







二叉搜索数相比普通的二叉树,有着自己独特的特性:
二叉搜索树是一个有序树:
若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
它的左、右子树也分别为二叉搜索树
针对则一个特性,我们二叉搜索树的递归和迭代程序也有所不同:
递归:
class Solution {
public:
TreeNode* searchBST(TreeNode* root, int val) {
//首先确立终止条件,当遍历到空节点或者遍历到了我们需要的节点的时候结束递归
if (root == NULL || root->val == val) return root;
//题目要求返回一个以val为根节点的二叉树,所以我们要设立一个指向值为val的指针
TreeNode* result = NULL;
//如果当前节点的值大于val,则
if (root->val > val) result = searchBST(root->left, val);
if (root->val < val) result = searchBST(root->right, val);
return result;
}
};迭代则更加简单,
因为二叉搜索树的特殊性,也就是节点的有序性,可以不使用辅助栈或者队列就可以写出迭代法。
对于一般二叉树,递归过程中还有回溯的过程,例如走一个左方向的分支走到头了,那么要调头,在走右分支。
而对于二叉搜索树,不需要回溯的过程,因为节点的有序性就帮我们确定了搜索的方向。
例如要搜索元素为3的节点,我们不需要搜索其他节点,也不需要做回溯,查找的路径已经规划好了。
class Solution {
public:
TreeNode* searchBST(TreeNode* root, int val) {
while (root != NULL) {
if (root->val > val) root = root->left;
else if (root->val < val) root = root->right;
else return root;
}
return NULL;
}
};验证二叉搜索树
https://leetcode.cn/problems/validate-binary-search-tree/
给定一个二叉树,判断其是否是一个有效的二叉搜索树。
思路:搜索二叉树一个特性就是中序遍历的时候得到的数组是升序,所以我们可以通过判断中序遍历后的数组是否是递增的来判断是否为二叉搜索树:
递归代码如下:
class Solution {
public:
vector<int> result;
bool isValidBST(TreeNode* root) {
traversal(root);
for(int i = 1; i < result.size(); i++){
if(result[i] <= result[i - 1]){
return false;
}
}
return true;
}
void traversal(TreeNode* root){
if(root == NULL ) return;
if(root -> left) traversal(root -> left);
result.push_back(root -> val);
if(root -> right) traversal(root -> right);
}
};迭代代码如下:
class Solution {
public:
bool isValidBST(TreeNode* root) {
stack<TreeNode*> st;
TreeNode* cur = root;
TreeNode* pre = NULL; // 记录前一个节点
while (cur != NULL || !st.empty()) {
if (cur != NULL) {
st.push(cur);
cur = cur->left; // 左
} else {
cur = st.top(); // 中
st.pop();
if (pre != NULL && cur->val <= pre->val)
return false;
pre = cur; //保存前一个访问的结点
cur = cur->right; // 右
}
}
return true;
}
};二叉搜索树的最小绝对差
给你一棵所有节点为非负值的二叉搜索树,请你计算树中任意两节点的差的绝对值的最小值。
思路:最直接的思路,中序遍历后对数组求最小差值:
class Solution {
public:
vector<int> result;
int getMinimumDifference(TreeNode* root) {
traversal(root);
int minvalue = INT_MAX;
for(int i = 1; i < result.size(); i++){
minvalue = minvalue < (result[i] - result[i - 1])? minvalue : (result[i] - result[i - 1]);
}
return minvalue;
}
void traversal(TreeNode* root){
if(root == NULL ) return;
if(root -> left) traversal(root -> left);
result.push_back(root -> val);
if(root -> right) traversal(root -> right);
}
};以上代码是把二叉搜索树转化为有序数组了,其实在二叉搜素树中序遍历的过程中,我们就可以直接计算了。需要用一个pre节点记录一下cur节点的前一个节点。
class Solution {
private:
int result = INT_MAX;
TreeNode* pre = NULL;
void traversal(TreeNode* cur) {
