







1. tokenizer
NLP的第一步是把文字转换为数字:

下面是个例子:
# 创建并运行数据处理管道
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import TweetTokenizer
from nltk.corpus import stopwords
from nltk.tag import pos_tag
def data_cleaning(text_list):
stopwords_rem=False
stopwords_en=stopwords.words('english')
lemmatizer=WordNetLemmatizer()
tokenizer=TweetTokenizer()
reconstructed_list=[]
for each_text in text_list:
lemmatized_tokens=[]
tokens=tokenizer.tokenize(each_text.lower())
pos_tags=pos_tag(tokens)
for each_token, tag in pos_tags:
if tag.startswith('NN'):
pos='n'
elif tag.startswith('VB'):
pos='v'
else:
pos='a'
lemmatized_token=lemmatizer.lemmatize(each_token, pos)
if stopwords_rem: # False
if lemmatized_token not in stopwords_en:
lemmatized_tokens.append(lemmatized_token)
else:
lemmatized_tokens.append(lemmatized_token)
reconstructed_list.append(' '.join(lemmatized_tokens))
return reconstructed_list
text到token的步骤叫做分词,有3种基本方法:
1)基于词典的分词方式:将待分词的中文文本根据一定规则切分和调整,然后跟词典中的词语进行匹配,匹配成功则按照词典的词分词,匹配失败通过调整或者重新选择,如此反复循环即可。代表方法有:
1. 最大正向匹配:切分m(最长可能字符数)个字符,从多到少依次看有没有匹配上的单词;
2. 最大逆向匹配:相反
3. 双向最大匹配:正向、逆向各匹配一次,选取取词数较少的作为匹配结果。
2)基于统计的分词方式:简单来说,是先估算好所有单词、词组的概率,那么句子S的分词方法就是使得
p
(
w
1
,
w
2
,
.
.
.
,
w
n
)
p(w_1,w_2,...,w_n)
p(w1,w2,...,wn)最大的划分方法。枚举分词效率比较低,实际一般使用动态规划+维特比(Viterbi)算法来求解。

tokens的总数量对于结果的影响很大,LLaMA的65B效果可以比肩GPT-3的175B效果。
vocab的数量对结果影响也很大:
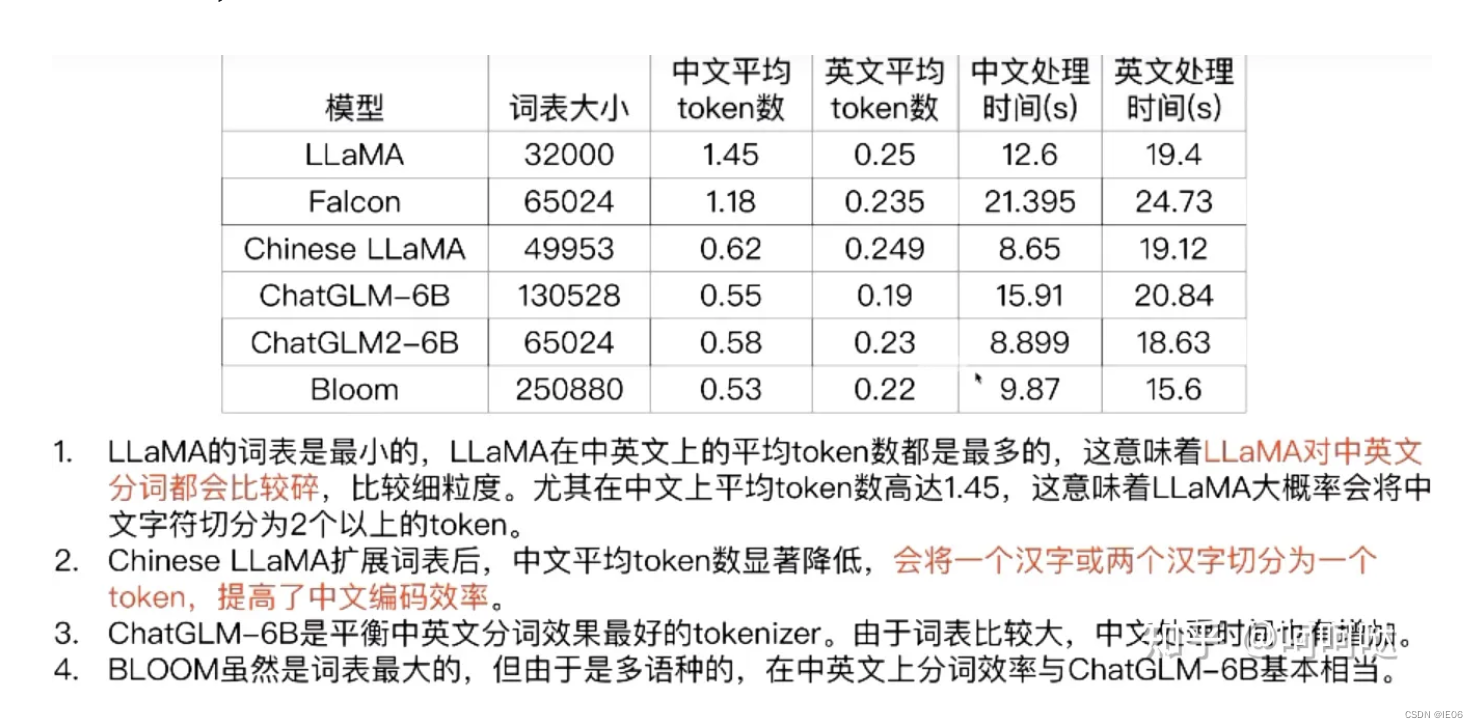
3)基于深度学习的分词方式:例如有人员尝试使用双向LSTM+CRF实现分词器,其本质上是序列标注,所以有通用性,命名实体识别等都可以使用该模型,据报道其分词器字符准确率可高达97.5%。
2. embedding
