









lxml和xpath
1. xpath语法
1.1 什么是xpath
- XPath(XML Path Language)是一种XML的查询语言: 他能在XML树状结构中寻找节点。XPath 用于在 XML 文档中通过元素和属性进行导航
- xml是一种标记语法的文本格式: xpath可以方便的定位xml中的元素和其中的属性值。lxml是python中的一个包,这个包中包含了将html文本转成xml对象,和对对象执行xpath的功能
- XPath 是一个 W3C 标准: XPath 于 1999 年 11 月 16 日 成为 W3C 标准。XPath 被设计为供 XSLT、XPointer 以及其他 XML 解析软件使用。您可以在我们的《W3C 教程》中阅读更多有关 XPath 标准的信息。
- XPath 路径表达式: XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
- XPath 标准函数: XPath 含有超过 100 个内建的函数。这些函数用于字符串值、数值、日期和时间比较、节点和 QName 处理、序列处理、逻辑值等等。
- XPath 节点: 在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档节点(或称为根节点)。节点关系有,父,子,先辈,同胞,后代等。基本上是按照节点的逻辑关系。
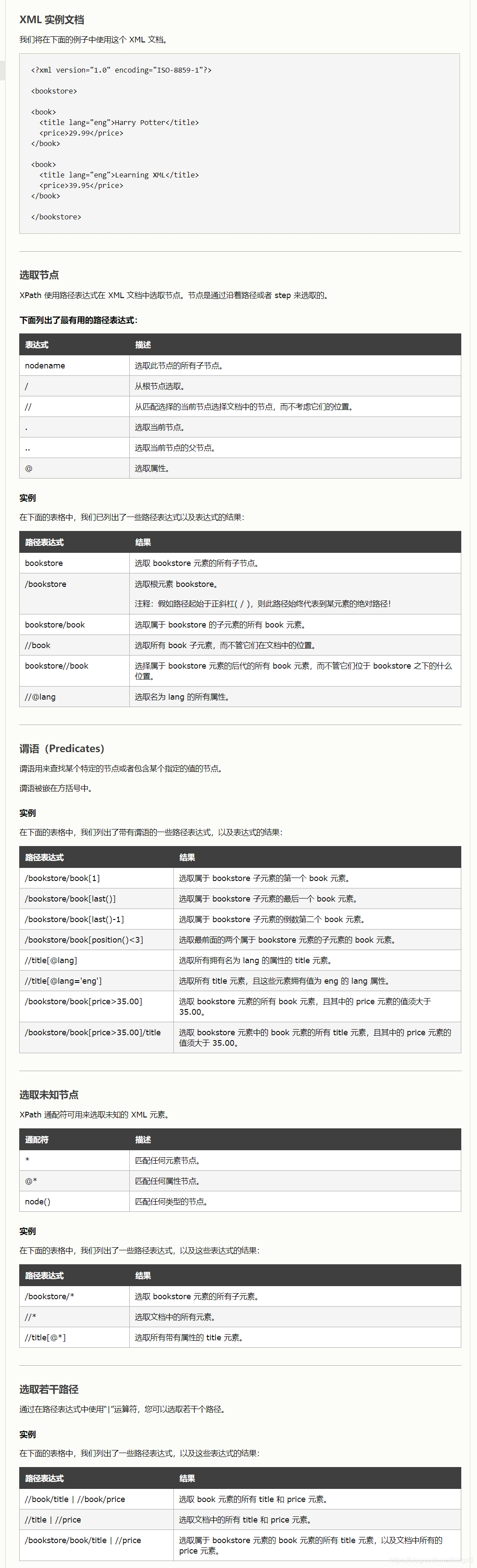
1.2 xpath语法
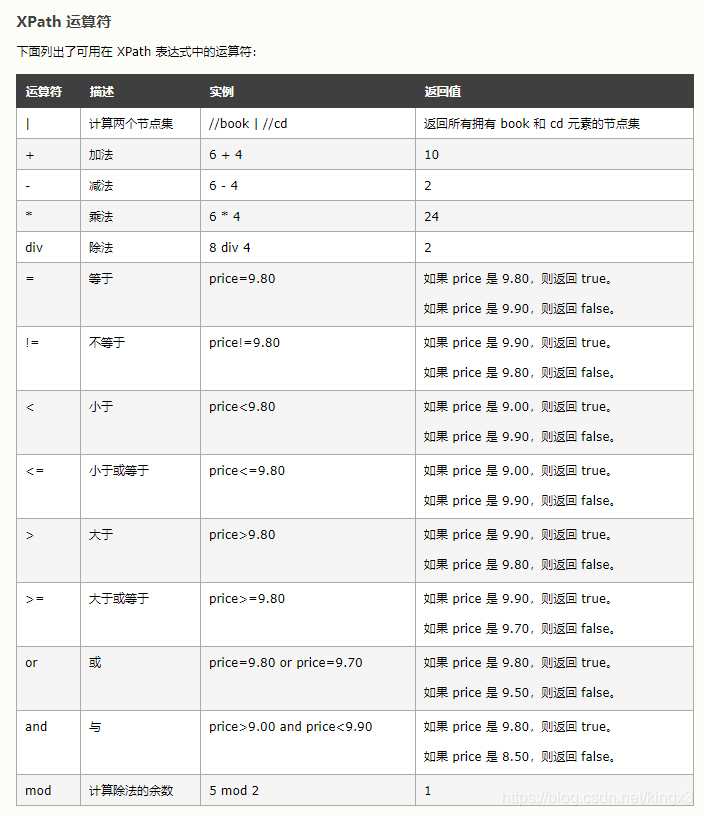
1.3 xpath运算符
2. xpath如何使用?
2.1 lxml库
- 在Python中,我们安装lxml库来使用XPath 技术。lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取HTML/XML数据利用etree.HTML,将字符串转化为Element对象
- lxml python 官方文档:http://lxml.de/index.html
- 可使用 pip 安装:pip install lxml
- lxml 可以⾃动修正 html 代码
2.2 etree用法
-
etree.HTML()
-
etree.HTML()可以用来解析字符串格式的HTML文档对象,将传进去的字符串转变成_Element对象。作为_Element对象,可以方便的使用getparent()、remove()、xpath()等方法。
-
如果想通过xpath获取html源码中的内容,就要先将html源码转换成_Element对象,然后再使用xpath()方法进行解析。
-
etree.tostring()
-
etree.tostring()方法用来将_Element对象转换成字符串。一般通过简单的xpath表达式无法得到想要的内容的时候我就会用该方法。
form lxml import html
# 在3.6之后的版本中,使用html.etree引入etree
# 注意html.etree.HTML()后边的HTML大写
3. 如何写入csv文件
-
定义表头
- csv.DictWriter(f, fieldnames=[‘title’, ‘star’, ‘quote’, ‘url’])
-
写入表头
- writer.writeheader()
-
逐行写入数据
- writer.writerow()
-
部分代码示例:
with open('result/douban.csv', 'w', encoding='utf-8-sig', newline='') as f:
# 定义头部信息
writer = csv.DictWriter(f, fieldnames=['title', 'star', 'quote', 'url'])
# 写入表头
writer.writeheader()
for each in movieList:
# 逐行写入movieList中的数据
writer.writerow(each)
4. 抓取豆瓣TOP250
- 代码示例:
# !/usr/bin/python
# Filename: 爬取豆瓣TOP250.py
# Data : 2020/07/23
# Author : --king--
# ctrl+alt+L自动加空格格式化
# 需求: 爬取标题,评分,详情页地址,引言1-10数据保存到scv文件当中
import requests
from lxml import html
import csv
# 1. 获取html源码
def getSource(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3756.400 QQBrowser/10.5.4043.400'}
req = requests.get(url, headers=headers)
