






.Z、.zip 压缩文件解压,识别文件编码并转为可读(支持中文)的PDF文件
pom.xml 重点
<!-- 检测编码 -->
<dependency>
<groupId>com.googlecode.juniversalchardet</groupId>
<artifactId>juniversalchardet</artifactId>
<version>1.0.3</version>
</dependency>
<!-- 转pdf -->
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itext7-core</artifactId>
<version>7.1.16</version>
<type>pom</type>
</dependency>
<!-- 解压.Z文件 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-compress</artifactId>
<version>1.21</version>
</dependency>
<!-- ImmutableMap -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>20.0</version>
</dependency>
controller
import com.google.common.collect.ImmutableMap;
import com.itextpdf.kernel.font.PdfFont;
import com.itextpdf.kernel.font.PdfFontFactory;
import com.itextpdf.kernel.pdf.PdfDocument;
import com.itextpdf.kernel.pdf.PdfWriter;
import com.itextpdf.layout.Document;
import com.itextpdf.layout.element.Paragraph;
import org.apache.commons.compress.compressors.z.ZCompressorInputStream;
import org.mozilla.universalchardet.UniversalDetector;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RestController;
import java.io.*;
import java.nio.charset.Charset;
import java.nio.file.*;
import java.nio.file.attribute.BasicFileAttributes;
import java.util.Enumeration;
import java.util.HashMap;
import java.util.Map;
import java.util.zip.ZipEntry;
import java.util.zip.ZipFile;
/**
* 文件处理控制器
* .Z、.zip 压缩文件解压,识别文件编码并转为可读(支持中文)的PDF文件
* @author KingFu
*/
@RestController
public class FileConversionController {
/**
* directoryPath: 目标路径
* unZPath: 解压后的文件路径
* pdfPath: pdf文件路径
* ttcPath: 宋体,ttc字体文件路径
*/
final Map<String, String> pathMap = ImmutableMap.of(
"directoryPath", "C:/Users/23228/backupdata/directory/",
"unZPath", "C:/Users/23228/backupdata/unZ/",
"pdfPath", "C:/Users/23228/backupdata/pdf/",
"ttcPath", "C:/Users/23228/backupdata/simsun.ttc,0");
/**
* 文件类型
*/
final String[] fileType = new String[]{".Z", ".zip", ".pdf"};
/**
* 只处理BC开头的文件
*/
final String startWith = "BC";
/**
* 文件转换
* @param map
* @return
* @throws Exception
*/
@PostMapping("/fileConversion")
public ResponseEntity<String> fileConversion(@RequestBody HashMap<String, Object> map) throws Exception {
// 遍历目录
Files.walkFileTree(Paths.get(pathMap.get("directoryPath")), new SimpleFileVisitor<Path>() {
@Override
public FileVisitResult preVisitDirectory(Path dir, BasicFileAttributes attrs) {
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
String fileName = file.getFileName().toString();
// 检查文件名是否以 BC 开头
if (fileName.startsWith(startWith)) {
System.out.println("fileName-----------:"+fileName);
// 检查文件是否是为 .Z 的压缩文件
if (fileName.endsWith(fileType[0])) {
File unZFile = deCompressZFile(file.toFile());
if(unZFile != null) {
conversionPdfFile(unZFile, null);
}
}
// 检查文件是否是为 .zip 的压缩文件
else if (fileName.endsWith(fileType[1])) {
// 支持中文文件名
try (ZipFile zipFile = new ZipFile(file.toFile(), Charset.forName("GBK"))) {
Enumeration<? extends ZipEntry> entries = zipFile.entries();
while (entries.hasMoreElements()) {
ZipEntry entry = entries.nextElement();
try (
InputStream zis = zipFile.getInputStream(entry)
) {
// 创建一个临时文件
File tempFile = File.createTempFile(entry.getName(), null);
// 创建一个输出流来写入临时文件
