







mysql中间件研究( Atlas,cobar,TDDL,mycat,heisenberg,Oceanus,vitess,OneProxy
)
mysql-proxy是官方提供的mysql中间件产品可以实现负载平衡,读写分离,failover等,但其不支持大数据量的分库分表且性能较差。下面介绍几款能代替其的mysql开源中间件产品,Atlas,cobar,tddl,让我们看看它们各自有些什么优点和新特性吧。
Atlas
Atlas是由 Qihoo 360, Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目。它是在mysql-proxy 0.8.2版本的基础上,对其进行了优化,增加了一些新的功能特性。360内部使用Atlas运行的mysql业务,每天承载的读写请求数达几十亿条。
Altas架构:
Atlas是一个位于应用程序与MySQL之间,它实现了MySQL的客户端与服务端协议,作为服务端与应用程序通讯,同时作为客户端与MySQL通讯。它对应用程序屏蔽了DB的细节,同时为了降低MySQL负担,它还维护了连接池。

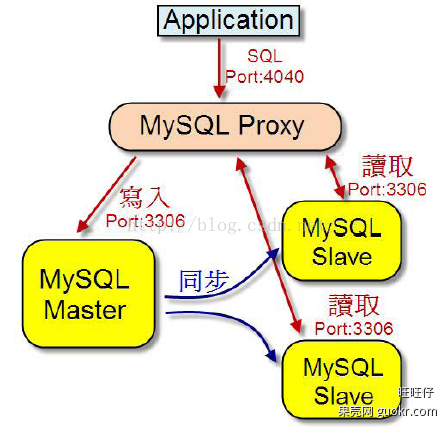
以下是一个可以参考的整体架构,LVS前端做负载均衡,两个Altas做HA,防止单点故障。

Altas的一些新特性:
1.主库宕机不影响读
主库宕机,Atlas自动将宕机的主库摘除,写操作会失败,读操作不受影响。从库宕机,Atlas自动将宕机的从库摘除,对应用没有影响。在mysql官方的proxy中主库宕机,从库亦不可用。
2.通过管理接口,简化管理工作,DB的上下线对应用完全透明,同时可以手动上下线。
图1是手动添加一台从库的示例。
图1

3.自己实现读写分离
(1)为了解决读写分离存在写完马上就想读而这时可能存在主从同步延迟的情况,Altas中可以在SQL语句前增加 /*master*/ 就可以将读请求强制发往主库。
(2)如图2中,主库可设置多项,用逗号分隔,从库可设置多项和权重,达到负载均衡。
图2
4.自己实现分表(图3)
(1)需带有分表字段。
(2)支持SELECT、INSERT、UPDATE、DELETE、REPLACE语句。
(3)支持多个子表查询结果的合并和排序。
图3
这里不得不吐槽Atlas的分表功能,不能实现分布式分表,所有的子表必须在同一台DB的同一个database里且所有的子表必须事先建好,Atlas没有自动建表的功能。
5.之前官方主要功能逻辑由使用lua脚本编写,效率低,Atlas用C改写,QPS提高,latency降低。
6.安全方面的提升
(1)通过配置文件中的pwds参数进行连接Atlas的用户的权限控制。
(2)通过client-ips参数对有权限连接Atlas的ip进行过滤。
(3)日志中记录所有通过Altas处理的SQL语句,包括客户端IP、实际执行该语句的DB、执行成功与否、执行所耗费的时间 ,如下面例子(图4)。
图4
7.平滑重启
通过配置文件中设置lvs-ips参数实现平滑重启功能,否则重启Altas的瞬间那些SQL请求都会失败。该参数前面挂接的lvs的物理网卡的ip,注意不是虚ip。平滑重启的条件是至少有两台配置相同的Atlas且挂在lvs之后。
source:https://github.com/Qihoo360/Atlas