接下来就是把数组转化为特征向量,叫做词表示(word representation)。有两个基本要求:能够表达词语相似度(similarity);能够推断词语之间的关系(relation)。
embedding包含两大类方法:词袋类和词向量类。词袋模型不考虑句子结构,仅统计单词数量,构建每个句子的特征向量;词向量模型则考虑句子结构,用训练出来的新词向量重新构建句子矩阵。由于词向量可以一次训练多次使用,因此也是目前比较常用的方法。
2.1 词袋类模型
2.1.1 基础词袋模型
文本分析的第一步是提取特征,最基本的方法是忽略文章结构,仅仅对出现的词的数量进行统计,称为词袋模型。例子如下:
语料为:
Jane wants to go to Shenzhen.
Bob wants to go to Shanghai.
词典为:
[Jane, wants, to, go, Shenzhen, Bob, Shanghai]
则两句话用词频向量可以表达为:
[1,1,2,1,1,0,0]
[0,1,2,1,0,1,1]
参考代码:
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
corpus = ["Jane wants to go to Shenzhen.","Bob wants to go to Shanghai."]
X = vectorizer.fit_transform(corpus)
feature_names = vectorizer.get_feature_names_out()
X_feature = X.toarray()
print(feature_names)
print(X_feature)
有些单词、词组在语料库中没有出现过~因此我们要考虑这个问题,留一些概率给没有出现过的这些单词、词组、句子……使用古德-图灵估计(Good-Turing Estimate),具体的方法如下:
- 统计语料库中出现 r r r次的单词,共 N r N_r Nr个。
- 设置阈值 T T T(一般设置为8-10),如果 0 < r < T 0<r<T 0<r<T,则单词概率的估算值从 r / N r/N r/N变为 N r + 1 ∗ ( r + 1 ) / ( N r ∗ N ) N_{r+1}*(r+1)/(N_r*N) Nr+1∗(r+1)/(Nr∗N),即由 r + 1 r+1 r+1的数据来平滑估计 r r r的数据。
- 这样可以得到出现0次的单词的概率估计值从0变为
Σ
r
<
T
(
r
−
(
r
+
1
)
∗
N
r
+
1
/
N
r
)
/
N
\Sigma _{r<T} (r - (r+1)*N_{r+1}/N_r)/N
Σr<T(r−(r+1)∗Nr+1/Nr)/N。
对于二元组的概率估计,也使用同样的方法进行处理。
2.1.2 TF-IDF
TF-IDF也可以看做是词袋模型的优化变种,单词的重要性随着它在文件中出现的次数(count)成正比增加,但同时会随着它在预料库中出现的频率(idf)成反比下降:

TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或者评级。
参考代码如下:
from sklearn.feature_extraction.text import TfidfVectorizer
document = ["I have a pen.",
"I have an apple."]
