







1. 简单文本:tesseract
使用google加的tesseract,效果不错。
首先安装tesseract,在mac直接brew install即可。
python调用代码:
import pytesseract
from PIL import Image
img = Image.open('1.png')
pytesseract.image_to_string(img, lang='chi_sim+eng')
2. 结构化文本:paddleocr
使用百度家的paddleocr可以达成如下效果:
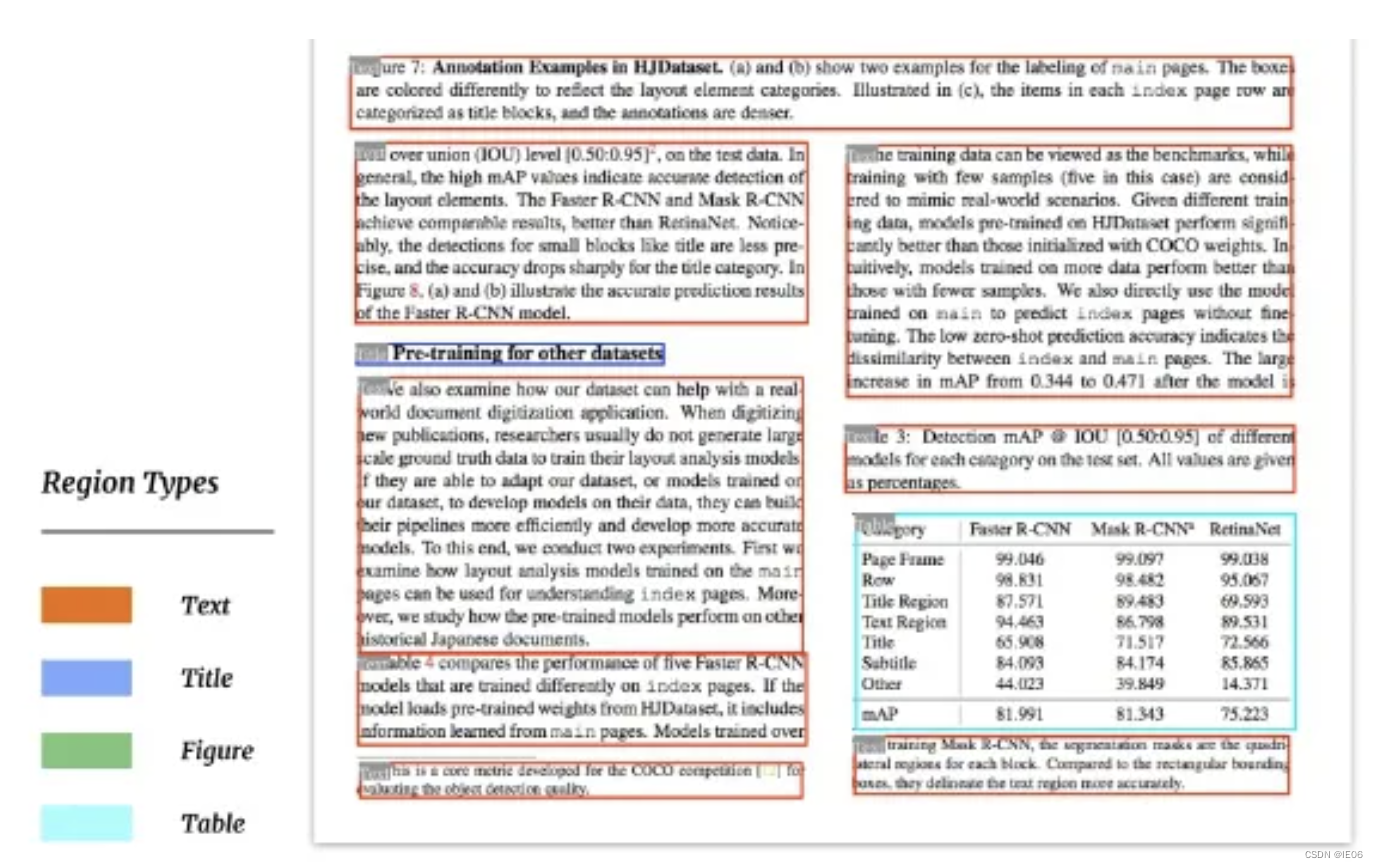
安装方法:pip install “paddleocr>=2.2”,调用代码。
其中画图的部分如果要用的话,需要下载字体库:!git clone https://gh.api.99988866.xyz/https://github.com/PaddlePaddle/PaddleOCR;不需要画图的话,注释掉即可。
import os
import cv2
from paddleocr import PPStructure, draw_structure_result, save_structure_res
from PIL import Image
def Structure_analysis(img_path):
table_engine = PPStructure(show_log=True)
save_folder = './output/table'
img = cv2.imread(img_path)
result = table_engine(img)1
save_structure_res(result, save_folder,os.path.basename(img_path).split('.')[0])
for line in result:
line.pop('img')
print(line)
font_path = '../PaddleOCR/doc/fonts/simfang.ttf' # PaddleOCR下提供字体包
image = Image.open(img_path).convert('RGB')
im_show = draw_structure_result(image, result, font_path=font_path)
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
pass
Structure_analysis('1.png')
3. 加强结构化文本:openparse
默认使用pypdf 和 pdfminer.six来解析pdf文档,将内容划分成node,再根据一些启发式规则如将标题与接下来的内容合并、将项目列表内容合并等来对pdf内容进行分块。
安装:
pip install openparse
#如果要使用识别表格的算法
pip install "openparse[ml]"
#安装openparse[ml]后,使用如下命令来下载模型,大概会占用1.5G的空间
openparse-download
# 测试文档
wget https://sergey-filimonov.nyc3.digitaloceanspaces.com/open-parse/sample-docs/naic-numerical-list-of-companies-page-94.pdf -O companies-list.pdf
wget https://sergey-filimonov.nyc3.digitaloceanspaces.com/open-parse/sample-docs/mobile-home-manual.pdf -O mobile-home-manual.pdf
解析和展示的代码如下:
import openparse
from openparse import DocumentParser
parser = DocumentParser()
parsed_content = parser.parse("mobile-home-manual.pdf")
for node in parsed_content.nodes:
display(node)
print("*"*20)
原文档和解析结果如下:

文本是以markdown形式保存的:

open_parse支持设置table_args来进行表格提取,其主要有如下三个参数。
parsing_algorithm, 用来解析表格的库,目前支持值为:pymupdf、unitable、table-transformers
min_table_confidence,默认值为0.75,一个表格被提取的置信度分数。
table_output_format,表格输出格式,unitable支持html、pymupdf和table-transformers支持html和markdown
pdf_path = "companies-list.pdf"
parser = DocumentParser(
table_args={
"parsing_algorithm": "unitable",
"min_table_confidence": 0.8}
)
parsed_content = parser.parse(pdf_path)
# 可通过node.variable来判断是否提取到表格,存在表格的话,里面会有"table" key存在
table_nodes = [node for node in parsed_nodes.nodes if "table" in node.variant]
# 也可以将提取的表格在原PDF中展示出来
doc = openparse.Pdf(file=pdf_path)
doc.display_with_bboxes(table_nodes)















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









