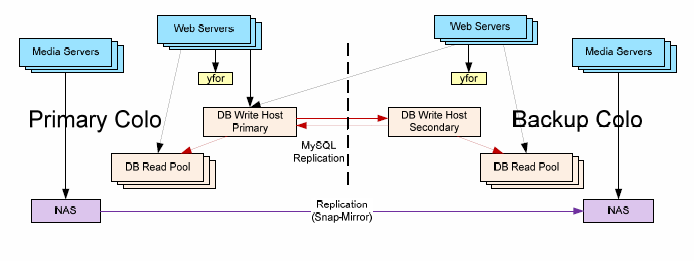
数据放在 Netapp NAS 上(所以有的时候应用之慢也可以理解了),通过快照复制到其他数据中心。
Yahoo! Mail 架构:
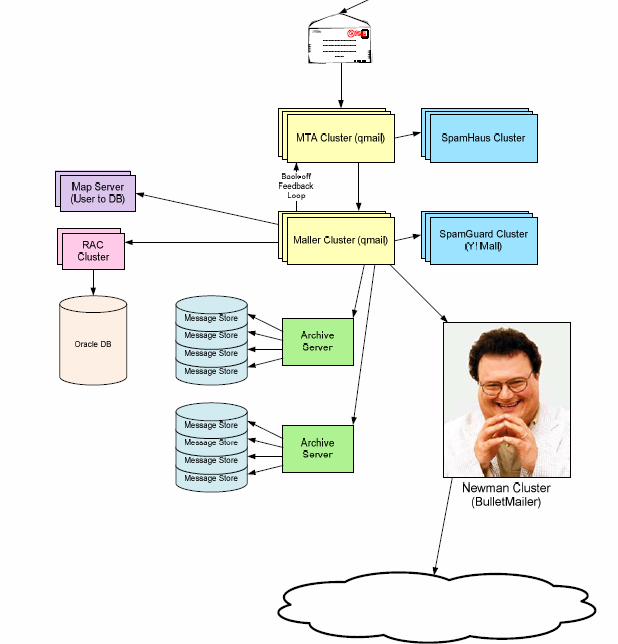
这里面居然部署了 Oracle RAC,用来存储 Mail 服务相关的 Meta 数据。非常有趣。
运营维护
监控工具主要用的是 Nagios ,用以监控集群。使用标准插件,另外也有自行定制的插件。Nagios 这东西太棒了。主动、被动检查的消息转发是通过 Ymon 来做到。网管上针对 SNMP 的解决方案是用 Yahoo!自己 Y 字头的 Ywatch。这些 Y 字头的东西基本上外面都是找不到的。Yahoo!的技术其实并不那么开放。Google 在运营这方面也好不到什么地方去。趋势图用 Drraw 展现。Drraw 是基于 RRDtool 的 Web 展现工具。
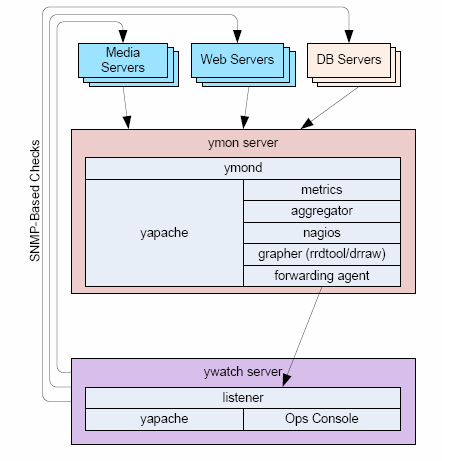
应用服务器的监控是被动的。整个监控系统模块化部署。Nagios 的警告信息转发到 Ywatch 中心控制台。
Note: 上面所有截图版权都属于 Ian (Image COPYRIGHT@IAN) 。如果去看那个 PDF 文件,你或许比我收获更多。我只是让你知道我的想法而已。
http://xiaogui9317170.javaeye.com/blog/275552
PlentyOfFish 网站架构学习
网址: http://www.dbanotes.net/arch/plentyoffish_arch.html
采取 Windows 技术路线的 Web 2.0 站点并不多,除了 MySpace ,另外就是这个 PlentyOfFish 。这个站点提供 "Online Dating” 服务。一个令人津津乐道的、惊人的数据是这个只有一个人(创建人Markus Frind )的站点价值 10 亿 ,估计要让很多人眼热,更何况 Markus Frind 每天只用两个小时打理网站--可操作性很强嘛。
之所以选择 Windows .NET 的技术路线是因为 Markus Frind 不懂 LAMP 那一套东西,会啥用啥。就这样,也能支撑 超过 3000 万的日点击率(从这个数字也能看出来人类对自然天性的渴望是多迫切)。Todd Hoff 收集了很多关于 PlentyOfFish 架构的细节 。记录一下感兴趣的部分。
带宽与CPU
PlentyOfFish 比较特殊的一个地方是 几乎不需要 Cache,因为数据变化过快,很快就过期。我不知道这是因为 ASP .NET 的特点带来的架构特点,还是业务就是这个样子的。至于图片,则是通过 CDN 支撑的。对于动态出站(outbound)的数据进行压缩,这耗费了 30% 的 CPU 能力,但节省了带宽资源。我最近才知道,欧美的带宽开销也不便宜。
负载均衡
微软 Windows 网络负载均衡(Network Load Balancing) 的一个缺陷是不能保持 Session 状态(我没有用过这玩意儿,不能确认),价格也不便宜,而且复杂;网络负载均衡对 Windows 架构的站点又是必须--IIS 的总连接数是有限制的。PlentyOfFish 用的是 ServerIron (Conf Refer ),ServerIron 使用简单,而且功能比 NLB 更丰富。