tfidf_model = TfidfVectorizer().fit(document)
sparse_result = tfidf_model.transform(document) # 得到tf-idf矩阵,稀疏矩阵表示法
print(sparse_result)
print(sparse_result.todense()) # 转化为更直观的一般矩阵
print(tfidf_model.vocabulary_)
也可以基于词袋模型继续计算
from sklearn.feature_extraction.text import TfidfTransformer
transformer = TfidfTransformer(smooth_idf=False)
tfidf = transformer.fit_transform(X_feature).toarray()
print(tfidf,len(tfidf),len(tfidf[0]))
2.2 词向量类模型
NLP领域复杂的文本分类、翻译、文本生成等任务,词向量都是绕不开的一个话题,要实现目标任务,往往需要先训练一份词向量,作为目标任务模型的输入,比起采用随机初始化的词向量作为模型输入,一份预先训练过的良好的词向量总是能给目标任务带来一些增益。
2.2.1 word2vec模型
word2vec也叫word embedding,使用一定范围内(滑动窗口)的上下文(context)和中心词(target)的映射关系,使用神经网络给出新的词向量。
CBOW(连续词袋)则是以上下文组成的单词组作为输入,中心词作为输出进行训练,去除了隐藏层,并且使用词向量的平均值代替了拼接;而skip-gram模型是以中心词作为输入,上下文组成的单词组作为输出进行训练。

