







一,简介
ButterKnife 使用注解的方式来替代繁琐的视图绑定,资源绑定,注册监听器等。
二,运行时注解&编译时注解
一个需求:如何自动实现findViewById()功能?
可以分为两个环节:找到需要待实现的成员变量,变量对应的待绑定id和实现findViewById代码。为了找到相应变量以及关联id,我们需要需要给他们做**“标记”** ,任何能够达到“标记”功能,且符合编译器语法的方式都是可以考虑的方向。比如(1)注解(没错,注解其实就是一种可以携带信息的标记);(2)具备关联信息的配置文件;(3)map等类变量;(4)其他很多种途径。基于jdk对注解功能的支 持全面性以及使用简约性,市面上的框架基本采用的是注解。 但不影响我们对注解的本质理解。
现在我们已经获取到了待处理的成员以及对应id,该如何实现绑定呢?
(1)运行时注解:代码执行的时候反射执行findViewById方法
(2)编译时注解:编译阶段完成findViewById操作
(3)修改字节码
(4)其他
简单示例:
运行时注解实现
//注解类
/**
* 注解 绑定view
*/
@Documented
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
public @interface BindView {
@IdRes int value();
}
//完成findViewbyId
public class AptRuntime {
private AptRuntime() {
throw new AssertionError("No instances.");
}
public final static Unbinder bind(Activity activity) {
Class cls = activity.getClass();
// 获取Activity下的所有成员
Field[] fields = cls.getDeclaredFields();
for (Field field : fields) {
// 获取所有带BindView注解的属性
BindView bindView = field.getAnnotation(BindView.class);
if (bindView == null) {
continue;
}
field.setAccessible(true);
int viewId = bindView.value();
if (viewId != -1) {
View view = activity.findViewById(viewId);
try {
// 重新设置属性值
field.set(activity, view);
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
}
return Unbinder.EMPTY;
}
}
流程很简单,反射找到带有特定注解的成员变量和待绑定资源id;执行findViewById方法后,通过反射设置变量。
遗留问题:为什么反射性能差?
编译时注解
//----------- 对外提供方法类
public class Apt {
private Apt() {
throw new AssertionError("No instances.");
}
public final static Unbinder bind(Activity activity) {
String viewBindingClassName = activity.getClass().getName() + "_ViewBinding";
try {
Class<? extends Unbinder> viewBindingClass = (Class<? extends Unbinder>) Class.forName(viewBindingClassName);
Constructor<? extends Unbinder> viewBindingConstructor = viewBindingClass.getDeclaredConstructor(activity.getClass());
Unbinder unbinder = viewBindingConstructor.newInstance(activity);
return unbinder;
} catch (Exception e) {
e.printStackTrace();
}
//返回empty,无需担心nullpoint
return Unbinder.EMPTY;
}
}
//解绑接口
public interface Unbinder {
@UiThread
void unbind();
Unbinder EMPTY = new Unbinder() {
@Override
public void unbind() {
}
};
}
//工具类
public class Utils {
public static final <T extends View> T findViewById(Activity activity, int viewId) {
return (T) activity.findViewById(viewId);
}
}
//注解解析,文件生成类
@AutoService(Processor.class)
public class KJ01Processor extends AbstractProcessor {
/**
* Filer 就是文件流输出路径,当我们用AbstractProcess生成一个java类的时候,我们需要保存在Filer指定的目录下。
*/
private Filer mFiler;
/**
* Elements 获取元素信息的工具,比如说一些类信息继承关系等。
*/
private Elements mElementUtils;
private Set<Class<? extends Annotation>> getSupportedAnnotations() {
Set<Class<? extends Annotation>> annotations = new LinkedHashSet<>();
annotations.add(BindView.class);
return annotations;
}
@Override
public Set<String> getSupportedAnnotationTypes() {
Set<String> types = new LinkedHashSet<>();
for (Class<? extends Annotation> annotation : getSupportedAnnotations()) {
//com.baoge.kj01_annotation.BindView 全路径名称
System.out.println("getCanonicalName " + annotation.getCanonicalName());
types.add(annotation.getCanonicalName());
}
return types;
}
@Override
public SourceVersion getSupportedSourceVersion() {
return SourceVersion.latestSupported();
}
@Override
public synchronized void init(ProcessingEnvironment processingEnvironment) {