数据库
一共三台 SQL Server,一台作为主库,另外两台只读数据库支撑查询。数据库性能监控用的是“Windows 任务管理器"。因为 Cache没啥用,所以要花大力气优化 DB。每个页面上调用 DB 次数越少越好,越简单越好,这是常识,不过不是每个人都体会那么深而已。
微软好不容易找到了一个宣传案例,所以在 Channel 9 上有一个 PlentyOfFish 的访谈 。
PlentyOfFish 取自天涯何处无芳草(Plenty of fish in the sea)的意思,还挺有文化的。从这一点上看,比国内那些拉皮条的网站好一些。
http://xiaogui9317170.javaeye.com/blog/275550
Flickr 的访问统计实现以及其他
网址: http://www.dbanotes.net/arch/flickr_stats_and_dathan.html
TechCrunch 前两天报道说 Flickr 针对 Pro 用户新增了一项统计功能 。今天有看到 Flickr 的 DBA Dathan Pattishall 描述了一下这个统计功能的实现。
Flickr 统计功能的基本技术信息:
- 所有的信息统计是实时的
- 同时用到 MYISAM 与 INNODB 两种引擎
- 数据因为存储需求跨在 6 个 Cluster 上(12 台服务器,6 台提供服务,6 台做失败接管)
- 没有用 Memcache
Dathan 提到这是他最耗时的一个项目(似乎有点怨言呀)。因为是实时统计,并且还要不影响整体页面响应速度,所以整个项目非常复杂。一旦 DB 设计搞定后,大部分时间都花在如何创建分布锁 上了。
其实就我个人而言,真的不觉得这个功能有什么必要(尤其还是实时统计)。这或许是过度设计的一个例子。Flickr 在被 Yahoo!收购之后,这段时间倒是有点颓势。
说起 Dathan 这老兄,在 MySQL 技术圈子算是大名鼎鼎了。曾先后在 Friendfinder 、Friendster 做 DBA,并获得国 05、06 两年的 "MySQL Application of the Year Award“。(看他 Blog 的活跃劲儿,估计今年也差不多。)
这老兄加盟了 Flickr 后,一个礼拜解决了 40% 左右的性能问题。从他的简历 来看,Flickr 目前每日 DB 的事务超过 10亿,MySQL 运行在 16G 内存、AMD CPU 服务器上,存储采用本地硬盘而没有用 SAN。数据库采用联邦架构,能做到线性扩展,为公司节省成本达 40 万美元(占40%,从而估计 DB 相关硬件成本为 60万美元).
推荐国内每个 Web 2.0 公司的 DBA 持续关注 Dathan 的 Blog,当然,可能大家都已经一直在看了。
http://xiaogui9317170.javaeye.com/blog/275548
37Signals 架构
网址: http://www.dbanotes.net/arch/37signals_arch.html
如果没有 37signals ,恐怕也没有 RoR 的如此流行。37signals 对于很多 Geek 来说,是一家非常迷人的公司。他们是网络上的另类新星。
37Signals 在 Signal vs. Noise 上披露了比较详细的运营数据,Ask 37signals: Numbers?
