








一、主从原理
Replication 线程
Mysql的 Replication 是一个异步的复制过程,从一个 Mysql instace(我们称之为 Master)复制到另一个 Mysql instance(我们称之 Slave)。在Master 与 Slave 之间的实现整个复制过程主要由三个线程来完成,其中两个线程(Sql线程和IO线程)在 Slave 端,另外一个线程(IO线程)在 Master 端。
要实现 MySQL 的Replication ,首先必须打开 Master 端的
Binary Log(mysql-bin.xxxxxx)功能,否则无法实现。因为整个复制过程实际上就是Slave从Master端获取该日志然后再在自己身上完全 顺序的执行日志中所记录的各种操作。打开 MySQL 的 Binary Log 可以通过在启动 MySQL Server 的过程中使用 “—log-bin” 参数选项,或者在 my.cnf 配置文件中的 mysqld 参数组([mysqld]标识后的参数部分)增加 “log-bin” 参数项。
复制的基本过程如下 :
1. Slave 上面的IO线程连接上 Master,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容;
2. Master 接收到来自 Slave 的 IO 线程的请求后,通过负责复制的 IO 线程根据请求信息读取指定日志指定位置之后的日志信息,返回给 Slave 端的 IO 线程。返回信息中除了日志所包含的信息之外,还包括本次返回的信息在 Master 端的 Binary Log 文件的名称以及在 Binary Log 中的位置;
3. Slave 的 IO 线程接收到信息后,将接收到的日志内容依次写入到 Slave 端的Relay Log文件(mysql-relay-bin.xxxxxx)的最末端,并将读取到的Master端的bin-log的文件名和位置记录到master- info文件中,以便在下一次读取的时候能够清楚的高速Master“我需要从某个bin-log的哪个位置开始往后的日志内容,请发给我”
4. Slave 的 SQL 线程检测到 Relay Log 中新增加了内容后,会马上解析该 Log 文件中的内容成为在 Master 端真实执行时候的那些可执行的 Query 语句,并在自身执行这些 Query。这样,实际上就是在 Master 端和 Slave 端执行了同样的 Query,所以两端的数据是完全一样的。
简单来讲就是从库先通过io线程读取主库的二进制文件(Master_Log_File)和位置(Read_Master_Log_Pos)然后缓存到本地(从库服务器)的中继文件(Relay_Log_File)中并记录已经读取到的位置(Relay_Log_Pos),再通过从库的sql线程去读取中继文件(Relay_Log_File),这个sql线程执行会记录已经执行到了哪个文件(Relay_Master_Log_File)和哪个位置(Exec_Master_Log_Pos)。
图解为:
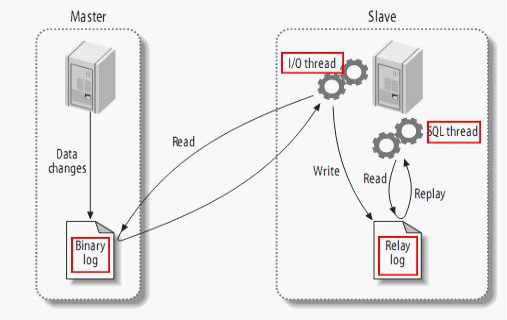
那上图中大家肯定会奇怪复制过程很简单,似乎也没有用到三种日志文件啊,只看到了2个;
既然在slave的状态中显示了三种日志文件以及其位置,那么我们先来看看他们的定义,稍后再做解释;
二、日志解释
l Master_Log_File,Read_Master_Log_Pos 记录了IO thread读到的当前master binlog文 件和位置, 对应master的binlog文件和位置。
l Relay_Log_File,Relay_Log_Pos记录了SQL thread执行到relay log的那个文件和位置,对应的是slave上的relay log文件和位置。
l Relay_Master_Log_File,Exec_Master_Log_Pos记录的是SQL thread执行到master binlog的文件和位置,对应的master上binlog的文件和位置。
看了定义就能更好的理解上面主从复制的过程了。
三、日志详解
1.我们看下普通的binlog文件,通过mysqlbinlog解析出来的文本文件:
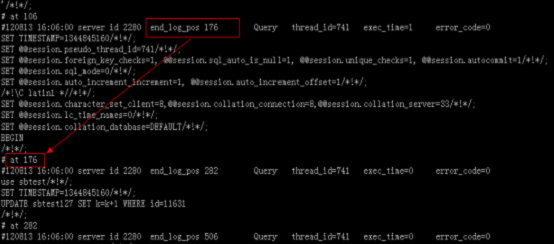
我们这里主要是row方式的binlog。
可以看到,binlog的event语句开始位置就是二进制binlog文件的字节偏移位置。而且根据上一个event的end_log_pos可以找到下一个event开始的位置,如上图所示 。
2.我们再看看relay_log,同样可以用mysqlbinlog工具来解析(不是同一台机器):
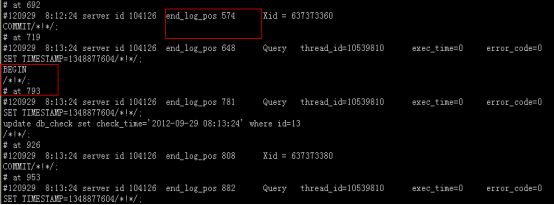
Relay_log和binlog记录方式基本相同,最大的不同就是end_log_pos记录的是master的binlog文件中event的位置,而不是relay log自己event的位置。如图所示,上一个event的end_log_pos和下一个relay log event开始的位置不一样。
为什么需要这样设置?原因很简单,就是为了方便找到master binlog的位置,在slave上,记录relay log 下一个event的开始偏移意义不大,但是如果记录了master binlog的偏移量,我们就可以在SQL thread中明确我们执行到master的某个binlog的哪个位置了。那么是哪个binlog列。我们找到relay_log的最前面 .