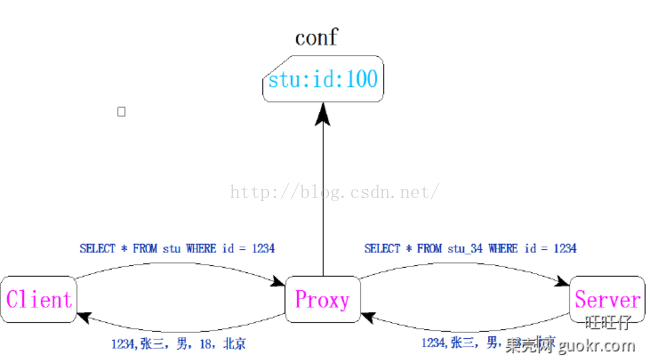

alibaba.cobar
Cobar是阿里巴巴(B2B)部门开发的一种关系型数据的分布式处理系统,它可以在分布式的环境下看上去像传统数据库一样为您提供海量数据服务。那么具体说说我们为什么要用它,或说cobar--能干什么?以下是我们业务运行中会存在的一些问题:
1.随着业务的进行数据库的数据量和访问量的剧增,需要对数据进行水平拆分来降低单库的压力,而且需要高效且相对透明的来屏蔽掉水平拆分的细节。
2.为提高访问的可用性,数据源需要备份。
3.数据源可用性的检测和failover。
4.前台的高并发造成后台数据库连接数过多,降低了性能,怎么解决。
针对以上问题就有了cobar施展自己的空间了,cobar中间件以proxy的形式位于前台应用和实际数据库之间,对前台的开放的接口是mysql通信协议。将前台SQL语句变更并按照数据分布规则转发到合适的后台数据分库,再合并返回结果,模拟单库下的数据库行为。
Cobar应用举例
应用架构:
应用介绍:
1.通过Cobar提供一个名为test的数据库,其中包含t1,t2两张表。后台有3个MySQL实例(ip:port)为其提供服务,分别为:A,B,C。
2.期望t1表的数据放置在实例A中,t2表的数据水平拆成四份并在实例B和C中各自放两份。t2表的数据要具备HA功能,即B或者C实例其中一个出现故障,不影响使用且可提供完整的数据服务。
cabar优点总结:
1.数据和访问从集中式改变为分布:
(1)Cobar支持将一张表水平拆分成多份分别放入不同的库来实现表的水平拆分
(2)Cobar也支持将不同的表放入不同的库
(3) 多数情况下,用户会将以上两种方式混合使用
注意!:Cobar不支持将一张表,例如test表拆分成test_1,test_2, test_3.....放在同一个库中,必须将拆分后的表分别放入不同的库来实现分布式。
2.解决连接数过大的问题。
3.对业务代码侵入性少。
4.提供数据节点的failover,HA:
(1)Cobar的主备切换有两种触发方式,一种是用户手动触发,一种是Cobar的心跳语句检测到异常后自动触发。那么,当心跳检测到主机异常,切换到备机,如果主机恢复了,需要用户手动切回主机工作,Cobar不会在主机恢复时自动切换回主机,除非备机的心跳也返回异常。
(2)Cobar只检查MySQL主备异常,不关心主备之间的数据同步,因此用户需要在使用Cobar之前在MySQL主备上配置双向同步。
cobar缺点:
开源版本中数据库只支持mysql,并且不支持读写分离。
source:http://code.alibabatech.com/wiki/display/cobar/Home
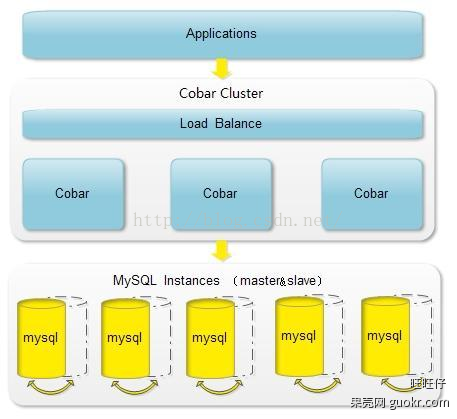

TDDL
淘宝根据自己的业务特点开发了TDDL(Taobao Distributed Data Layer 外号:头都大了 ©_Ob)框架,主要解决了分库分表对应用的透明化以及异构数据库之间的数据复制,它是一个基于集中式配置的 jdbc datasource实现,具有主备,读写分离,动态数据库配置等功能。
TDDL所处的位置(tddl通用数据访问层,部署在客户端的jar包,用于将用户的SQL路由到指定的数据库中):