使用gensim包,word2vec 相关的API都在包gensim.models.word2vec中,sg参数默认为0,即CBOW算法,如果设置为1则是skip-gram算法。
下面是示例:
from gensim.models import word2vec
document = ["I like pen",
"I like apple",
"I go to school by bus",
"I go to school by subway"]
sentenses = [s.split() for s in document]
model = word2vec.Word2Vec(sentenses,vector_size=10, min_count=1, window=2)
model.wv.similarity('bus','subway'),model.wv['apple']
CBOW和CSG的模型结构如下,其中橙色的部分是词表的大小 :
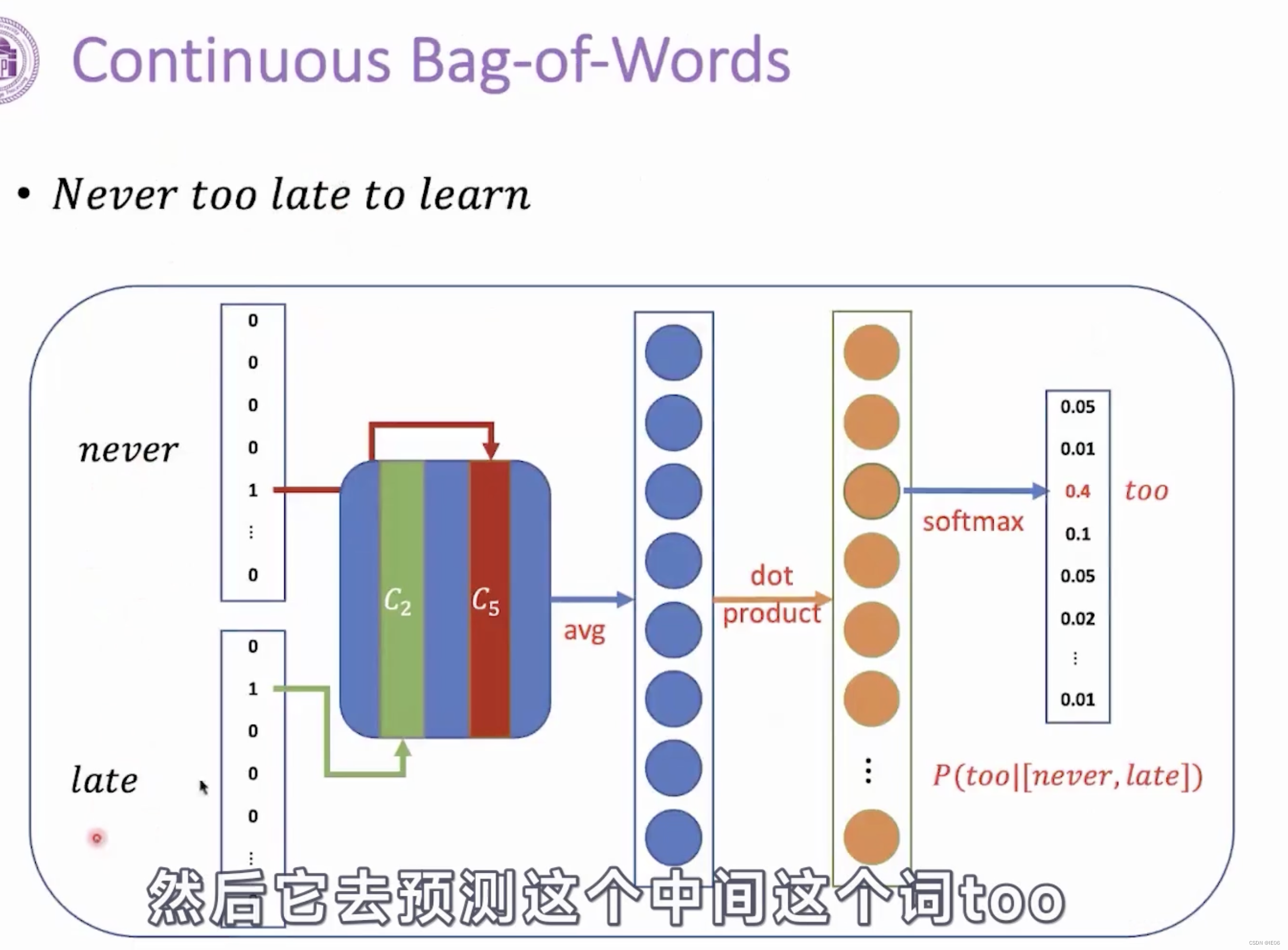
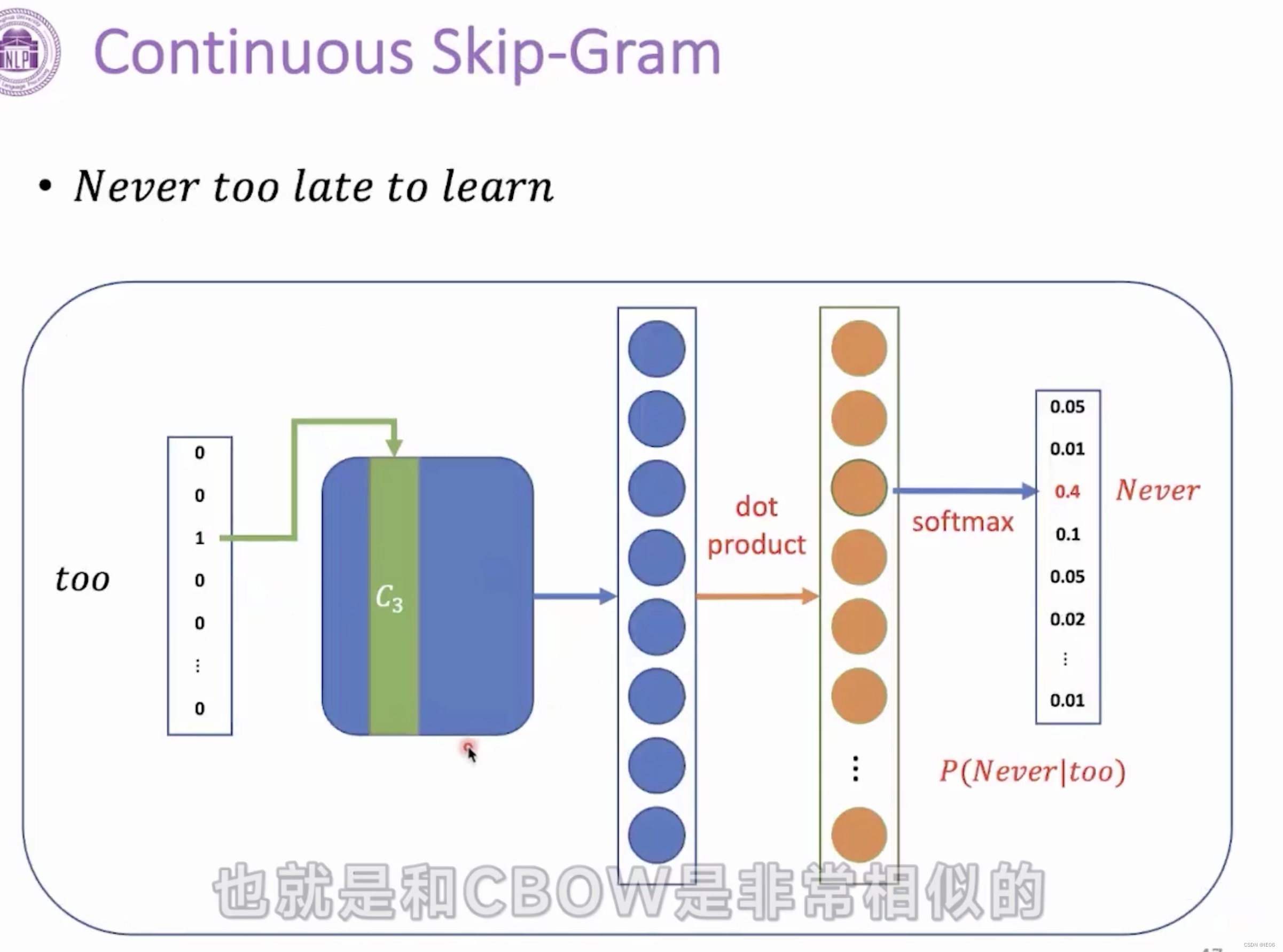
2.2.2 动态词向量模型
同一个单词可能有多个意思,这时候word2vec就出现问题了。因此需要再加一个上下文映射模型,将词向量映射为不同语境下的新向量。
对于动态词向量的尝试,最早可以追溯到CoVe,他们在序列到序列的机器翻译任务上训练了一个深度 LSTM 编码器,然后用它生成根据上下文变化的词向量,再在下游任务中应用这些词向量。
随后就是TagLM,它是一个双向RNN模型,模型的输入是Token representation,可以是word2vec这类静态词向量,输出是编码了上下文语义的词向量。