super.init(processingEnvironment);
mFiler = processingEnvironment.getFiler();
mElementUtils = processingEnvironment.getElementUtils();
}
@Override
public boolean process(Set<? extends TypeElement> set, RoundEnvironment roundEnvironment) {
System.out.println("process##################");
Set<? extends Element> elements = roundEnvironment.getElementsAnnotatedWith(BindView.class);
Map<Element, List<Element>> elementsMap = new LinkedHashMap<>();
for (Element element : elements) {
Element enclosingElement = element.getEnclosingElement();
System.out.println("elment info:");
/**
* txt , MainActivity,FIELD,com.baoge.kj01_apttest.MainAcvitity
*/
System.out.println(element.getSimpleName().toString() + "\r\n" + enclosingElement.getSimpleName().toString());
System.out.println(element.getKind().toString() + "\r\n" + enclosingElement.asType().toString());
for (Modifier modifiers : element.getModifiers()) {
System.out.println("Modifier info:");
System.out.println(modifiers.getClass().getSimpleName());
}
/**
* 以外层类全名为key,element为value 保存进hashmap
*/
List<Element> viewBindElements = elementsMap.get(enclosingElement);
if (viewBindElements == null) {
viewBindElements = new ArrayList<>();
elementsMap.put(enclosingElement, viewBindElements);
}
viewBindElements.add(element);
}
// 生成代码
for (Map.Entry<Element, List<Element>> entry : elementsMap.entrySet()) {
Element enclosingElement = entry.getKey();
List<Element> viewBindElements = entry.getValue();
// public final class xxxActivity_ViewBinding implements Unbinder
String activityClassNameStr = enclosingElement.getSimpleName().toString();
ClassName activityClassName = ClassName.bestGuess(activityClassNameStr);
ClassName unbinderClassName = ClassName.get("com.baoge.kj01_libapt", "Unbinder");
TypeSpec.Builder classBuilder = TypeSpec.classBuilder(activityClassNameStr + "_ViewBinding")
.addModifiers(Modifier.FINAL, Modifier.PUBLIC).addSuperinterface(unbinderClassName)
.addField(activityClassName, "activity", Modifier.PRIVATE);
// 实现 unbind 方法
// android.support.annotation.CallSuper
// ClassName callSuperClassName = ClassName.get("androidx.annotation", "CallSuper");
// MethodSpec.Builder unbindMethodBuilder = MethodSpec.methodBuilder("unbind")
// .addAnnotation(Override.class)
// .addModifiers(Modifier.PUBLIC, Modifier.FINAL)
// .addAnnotation(callSuperClassName);
//已经引入了sdk,可以直接使用sdk中的注解
MethodSpec.Builder unbindMethodBuilder = MethodSpec.methodBuilder("unbind")
.addAnnotation(Override.class)
.addModifiers(Modifier.PUBLIC, Modifier.FINAL)
.addAnnotation(CallSuper.class);
unbindMethodBuilder.addStatement("$T activity = this.activity", activityClassName);
unbindMethodBuilder.addStatement("if (activity == null) throw new IllegalStateException(\"Bindings already cleared.\");");
// 构造函数
MethodSpec.Builder constructorMethodBuilder = MethodSpec.constructorBuilder()
.addParameter(activityClassName, "activity");
// this.target = target;
constructorMethodBuilder.addStatement("this.activity = activity");
// findViewById 属性
for (Element viewBindElement : viewBindElements) {
// target.textView1 = Utils.findRequiredViewAsType(source, R.id.tv1, "field 'textView1'", TextView.class);
// target.textView1 = Utils.findViewById(source, R.id.tv1);
String filedName = viewBindElement.getSimpleName().toString();