if (cur == NULL) return;
traversal(cur->left); // 左
if (pre != NULL){ // 中
result = min(result, cur->val - pre->val);
}
pre = cur; // 记录前一个
traversal(cur->right); // 右
}
public:
int getMinimumDifference(TreeNode* root) {
traversal(root);
return result;
}
};class Solution {
public:
int getMinimumDifference(TreeNode* root) {
stack<TreeNode*> st;
TreeNode* cur = root;
TreeNode* pre = NULL;
int result = INT_MAX;
while (cur != NULL || !st.empty()) {
if (cur != NULL) { // 指针来访问节点,访问到最底层
st.push(cur); // 将访问的节点放进栈
cur = cur->left; // 左
} else {
cur = st.top();
st.pop();
if (pre != NULL) { // 中
result = min(result, cur->val - pre->val);
}
pre = cur;
cur = cur->right; // 右
}
}
return result;
}
};二叉搜索树中的众数
给定一个有相同值的二叉搜索树(BST),找出 BST 中的所有众数(出现频率最高的元素)。

思路:如果按照一般二叉树思考的话,那就是遍历整个二叉树,然后使用map进行统计数值和对应的出现次数,最后按照出现次数进行排列。
代码如下:
class Solution {
public:
vector<int> vec;
vector<int> result;
vector<int> findMode(TreeNode* root) {
// map<int, int> key:元素,value:出现频率,可以参考哈希表章节的题目内容
unordered_map<int,int> map;
if(root == NULL) return result;
traversal(root,map);
//把统计的出来的出现频率(即map中的value)排个序
//map不能对value排序,所以需要先转化为数组,然后进行排序
//所以要把map转化数组即vector,再进行排序,
//当然vector里面放的也是pair<int, int>类型的数据,第一个int为元素,第二个int为出现频率。
vector<pair<int,int>> vec(map.begin(),map.end());
sort(vec.begin(),vec.end(),cmp);
result.push_back(vec[0].first);
for(int i = 1; i < vec.size();i++){
if(vec[i].second == vec[0].second){
result.push_back(vec[i].first);
}else break;
}return result;
}
private:
void traversal(TreeNode* root, unordered_map<int,int>& map){
if(root == NULL) return;
traversal(root -> left,map);
map[root -> val]++;// 统计元素频率
traversal(root -> right,map);
return;
}
bool static cmp(const pair<int,int>& a,const pair<int,int>& b){
return a.second > b.second;
}
};补充知识:cmp快排:
sort函数中的比较函数cmp(),即void sort( iterator start, iterator end, StrictWeakOrdering cmp );
sort函数头文件为:#include <algorithm>
其中,cmp函数可以自己编写,自己决定逻辑,包括cmp的命名也是自己决定的。
bool cmp(int a ,int b)
{
return a < b ; 从小到大排序,把 < 换成 > 就是从大到小
}
sort(p.begin(), p.end(), cmp);引用自: https://blog.csdn.net/weixin_53833977/article/details/124322406
注意到,其中和cmp函数的示例有以下不同:
1. 形参写成了const引用的形式
2. 函数更改为静态函数static
关于1:当引用作为形参,函数调用时也可以看成将传递的实参绑定给它,这样我们在函数体内对这个引用做的一切操作都有可能影响到函数传递的实参。如果我们希望参数在函数体内是只读的,所以当我们加了引用有希望参数是只读的就必须加 const。
为什么不直接值传递呢? 确实,但是当参数是类对象时值传递就有了一个问题,那就是性能可能会大受影响。我们知道值传递实际就是向函数拷贝一份副本来使用,那么对于一些复杂的类,尤其是 string 这样每一次拷贝可能消耗很多的时间,那么通过引用传参就很有必要了。
总的来说 因为我想提高类对象传参时的性能,所以要用引用,因为用了引用我又希望它只读所以我用了const。
关于2:在(非静态成员)函数的返回类型前加上关键字static,函数就被定义成为静态函数。普通 函数的定义和声明默认情况下是extern的,但静态函数只是在声明他的文件当中可见,不能被其他文件所用。因此定义静态函数有以下好处:
<1> 其他文件中可以定义相同名字的函数,不会发生冲突。
<2> 静态函数不能被其他文件所用。
