







基本数据类型补充:
set 是一个无序且不重复的元素集合
1:创建
- s = set()
- s = {11,22,33,55}
2:转换
- li = [11,22,33,44]
- tu = (11,22,33,44)
- st = ''
- s = set(li)
3:intersection , intersection_update方法
- a = {11,22,33,44}
- b = {22,66,77,88}
- ret = a.intersection(b)
- print(ret)
intersection取得两个集合中的交集元素,并将这些元素以一个新的集合返回给一个变量接收
- a = {11,22,33,44}
- b = {22,66,77,88}
- a.intersection_update(b)
- print(a)
intersection_update取得两个集合的交集元素,并更新a集合
4:isdisjoint , issubset , issuperset方法
- s = {11,22,33,44}
- b = {11,22,77,55}
- ret = s.isdisjoint(b)#有交集返回False,没有交集返回True
- print(ret)
- ## False
issubset判断是否为子集
- a = {11,22,33,44}
- b = {11,44}
- ret = b.issubset(a)
- print(ret)
- ##########################################
- True
issuperset判断是否为父集
- a = {11,22,33,44}
- b = {11,44}
- ret = a.issubset(b)
- print(ret)
- ##########################################
- False
5:discard , remove , pop
- s = {11,22,33,44}
- s.remove(11)
- print(s)
- s.discard(22)
- print(s)
- s.pop()
- print(s)
三者都能达到移除元素的效果,区别在于remove移除集合中不存在的元素时会报错,discard移除不存在的元素是不会报错,pop无法精确控制移除哪个元素,按其自身的规则随机移除元素,返回被移除的元素,可以使用变量接收其返回值
6:symmetric_difference取差集
- s = {11,22,33,44}
- b = {11,22,77,55}
- r1 = s.difference(b)
- r2 = b.difference(s)
- print(r1)
- print(r2)
- ret = s.symmetric_difference(b)
- print(ret)
- ## set([33, 44])
- ## set([77, 55])
- ## set([33, 44, 77, 55])
symmetric_difference返回两个集合中不是交集的元素
上面的代码中,将symmetric_difference换成symmetric_difference_update则表示将两个集合中不是交集的部分赋值给s
7:union , update方法
- s = {11,22,33,44}
- b = {11,22,77,55}
- ret = s.union(b)
- print(ret)
- ## set([33, 11, 44, 77, 22, 55])
union方法合并两个集合
- s = {11,22,33,44}
- b = {11,22,77,55}
- s.update(b)
- print(s)
- ## set([33, 11, 44, 77, 22, 55])
update方法更新s集合,将b集合中的元素添加到s集合中!update方法也可以传递一个列表,如:update([23,45,67])
练习题:有下面两个字典
要求:
1)两个字典中有相同键的,则将new_dict中的值更新到old_dict对应键的值
2)old_dict中存在的键且new_dict中没有的键,在old_dict中删除,并把new_dict中的键值更新到old_dict中
3)最后输出old_dict
- # 数据库中原有
