







SDS Simple Dynamic String
结构体定义
-
struct __attribute__ ((__packed__)) sdshdr8 {
-
uint8_t len; /* 使用长度 */
-
uint8_t alloc; /* 申请的长度 */
-
unsigned char flags; /* 编码格式 */
-
char buf[]; /* 内容 */
-
};
-
len: 使用的长度
-
alloc:申请的内存空间长度,头部以及结束字符不包含
-
flags:编码格式,sds具备动态升级功能,就体现在flags上。当前给的 sdshdr8 len定义为8bit位,最长只能保存256字节,当需要保存更长的字符时,sds会自动升级,使用不同的编码格式,当前支持的有,最大会用64bit位定义length,这也是为什么redis最长能够保存256m 长度的string。
-
#define SDS_TYPE_8 1
-
#define SDS_TYPE_16 2
-
#define SDS_TYPE_32 3
-
#define SDS_TYPE_64 4
-
Buff: 真正保存数据的字符串数组
动态升级
-
f (greedy == 1) {
-
if (newlen < SDS_MAX_PREALLOC) // 1024*1024
-
newlen *= 2;
-
else
-
newlen += SDS_MAX_PREALLOC;
-
}
小于1mb, newlength = length*2
大于1mb, newlength += 2
存储示例
Name存储格式

优缺点
存储空间少(动态升级模式, 头部占用空间少)
获取长度的复杂度为 1
内存预分配,减少字符串添加时间
Intset
结构体定义
-
typedef struct intset {
-
uint32_t encoding; // 编码格式
-
uint32_t length; // 长度
-
int8_t contents[]; // 存储内容
-
} intset;
编码格式:当前数组中数字的编码格式,代表intset中字符的长度,当前支持是哪种类型
-
#define INTSET_ENC_INT16 (sizeof(int16_t))
-
#define INTSET_ENC_INT32 (sizeof(int32_t))
-
#define INTSET_ENC_INT64 (sizeof(int64_t))
长度: 数组长度
Contents: 存储内容
编码升级
字符串编码格式是由sets中最大数字的大小定义,如果新增的数字大于当前的编码格式,将进行编码升级
-
/* Upgrades the intset to a larger encoding and inserts the given integer. */
-
static intset *intsetUpgradeAndAdd(intset *is, int64_t value) {
-
// 当前编码格式
-
uint8_t curenc = intrev32ifbe(is->encoding);
-
// 需要升级的编码格式
-
uint8_t newenc = _intsetValueEncoding(value);
-
// 当前长度
-
int length = intrev32ifbe(is->length);
-
int prepend = value < 0 ? 1 : 0;
-
/* First set new encoding and resize */
-
is->encoding = intrev32ifbe(newenc);
-
// 数组扩容,申请新的内存空间
-
is = intsetResize(is,intrev32ifbe(is->length)+1);
-
/* Upgrade back-to-front so we don’t overwrite values.
-
* Note that the “prepend” variable is used to make sure we have an empt
-
* space at either the beginning or the end of the intset. */
-
// 倒序进行设置新的内容
-
while(length–)
-
_intsetSet(is,length+prepend,_intsetGetEncoded(is,length,curenc));
-
/* Set the value at the beginning or the end. */
-
if (prepend)
-
_intsetSet(is,0,value);
-
else
-
_intsetSet(is,intrev32ifbe(is->length),value);
-
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
-
return is;
-
}
升级过程:
-
设置新的编码格式
-
申请内存空间
-
倒序添加旧的数组内容
-
添加新的值
存储示例
5,10,20

优缺点
Encoding升级机制,节省内存
需要申请连续的内存空间
升序数组,采用二分查找,当数据量大的时候增删消耗时间
Dict(hashtable+链表)
结构体定义
-
struct dict {
-
dictType *type; //hash类型
-
dictEntry **ht_table[2]; //哈希表节点数组
-
unsigned long ht_used[2]; // entry使用个数
-
long rehashidx; /* rehash进度, -1 表示未开始 */
-
/* Keep small vars at end for optimal (minimal) struct padding */
-
int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error) */
-
signed char ht_size_exp[2]; /* hash表大小, exponent of size. (size = 1<<exp) */
-
};
-
typedef struct dictType {