淘宝很早就对数据进行过分库的处理, 上层系统连接多个数据库,中间有一个叫做DBRoute的路由来对数据进行统一访问。DBRoute对数据进行多库的操作、数据的整合,让上层系统像操作一个数据库一样操作多个库。但是随着数据量的增长,对于库表的分法有了更高的要求,例如,你的商品数据到了百亿级别的时候,任何一个库都无法存放了,于是分成2个、4个、8个、16个、32个……直到1024个、2048个。好,分成这么多,数据能够存放了,那怎么查询它?这时候,数据查询的中间件就要能够承担这个重任了,它对上层来说,必须像查询一个数据库一样来查询数据,还要像查询一个数据库一样快(每条查询在几毫秒内完成),TDDL就承担了这样一个工作。在外面有些系统也用DAL(数据访问层) 这个概念来命名这个中间件。
下图展示了一个简单的分库分表数据查询策略:
主要优点:
1.数据库主备和动态切换
2.带权重的读写分离
3.单线程读重试
4.集中式数据源信息管理和动态变更
5.剥离的稳定jboss数据源
6.支持mysql和oracle数据库
7.基于jdbc规范,很容易扩展支持实现jdbc规范的数据源
8.无server,client-jar形式存在,应用直连数据库
9.读写次数,并发度流程控制,动态变更
10.可分析的日志打印,日志流控,动态变更
TDDL必须要依赖diamond配置中心(diamond是淘宝内部使用的一个管理持久配置的系统,目前淘宝内部绝大多数系统的配置,由diamond来进行统一管理,同时diamond也已开源)。
TDDL动态数据源使用示例说明:http://rdc.taobao.com/team/jm/archives/1645
diamond简介和快速使用:http://jm.taobao.org/tag/diamond%E4%B8%93%E9%A2%98/
TDDL源码:https://github.com/alibaba/tb_tddl
TDDL复杂度相对较高。当前公布的文档较少,只开源动态数据源,分表分库部分还未开源,还需要依赖diamond,不推荐使用。
终其所有,我们研究中间件的目的是使数据库实现性能的提高。具体使用哪种还要经过深入的研究,严谨的测试才可决定。

MyCAT
https://github.com/myCATApache
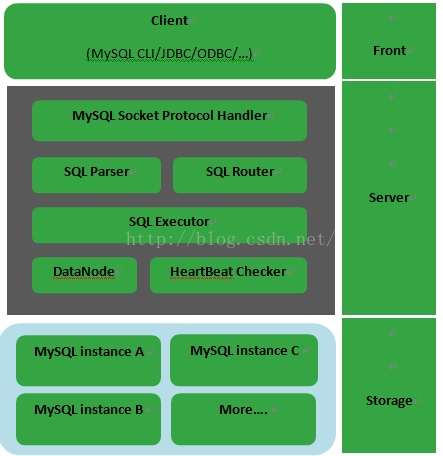

什么是MyCAT?简单的说,MyCAT就是: 一个彻底开源的,面向企业应用开发的“大数据库集群” 支持事务、ACID、可以替代Mysql的加强版数据库 ? 一个可以视为“Mysql”集群的企业级数据库,用来替代昂贵的Oracle集群 ? 一个融合内存缓存技术、Nosql技术、HDFS大数据的新型SQL Server ? 结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品 ? 一个新颖的数据库中间件产品。
目标
低成本的将现有的单机数据库和应用平滑迁移到“云”端,解决数据存储和业务规模迅速增长情况下的数据瓶颈问题。
关键特性
1. 支持 SQL 92标准 支持Mysql集群,可以作为Proxy使用 支持JDBC连接ORACLE、DB2、SQL Server,将其模拟为MySQL Server使用 支持galera for mysql集群,percona-cluster或者mariadb cluster,提供高可用性数据分片集群,自动故障切换,高可用性 。
2. 支持读写分离。
3. 支持Mysql双主多从,以及一主多从的模式 。
4. 支持全局表。
5. 支持数据自动分片到多个节点,用于高效表关联查询 。
6. 垮裤join,支持独有的基于E-R 关系的分片策略,实现了高效的表关联查询多平台支持,部署和实施简单。
优势
基于阿里开源的Cobar产品而研发,Cobar的稳定性、可靠性、优秀的架构和性能,以及众多成熟的使用案例使得MyCAT一开始就拥有一个很好的起点,站在巨人的肩膀上,我们能看到更远。广泛吸取业界优秀的开源项目和创新思路,将其融入到MyCAT的基因中,使得MyCAT在很多方面都领先于目前其他一些同类的开源项目,甚至超越某些商业产品。MyCAT背后有一只强大的技术团队,其参与者都是5年以上资深软件工程师、架构师、DBA等,优秀的技术团队保证了MyCAT的产品质量。 MyCAT并不依托于任何一个商业公司,因此不像某些开源项目,将一些重要的特性封闭在其商业产品中,使得开源项目成了一个摆设,目前在持续维护更新。
长期规划
在支持Mysql的基础上,后端增加更多的开源数据库和商业数据库的支持,包括原生支持PosteSQL、FireBird等开源数据库,以及通过JDBC等方式间接支持其他非开源的数据库如Oracle、DB2、SQL Server等实现更为智能的自我调节特性,如自动统计分析SQL,自动创建和调整索引,根据数据表的读写频率,自动优化缓存和备份策略等实现更全面的监控管理功能与HDFS集成,提供SQL命令,将数据库装入HDFS中并能够快速分析集成优秀的开源报表工具,使之具备一定的数据分析的能力。
强大好用的mysql分库分表中间件,来自百度
其优点: 分库分表与应用脱离,分库表如同使用单库表一样 减少db 连接数压力 热重启配置 可水平扩容 遵守Mysql原生协议 读写分离 无语言限制,mysqlclient,c,java等都可以使用 Heisenberg服务器通过管理命令可以查看,如连接数,线程池,结点等,并可以调整 采用velocity的分库分表脚本进行自定义分库表,相当的灵活
qq群:150720285 邮箱:brucest0078@gmail.com
https://github.com/songwie/heisenberg