存储数据量
截止到 2007 年 11 月,总存储量统计:
- 5.9 T 用户上传 的数据
- 888 GB 上传文件 (900,000 请求)
- 2 TB 文件下载 (8,500,000 请求)
这包括 Basecamp 、Highrise 、BackPack 、Campfire 总的数据统计。总的用户量其实并不多,只有 200 万。
这些数据存放在 Amazon S3 上,37Signals 用了这个服务已经一年多了,他们对此比较满意。事实上,Amazon S3 已经成为 Web 2.0 分布式存储的既定事实的解决方案。
服务器状况
37Signals 当前正在部署虚拟化软件产品,当然不用 VMware,而用开源的 Xen。当前大约有 30 台服务器,从单 CPU 的文件服务器到 8 CPU 的应用服务器都有,总共 100 颗 CPU、200GB 内存。预计 XEN 部署完毕后,服务器数量降低到 16 台,92 颗更快的 CPU、230GB 的内存量。这样做的主要目的是管理起来更方便(至于性能是否更好,我个人还是有点怀疑的--Fenng)。
关心 ROR 以及具体一些策略具体实现的朋友不防去看看那个帖子下面的留言。
之前还真的很少有听说哪家 Web 2.0 公司部署 XEN 的,37signals 的这个动作或许是个积极的信号。2007 年也是个"虚拟化"年,相信随着虚拟化的技术成熟,开源力量的壮大,会有更多的公司收益于 XEN 虚拟化架构.
http://xiaogui9317170.javaeye.com/blog/275547
Yupoo! 的网站技术架构
网址: http://www.dbanotes.net/arch/yupoo_arch.html
又有机会爆料国内 Web 2.0 网站的架构了。这次是 Yupoo! 。非正式的采访了一下 Yupoo! (又拍网) 的创建人之一的 阿华 (沈志华)同学,了解了一些小道消息。
作为国内最大的图片服务提供商之一,Yupoo! 的 Alexa 排名大约在 5300 左右。同时收集到的一些数据如下:
带宽:4000M/S (参考 )
服务器数量:60 台左右
Web服务器:Lighttpd, Apache, nginx
应用服务器:Tomcat
其他:Python, Java, MogileFS 、ImageMagick 等
首先看一下网站的架构图:
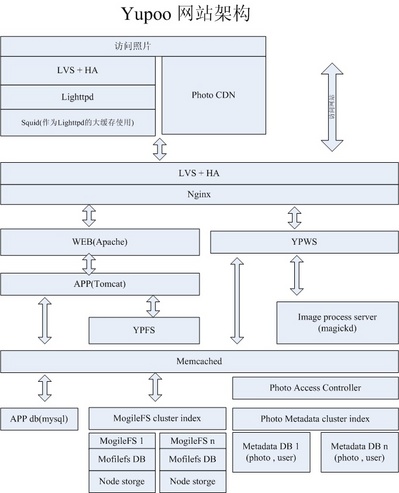
该架构图给出了很好的概览(点击可以查看在 Yupoo! 上的大图和原图 ,请注意该图版权信息)。
关于 Squid 与 Tomcat
Squid 与 Tomcat 似乎在 Web 2.0 站点的架构中较少看到。我首先是对 Squid 有点疑问,对此阿华的解释是"目前暂时还没找到效率比 Squid 高的缓存系统,原来命中率的确很差,后来在 Squid 前又装了层 Lighttpd, 基于 url 做 hash, 同一个图片始终会到同一台 squid 去,所以命中率彻底提高了"
对于应用服务器层的 Tomcat,现在 Yupoo! 技术人员也在逐渐用其他轻量级的东西替代,而 YPWS/YPFS 现在已经用 Python 进行开发了。
名次解释:
- YPWS--Yupoo Web Server YPWS 是用 Python开发的一个小型 Web 服务器,提供基本的 Web 服务外,可以增加针对用户、图片、外链网站显示的逻辑判断,可以安装于任何有空闲资源的服务器中,遇到性能瓶颈时方便横向扩展。
- YPFS--Yupoo File System 与 YPWS 类似,YPFS 也是基于这个 Web 服务器上开发的图片上传服务器。
【Updated: 有网友留言质疑 Python 的效率,Yupoo 老大刘平阳在 del.icio.us 上写到 "YPWS用Python自己写的,每台机器每秒可以处理294个请求, 现在压力几乎都在10%以下"】
图片处理层
接下来的 Image Process Server 负责处理用户上传的图片。使用的软件包也是 ImageMagick,在上次存储升级的同时,对于锐化的比率也调整过了(我个人感觉,效果的确好了很多)。”Magickd“ 是图像处理的一个远程接口服务,可以安装在任何有空闲 CPU资源的机器上,类似 Memcached的服务方式。
我们知道 Flickr 的缩略图功能原来是用 ImageMagick 软件包的,后来被雅虎收购后出于版权原因而不用 了(?);EXIF 与 IPTC Flicke 是用 Perl 抽取的,我是非常建议 Yupoo! 针对 EXIF 做些文章,这也是潜在产生受益的一个重点。
图片存储层