try (OutputStream outputStream = new FileOutputStream(tempFile)) {
// 创建一个缓冲区来读取和写入数据
byte[] buffer = new byte[1024];
int bytesRead;
// 读取输入流并写入输出流
while ((bytesRead = zis.read(buffer)) != -1) {
outputStream.write(buffer, 0, bytesRead);
}
// 刷新输出流以确保所有数据都已写入文件
outputStream.flush();
conversionPdfFile(tempFile, pathMap.get("pdfPath") + nameWithoutExtension(entry.getName()));
}
}
}
}
} else {
// 不是 pdf 文件
if (!fileName.endsWith(fileType[2])) {
conversionPdfFile(file.toFile(), null);
}
}
}
return FileVisitResult.CONTINUE;
}
});
return null;
}
/**
* 解压 .Z 文件
* @param file
* @return
*/
private File deCompressZFile(File file) {
int buffersize = 2048;
FileOutputStream out = null;
ZCompressorInputStream zIn = null;
File outFile = null;
try(FileInputStream fin = new FileInputStream(file);
BufferedInputStream in = new BufferedInputStream(fin);
) {
//解压后的文件存放路径及文件名
String name = file.getName().substring(0, file.getName().indexOf("."));
outFile = new File(pathMap.get("unZPath") + name);
out = new FileOutputStream(outFile);
zIn = new ZCompressorInputStream(in);
final byte[] buffer = new byte[buffersize];
int n = 0;
while (-1 != (n = zIn.read(buffer))) {
out.write(buffer, 0, n);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
return outFile;
}
}
/**
* 去掉后缀名
* @param fileName
* @return
*/
private String nameWithoutExtension(String fileName) {
return fileName != null && fileName.lastIndexOf('.' )> -1 ?
fileName.substring(0, fileName.lastIndexOf('.')) : fileName;
}
/**
* 转码为可读编码的 Pdf 文件
* @param file
* @param filePath
* @throws IOException
*/
private void conversionPdfFile(File file, String filePath) throws IOException {
String path = filePath==null ? pathMap.get("pdfPath") + file.getName() + fileType[2]
: nameWithoutExtension(filePath) + fileType[2];
byte[] byt = Files.readAllBytes(Paths.get(file.getPath()));
// 使用 juniversalchardet 检测字符集所属编码
UniversalDetector detector = new UniversalDetector(null);
detector.handleData(byt, 0, byt.length);
detector.dataEnd();
String encoding = detector.getDetectedCharset();
if (encoding == null) {
System.out.println("No encoding detected.");
} else {
System.out.println("Detected encoding: " + encoding);
// 使用检测到的编码读取文件内容,并转换为可读的 Pdf 文件
try (InputStreamReader reader = new InputStreamReader(new ByteArrayInputStream(byt), encoding);
BufferedReader bufferedReader = new BufferedReader(reader);
PdfWriter writer = new PdfWriter(path);
PdfDocument pdfDoc = new PdfDocument(writer);
Document document = new Document(pdfDoc);
) {
// PdfFont font = PdfFontFactory.createFont(ttcPath, PdfEncodings.IDENTITY_H); // 指定字体文件
PdfFont font = PdfFontFactory.createFont("STSongStd-Light", "UniGB-UCS2-H");
String line;
while ((line = bufferedReader.readLine()) != null) {
// 将每一行文本添加到 Paragraph 中
Paragraph p = new Paragraph(line).setFont(font);
// 将 Paragraph 添加到 Document 中
document.add(p);
}
// 关闭 Document,这将触发 PDF 的创建
// document.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
效果:
目标路径 :
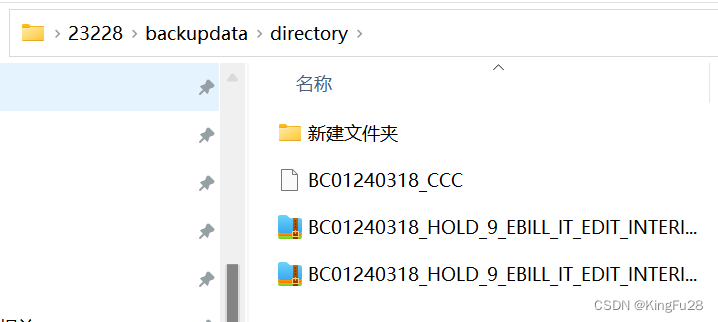
.Z压缩文件
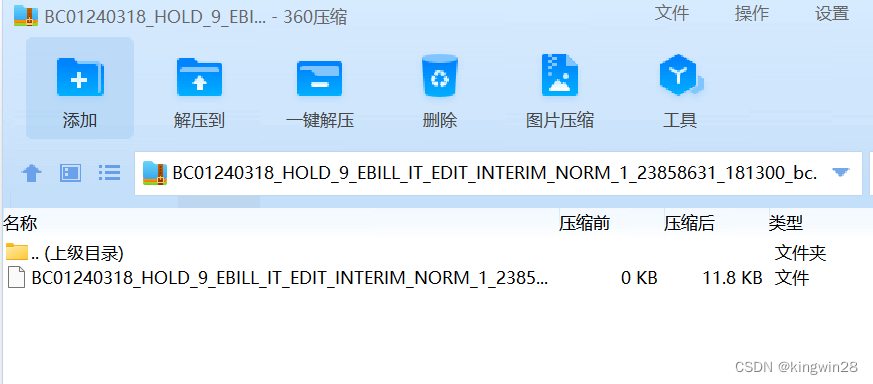
.zip压缩文件
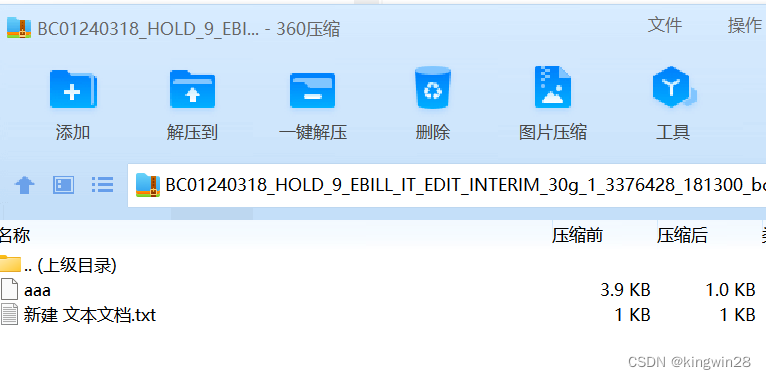
处理后的pdf文件
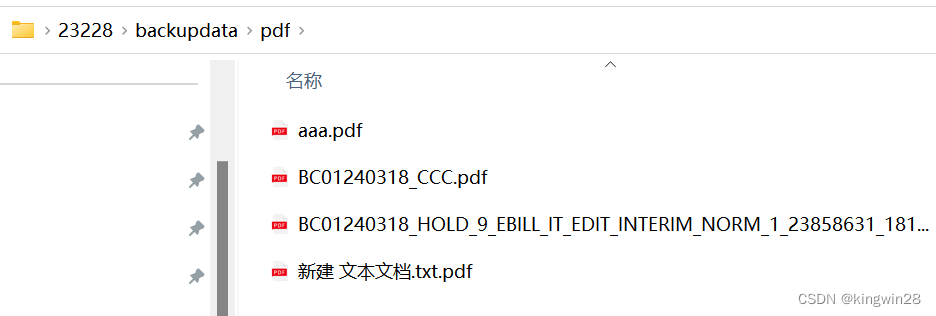
原文件,编码问题识别不出中文

处理后的PDF文件,识别编码转换后支持中文

调用:

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