ClassName utilsClassName = ClassName.get("com.baoge.kj01_libapt", "Utils");
int resId = viewBindElement.getAnnotation(BindView.class).value();
constructorMethodBuilder.addStatement("activity.$L = $T.findViewById(activity, $L)", filedName, utilsClassName, resId);
// target.textView1 = null;
unbindMethodBuilder.addStatement("activity.$L = null", filedName);
}
classBuilder.addMethod(unbindMethodBuilder.build());
classBuilder.addMethod(constructorMethodBuilder.build());
// 生成类,看下效果
try {
String packageName = mElementUtils.getPackageOf(enclosingElement).getQualifiedName().toString();
JavaFile.builder(packageName, classBuilder.build())
.addFileComment("自动生成")
.build().writeTo(mFiler);
} catch (IOException e) {
e.printStackTrace();
}
}
return false;
}
}
//生成的类如下:
public final class MainActivity_ViewBinding implements Unbinder {
private MainActivity activity;
MainActivity_ViewBinding(MainActivity activity) {
this.activity = activity;
activity.txt = Utils.findViewById(activity, 2131165326);
activity.btn1 = Utils.findViewById(activity, 2131165218);
}
@Override
@CallSuper
public final void unbind() {
MainActivity activity = this.activity;
if (activity == null) throw new IllegalStateException("Bindings already cleared.");
activity.txt = null;
activity.btn1 = null;
}
}
总共分为3步骤:配置注解处理器 -> 注解处理器解析注解,保存注解信息 -> 生成文件
三,AutoService
Java编译流程
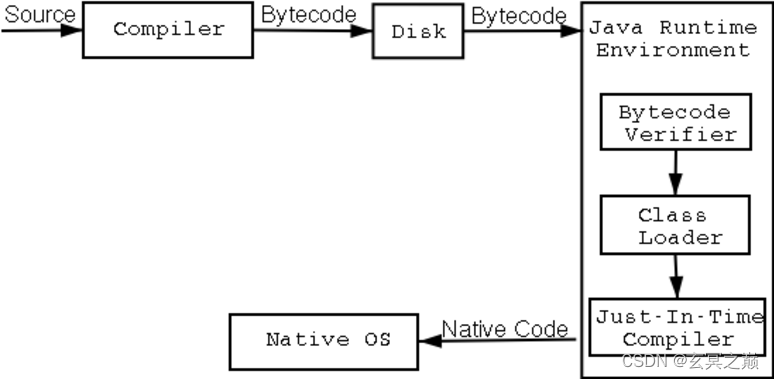
上图是一张简单的编译流程图,compiler代表我们的javac(java语言编程编译器)。这张图应该中其实缺少了一个流程,在source -> complier的过程中就应该把我们的Processor补充上去。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z1m7SdK2-1684312933069)(02_apt.assets/1620-16660089365182.png)]](https://img-blog.csdnimg.cn/078a2eaa3ca34a50b79a59087666afa7.png)
把两张图结合就是整个java的编译流程了。整个编译过程就是 source(源代码) -> processor(处理器) -> generate (文件生成)-> javacompiler -> .class文件 -> .dex(只针对安卓)。
注解预编译的方式解决了之前通过反射机制所引起的性能效率问题,其中注解预编译所采用的的就是android-apt的方式,不过最近Apt工具的作者宣布了不再维护该工具了,因为Android Studio推出了官方插件,并且可以通过gradle来简单的配置,它就是annotationProcessor。
如果你直接编译或者运行工程的话,是看不到任何输出信息的,这里还要做的一步操作是指定注解处理器的所在,需要做如下操作:
- 1、在 processors 库的 main 目录下新建 resources 资源文件夹;
- 2、在 resources文件夹下建立 META-INF/services 目录文件夹;
- 3、在 META-INF/services 目录文件夹下创建 javax.annotation.process.Processors 文件;
- 4、在 javax.annotation.process.Processors 文件写入注解处理器的全称,包括包路径;
经历了以上步骤以后方可成功运行,但是实在是太复杂了,这里推荐使用开源框架AutoService
AutoService会自动执行上面4步骤
AutoService源码分析
APT其实就是基于SPI一个工具,是JDK留给开发者的一个在编译前处理注解的接口。
SPI
SPI是Service Provider Interface的简称,是JDK默认提供的一种将接口和实现类进行分离的机制。这种机制能将接口和实现进行解耦,大大提升系统的可扩展性。
SPI机制约定:当一个Jar包需要提供一个接口的实现类时,这个Jar包需要在META-INF/services目录里同时创建一个以服务接口命名的文件。该文件里就是实现该服务接口的具体实现类。而当外部程序装配这个模块的时候,就能通过该Jar包META-INF/services/里的配置文件找到具体的实现类名,并装载实例化,完成模块的注入。
举例
(1)新建java lib工程

新建配置清单,文件名为待实现的待实现的服务全路径名称,文件内容为实现类的全路径
public interface ISpiService {
void doSomeThing();
}
//另一个工程的实现类内容
package com.baoge.kj01_spitest;
import com.baoge.kj01_libspi.ISpiService;
public class SpiServiceImp1 implements ISpiService {
@Override
public void doSomeThing() {
System.out.println(SpiServiceImp1.class.getName());
}
}
package com.baoge.kj01_spitest;
import com.baoge.kj01_libspi.ISpiService;
public class SpiServiceImp2 implements ISpiService {
@Override
public void doSomeThing() {
System.out.println(SpiServiceImp2.class.getName());
}
}
//调用
public class Test {
public static void main(String[] args) {
//使用jdk提供的类ServiceLoader来加载 ISpiService 的子类