ELMo是TagLM的升级版,实际上也是同一批人做的。总的来说,它只是改变了TagLM的预训练词向量方法。
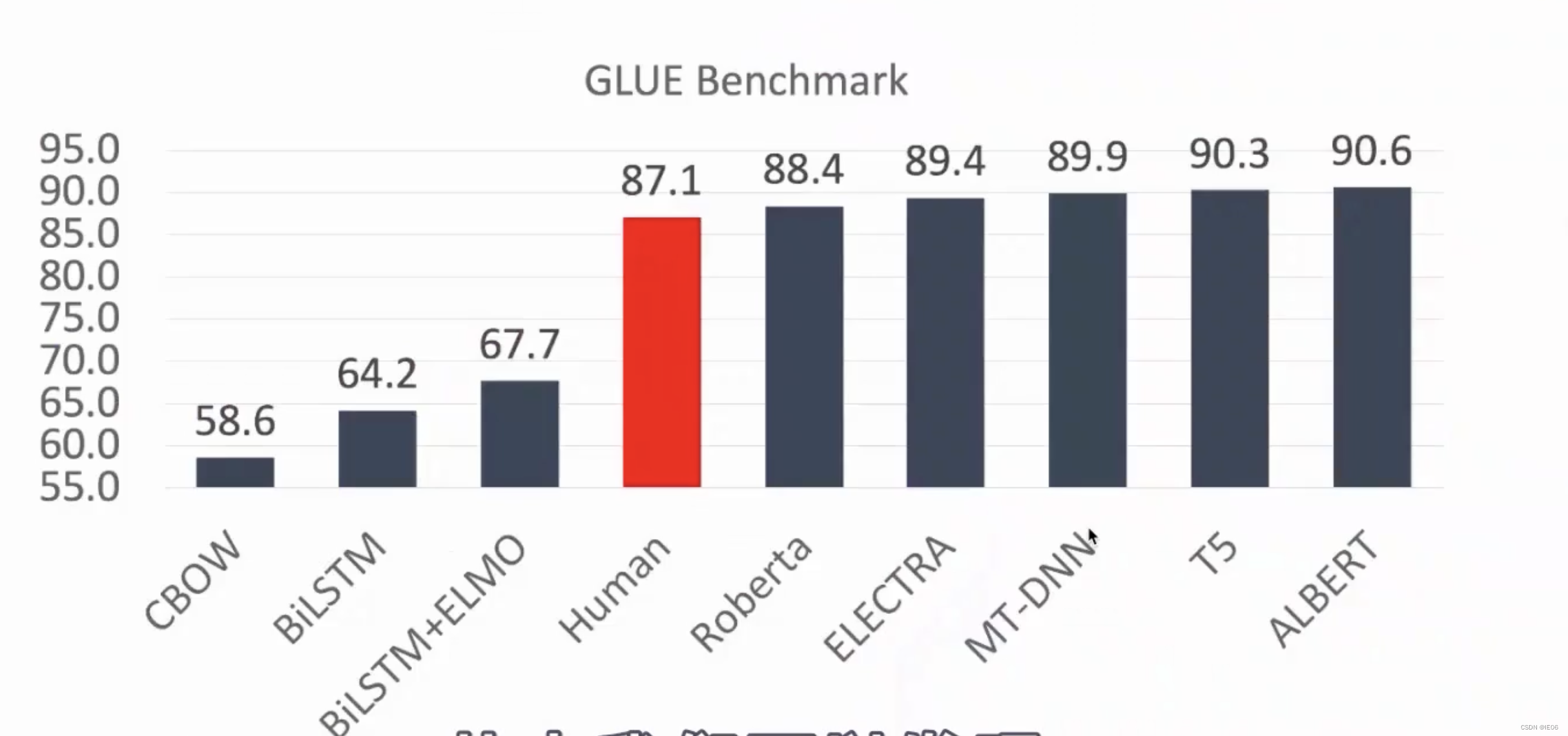
另外,使用了注意力集之后,词向量的效果得到了突飞猛进,我们在后面的大模型文章中进行介绍,这里不多赘述。
3 语言模型
语言模型有两个最基础的任务,一个是判断某个句子是否合理(联合概率),一个是如何生成下一个词(完形填空,条件概率)。
传统的语言模型用的是N-gram方法,用统计方法去描述在前面有N个词的前提下,下一个词的概率分布。
当前主流的方法是2003年有Yoshua Bengio发布的,叫神经网络概率模型。基本原则是:使用神经网络来学习语义,使用向量来表达单词。最近几年则有全面使用预训练大模型解决语言任务的趋势。我们在后面的文章中再介绍。这里只介绍传统的统计学语言模型。

3.1 翻译问题
翻译为例,假设我们接收到的文章是无法理解的句子组合 o 1 , o 2 , . . . o_1,o_2,... o1,o2,...,怎样把它们转化为我们能够理解的句子组合 s 1 , s 2 , . . . s_1,s_2,... s1,s2,...?使用概率模型,求解最大的 p ( s 1 , s 2 , . . . ∣ o 1 , o 2 , . . . ) p(s_1,s_2,...|o_1,o_2,...) p(s1,s2,...∣o1,o2,...)即可。首先将上式转为 p ( o 1 , o 2 , . . . ∣ s 1 , s 2 , . . . ) ∗ p ( s 1 , s 2 , . . . ) / p ( o 1 , o 2 , . . . ) p(o_1,o_2,...|s_1,s_2,...)