当考虑搜索二叉树的时候,我们知道搜索二叉树根据中序遍历可以得到一个升序数组:
那么我们遍历数组的时候,同时考虑前后是否一致,如果一致则count+1,最后统计count谁最大即可,但是这里还有两个要注意的地方,一个是count可能存在一样大的,另一个是count的最大值是不断改变的,如果最大值变大,就要重新更换最大值,并且清零之前的内容。这样的好处是只用遍历一遍(要不然一层for找最大值,一层for找最大频率)
代码如下:
class Solution {
private:
int maxCount = 0; // 最大频率
int count = 0; // 统计频率
TreeNode* pre = NULL;
vector<int> result;
void searchBST(TreeNode* cur) {
if (cur == NULL) return ;
searchBST(cur->left); // 左
// 中
if (pre == NULL) { // 第一个节点
count = 1;
} else if (pre->val == cur->val) { // 与前一个节点数值相同
count++;
} else { // 与前一个节点数值不同
count = 1;
}
pre = cur; // 更新上一个节点
if (count == maxCount) { // 如果和最大值相同,放进result中
result.push_back(cur->val);
}
if (count > maxCount) { // 如果计数大于最大值频率
maxCount = count; // 更新最大频率
result.clear(); // 很关键的一步,不要忘记清空result,之前result里的元素都失效了
result.push_back(cur->val);
}
searchBST(cur->right); // 右
return ;
}
public:
vector<int> findMode(TreeNode* root) {
count = 0;
maxCount = 0;
TreeNode* pre = NULL; // 记录前一个节点
result.clear();
searchBST(root);
return result;
}
};二叉树的最近公共祖先
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”

思路:
这道题第一想法是通过自下而上的方法进行遍历,这样就可以找到节点的公共祖先,但是二叉树本身没法从下而上查找,需要使用回溯进行查找。其中后序遍历就是天然的回溯过程,可以根据左右子树的返回值,来处理中间节点。
这个时候我们就要去想如何去处理和具体的情况分析:
当我们找到一个节点,发现左子树出现节点p(q),右子树出现节点q(p),是不也是说明这个节点是pq的最近公共祖先呢?比如上面的二叉树中qp是7和4,我们遍历节点2的时候发现。那么根据这个想法,我们去进行遍历:
确定递归函数返回值以及参数
我们还要返回最近公共节点,可以利用上题目中返回值是TreeNode * ,那么如果遇到p或者q,就把q或者p返回,返回值不为空,就说明找到了q或者p。
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q)确定终止条件
遇到空的话,因为树都是空了,所以返回空。
那么我们来说一说,如果 root == q,或者 root == p,说明找到 q p ,则将其返回。
if (root == q || root == p || root == NULL) return root;确定单层递归逻辑
TreeNode* left = lowestCommonAncestor(root->left, p, q);
TreeNode* right = lowestCommonAncestor(root->right, p, q);
if (left != NULL && right != NULL) return root;
if (left == NULL && right != NULL) return right;
else if (left != NULL && right == NULL) return left;
else { // (left == NULL && right == NULL)
return NULL;
}整体代码如下:
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if (root == q || root == p || root == NULL) return root;
TreeNode* left = lowestCommonAncestor(root->left, p, q);
TreeNode* right = lowestCommonAncestor(root->right, p, q);
if (left != NULL && right != NULL) return root;
if (left == NULL && right != NULL) return right;
else if (left != NULL && right == NULL) return left;
else { // (left == NULL && right == NULL)
return NULL;
}
}
};二叉搜索树的最近公共祖先
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
思路:运用二叉搜索树中序遍历有序数组的思路,找到范围在[p,q]之间的值。
class Solution {
private:
TreeNode* traversal(TreeNode* cur, TreeNode* p, TreeNode* q) {
if (cur == NULL) return cur;
// 中