- old_dict = {
- "#1":{ 'hostname':'c1', 'cpu_count': 2, 'mem_capicity': 80 },
- "#2":{ 'hostname':'c1', 'cpu_count': 2, 'mem_capicity': 80 },
- "#3":{ 'hostname':'c1', 'cpu_count': 2, 'mem_capicity': 80 }
- }
- # cmdb 新汇报的数据
- new_dict = {
- "#1":{ 'hostname':'c1', 'cpu_count': 2, 'mem_capicity': 800 },
- "#3":{ 'hostname':'c1', 'cpu_count': 2, 'mem_capicity': 80 },
- "#4":{ 'hostname':'c2', 'cpu_count': 2, 'mem_capicity': 80 }
- }
- old_keys = set(old_dict.keys())
- new_keys = set(new_dict.keys())
- #需要更新元素的键
- update_keys = old_keys.intersection(new_keys)
- print(update_keys)
- #需要删除元素的键
- del_keys = old_keys.difference(new_keys)
- #需要添加元素的键
- add_keys = new_keys.difference(old_keys)
- print(del_keys)
- print(add_keys)
- update_keys = list(update_keys)
- for i in update_keys :
- old_dict[i] = new_dict[i]
- del_keys = list(del_keys)
- for j in del_keys :
- del old_dict[j]
- for k in list(add_keys) :
- old_dict[k] = new_dict[k]
- print(old_dict)
- ########################################
- {'#3': {'hostname': 'c1', 'cpu_count': , 'mem_capicity': }, '#1': {'hostname': 'c1', 'cpu_count': , 'mem_capicity': }, '#4': {'hostname': 'c2', 'cpu_count': , 'mem_capicity': }}
答案
collections系列
一、计数器(counter)
Counter是对字典类型的补充,用于追踪值的出现次数。
ps:具备字典的所有功能 + 自己的功能
- c = Counter('abcdeabcdabcaba')
- print c
- 输出:Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
Counter
二、有序字典(orderedDict )
orderdDict是对字典类型的补充,他记住了字典元素添加的顺序
OrderedDict
三、默认字典(defaultdict)
defaultdict是对字典的类型的补充,他默认给字典的值设置了一个类型。
defaultdict
使用方法:
- import collections
- dic = collections.defaultdict(list)
- dic['k1'].append('alext')
- print(dic)
练习:
- 有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
- 即: {'k1': 大于66 , 'k2': 小于66}
- values = [11, 22, 33,44,55,66,77,88,99,90]
- my_dict = {}
- for value in values:
- if value>66:
- if my_dict.has_key('k1'):
- my_dict['k1'].append(value)
- else:
- my_dict['k1'] = [value]
- else:
- if my_dict.has_key('k2'):
- my_dict['k2'].append(value)
- else:
- my_dict['k2'] = [value]
原生字典
- from collections import defaultdict
- values = [11, 22, 33,44,55,66,77,88,99,90]
- my_dict = defaultdict(list)
- for value in values:
- if value>66:
- my_dict['k1'].append(value)
- else:
- my_dict['k2'].append(value)
- defaultdict字典解决方法
- 默认字典
默认字典
四、可命名元组(namedtuple)
根据nametuple可以创建一个包含tuple所有功能以及其他功能的类型。
Mytuple
五、双向队列(deque)
一个线程安全的双向队列
deque
注:既然有双向队列,也有单项队列(先进先出 FIFO )
Queue.Queue
三元运算
三元运算(三目运算),是对简单的条件语句的缩写。
- # 书写格式
- result = 值1 if 条件 else 值2
- # 如果条件成立,那么将 “值1” 赋值给result变量,否则,将“值2”赋值给result变量
- a = 1
- name = 'poe' if a == 1 else 'jet'
- print(name)
深浅拷贝
一、数字和字符串
对于 数字 和 字符串 而言,赋值、浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址。
- import copy
- # ######### 数字、字符串 #########
- n1 = 123
- # n1 = "i am alex age 10"
- print(id(n1))
- # ## 赋值 ##
- n2 = n1
- print(id(n2))
- # ## 浅拷贝 ##
- n2 = copy.copy(n1)
- print(id(n2))
- # ## 深拷贝 ##
- n3 = copy.deepcopy(n1)
- print(id(n3))

二、其他基本数据类型
对于字典、元祖、列表 而言,进行赋值、浅拷贝和深拷贝时,其内存地址的变化是不同的。
1、赋值
赋值,只是创建一个变量,该变量指向原来内存地址,如:
- n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
- n2 = n1

2、浅拷贝
浅拷贝,在内存中只额外创建第一层数据
- import copy
- n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
- n3 = copy.copy(n1)
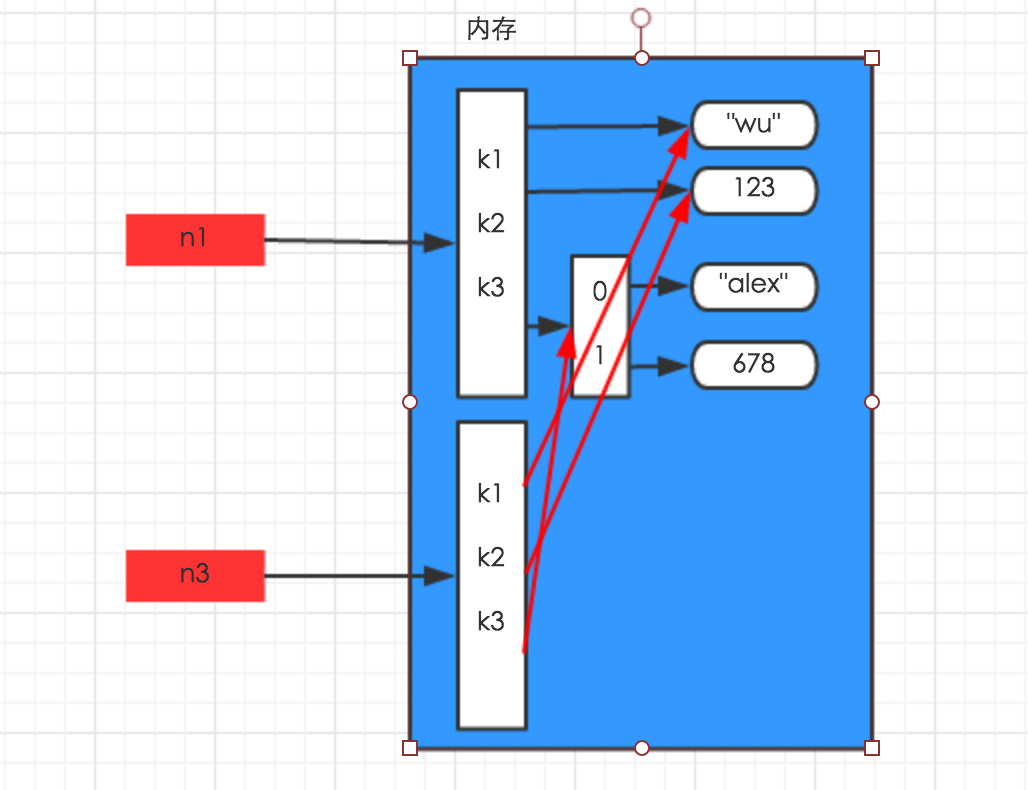
3、深拷贝
深拷贝,在内存中将所有的数据重新创建一份(排除最后一层,即:python内部对字符串和数字的优化)
- import copy
- n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
- n4 = copy.deepcopy(n1)

函数
1:函数的定义
- def 函数名(参数):
- ...
- 函数体
- ...
- 返回值
函数的定义主要有如下要点:
def:表示函数的关键字
函数名:函数的名称,日后根据函数名调用函数
函数体:函数中进行一系列的逻辑计算,如:发送邮件、计算出 [11,22,38,888,2]中的最大数等...
参数:为函数体提供数据
返回值:当函数执行完毕后,可以给调用者返回数据。
2:返回值
函数是一个功能块,该功能到底执行成功与否,需要通过返回值来告知调用者。
以上要点中,比较重要有参数和返回值:
- def 发送短信():
- 发送短信的代码...
- if 发送成功:
- return True
- else:
- return False
- while True:
- # 每次执行发送短信函数,都会将返回值自动赋值给result
- # 之后,可以根据result来写日志,或重发等操作
- result = 发送短信()
- if result == False:
- 记录日志,短信发送失败...