*p(s_1,s_2,...)/p(o_1,o_2,...) p(o1,o2,...∣s1,s2,...)∗p(s1,s2,...)/p(o1,o2,...),分母是个固定项不用计算,只需要计算分子的两项就行了。紧接着将问题建模成隐马尔科夫过程(Hidden Markov Model),即假设 p ( s 1 , s 2 , . . . ) = p ( s 1 ) ∗ p ( s 2 ∣ s 1 ) ∗ p ( s 3 ∣ s 2 ) ∗ . . . p(s_1,s_2,...)=p(s_1)*p(s_2|s_1)*p(s_3|s_2)*... p(s1,s2,...)=p(s1)∗p(s2∣s1)∗p(s3∣s2)∗...称为转移概率,另外 p ( o 1 , o 2 , . . . ∣ s 1 , s 2 , . . . ) = p ( o 1 ∣ s 1 ) ∗ p ( o 2 ∣ s 2 ) ∗ . . . p(o_1,o_2,...|s_1,s_2,...)=p(o_1|s_1)*p(o_2|s_2)*... p(o1,o2,...∣s1,s2,...)=p(o1∣s1)∗p(o2∣s2)∗...称为发射概率。使用大量语料进行统计的方法,去得到这些概率。
3.2 情感分析
一种有效的方法是基于词典的词袋方法,将词典中的单词标注为积极和消极两类,把句子中所有单词的情感得分加起来,即得到最终的文本情感分。我们可以使用VADER库:
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
# polarity_scores方法
SentimentIntensityAnalyzer().polarity_scores('Today is a good day.')