ServiceLoader<ISpiService> loaders = ServiceLoader.load(ISpiService.class);
//遍历并调用子类方法
for (ISpiService service : loaders) {
service.doSomeThing();
}
}
}
执行结果:
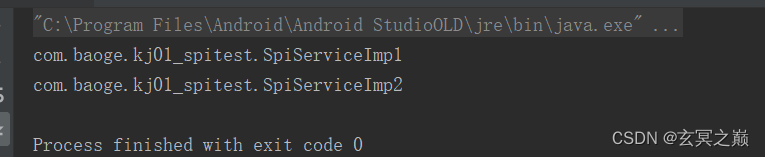
通过一个接口和实现类清单配置,就可以找到它的实现类,这就是SPI的作用。
APT
APT是SPI的一个应用。APT其实就是Java给我们提供的内置的SPI接口,作用是在编译java前处理java源码中的注解。
APT的服务接口就是这个:javax.annotation.processing.Processor
也是@AutoService(Processor.class)注解的value。
跟META_INF/service下的文件名是一致的。
Java编译器读取这个清单文件,加载实现这个接口的所有类,完成用户的注解处理逻辑。
javac认定的注解处理器是实现了 Processor接口的类,我们一般继承的AbstractProcessor就是实现了Processor接口。
在完成了APT程序的实现以及注册之后,接下来我们可以直接利用Gradle的依赖配置组:annotationProcessor引入我们的APT模块。也可以将APT模块打包出单独的Jar包程序,利用javac -processorpath xxx.jar(APT) 对指定的java源文件进行编译。
其实到这里,APT怎么被执行起来的已经很明显了。APT程序就是Javac的小插件,由javac在编译时候根据条件调起! 具体的执行过程可以结合javac源码进一步了解。
Javac执行追溯
javac本身也是一个计算机程序,当需要编译java源代码时就需要执行程序。而javac程序的main函数定义在com/sun/tools/javac/Main.java中:
public class Main {
public static void main(String[] args) throws Exception {
System.exit(compile(args));
}
public static int compile(String[] args) {
com.sun.tools.javac.main.Main compiler =
new com.sun.tools.javac.main.Main("javac");
return compiler.compile(args).exitCode;
}
public static int compile(String[] args, PrintWriter out) {
com.sun.tools.javac.main.Main compiler =
new com.sun.tools.javac.main.Main("javac", out);
return compiler.compile(args).exitCode;
}
}
可以看到,当执行javac程序将会执行上面的main方法,而main方法会调用到compile方法,在compile方法中又会创建com.sun.tools.javac.main.Main并执行其compile方法。
打开com/sun/tools/javac/main/Main.java文件,其compile实现为:
public Result compile(String[] args) {
Context context = new Context();
JavacFileManager.preRegister(context);
// 调用两参的重载compile方法
Result result = compile(args, context);
if (fileManager instanceof JavacFileManager) {
((JavacFileManager)fileManager).close();
}
return result;
}
public Result compile(String[] args, Context context) {
// 最后一个参数:processors 本次编译要执行的注解处理器集合 直接置为null
return compile(args, context, List.<JavaFileObject>nil(), null);
}
public Result compile(String[] args,
Context context,
List<JavaFileObject> fileObjects,
Iterable<? extends Processor> processors){
return compile(args, null, context, fileObjects, processors);
}
public Result compile(String[] args,
String[] classNames,
Context context,
List<JavaFileObject> fileObjects,
Iterable<? extends Processor> processors){
//......
comp = JavaCompiler.instance(context);
//......
comp.compile(fileObjects,
classnames.toList(),
processors);
//......
}
具体的编译是通过JavaCompiler#compile完成。这个方法的第三个参数即为要执行的注解处理器集合,根据执行流程追溯,此处直接传递的为null。进一步进入com/sun/tools/javac/main/JavaCompiler.java
public void compile(List sourceFileObjects,
List classnames,
Iterable<? extends Processor> processors){
//......
//初始化
initProcessAnnotations(processors);
//执行注解处理器
delegateCompiler =
processAnnotations(
enterTrees(stopIfError(CompileState.PARSE, parseFiles(sourceFileObjects))),
classnames);
//......
}
初始化
终于在JavaCompiler#compile方法中找到了javac执行过程中对APT的处理。首先initProcessAnnotations方法实现了对APT的初始化。根据源码流程可知此时,该方法参数为要执行的注解处理器集合,当前其实被设置为null。
那initProcessAnnotations方法中会怎么初始化我们的APT程序呢?实际上,在一开始我们说APT程序就是Javac的小插件,由javac在编译时候根据条件调起! 那么既然javac要调起APT中AbstractProcessor的process方法,而process方法是实例方法,自然需要先实现对APT中的AbstractProcessor(Processor接口)实现类class对象的加载。
而这个实现类由我们编写,javac如何得知要加载的APT实现类的类名呢?
结合到文章最开头处APT的注册,相信基础扎实的同学马上就能够想到:Java SPI机制。实际上,javac就是利用ServiceLoader加载注册文件,从而得到了APT实现类的类名!