-
uint64_t (*hashFunction)(const void *key);
-
void *(*keyDup)(dict *d, const void *key);
-
void *(*valDup)(dict *d, const void *obj);
-
int (*keyCompare)(dict *d, const void *key1, const void *key2);
-
void (*keyDestructor)(dict *d, void *key);
-
void (*valDestructor)(dict *d, void *obj);
-
int (*expandAllowed)(size_t moreMem, double usedRatio);
-
/* Allow a dictEntry to carry extra caller-defined metadata. The
-
* extra memory is initialized to 0 when a dictEntry is allocated. */
-
size_t (*dictEntryMetadataBytes)(dict *d);
-
} dictType;
-
typedef struct dictEntry {
-
void *key; // 键
-
union { // 值
-
void *val;
-
uint64_t u64;
-
int64_t s64;
-
double d;
-
} v;
-
struct dictEntry *next; /* Next entry in the same hash bucket. */
-
void *metadata[]; /* An arbitrary number of bytes (starting at a
-
* pointer-aligned address) of size as returned
-
* by dictType’s dictEntryMetadataBytes(). */
-
} dictEntry;
图表示例
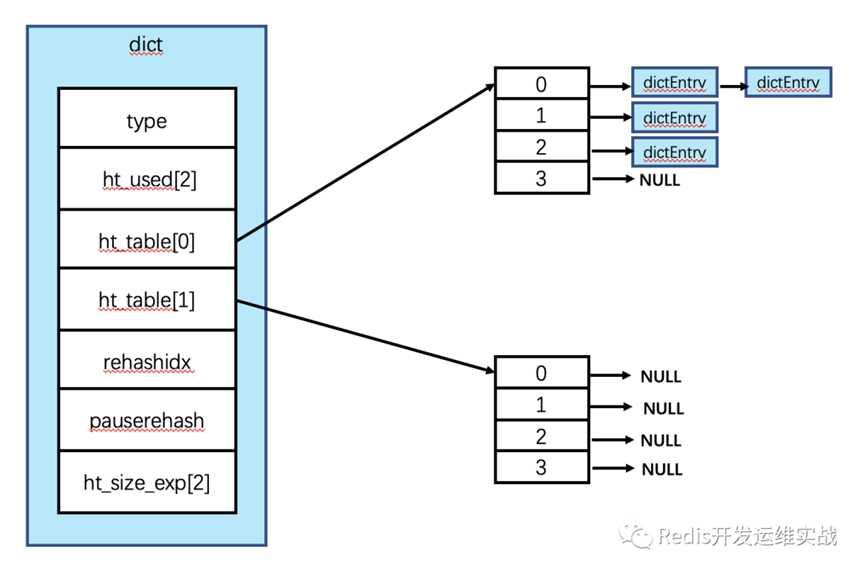
Redis7.0 中对dict类型做了优化,原来的dictht拆分出来,构成了以上新的结构
添加过程

Rehash
在添加或者删除时候,redis会判断当前hash表是否需要扩容或者缩容
优缺点
1:占用内存(存在大量指针)
2:内存碎片
3: 查找速度快
ZipList
结构体定义
-
// 整体ziplist的结构如下
-
// <zlbytes> <zltail> <zllen> <entry> <entry> … <entry> <zlend>
-
// 32bit 总长度 + 32bit 到最后一个zipentry的位移+16bit entry数量
-
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
-
//1字节的结束标识
-
#define ZIPLIST_END_SIZE (sizeof(uint8_t))
-
#define ZIP_END 255 /* Special “end of ziplist” entry. */
-
/* Create a new empty ziplist. */
-
unsigned char *ziplistNew(void) {
-
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE;
-
unsigned char *zl = zmalloc(bytes);
-
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
-
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
-
ZIPLIST_LENGTH(zl) = 0;
-
zl[bytes-1] = ZIP_END;
-
return zl;
-
}
-
/* Each entry in the ziplist is either a string or an integer. */
-
typedef struct {
-
/* When string is used, it is provided with the length (slen). */
-
unsigned char *sval;
-
unsigned int slen;
-
/* When integer is used, ‘sval’ is NULL, and lval holds the value. */
-
long long lval;
-
} ziplistEntry;
-
// entry结构如下
-
// <prevlen from 0 to 253> <encoding> <entry>
-
/* We use this function to receive information about a ziplist entry.
-
* Note that this is not how the data is actually encoded, is just what we
-
* get filled by a function in order to operate more easily. */
-
typedef struct zlentry {
-
unsigned int prevrawlensize; /* Bytes used to encode the previous entry len*/
-
unsigned int prevrawlen; /* Previous entry len. */
-
unsigned int lensize; /* Bytes used to encode this entry type/len.
-
For example strings have a 1, 2 or 5 bytes
-
header. Integers always use a single byte.*/
-
unsigned int len; /* Bytes used to represent the actual entry.