if (cur->val > p->val && cur->val > q->val) { // 左
TreeNode* left = traversal(cur->left, p, q);
if (left != NULL) {
return left;
}
}
if (cur->val < p->val && cur->val < q->val) { // 右
TreeNode* right = traversal(cur->right, p, q);
if (right != NULL) {
return right;
}
}
return cur;
}
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
return traversal(root, p, q);
}
};class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
while(root) {
if (root->val > p->val && root->val > q->val) {
root = root->left;
} else if (root->val < p->val && root->val < q->val) {
root = root->right;
} else return root;
}
return NULL;
}
};二叉搜索树中的插入操作
https://leetcode.cn/problems/insert-into-a-binary-search-tree/
给定二叉搜索树(BST)的根节点和要插入树中的值,将值插入二叉搜索树。 返回插入后二叉搜索树的根节点。 输入数据保证,新值和原始二叉搜索树中的任意节点值都不同。
思路:遍历二叉搜索树,找到空节点后插入元素即可
class Solution {
public:
TreeNode* insertIntoBST(TreeNode* root, int val) {
if (root == NULL) {
TreeNode* node = new TreeNode(val);
return node;
}
if (root->val > val) root->left = insertIntoBST(root->left, val);
if (root->val < val) root->right = insertIntoBST(root->right, val);
return root;
}
};注意看这里的return node,这里递归加入了返回值,运用返回值可以帮助完成新加入节点和父节点的赋值,我们可以看代码第六行return的是node,也就是当遍历到空节点的时候,我们要插入节点的位置,并且将插入的节点返回到上一层,然后我们在单层递归中用root ->left , root -> right将其接住。(不理解的话可以看下一个删除二叉搜索树节点)
删除二叉搜索树中的节点
https://leetcode.cn/problems/delete-node-in-a-bst/
给定一个二叉搜索树的根节点 root 和一个值 key,删除二叉搜索树中的 key 对应的节点,并保证二叉搜索树的性质不变。返回二叉搜索树(有可能被更新)的根节点的引用。
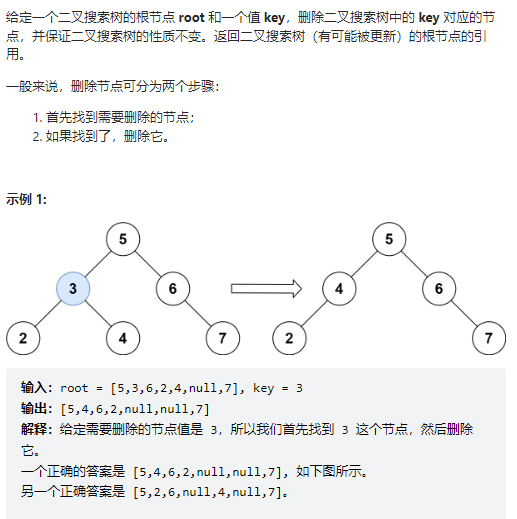
思路:和插入叶子节点只需要考虑叶子的情况不同,删除节点是可以删除任意地方的节点,需要针对节点情况进行专门分析:
情况一:
没有找到删除的节点,遍历到空节点就返回了:
if (root == nullptr) return root;情况二:
找到了要删除的节点,这个节点自身就是叶子节点,那么要删掉这个节点,并且返回NULL
if( !root -> left && !root -> right){
delete root;
return NULL;
情况三:
找到了删除节点,这个节点有左子树,没有右子树。这个时候要让左子树的节点等于该节点,同时这个时候要把新的一层节点返回给上一层,上一层需要用root ->left , root -> right将其接住。
if(root -> left && !root -> right){
root = root -> left;
return root; 情况四:
和三一样,区别是左子树没有,右子树有:
if(root -> right && !root -> left){
root = root -> right;
return root;情况五:
最复杂的一种,左右子树都存在。这个时候我们就要要去考虑搜索二叉树的特征了,那就是中序遍历是升序数组,所以我们可以采用“嫁接”的方法,将左节点嫁接到右节点的左节点末尾,这个时候新的二叉树是符合搜索二叉树有序数组的要求的。
else {
TreeNode* cur = root->right; // 找右子树最左面的节点
while(cur->left != nullptr) {
cur = cur->left;
}
cur->left = root->left; // 把要删除的节点(root)左子树放在cur的左孩子的位置
TreeNode* tmp = root; // 把root节点保存一下,下面来删除
root = root->right; // 返回旧root的右孩子作为新root
delete tmp; // 释放节点内存(这里不写也可以,但C++最好手动释放一下吧)
return root;
}整体代码如下:
class Solution {
public:
TreeNode* deleteNode(TreeNode* root, int key) {
if(root == NULL) return NULL;
return traversal(root ,key);
}
private:
TreeNode* traversal(TreeNode* root, int key){
if(root == NULL) return root;