很多同学听到AutoService就只能想到APT,这是片面的,实际上AutoService就是利用APT技术完成对Java SPI机制配置文件的自动生成。
ServiceLoader源码非常简单,Java与Android的实现也没有差异,可以自行阅读。
public void initProcessAnnotations(Iterable<? extends Processor> processors) {
//......
procEnvImpl = JavacProcessingEnvironment.instance(context);
procEnvImpl.setProcessors(processors);
//......
}
进入com/sun/tools/javac/processing/JavacProcessingEnvironment.java文件:
public void setProcessors(Iterable<? extends Processor> processors) {
Assert.checkNull(discoveredProcs);
initProcessorIterator(context, processors);
}
private void initProcessorIterator(Context context, Iterable<? extends Processor> processors) {
Log log = Log.instance(context);
//要执行的注解处理器集合
Iterator<? extends Processor> processorIterator;
//....
// ServiceIterator 使用SPI机制(ServiceLoader)加载注册文件并创建APT实现类实例对象
processorIterator = new ServiceIterator(processorClassLoader, log);
//....
discoveredProcs = new DiscoveredProcessors(processorIterator);
}
#执行注解处理器
回到JavaCompiler#compile,在通过initProcessAnnotations初始化注解处理器后,接着执行processAnnotations实现对注解的处理。
public JavaCompiler processAnnotations(List<JCCompilationUnit> roots,
List<String> classnames) {
//......
JavaCompiler c = procEnvImpl.doProcessing(context, roots, classSymbols, pckSymbols,
deferredDiagnosticHandler);
//......
}
进入com/sun/tools/javac/processing/JavacProcessingEnvironment.java文件:
public JavaCompiler doProcessing(Context context,
List<JCCompilationUnit> roots,
List<ClassSymbol> classSymbols,
Iterable<? extends PackageSymbol> pckSymbols,
Log.DeferredDiagnosticHandler deferredDiagnosticHandler) {
Round round = new Round(context, roots, classSymbols, deferredDiagnosticHandler);
boolean errorStatus;
boolean moreToDo;
do {
// 第一次执行apt
round.run(false, false);
errorStatus = round.unrecoverableError();
moreToDo = moreToDo(); //执行apt后是否还需要再次执行
round = round.next(
new LinkedHashSet<JavaFileObject>(filer.getGeneratedSourceFileObjects()),
new LinkedHashMap<String,JavaFileObject>(filer.getGeneratedClasses()));
if (round.unrecoverableError())
errorStatus = true;
} while (moreToDo && !errorStatus);
// 最后一次执行apt
round.run(true, errorStatus);
//......
}
此处代码包含了本文需要解决的第2、3个文件。注解处理器的执行是由javac调起我们APT实现类的process方法,而这个方法就是在round.run中调起的。
第一次执行
第一次执行process方法是在do-while中调起round.run(false, false)完成
void run(boolean lastRound, boolean errorStatus) {
try {
if (lastRound) {
filer.setLastRound(true);
Set<Element> emptyRootElements = Collections.emptySet(); // immutable
RoundEnvironment renv = new JavacRoundEnvironment(true,
errorStatus,
emptyRootElements,
JavacProcessingEnvironment.this);
//只有最后一次执行此处
discoveredProcs.iterator().runContributingProcs(renv);
} else {
//不是最后一次执行此处
discoverAndRunProcs(context, annotationsPresent, topLevelClasses, packageInfoFiles);
}
} catch (Throwable t) {
//.......
} finally {
//.......
}
}
如果我们的APT实现类将会被javac调起process方法,它的原型是:
public boolean process(Set<? extends TypeElement> set, RoundEnvironment roundEnvironment)
在编译过程中第一次由discoverAndRunProcs调起:
private void discoverAndRunProcs(Context context,
Set<TypeElement> annotationsPresent,
List<ClassSymbol> topLevelClasses,
List<PackageSymbol> packageInfoFiles) {
//......
//调用APT实现类的process方法的参数
RoundEnvironment renv = new JavacRoundEnvironment(false,
false,
rootElements,
JavacProcessingEnvironment.this);
while(unmatchedAnnotations.size() > 0 && psi.hasNext() ) {
ProcessorState ps = psi.next();
Set<String> matchedNames = new HashSet<String>();
Set<TypeElement> typeElements = new LinkedHashSet<TypeElement>();
for (Map.Entry<String, TypeElement> entry: unmatchedAnnotations.entrySet()) {
String unmatchedAnnotationName = entry.getKey();
//匹配apt实现类支持的注解
if (ps.annotationSupported(unmatchedAnnotationName) ) {
matchedNames.add(unmatchedAnnotationName);
//调用APT实现类的process方法的参数
TypeElement te = entry.getValue();
if (te != null)
typeElements.add(te);
}
}
if (matchedNames.size() > 0 || ps.contributed) {
//执行注解处理器
boolean processingResult = callProcessor(ps.processor, typeElements, renv);
/**
* TODO 问题3
* APT实现类返回值为ture,删除它能处理的注解信息,
* 这样其他需要处理相同注解的注解处理器就得不到执行了
*/
if (processingResult) {
// unmatchedAnnotations : 所有的注解集合
// matchedNames:匹配此注解处理器的注解
unmatchedAnnotations.keySet().removeAll(matchedNames);
}
}
}
//......
