







1、获取Disruptor
Maven仓库
https://search.maven.org/search?q=g:com.lmax%20AND%20a:disruptor
源码
https://github.com/LMAX-Exchange/disruptor
2、一个简单的事件生产者和消费者示例
首先创建一个事件数据类型:

创建一个事件工厂,使Disruptor可以用来生成RingBuffer的预分配条目:

创建一个事件消费者:

在本例中,我们假设这个事件数据是来自于某种I/O设备,源数据封装在ByteBuffer中。
从3.0版本开始,Disruptor支持Lambda风格的API,帮助开发人员可以把复杂性封装在RingBuffer中,建议的发布消息的方法是通过结合使用翻译器(Translator)来发布数据(Event Publisher/Event Translator)。
该方法的好处是可以把数据转换的代码单独剥离出来,便于进行单元测试。Disruptor提供了多种不同的转换器接口(EventTranslator、EventTranslatorOneArg、EventTranslatorTwoArg等)。

也可以用非Lambda风格的传统代码来编写生产者:

从上面的代码片段可以看出,在底层代码逻辑中,发布一个事件需要两个步骤,第一个步骤是从RingBuffer中获取一个可用的数据槽(调用RingBuffer.next()),同时需要把发布操作封装在一个try/finally代码块中,每当获取了一个数据槽,那么必须要发布这个sequence。如果不遵守这个规则,那么会导致Disruptor中的状态损坏,特别是在多个生产者的场景中,会导致消费者停止消费,只有重启系统才能重置状态。因此,这也是推荐使用EventTranslator API的原因。
最后一个步骤是把上述的各个部分组装起来,可以用较复杂的纯手工组装,也可以使用简易的基于DSL方式的组装,虽然一些复杂的配置选项不能用DSL,但是DSL已经可适用于大多数场合。

使用Java8函数风格的API:
在代码中使用了匿名函数,节省了两个类handler、producer。

不使用匿名函数,可以使用方法引用:

3、基本的调优选项
提高性能的调优选项,主要有两个方面:(1)单个或者多个生产者;(2)等待事件到达的策略。
3.1 Single vs. Multiple Producers
在并行系统中,提高性能的方法是遵从单写原则(Single Writer Principle),单写原则可以避免临界资源的锁竞争。
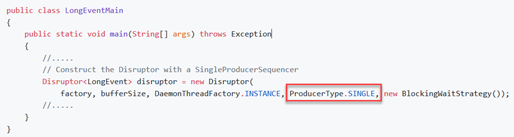
性能差异可以通过测试程序检测:
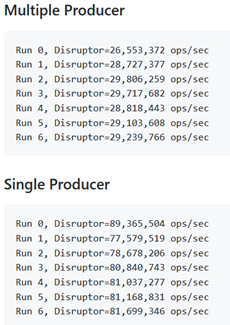
从测试结果看,单写模式比多写模式性能高出2.8倍左右。
3.2 等待事件到达的策略
- BlockingWaitStrategy
Disruptor的默认等待策略是BlockingWaitStrategy,该策略的内部使用锁和条件变量来处理线程的唤醒。在所有的等待策略中BlockingWaitStrategy是最慢的,但是对CPU的使用又是最保守的,在大多数部署场景中,该策略的行为表现是最恒定的。
- SleepingWaitStrategy
SleepingWaitStrategy也是试图保守使用CPU,内部使用了一个简单的忙等待循环(busy wait loop),并在循环中调用LockSupport.parkNanos(1),在一个典型的Linux系统中会暂停线程大约60μs。
这个策略可以避免使用计数器、和对条件变量发送信号方面的消耗,但是在生产者和消费者线程之间移动事件的平均延迟将会更高。
SleepingWaitStrategy适用于对低延时不苛求,但是对生产者线程要求低影响的场景中,例如异步写日志就是一个适用的场景。
注意事项:On 32 bit Linux systems it appears that LockSupport.parkNanos() is quite expensive, therefore using the SleepingWaitStrategy is not recommended.
- YieldingWaitStrategy
YieldingWaitStrategy适用于低延迟要求的系统中,该策略可以基于改进延迟的目标来选择刻录CPU周期,策略内部使用忙自旋(busy spin)来等待sequence增加到一个合适的值,在循环中调用Thread.yield()来允许其它排队线程去执行。
该策略适用于要求非常高的性能,并且事件处理线程小于CPU逻辑核数的场景,例如开启了超线程的部署环境。
- BusySpinWaitStrategy
BusySpinWaitStrategy具有最高的性能,也就是最低的数据推送延迟,但是对部署环境的限制条件最高。只有在事件处理程序线程数量小于机器的物理核心数量时,才应使用此等待策略,例如,部署环境应禁用超线程。
3.3 清理RingBuffer中的数据对象
当通过Disruptor传递数据,我们希望在数据处理完成之后,对RingBuffer中已处理数据进行及时清理。如果是单个事件处理器,那么在就在该事件处理器中执行清理。如果存在事件处理器链,那么应该在处理器链末端的处理器中执行清理。

















 1547
1547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