3:参数
函数有三种不同的参数:
普通参数
- # ######### 定义函数 #########
- # name 叫做函数func的形式参数,简称:形参
- def func(name):
- print name
- # ######### 执行函数 #########
- # 'wupeiqi' 叫做函数func的实际参数,简称:实参
- func('poe')
默认参数
- def func(name, age = 18):
- print "%s:%s" %(name,age)
- # 指定参数
- func('poe', 19)
- # 使用默认参数
- func('gin')
- 注:默认参数需要放在参数列表最后
动态参数
- def f1(*a):
- print(a,type(a))
- f1(123,456,[1,2,3],'who')
- ## ((123, 456, [1, 2, 3], 'who'), <type 'tuple'>)
- def func(**kwargs):
- print args
- # 执行方式一
- func(name='poe',age=18)
- # 执行方式二
- li = {'name':'poe', age:18, 'gender':'male'}
- func(**li)
- def f1(*a,**b) :#一个星的参数必须在前,两个星的参数必须在后
- print(a,type(a))
- print(b,type(b))
- f1(11,22,33,k1=1234,k2=456)
- ## ((11, 22, 33), <type 'tuple'>)({'k2': 456, 'k1': 1234}, <type 'dict'>)
为动态参数传入列表,元组,字典:(注:这几种数据类型在函数传参的时候只有引用传递,没有值传递)
- def f1(*args) :
- print(args,type(args))
- li = [1,2,3,4]
- f1(li)
- f1(*li)
- ## (([1, 2, 3, 4],), <type 'tuple'>)
- ## ((1, 2, 3, 4), <type 'tuple'>)
- def f2(**kwargs) :
- print(kwargs,type(kwargs))
- dic = {'k1':123,'k2':456}
- f2(k1 = dic)
- f2(**dic)
- ## ({'k1': {'k2': 456, 'k1': 123}}, <type 'dict'>)
- ## ({'k2': 456, 'k1': 123}, <type 'dict'>)
4:内置函数

注:查看详细猛击这里
数据类型转换函数
- chr(i) 函数返回ASCII码对应的字符串
-
- print(chr(65))
- print(chr(66))
- print(chr(65)+chr(66))
- ##########################################
- A
- B
- AB
- complex(real[,imaginary]) 函数可把字符串或数字转换为复数
-
- print(complex("2+1j"))
- print(complex(""))
- print(complex(2,1))
- ##########################################
- (2+1j)
- (2+0j)
- (2+1j)
- float(x) 函数把一个数字或字符串转换成浮点数
-
- print(float(12))
- print(float(12.2))
- ##########################################
- 12.0
- 12.2
- long(x[,base]) 函数把数字和字符串转换成长整数,base为可选的基数
- list(x) 函数可将序列对象转换成列表
- min(x[,y,z...]) 函数返回给定参数的最小值,参数可以为序列
- max(x[,y,z...]) 函数返回给定参数的最大值,参数可以为序列
- ord(x) 函数返回一个字符串参数的ASCII码或Unicode值
-
- print(ord('a'))
- print(ord(u"A"))
- ##########################################
- 97
- 65
- str(obj) 函数把对象转换成可打印字符串
- tuple(x) 函数把序列对象转换成tuple
- type(x) 可以接收任何东西作为参数――并返回它的数据类型。整型、字符串、列表、字典、元组、函数、类、模块,甚至类型对象都可以作为参数被 type 函数接受
abs()函数:取绝对值
- print(abs(-1.2))
all()函数与any函数:
all(iterable):如果iterable的任意一个元素为0、''、False,则返回False,否则返回True
- print(all(['a','b','c','d']))#True
- print(all(['a','b','','d']))#False
- #注意:空元组、空列表返回值为True,这里要特别注意
any(iterable):如果iterable的所有元素都为0、''、False,则返回False,否则返回True
- print(any(['a','b','c','d']))#True
- print(any(['a',0,' ',False]))#True
- print(any([0,'',False]))#False
ascii(object) 函数:
返回一个可打印的对象字符串方式表示,如果是非ascii字符就会输出\x,\u或\U等字符来表示。与python2版本里的repr()是等效的函数。
- print(ascii(1))
- print(ascii('a'))
- print(ascii(123))
- print(ascii('中文'))#非ascii字符
- ##########################################
- 1
- 'a'
- 123
- '\u4e2d\u6587'
lambda表达式:
学习条件运算时,对于简单的 if else 语句,可以使用三元运算来表示,即:
- # 普通条件语句
- if 1 == 1:
- name = 'poe'
- else:
- name = 'bruce'
- # 三元运算
- name = 'poe' if 1 == 1 else 'bruce'
对于简单的函数,也存在一种简便的表示方式,即:lambda表达式
- # ###################### 普通函数 ######################
- # 定义函数(普通方式)
- def func(arg):
- return arg + 1
- # 执行函数
- result = func(123)
- # ###################### lambda ######################
- # 定义函数(lambda表达式)
- my_lambda = lambda arg : arg + 1
- # 执行函数
- result = my_lambda(123)
生成随机数:
- import random
- chars = ''
- for i in range(4) :
- rand_num = random.randrange(0,4)
- if rand_num == 3 or rand_num == 1:
- rand_digit = random.randrange(0,10)
- chars += str(rand_digit)
- else:
- rand_case = random.randrange(65,90)
- case = chr(rand_case)
- chars += case
- print(chars)
filter函数
filter()函数是 Python 内置的另一个有用的高阶函数,filter()函数接收一个函数 f 和一个list,这个函数 f 的作用是对每个元素进行判断,返回 True或 False,filter()根据判断结果自动过滤掉不符合条件的元素,返回由符合条件元素组成的新list。
例1,要从一个list [1, 4, 6, 7, 9, 12, 17]中删除偶数,保留奇数,首先,要编写一个判断奇数的函数:
- # filter(fn,iterable)
- def is_odd(x) :
- return x % 2 == 1
- li = [1, 4, 6, 7, 9, 12, 17]
- result = filter(is_odd,li)
- print(result)
- ##########################################
- [1, 7, 9, 17]
例2:删除 列表中的None 或者空字符串
- li = ['test', None, '', 'str', ' ', 'END']
- def is_not_empty(s) :
- return s and len(s.strip()) > 0
- print(filter(is_not_empty,li))
- ##########################################
- ['test', 'str', 'END']
例3:请利用filter()过滤出1~100中平方根是整数的数,即结果应该是:[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
- import math
- def is_sqr(x) :
- return math.sqrt(x) % 1 == 0
- print filter(is_sqr,range(1,101))
以上三个函数都可以使用lambda表达式的写法来书写,如:
- result = filter(lambda x : x % 2 == 1,[1,4,6,9,12,7,17])
- print(result)
map()函数
map()是 Python 内置的高阶函数,它接收一个函数 f 和一个 list,并通过把函数 f 依次作用在 list 的每个元素上,得到一个新的 list 并返回
例如,对于list [1, 2, 3, 4, 5, 6, 7, 8, 9]如果希望把list的每个元素都作平方,就可以用map()函数
- li = [1, 2, 3, 4, 5, 6, 7, 8, 9]
- print(li)
- def f(x) :
- return x*x
- r = list(map(f,[1, 2, 3, 4, 5, 6, 7, 8, 9]))
- print(r)
注:在python3里面,map()的返回值已经不再是list,而是iterators, 所以想要使用,只用将iterator 转换成list 即可, 比如 list(map()) 。
进制转换函数(以下四个函数可以实现各进制间的互相转换)
bin(x) :将整数x转换为二进制字符串,如果x不为Python中int类型,x必须包含方法__index__()并且返回值为integer
oct(x):将一个整数转换成8进制字符串。如果传入浮点数或者字符串均会报错
hex(x):将一个整数转换成16进制字符串。
int():
- 传入数值时,调用其__int__()方法,浮点数将向下取整
-
- print(int(3))#
- print(int(3.6))#
- 传入字符串时,默认以10进制进行转换
-
- print(int(''))#
- 字符串中允许包含"+"、"-"号,但是加减号与数值间不能有空格,数值后、符号前可出现空格
-
- print(int('+36'))#
- 传入字符串,并指定了进制,则按对应进制将字符串转换成10进制整数
-
- print(int('',2))#
- print(int('0o7',8))#
- print(int('0x15',16))#
open函数,该函数用于文件处理
操作文件时,一般需要经历如下步骤:
- 打开文件
- 操作文件
一:打开文件
- 文件句柄 = open('文件路径', '模式')
打开文件时,需要指定文件路径和以何等方式打开文件,打开后,即可获取该文件句柄,日后通过此文件句柄对该文件操作。
打开文件的模式有:
- r ,只读模式【默认】
- w,只写模式【不可读;不存在则创建;存在则清空内容;】