}
private boolean callProcessor(Processor proc,Set<? extends TypeElement> tes,
RoundEnvironment renv) {
return proc.process(tes, renv);
}
process方法返回值
其实到现在,我们已经看到文章开头的第三个问题的答案。
在javac执行时可以指定多个APT程序(-processorpath 指定的jar包),一个APT程序可以包含多个APT实现类,所以javac会将指定的多个APT程序中的所有注册的APT实现类加载并实例化,使用迭代器Iterator装载。
在discoverAndRunProcs中对所有要执行的APT实现类进行迭代,依次执行APT实现类的process方法,顺序由注册顺序决定。
但是执行APT实现类的前提是:有APT实现类声明的支持处理的注解信息。而若先注册的APT实现类其process方法返回true,则会在执行结束此APT实现类后,通过unmatchedAnnotations.keySet().removeAll(matchedNames);将其能处理的注解信息删除。这样后注册的APT实现类将会因为没有匹配处理的注解而得不到执行。
比如AProcessor声明处理@Test注解,而BProcessor也声明处理@Test注解,而AProcessor先于BProcessor注册,AProcessor的process方法返回ture。此时BProcessor不会执行。
第2-N次执行
回到JavacProcessingEnvironment#doProcessing
public JavaCompiler doProcessing(Context context,
List<JCCompilationUnit> roots,
List<ClassSymbol> classSymbols,
Iterable<? extends PackageSymbol> pckSymbols,
Log.DeferredDiagnosticHandler deferredDiagnosticHandler) {
Round round = new Round(context, roots, classSymbols, deferredDiagnosticHandler);
boolean errorStatus;
boolean moreToDo;
do {
// 第一次执行apt
round.run(false, false);
errorStatus = round.unrecoverableError();
moreToDo = moreToDo(); //执行apt后是否还需要再次执行
round = round.next(
new LinkedHashSet<JavaFileObject>(filer.getGeneratedSourceFileObjects()),
new LinkedHashMap<String,JavaFileObject>(filer.getGeneratedClasses()));
if (round.unrecoverableError())
errorStatus = true;
} while (moreToDo && !errorStatus);
// 最后一次执行apt
round.run(true, errorStatus);
//......
}
round.run(false, false);是在do-while循环中被调用,这也是为什么本节小标题为:第2-N次执行。执行多轮的条件为:moreToDo && !errorStatus。
第二个条件是执行APT实现类时未产生异常,而第一个条件:moreTodo
private boolean moreToDo() {
return filer.newFiles();
}
public boolean newFiles() {
return (!generatedSourceNames.isEmpty())
|| (!generatedClasses.isEmpty());
}
如果熟悉APT的同学,应该清楚,一般的我们利用APT实现在编译阶段生成新的Java类:
//在apt中生成 Test.java
JavaFileObject sourceFile = processingEnv.getFiler()
.createSourceFile("com.xx.Test");
OutputStream os = sourceFile.openOutputStream();
os.write("package com.xx;\n public class Test{}".getBytes());
os.close();
JavaPoet框架实际上就是封装了这些API。所以学习技术还是应该掌握本质与原理,否则学习其他相关联或者类似技术时,只能从头开始,很吃力。这也是所谓面试八股文的意义,掌握和没掌握,确实有差别!
在执行到os.close()时就会执行一次generatedSourceNames.add(typeName)。
也就是说APT执行多次的条件是:在APT执行是生成了一个java源文件(或者class文件)都会导致APT再执行一次,这次执行只会处理新生成的类:
//只处理新生成类的round
round = round.next( new LinkedHashSet<JavaFileObject>(filer.getGeneratedSourceFileObjects()),
new LinkedHashMap<String,JavaFileObject>(filer.getGeneratedClasses()));
//执行apt
round.run(false, false);
而如果第二轮执行又新生成了类,就会执行第三轮、第四轮…,直到不再产生新的.java(或.class)
#最后一次执行
不产生新的类文件时会退出do-While循环,此时会执行一次round.run(true, errorStatus);
void run(boolean lastRound, boolean errorStatus) {
try {
if (lastRound) {
filer.setLastRound(true);
Set<Element> emptyRootElements = Collections.emptySet(); // immutable
RoundEnvironment renv = new JavacRoundEnvironment(true,
errorStatus,
emptyRootElements,
JavacProcessingEnvironment.this);
//只有最后一次执行此处
discoveredProcs.iterator().runContributingProcs(renv);
} else {
//不是最后一次执行此处
discoverAndRunProcs(context, annotationsPresent, topLevelClasses, packageInfoFiles);
}
} catch (Throwable t) {
//.......