—Heisenberg服务器通过管理命令可以查看,如连接数,线程池,结点等,并可以调整
Oceanus:Oceanus致力于打造一个功能简单、可依赖、易于上手、易于扩展、易于集成的解决方案,甚至是平台化系统。拥抱开源,提供各类插件机制集成其他开源项目,新手可以在几分钟内上手编程,分库分表逻辑不再与业务紧密耦合,扩容有标准模式,减少意外错误的发生。
Oceanus内部名词定义
datanode:数据源节点。为一个数据源命名,配置链接属性、报警实现
namenode:数据源的簇。为一组数据源命名,指定这组数据源的负载方式、访问模式、权重
table:映射表。匹配解析sql中的table名称,命中table标签的name属性值后,会执行约定的路由逻辑
bean:实体。由其他标签引用,实体类必须有无参的构造函数
tracker:监控埋点。涉及到计算和IO的功能点都有监控点,自定义一个埋点实现类,当功能耗时超出预期时会执行其中的回调函数,便于监控和优化系统
为什么说Oceanus是非常易用的
Oceanus在设计时非常注重使用者的评价,配置结构近乎于和使用者交流约定业务规则,便于不同的人看同一套配置,互相理解流程。当配置文件编写 完成后,编码就变得更加简单,只调用Oceanus客户端的几个方法就可以实现数据库操作,不再关心HA、报警、负载均衡、性能监控等问题。良好的用户视 觉减少了分库分表在业务场景中的耦合度,对于编码者就像只对一个table操作,Oceanus负责进行sql解析、路由、sql重写。
如提交: select * from user;改写成: select * from user0; select * from user1; select * from user2; select * from user3;分发给不同的库(或者同库)执行,用户视觉如图:

开源集成
“接地气,拥抱开源” 是Oceanus的设计原则之一,可以很好的集成到mybatis和hibernate中,只要引用其中的插件,编写Oceanus配置文件,然后改写各 自的DataSource实现或ConnectionProvider即可做到集成。这样既用到了熟悉的ORM,又借助Oceanus实现了分库分表等功 能。
待开发
不得不说Oceanus在设计上非常灵活,使得每一个细小的功能点都有极高的切入价值,比如Cache机制、全局的ID生成规则、资源可视化监控等等,把其中某一个点做得足够好,都会为整体产品带来质的提升,简化实际生产环境中的配套系统研发维护成本。
谷歌开发的数据库中间件,集群基于ZooKeeper管理,通过RPC方式进行数据处理,总体分为,server,command line,gui监控 3部分。
https://github.com/youtube/vitess
Vitess is a set of servers and tools meant to facilitate scaling of MySQL databases for the web. It's been developed since 2011, and is currently used as a fundamental component of YouTube's MySQL infrastructure, serving thousands of QPS (per server). If you want to find out whether Vitess is a good fit for your project, please read our helicopter overview.

Vitess consists of a number servers, command line utilities, and a consistent metadata store. Taken together, they allow you to serve more database traffic, and add features like sharding, which normally you would have to implement in your application.
vttablet is a server that sits in front of a MySQL database, making it more robust and available in the face of high traffic. Among other things, it adds a connection pool, has a row based cache, and it rewrites SQL queries to be safer and nicer to the underlying database.
vtgate is a very light proxy that routes database traffic from your app to the right vttablet, basing on the sharding scheme, latency required, and health of the vttablets. This allows the client to be very simple, as all it needs to be concerned about is finding the closest vtgate.
The topology is a metadata store that contains information about running servers, the sharding scheme, and replication graph. It is backed by a consistent data store, like Apache ZooKeeper. The topology backends are plugin based, allowing you to write your own if ZooKeeper doesn't fit your needs. You can explore the topology through vtctld, a webserver (not shown in the diagram).
vtctl is a command line utility that allows a human or a script to easily interact with the system.
All components communicate using a lightweight RPC system based on BSON. The RPC system is plugin based, so you can easily write your own backend (at Google we use a Protocol Buffers based protocol). We provide a client implementation for three languages: Python, Go, and Java. Writing a client for your language should not be difficult, as it's a matter of implementing only a few API calls (please send us a pull request if you do!).
最新博文在http://www.cnblogs.com/youge-OneSQL/articles/4208583.html



















 336
336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