- x, 只写模式【不可读;不存在则创建,存在则报错】
- a, 追加模式【可读; 不存在则创建;存在则只追加内容;】
- f = open('test.log','r')
- data = f.read()
- f.close()
- print(data)
"+" 表示可以同时读写某个文件
- r+, 读写【可读,可写】
- w+,写读【可读,可写】
- x+ ,写读【可读,可写】
- a+, 写读【可读,可写】
- # r+ 模式
- f = open('test.log','r+',encoding='utf-8')
- print(f.tell())#打印当前指针所在的位置,此时为0
- data = f.read()
- print(data)
- print(f.tell())#此时当前指针在文件最末尾
- f.close()
- # w+模式:先清空文件,再写入文件,写入文件后才可以读文件
- f = open('test.log','w+',encoding="utf-8")
- f.write('python')#写完后,指针到了最后
- f.seek(0)#移动指针到开头
- data = f.read()
- f.close()
- print(data)
- # a+模式:打开的同时,指针已经到最后,
- # 写时,追加,指针到最后
- f = open('test.log','a+',encoding="utf-8")
- print(f.tell())#读取当前指针位置,此时指针已经到最后
- f.write('c++')
- print(f.tell())
- #此时要读文件必须把指针移动到文件开头
- f.seek(0)
- data = f.read();
- print(data)
- f.close()
"b"表示以字节的方式操作
- rb 或 r+b
- wb 或 w+b
- xb 或 w+b
- ab 或 a+b
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型
二:文件操作
3.x版本
三:管理上下文
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
- with open('log','r') as f:
- ...
如此方式,当with代码块执行完毕时,内部会自动关闭并释放文件资源。
在Python 2.7 及以后,with又支持同时对多个文件的上下文进行管理,即:
- with open('log1') as obj1, open('log2') as obj2:
- pass
可使用此方法对一个文件进行读操作,同时把数据又写入到另一个打开的文件中!
read()、readline() 和 readlines()
每种方法可以接受一个变量以限制每次读取的数据量,但它们通常不使用变量。 .read() 每次读取整个文件,它通常用于将文件内容放到一个字符串变量中。然而 .read() 生成文件内容最直接的字符串表示,但对于连续的面向行的处理,它却是不必要的,并且如果文件大于可用内存,则不可能实现这种处理。
.readline() 和 .readlines() 非常相似。它们都在类似于以下的结构中使用:
- fh = open('c:\\autoexec.bat')
- for line in fh.readlines():
- print line
.readline() 和 .readlines() 之间的差异是后者一次读取整个文件,象 .read() 一样。.readlines() 自动将文件内容分析成一个行的列表,该列表可以由 Python 的 for ... in ... 结构进行处理。另一方面,.readline() 每次只读取一行,通常比 .readlines() 慢得多。仅当没有足够内存可以一次读取整个文件时,才应该使用 .readline()。
练习题:用户名与密码的验证
首先新建一个文件,这里为test.log文件,内容为两行如下:
- admin$123
- ginvip$123456
1:让用户选择1或2,1为登录,2为注册
2:如果用户选择1,用户输入用户名与密码,然后与test.log文件中的用户名与密码进行验证,验证成功输出“登录成功”,否则“登录失败”
3:如果用户选择2,让用户输入用户名与密码,并与test.log文件中的用户名验证,如果test.log中用户名已经存在,则输出“该用户名已经存在”,否则将用户输入的用户与密码以上面test.log文件中的形式写入test.log文件中
- def check_user(user) :
- with open('test.log','r',encoding='utf-8') as f :
- for line in f :
- user_list = line.strip()
- user_list = user_list.split('$')
- if user == user_list[0] :
- return True
- return False
- def register(user,pwd) :
- with open('test.log','a',encoding='utf-8') as f :
- user_info = '\n' + user + '$' + pwd
- if f.write(user_info) :
- return True
- return False
- def login(user,pwd) :
- with open('test.log','r',encoding='utf-8') as f :
- for line in f:
- user_list = line.strip()
- user_list = user_list.split('$')
- if user == user_list[0] and pwd == user_list[1]:
- return True
- return False
- def main() :
- print('welcome to my website')
- choice = input('1:login 2:register')
- if choice == '':