-
For strings this is just the string length
-
while for integers it is 1, 2, 3, 4, 8 or
-
0 (for 4 bit immediate) depending on the
-
number range. */
-
unsigned int headersize; /* prevrawlensize + lensize. */
-
unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on
-
the entry encoding. However for 4 bits
-
immediate integers this can assume a range
-
of values and must be range-checked. */
-
unsigned char *p; /* Pointer to the very start of the entry, that
-
is, this points to prev-entry-len field. */
-
} zlentry;
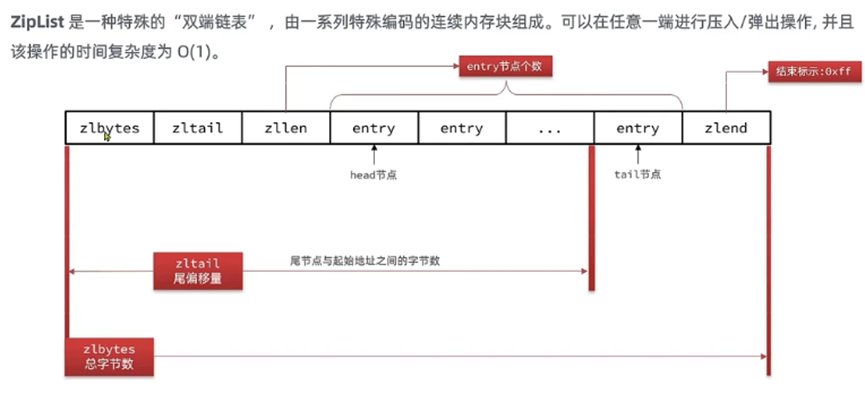
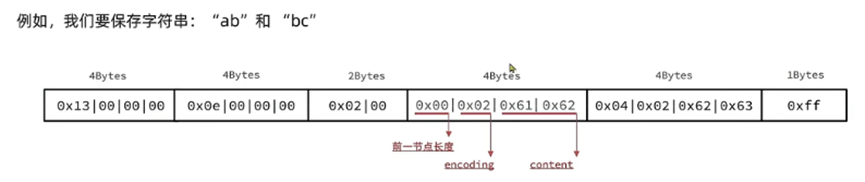
存储示例
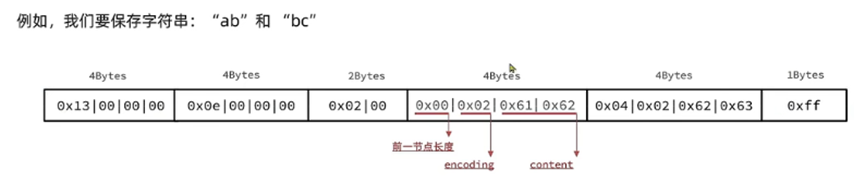
-
* [0f 00 00 00] [0c 00 00 00] [02 00] [00 f3] [02 f6] [ff]
-
* | | | | | |
-
* zlbytes zltail zllen “2” “5” end
优缺点
1: 内存空间占用小,前后插入方便
2: 需要连续内存空间,申请难
3: 数据量大的时候查找困难
4: 因为需要存储上一个节点的长度,存在连锁更新问题
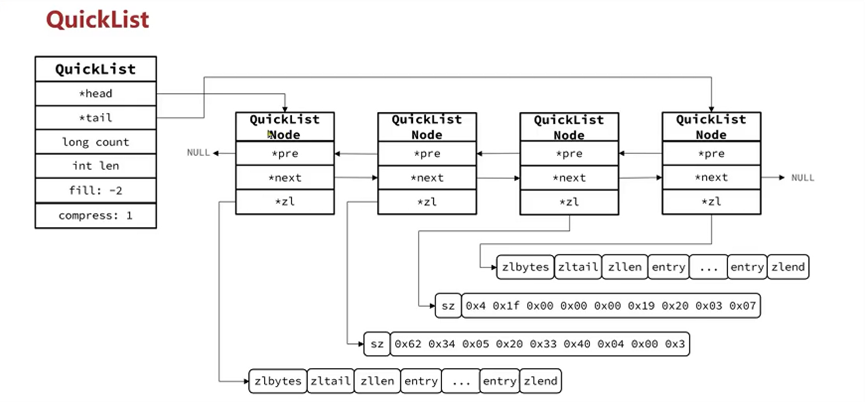
QuickList
结构体定义
-
typedef struct quicklist {
-
quicklistNode *head; // 头节点指针
-
quicklistNode *tail; // 尾结点指针
-
unsigned long count; /* total count of all entries in all listpacks */
-
unsigned long len; /* number of quicklistNodes */
-
signed int fill : QL_FILL_BITS; /* 如果装载因子为正数,那么表示每一个快速链表节点quicklistNode中存储数据节点的个数的上限,
-
* 例如quicklist.fill被设置成10,那么意味着每个quicklisNode的压缩链表中最多只能存储10个数据节点。
-
* 如果装载因子为负数,则标记了每个quicklistNode中压缩链表的最大内存大小,也就是quicklistNode.sz字段的上限。 */
-
unsigned int compress : QL_COMP_BITS; /* 需要压缩的链表长度, 默认为0不要锁*/
-
unsigned int bookmark_count: QL_BM_BITS;
-
quicklistBookmark bookmarks[];
-
} quicklist;
-
typedef struct quicklistNode {
-
struct quicklistNode *prev; // 上一个链表节点
-
struct quicklistNode *next; // 下一个链表节点
-
unsigned char *entry; /* 当前节点的ziplist指针 */
-
size_t sz; /* entry size in bytes */
-
unsigned int count : 16; /* count of items in listpack */
-
unsigned int encoding : 2; /* 是否压缩,1没有,2lzf压缩算法RAW1 or LZF2 */
-
unsigned int container : 2; /* PLAIN1 or PACKED2 */
-
unsigned int recompress : 1; /* was this node previous compressed? */
-
unsigned int attempted_compress : 1; /* node can’t compress; too small */
-
unsigned int dont_compress : 1; /* prevent compression of entry that will be used later */
-