} finally {
//.......
}
}
此时,会通过discoveredProcs.iterator().runContributingProcs(renv);执行最后一轮APT。
public void runContributingProcs(RoundEnvironment re) {
if (!onProcInterator) {
// process方法第一个参数
Set<TypeElement> emptyTypeElements = Collections.emptySet();
while(innerIter.hasNext()) {
ProcessorState ps = innerIter.next();
//执行最后一轮
if (ps.contributed)
callProcessor(ps.processor, emptyTypeElements, re);
}
}
}
可以看到在执行最后一轮时,会构建一个空Set集合作为process方法的第一个参数。这么做的意义猜测是为了将工作和打扫分开。
第一轮执行:处理你的工作
第X轮执行: 处理你的工作
最后执行:在处理完工作之后,再通知一次,执行收尾。
如:
public class LanceProcessor extends AbstractProcessor {
FileOutputStream fos;
int i = 0;
@Override
public boolean process(Set<? extends TypeElement> set, RoundEnvironment roundEnvironment) {
//最后一轮执行会为true
if (roundEnvironment.processingOver()) {
if (fos != null) {
//最后一轮收尾,close
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
} else {
if (fos == null) {
// 只在第一轮执行初始化。
fos = new FileOutputStream(xxx);
}
}
fos.write(("第" + i + "次执行").getBytes());
i++;
//......
return true;
}
}
总结
Q:APT原理是什么,怎么被执行起来的?
A:在javac编译时,先通过SPI机制加载所有的APT实现类,并将解析到需要编译的java源文件中所有的注解信息,与APT声明的支持处理的注解信息进行匹配,若待编译的源文件中存在APT声明的注解,则调起APT实现类的process方法。
Q:APT中process方法到底执行几次?为什么这么设计?
A:最少执行两次,最多无数次。最后一次执行可以视为Finish结束通知,执行收尾工作。
Q:APT中process方法boolean返回值返回true或者false有什么影响?
A: true:声明的注解只能被当前APT处理;false:在当前APT处理完声明的注解后,仍能被其他APT处理。
遗留问题:回调中的对象是接口,没有找到javac的代码,找到相应的实现类
AutoService分析
AutoService是Google开发一个自动生成SPI清单文件的框架,一般我们用它来自动帮我们注册APT文件(全称是Annotation Process Tool,或者叫注解处理器,AbstractProcessor的实现)。
java
@Documented
@Retention(CLASS)
@Target(TYPE)
public @interface AutoService {
/** Returns the interfaces implemented by this service provider. */
Class<?>[] value();
}
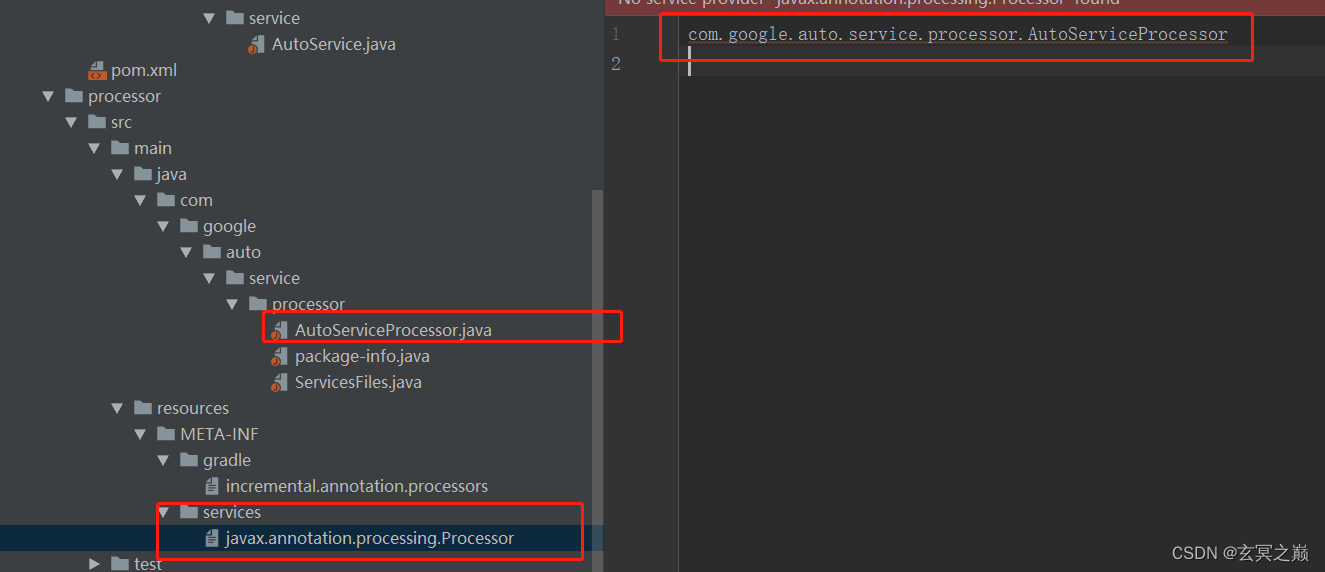
AutoService手动配置了注解处理器实现类清单。
private void processImpl(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {
if (roundEnv.processingOver()) { //本轮注解处理完毕
generateConfigFiles();//生成SPI注册文件
} else { //未处理完毕,继续处理
processAnnotations(annotations, roundEnv);//整理需要注册的文件,放入缓存
}
}
private void processAnnotations(
Set<? extends TypeElement> annotations, RoundEnvironment roundEnv){
//获取所有加了AutoService注解的类
Set<? extends Element> elements = roundEnv.getElementsAnnotatedWith(AutoService.class);
for (Element e : elements) {
//将Element转成TypeElement
TypeElement providerImplementer = MoreElements.asType(e);
//获取AutoServce注解指定的value
AnnotationMirror annotationMirror = getAnnotationMirror(e, AutoService.class).get();
//获取value集合
Set<DeclaredType> providerInterfaces = getValueFieldOfClasses(annotationMirror);