原来 Yupoo! 的存储采用了磁盘阵列柜,基于 NFS 方式的,随着数据量的增大,”Yupoo! 开发部从07年6月份就开始着手研究一套大容量的、能满足 Yupoo! 今后发展需要的、安全可靠的存储系统“,看来 Yupoo! 系统比较有信心,也是满怀期待的,毕竟这要支撑以 TB 计算的海量图片的存储和管理。我们知道,一张图片除了原图外,还有不同尺寸的,这些图片统一存储在 MogileFS 中。
对于其他部分,常见的 Web 2.0 网站必须软件都能看到,如 MySQL、Memcached 、Lighttpd 等。Yupoo! 一方面采用不少相对比较成熟的开源软件,一方面也在自行开发定制适合自己的架构组件。这也是一个 Web 2.0 公司所必需要走的一个途径。
http://xiaogui9317170.javaeye.com/blog/275546
财帮子(caibangzi.com)网站架构
网址: http://www.dbanotes.net/arch/caibangzi_web_arch.html
财帮子(caibangzi.com) 定位在”基金理财社区"。是国内访问量最大的基于 Ruby on rails 的 startup 项目。“理财”这个词据说是光大银行发明的,且不去管,不可否认的是,目前国内"理财"是个很有潜力的切入点。财帮子网站潜在用户群还是很大的。
1.创建人员
创建者有三人。Robin Lu(石锅拌饭) 、Meng Yan ( 孟岩 ) ,还有一位"不写Blog的家伙"。前两位都是技术人员。很早就看过孟岩 的 Blog,那时候他还在 Sun。Robin Lu 的 Blog 也一直在我的订阅列表中的,所以财帮子刚成立我就知道的。倒没有细问第三位是技术人员还是负责商务。(Updated: Robin Lu留言说”财帮子那位不写blog的创建者也是工程师,叫赵路,曾经是 Mozilla 项目accessibility模块的module peer."
2.服务器信息
Web 服务器用的是 Lighttpd ,出于节省成本的目的,服务器是自行组装的。数据库采用的是 MySQL 5,目前还没有使用 Replication. 正准备扩充服务器,服务器数量...暂且保密一下。
3.统计分析及监控
统计分析采用 Google Analytics 和 Awstats 。目前 Alexa 排名是 2 万一点。监控工具用 monit,"以及自己写的一些分析 Proc 的脚本",再有就是 Unix 性能工具等。(Fenng: 服务器处于规模化 之前基本上要这个样子)。
4.优化之路
Robbin 在此前的一篇 财帮子性能优化简报 披露:“财帮子两个星期以前,遇到严重的性能问题,最终我们采用了相当非主流的部署方案和打了自己补丁的web server,成功度过了难关”,我很好奇这具体是个什么问题。得到的答案是:“Apache的负载均衡是有问题的,算法太简单了,对Ror的应用来说,会造成某一个app instance的阻塞,从而阻塞了所有的request”。
谈及 Cache 的感慨:
Fenng: ... 我个人感觉你们需要Cache服务器, 这一类的站点内容需要 Cache 的太多 Meng Yan: ...Web 2.0网站的 cache 非常重要。我们从Mem的cache,到disk的cache, 再到数据库的cache,架构还不错,否则当前机器撑不住 :) Fenng: 很多站点扩展作不好,也是Cache没用好 Meng Yan: 是啊,Cache非常重要,非常非常 Fenng: 豆瓣的阿北说他们 Memcached 用的非常爽,命中率非常之高 Meng Yan: 确实,我们的内存cache就是用的memcached,真的很棒
5.挑战
这是就这次采访的最后一个问题。
Fenng:还要采访你一个问题:caibangzi.com 现在运营、开发面临的最大的一个问题是什么? Meng Yan:目前可能我们遇到最多的是合作、商务 上的事情。真正开发、运营上来说对我们的挑战还不大。
6.后记
这次采访(如果可以说这是采访的话)非常顺利。财帮子从三月底上线 ,到现在已经积累了一定数量的用户,当然不是十全十美的(我个人就感觉应该提供更多的RSS输出才是,不要太在乎站点流量,流量本身也是开销),网站也还有很长的路要走。真诚希望财帮子 能成为更多人的理财工具(至少我已经开始用了)。
这是我第一次写国内 Web 2.0 网站架构技术。感谢 Meng Yan 提供的第一手信息。关于网站架构,我在这个 Blog 上写过不少国外的站点分析。一直想采访一些国内的 Web 2.0 站点并且能披露点技术信息,相对来说,国内站点还是比较保守,各自闷头折腾。为什么不换个角度,分享、借鉴、壮大,这个方式不也不错麽?