# output:
# {'neg': 0.0, 'neu': 0.58, 'pos': 0.42, 'compound': 0.4404}
另一种方法是使用传统机器学习方法,如SVM、NB等。首先需要用word2vec方法构建单词特征向量,然后再训练集上用机器学习算法进行分类训练。
最后是使用深度学习的方法(主要是LSTM和GRU方法)。
3.3 词性标注
最简单的方法莫过于将语料库的高频词性作为预测的词性,稍复杂的方法是将问题看做序列标注问题,用隐马尔科夫模型等进行标注。jieba分词使用词典匹配和HMM共同的方式。
3.4 关键词提取和自动摘要
Text-Rank是一种基于图的用于关键词抽取和文档摘要的排序算法,由谷歌的网页重要性排序算法PageRank算法改进而来,它利用一篇文档内部的词语间的共现信息(语义)便可以抽取关键词,它能够从一个给定的文本中抽取出该文本的关键词、关键词组,并使用抽取式的自动文摘方法抽取出该文本的关键句。
自动摘要同样使用Text-Rank方法,注意要计算句子之间两两相似度作为权重乘到得分上。相似度可以用余弦相似度。
3.5 主题分类
方法包括LDA/Top2Vec/BertTopic等。
主题模型可以从大量的文本中发现潜在的主题。LDA是通过假设每个文档由主题的一个多项分布表示,Top2Vec、BertTopic则是通过聚类的方式把不同的文档聚到不同的主题。主题分类的应用有:
- 新闻推荐场景,对语料库的每篇新闻进行主题分析,根据浏览者的已看新闻推荐同主题的新闻
- 商品分析场景,分析商品的评论,挖掘购买者对商品不同维度的意见和评价
首先要进行降维和聚类:
- UMAP 18年提出,目前是当红炸子鸡的降维算法,属于非线性流形降维。由于 embedding 空间通常有着各向异性的问题,用 PCA 这种线性降维效果是不适合的,而 UMAP 相对于 t-SNE,能更好保留原空间的局部和全局结构,且计算效率更好
- 密度聚类优势能天然挖掘异常点。因为 embedding 空间的各向异性,并不适合用 K-means 这种 centroid-based 的聚类方。HDBSCAN 相比于 DBSCAN,不用定义领域半径 eps 和密度阈值 MinPt 这两个刺手的参数。
Doc2vec 技术,把文档和词都映射到同一个语义向量空间。对文档向量进行聚类,分成不同的簇,每个簇就代表一个主题,同一个簇的文档向量求 average,得到的向量作为该主题的 Topic 表示,再用离该 topic vector 最近的N个词作为该 Topic 的表示。
BertTopic 并不是把文档和词都嵌入到同一个空间,而是单独对文档进行 embedding 编码,然后同样过降维和聚类,得到不同的主题。但在寻找主题表示时,是把同一个主题下的所有文档看成一个大文档,然后通过 c-TF-IDF 最高的N个词作为该主题表示。简单点说,BerTopic 寻找主题表示时用的是 bags-of-words。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