· IO thread 把所有从master读到的binlog记录到本地的binlog中,所以relay log的最后一个event的end log_pos就是Read_Master_Log_Pos
1、什么是relay log
The relay log, like the binary log, consists of a set of numbered files containing events that describe database changes, and an index file that contains the names of all used relay log files.
The term "relay log file" generally denotes an individual numbered file containing database events. The term"relay log" collectively denotes the set of numbered relay log files plus the index file
来源: <http://dev.mysql.com/doc/refman/5.5/en/slave-logs-relaylog.html>
理解:relay log很多方面都跟binary log差不多。
区别是:从服务器I/O线程将主服务器的二进制日志读取过来记录到从服务器本地文件,然后SQL线程会读取relay-log日志的内容并应用到从服务器,从而使从服务器和主服务器的数据保持一致
2、relay log的相关参数说明
通过语句:show variables like '%relay%',查看先骨干的relay的所有相关参数
mysql> show variables like '%relay%';
+-----------------------+----------------+
| Variable_name | Value |
+-----------------------+----------------+
| max_relay_log_size
| relay_log
| relay_log_basename
| relay_log_index
| relay_log_info_file
| relay_log_info_repository
| relay_log_purge
| relay_log_recovery
| relay_log_space_limit
| sync_relay_log
| sync_relay_log_info
+-----------------------+----------------+
参数详细解释:
2.1 max_relay_log_size:
标记relay log 允许的最大值,如果该值为0,则默认值为max_binlog_size(1G);如果不为0,则max_relay_log_size则为最大的relay_log文件大小;
2.2 relay_log:
定义relay_log的位置和名称,如果值为空,则默认位置在数据文件的目录(datadir),文件名为host_name-relay-bin.nnnnnn(By default, relay log file names have the form host_name-relay-bin.nnnnnn in the data directory);
2.3 relay_log_index:
同relay_log,定义relay_log的位置和名称;一般和relay-log在同一目录
2.4 relay_log_info_file:
设置relay-log.info的位置和名称(relay-log.info记录MASTER的binary_log的恢复位置和relay_log的位置)
2.5 relay_log_purge:
是否自动清空不再需要中继日志时。默认值为1(启用)。
2.6 relay_log_recovery:
当slave从库宕机后,假如relay-log损坏了,导致一部分中继日志没有处理,则自动放弃所有未执行的relay-log,并且重新从master上获取日志,这样就保证了relay-log的完整性。默认情况下该功能是关闭的,将relay_log_recovery的值设置为 1时,可在slave从库上开启该功能,建议开启。
2.7 relay_log_space_limit:
防止中继日志写满磁盘,这里设置中继日志最大限额。但此设置存在主库崩溃,从库中继日志不全的情况,不到万不得已,不推荐使用;
2.8 sync_relay_log:
这个参数和sync_binlog是一样的,
当设置为1时,slave的I/O线程每次接收到master发送过来的binlog日志都要写入系统缓冲区,然后刷入relay log中继日志里,这样是最安全的,因为在崩溃的时候,你最多会丢失一个事务,但会造成磁盘的大量I/O。
当设置为0时,并不是马上就刷入中继日志里,而是由操作系统决定何时来写入,虽然安全性降低了,但减少了大量的磁盘I/O操作。这个值默认是0,可动态修改,建议采用默认值。
2.9 sync_relay_log_info:
这个参数和sync_relay_log参数一样,当设置为1时,slave的I/O线程每次接收到master发送过来的binlog日志都要写入系统缓冲区,然后刷入relay-log.info里,这样是最安全的,因为在崩溃的时候,你最多会丢失一个事务,但会造成磁盘的大量I/O。当设置为0时,并不是马上就刷入relay-log.info里,而是由操作系统决定何时来写入,虽然安全性降低了,但减少了大量的磁盘I/O操作。这个值默认是0,可动态修改,建议采用默认值。
3、总结:以上只是简单的介绍了每个参数的作用,这些参数具体的设置还是需要根据每个用户的实际系统情况进行设置的;
推荐从库线上环境使用以下配置
#relay log
max_relay_log_size = 0;
relay_log=$datadir/relay-bin
relay_log_purge = 1;
relay_log_recovery = 1;
sync_relay_log =0;
sync_relay_log_info = 0;如果是mha环境,则| relay_log_purge 不要开启,设置为0,可以使用 purge_relay_logs 来定期清除
· SQL thread按照transaction来执行,所以Exec_Master_Log_Pos对应relay log中最后一个事务event的end_log_pos,这个位置对应的是master的binlog的位置。
· Relay_Log_Pos 记录的是SQL thread执行的event在relay log中结束位置,这个才是relay log的偏移量。
那么,从别的服务器取的从库信息来看,我们重新搭建新的从库只需要的是其中的Relay_Master_Log_File & Exec_Master_Log_Pos。















 3286
3286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