http://xiaogui9317170.javaeye.com/blog/275545
Twitter 的架构扩展: 100 倍性能提升
网址: http://www.dbanotes.net/arch/twitter_arch.html
Twitter 是我最近一段时间用的最多的网络服务之一.还记得刚开始有段时间发消息速度那叫一个慢. 难得的是 Twitter 的开发者在用户激增的情况下性能提升的不错, 据说,相比当初有 100 倍的性能提升 , 那我们就来看看他们都做了什么.(发现我这个 Blog 快成了 High Scalability 的中文镜像站了.)
是否真的是 100 倍性能提升, 大可不必较真, 但 Twitter 的一些经验是足以借鉴的.
Ruby on rails
似乎 Twitter 是用 RoR 开发的流量最大的站点(有待于求证). 开始使用DRb ("Distributed Ruby".), 该库可以通过 TCP/IP 从远程 Ruby 对象发送接收消息, 其缺点是不那么好用,并且没有冗余, 于是转向 Rinda , Rinda 基于 DRb 开发, 使用简单. Twitter 也证明了 Ror 应用同样可以支撑比较繁忙的站点, 工具没有对于错,关键是否能运用好.
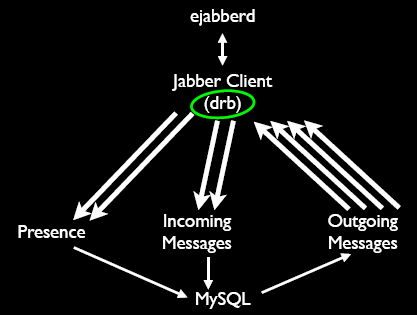
图片来源 . (这里面我非常疑惑的一点是据说只有两台DB(Master/Slave),可要支撑这么大的并发更新似乎有些难度.)
ETag
Twitter 对于Etag 的态度让不少人疑惑. 这恰恰是因技术制宜的一个体现, 因为 Etag 不是万能药 . 另外一点比较重要的原因是 Twitter 有超过 90% 的流量来自 API , 而 多数 API 客户端不支持 Etag.
数据库方面的经验
尽可能的索引(Fenng补充:不要过度索引). 因为 RoR 应用的特殊性, 索引是在代码中向 DB 提交的. 另外一个值得议题的是, 反范式. 严格遵守范式是要吃苦头的.建立可行的测试方法,明确的知道你的SQL都在用什么方式运行.(另外,我有个疑问是 rails 不支持 2 阶段提交的吧?)
避免资源过度被占用
哪个站点都不避免的有"水葫芦用户" ,对于这样的 Spam 类型用户, 肯定会影响原有的应用处理资源. 该处理就要处理掉. 另一个方面,对于间歇性占用系统资源过多的进程用 Monit 处理.