unsigned int extra : 9; /* more bits to steal for future usage */
-
} quicklistNode;
存储示例
优缺点
1:解决了ziplist需要连续内存空间的问题
2:中间插入查找方便,头尾麻烦
3:节省内存占用
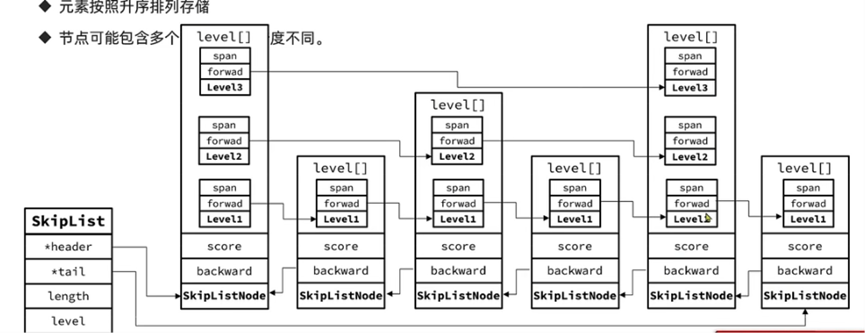
SkipList
结构体定义
-
typedef struct zskiplist {
-
// 头尾节点指针
-
struct zskiplistNode *header, *tail;
-
// 节点数量
-
unsigned long length;
-
// 最大索引层级, 默认是1
-
int level;
-
} zskiplist;
-
typedef struct zskiplistNode {
-
sds ele; // 节点值
-
double score; // 节点分数,排序,查找使用
-
struct zskiplistNode *backward; // 前一个节点指针
-
struct zskiplistLevel {
-
struct zskiplistNode *forward; // 下一个节点指针
-
unsigned long span; // 索引跨度
-
} level[]; // 多级索引数组
-
} zskiplistNode;
存储示例
优缺点
增删改查快
支持排序
占用空间
RedisObject
结构体定义
-
struct redisObject {
-
// 头部就占用了 24字节
-
unsigned type:4; // string, list, set, zset, hash
-
unsigned encoding:4; // 共有 11 种编码
-
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
-
* LFU data (least significant 8 bits frequency
-
* and most significant 16 bits access time). */
-
int refcount; // 引用技术器,如果是 0 则表示没有引用
-
void *ptr; // 指针指向任意类型测得值
-
};
Redis中所有的结构体都是用redisObject包装,固定存储开销,ptr指向类型值
Types: 五种
-
#define OBJ_STRING 0 /* String object. */
-
#define OBJ_LIST 1 /* List object. */
-
#define OBJ_SET 2 /* Set object. */
-
#define OBJ_ZSET 3 /* Sorted set object. */
-
#define OBJ_HASH 4 /* Hash object. */
Encoding 共支持11种编码格式
-
#define OBJ_ENCODING_RAW 0 /* Raw representation */
-
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
-
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
-
#define OBJ_ENCODING_ZIPMAP 3 /* No longer used: old hash encoding. */
-
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
-
#define OBJ_ENCODING_ZIPLIST 5 /* No longer used: old list/hash/zset encoding. */
-
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
-
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
-
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
-
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of listpacks */
-
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
-
#define OBJ_ENCODING_LISTPACK 11 /* Encoded as a listpack */















 7367
7367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