# 避免编码问题,对html源码进行编码
req.encoding = 'utf-8'
return req.text
# 2. 用etree处理html源码
def getEveryItem(source):
html_ele = html.etree.HTML(source)
movieItemList = html_ele.xpath('//div[@class="info"]')
# 显示信息
movieList = []
# 获取title
for eachMovie in movieItemList:
# 存储标题,评分,详情页的地址,引言
movieDict = {}
title = eachMovie.xpath('div[@class="hd"]/a/span[@class="title"]/text()')
other_title = eachMovie.xpath('div[@class="hd"]/a/span[@class="other"]/text()')
# 解决结果带[]的问题,添加切片[0]
link = eachMovie.xpath('div[@class="hd"]/a/@href')[0]
star = eachMovie.xpath('div[@class="bd"]/div/span/@content')[0]
# 部分结果没有quote内容,故增加判断。有结果的切片,没结果返回空值
quote = eachMovie.xpath('div[@class="bd"]/p/span/text()')
if quote:
quote = quote[0]
else:
quote = ''
# 创建字典
movieDict['title'] = ''.join(title + other_title)
movieDict['url'] = link
movieDict['star'] = star
movieDict['quote'] = quote
movieList.append(movieDict)
print(movieList)
return movieList
# 3.写入数据
def writeData(movieList):
# 编码格式需要采用‘utf-8-sig’,否则excel打开会乱码
# 为了避免数据有空行,添加newline=''参数
with open('result/douban.csv', 'w', encoding='utf-8-sig', newline='') as f:
# 定义头部信息,逐行保存时,写入时会按照表头的key填入value
writer = csv.DictWriter(f, fieldnames=['title', 'star', 'quote', 'url'])
# 写入表头
writer.writeheader()
for each in movieList:
# 逐行写入movieList中的数据
writer.writerow(each)
# 4 主函数
if __name__ == '__main__':
movieList = []
# 获取url
n = int(input('请输入想要抓取的页数:'))
for i in range(n):
# 生成url
url = 'https://movie.douban.com/top250?start={}'.format(str(i * 25))
# 获取源码
source = getSource(url)
# 获取数据,把每一页的数据都添加到movieList中
movieList += getEveryItem(source)
# 写入movieList数据
writeData(movieList)
5. 需要注意的地方
- 学会使用函数的封装,尽量使主函数逻辑清晰明了
- 当xpath规则较长时,把相同的父节点提取出来,再从父节点中逐个匹配想要的子节点
- 路径可以采用相对路径,即开头不含/,如path/xxx,也可以采用绝对路径/path/xxx
- 注意对节点数据为空时的处理,注意超出索引的报错的处理
- 对数据结果的整理,如果出现[ ],’ '之类的内容可以用切片取出想要的内容
- 在字典定义时,可以利用’‘.join()拼接数据
- 写入的csv文件如果想要在excel中打开没有乱码,with open()或者open()中编码格式要采用’utf-8-sig‘
- 对结果空行的处理,with open()需要添加newline = ’‘参数
- csv写入时,fieldnames的值要与字典的key相对应,但顺序可以不一致
- 通过format格式化字符串数据时,传入的数据应当时字符串,或者经过str()格式化
- 注意每一个函数的传入参数和返回值
- 数据爬取取完毕后要对爬取结果进行检查,并调整代码















 6790
6790











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