另外一个很重要的环节是 Cache, 不废话了,没有好的Cache机制怕这样的站点不会成功的. (建议阅读车东 辛苦翻译的这篇面向站长和网站管理员的Web缓存加速指南[翻译] ). Twitter 运营的一个可取之处是能够积极听取社区的意见并改进, 同时社区上也有很多用户给他们提供了不少技术支持. 这也是开放而带来的好处吧.
http://xiaogui9317170.javaeye.com/blog/275544
Tailrank 网站架构
网址: http://www.dbanotes.net/review/tailrank_arch.html
![]()
每天数以千万计的 Blog 内容中,实时的热点是什么? Tailrank 这个 Web 2.0 Startup 致力于回答这个问题。
专门爆料网站架构的 Todd Hoff 对 Kevin Burton 进行了采访。于是我们能了解一下 Tailrank 架构 的一些信息。每小时索引 2400 万的 Blog 与 Feed,内容处理能力为 160-200Mbps,IO 写入大约在10-15MBps。每个月要处理 52T 之多的原始数据。Tailrank 所用的爬虫现在已经成为一个独立产品:spinn3r 。
服务器硬件
目前大约 15 台服务器,CPU 是 64 位的 Opteron。每台主机上挂两个 SATA 盘,做 RAID 0。据我所知,国内很多 Web 2.0 公司也用的是类似的方式,SATA 盘容量达,低廉价格,堪称不二之选。操作系统用的是 Debian Linux 。Web 服务器用 Apache 2.0,Squid 做反向代理服务器。
数据库
Tailrank 用 MySQL 数据库,联邦数据库形式。存储引擎用 InnoDB, 数据量 500GB。Kevin Burton 也指出了 MySQL 5 在修了一些 多核模式下互斥锁的问题(This Bug ?)。到数据库的JDBC 驱动连接池用 lbpool 做负载均衡。MySQL Slave 或者 Master的复制用 MySQLSlaveSync 来轻松完成。不过即使这样,还要花费 20% 的时间来折腾 DB。
其他开放的软件
任何一套系统都离不开合适的 Profiling 工具,Tailrank 也不利外,针对 Java 程序的 Benchmark 用 Benchmark4j 。Log 工具用 Log5j (不是 Log4j)。Tailrank 所用的大部分工具都是开放的。
Tailrank 的一个比较大的竞争对手是 Techmeme ,虽然二者暂时看面向内容的侧重点有所不同。其实,最大的对手还是自己,当需要挖掘的信息量越来越大,如果精准并及时的呈现给用户内容的成本会越来越高。从现在来看,Tailrank 离预期目标还差的很远。期待罗马早日建成。
http://xiaogui9317170.javaeye.com/blog/275543
LinkedIn 架构笔记
网址: http://www.dbanotes.net/arch/linkedin.html
现在是 SNS 的春天,最近又有消息传言新闻集团准备收购 LinkedIn 。有趣的是,LinkedIn 也是 Paypal 黑帮 成员创建的。在最近一个季度,有两个 Web 2.0 应用我用的比较频繁。一个是Twitter ,另一个就是 LinkedIn 。
LinkedIn 的 CTO Jean-Luc Vaillant 在 QCon 大会上做了 ”Linked-In: Lessons learned and growth and scalability “ 的报告。不能错过,写一则 Blog 记录之。
LinkedIn 雇员有 180 个,在 Web 2.0 公司中算是比较多的,不过人家自从 2006 年就盈利了,这在 Web 2.0 站点中可算少的。用户超过 1600 万,现在每月新增 100 万,50% 会员来自海外(中国用户不少,也包括我 ).
开篇明义,直接说这个议题不讲"监控、负载均衡”等话题,而是实实在在对这样特定类型站点遇到的技术问题做了分享。LinkedIn 的服务器多是 x86 上的 Solaris ,关键 DB 用的是 Oracle 10g。人与人之间的关系图生成的时候,关系数据库有些不合时宜,而把数据放到内存里进行计算就是必经之路。具体一点说,LinkedIn 的基本模式是这样的:前台应用服务器面向用户,中间是DB,而DB的后边还有计算服务器来计算用户间的关系图的。
问题出来了,如何保证数据在各个 RAM 块(也就是不同的计算服务器)中是同步的呢? 需要一个比较理想的数据总线(DataBus)机制。
第一个方式是用 Timestamp . 对记录设置一个字段,标记最新更新时间。这个解决方法还是不错的---除了有个难以容忍的缺陷。什么问题?就是 Timestamp 是 SQL调用发起的时间,而不是 Commit 的确切时间。步调就不一致喽。
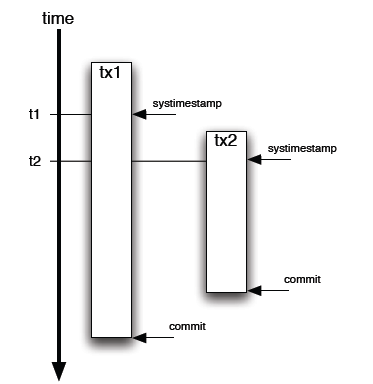
第二个办法,用 Oracle 的 ORA_ROWSCN (还好是 Oracle 10g). 这个伪列包含 Commit 时候的 SCN(System Change Number),是自增的,DB 自己实现的,对性能没有影响。Ora_ROWSCN 默认是数据库块级别的粒度,当然也可做到行级别的粒度。唯一的缺点是不能索引(伪列). 解决办法倒也不复杂:增加一个 SCN 列,默认值"无限大"。然后用选择比某个 SCN 大的值就可以界定需要的数据扔到计算服务器的内存里。
ORA_ROWSCN 是 Oracle 10g 新增的一个特性,不得不承认,我过去忽略了这一点。我比较好奇的是,国内的 Wealink、联络家等站点是如何解决这个关系图的计算的呢?