- user = input('input username :')
- pwd = input('input password : ')
- if check_user(user) :
- print('the username is exist')
- else:
- if register(user,pwd) :
- print('register success')
- else:
- print('register failed')
- elif choice == '':
- user = input('input username :')
- pwd = input('input password : ')
- if login(user,pwd) :
- print('login success')
- else:
- print('login failed')
- main()
冒泡排序
冒泡排序的原理:
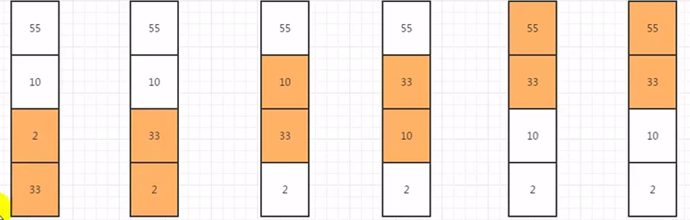
- def Bubble_sort(args) :
- for i in range(len(args)-1) :
- for j in range(len(args) -1):
- if args[j] > args[j+1]:
- temp = args[j]
- args[j] = args[j+1]
- args[j+1] = temp
- return args
- li = [33,2,10,1,9,3,8]
- print(Bubble_sort(li))
练习题
1、简述普通参数、指定参数、默认参数、动态参数的区别
2、写函数,计算传入字符串中【数字】、【字母】、【空格] 以及 【其他】的个数
- digit = 0
- case = 0
- space = 0
- other = 0
- def func2(s) :
- global digit,case,space,other
- if not isinstance(s,basestring) :
- print('the data type wrong!')
- return False
- for i in s :
- if i.isdigit() :
- digit += 1
- elif i.isalpha() :
- case += 1
- elif i.isspace() :
- space += 1
- else:
- other += 1
- s = 'I love python , is num 1 , o_k'
- a = [1,2,3]
- func2(s)
- print(digit)
- print(case)
- print(space)
- print(other)
- ########################################
- 1
- 18
- 8
- 3
- 问题:判断是不是字符串后直接退出函数,而不执行下面的代码?
第2题答案
3、写函数,判断用户传入的对象(字符串、列表、元组)长度是否大于5。
- def func3(v) :
- if len(v) > 5 :
- return True
- else:
- return False
- a = 'I love python , is num 1 , o_k'
- l = [1,2,3]
- t = (5,7,9,10,45,10)
- print(func3(t))
第三题答案
4、写函数,检查用户传入的对象(字符串、列表、元组)的每一个元素是否含有空内容。
5、写函数,检查传入列表的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者。
- def func5(lis) :
- if len(lis) > 2 :
- return lis[0:2]
- else :
- return False
- li = [1,2,3]
- print(func5(li))
- ##########################################
- [1, 2]
第五题答案
6、写函数,检查获取传入列表或元组对象的所有奇数位索引对应的元素,并将其作为新列表返回给调用者。
- def func6(lis) :
- new_lis = []
- for k in range(len(lis)) :
- if k % 2 == 1 :
- new_lis.append(lis[k])
- return new_lis
- li = [1,2,3,8,10,44,77]
- tu = ('poe','andy','jet','bruce','jacky')
- print(func6(tu))
- ##########################################
- ['andy', 'bruce']
第六题答案
7、写函数,检查传入字典的每一个value的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者。
- dic = {"k1": "v1v1", "k2": [,,,]}
- PS:字典中的value只能是字符串或列表
- def func7(d) :
- v = d.values()
- li = []
- for i in v :
- if len(i) > 2:
- li.append(i[0:2])
- return li
- print(func7(dic))
- ##########################################
- [[11, 22], 'v1']
第七题答案
8、写函数,利用递归获取斐波那契数列中的第 10 个数,并将该值返回给调用者
- def fabonacci(n) :
- if n == 0 :
- return 0
- elif n == 1:
- return 1
- else:
- return fabonacci(n-1) + fabonacci(n-2)
- print(fabonacci(10))















 1655
1655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