if(root -> val == key){
if( !root -> left && !root -> right){
delete root;
return NULL;
}
if(root -> left && !root -> right){
root = root -> left;
return root;
}
if(root -> right && !root -> left){
root = root -> right;
return root;
}
else{
TreeNode* cur = root -> right;
while(cur -> left != NULL){
cur = cur -> left;
}
cur -> left = root -> left;
TreeNode* tmp = root;
root = root -> right;
delete tmp;
return root;
}
}
//注意这里一定要有承接,因为上面删除了节点root,把新的节点返回给上一层,上一层就需要接住。
if(root -> val > key) root->left =traversal(root -> left,key);
if(root -> val < key) root->right =traversal(root -> right,key);
return root;
}
};修剪二叉搜索树
https://leetcode.cn/problems/trim-a-binary-search-tree/
给定一个二叉搜索树,同时给定最小边界L 和最大边界 R。通过修剪二叉搜索树,使得所有节点的值在[L, R]中 (R>=L) 。你可能需要改变树的根节点,所以结果应当返回修剪好的二叉搜索树的新的根节点。
思路:
修剪二叉树并不能直接在递归中定义L和R边界,因为搜索二叉树的特性,左子树小于L的情况下,左子树的右子树不一定也小于L,同理右子树和R也有关系,所以当左右子树分别小于L大于R的时候,也要考虑左子树的右子树,右子树的左子树
代码如下:
class Solution {
public:
TreeNode* trimBST(TreeNode* root, int low, int high) {
if (root == nullptr ) return nullptr;
if (root->val < low) {
TreeNode* right = trimBST(root->right, low, high); // 寻找符合区间[low, high]的节点
return right;
}
if (root->val > high) {
TreeNode* left = trimBST(root->left, low, high); // 寻找符合区间[low, high]的节点
return left;
}
root->left = trimBST(root->left, low, high); // root->left接入符合条件的左孩子
root->right = trimBST(root->right, low, high); // root->right接入符合条件的右孩子
return root;
}
};将有序数组转换为二叉搜索树
https://leetcode.cn/problems/convert-sorted-array-to-binary-search-tree/
将一个按照升序排列的有序数组,转换为一棵高度平衡二叉搜索树。
本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1。
思路:
class Solution {
public:
TreeNode* sortedArrayToBST(vector<int>& nums) {
TreeNode* root = traversal(nums, 0, nums.size() - 1);
return root;
}
private:
TreeNode* traversal(vector<int>& nums, int low,int high){
if(low > high) return NULL;
int mid = low +(high - low) / 2;
TreeNode* root = new TreeNode(nums[mid]);
root -> left = traversal(nums, low, mid - 1);
root -> right = traversal(nums, mid + 1, high);
return root;
}
};把二叉搜索树转换为累加树
https://leetcode.cn/problems/convert-bst-to-greater-tree/
给出二叉 搜索 树的根节点,该树的节点值各不相同,请你将其转换为累加树(Greater Sum Tree),使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。
思路:通过pre指针从后向前反向遍历数组(也就是中序遍历得到的数组反向遍历)
class Solution {
private:
int pre = 0; // 记录前一个节点的数值
void traversal(TreeNode* cur) { // 右中左遍历
if (cur == NULL) return;
traversal(cur->right);
cur->val += pre;
pre = cur->val;
traversal(cur->left);
}
public:
TreeNode* convertBST(TreeNode* root) {
pre = 0;
traversal(root);
return root;
}
};














 495
495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