http://xiaogui9317170.javaeye.com/blog/275539
WikiPedia 技术架构学习分享
网址: http://www.dbanotes.net/opensource/wikipedia_arch.html
维基百科(WikiPedia.org )位列世界十大网站,目前排名第八位。这是开放的力量。
来点直接的数据:
* 峰值每秒钟3万个 HTTP 请求
* 每秒钟 3Gbit 流量, 近乎375MB
* 350 台 PC 服务器
(数据来源 )
架构示意图如下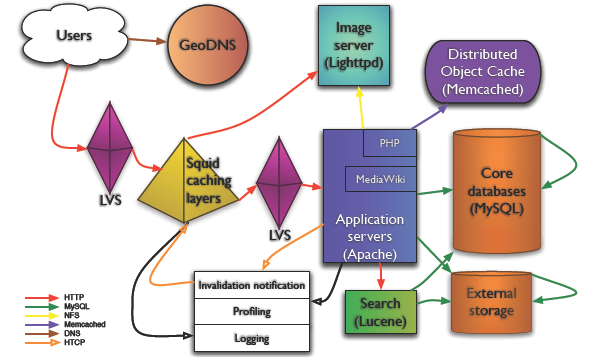
WikiPedia_arch.png Copy @Mark Bergsma
GeoDNS
在我写的这些网站架构的 Blog 中,GeoDNS 第一次出现,这东西是啥? "A 40-line patch for BIND to add geographical filters support to the existent views in BIND", 把用户带到最近的服务器。GeoDNS 在 WikiPedia 架构中担当重任当然是由 WikiPedia 的内容性质决定的--面向各个国家,各个地域。
负载均衡:LVS
WikiPedia 用 LVS 做负载均衡, 是章文嵩博士发起的项目,也算中国人为数不多的在开源领域的骄傲啦。LVS 维护的一个老问题就是监控了,维基百科的技术人员用的是 pybal.
图片服务器:Lighttpd
Lighttpd 现在成了准标准图片服务器配置了。不多说。
Wiki 软件: MediaWiki
对 MediaWiki 的应用层优化细化得快到极致了。用开销相对比较小的方法定位代码热点,参见实时性能报告,瓶颈在哪里,看这样的图树展示一目了然。另外一个十分值得重视的经验是,尽可能抛弃复杂的算法、代价昂贵的查询,以及可能带来过度开销的 MediaWiki 特性。

Cache! Cache! Cache!
维基百科网站成功的第一关键要素就是 Cache 了。CDN(其实也算是 Cache) 做内容分发到不同的大洲、Squid 作为反向代理. 数据库 Cache 用 Memcached,30 台,每台 2G 。对所有可能的数据尽可能的Cache,但他们也提醒了 Cache 的开销并非永远都是最小的,尽可能使用,但不能过度使用。
数据库: MySQL
MediaWiki 用的DB 是 MySQL. MySQL 在 Web 2.0 技术上的常见的一些扩展方案他们也在使用。 复制、读写分离......应用在 DB 上的负载均衡通过 LoadBalancer.php 来做到的,可以给我们一个很好的参考。
运营这样的站点,WikiPedia 每年的开支是 200 万美元,技术人员只有 6 个,惊人的高效。
参考文档:
Wikimedia architecture (PDF)
Todd Hoff 的文章















 341
341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