//如果没有指定value,报错
if (providerInterfaces.isEmpty()) {
error(MISSING_SERVICES_ERROR, e, annotationMirror);
continue;
}
//遍历所有的value,获取value的完整类名(例如javax.annotation.processing.Processor)
for (DeclaredType providerInterface : providerInterfaces) {
TypeElement providerType = MoreTypes.asTypeElement(providerInterface);
//判断是否是继承关系,是则放入providers缓存起来,否则报错
if (checkImplementer(providerImplementer, providerType, annotationMirror)) {
providers.put(getBinaryName(providerType), getBinaryName(providerImplementer));
} else {
//报错代码,略
}
}
}
}
注解处理完毕,就会生成SPI注册文件。如果SPI路径上文件已经存在,先要把已存在的SPI清单读进内存,再把新的provider加进去,然后全部写出,覆盖原来的文件。这部分逻辑如下:
private void generateConfigFiles() {
Filer filer = processingEnv.getFiler();//获取文件工具类,processingEnv是AbstractProcessor的成员变量,直接拿来用。
//遍历之前解析的providers缓存
for (String providerInterface : providers.keySet()) {
//providerInterface就是value字段指定的接口,例如javax.annotation.processing.Processor
String resourceFile = "META-INF/services/" + providerInterface;
log("Working on resource file: " + resourceFile);
try {
SortedSet<String> allServices = Sets.newTreeSet();
try {
//已经存在的SPI文件
FileObject existingFile =
filer.getResource(StandardLocation.CLASS_OUTPUT, "", resourceFile);
//SPI文件中的service条目清单
Set<String> oldServices = ServicesFiles.readServiceFile(existingFile.openInputStream());
log("Existing service entries: " + oldServices);
allServices.addAll(oldServices);
} catch (IOException e) {
log("Resource file did not already exist.");
}
//新的service条目清单
Set<String> newServices = new HashSet<>(providers.get(providerInterface));
//如果已经存在,则不处理
if (!allServices.addAll(newServices)) {
log("No new service entries being added.");
continue;
}
//以下是将缓存的services写入文件中。
log("New service file contents: " + allServices);
FileObject fileObject =
filer.createResource(StandardLocation.CLASS_OUTPUT, "", resourceFile);
try (OutputStream out = fileObject.openOutputStream()) {
ServicesFiles.writeServiceFile(allServices, out);
}
log("Wrote to: " + fileObject.toUri());
} catch (IOException e) {
fatalError("Unable to create " + resourceFile + ", " + e);
return;
}
}
}
AutoServiceProcessor的主要功能就是将加了AutoService注解的类,加到SPI注册文件中。SPI文件名称(或者叫服务)可以通过value指定。
AutoService源码:https://github.com/google/auto
javc源码:https://github.com/openjdk/jdk/tree/9842ff4129b756abb5761cdca71126508224875f/src/jdk.compiler/share/classes/com/sun/tools/javac
参考:
https://www.jb51.net/article/267482.htm
https://blog.csdn.net/zzz777qqq/article/details/127624497















 131
131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









