









前端操作偶尔超时,发现一个查询很慢,格式如下:
select * from a
inner join b on b.id=a.bid
inner join c on c.id=a.cid
where a.way=1 and a.num='10000'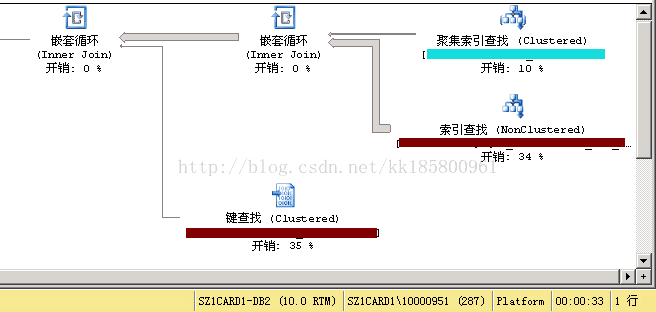
a 表为深红色,返回240万行数据。执行了33秒。最终结果返回一条记录!可以看到其行数估计非常不准。
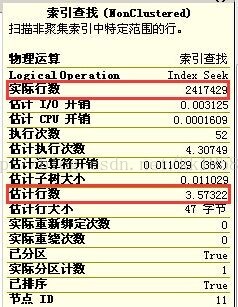
看看该索引统计信息最后更新时间,是2014-12更新的。
更新整个表的统计信息:UPDATE STATISTICS DBO.TableName
更新之后再执行,结果还是一样,看来统计信息没有错。
可能大家会想到的,是先这样执行过滤。即时这样执行,优化引擎选择还是一样的。
select *
from (select * from a where way=1 and num='10000')a
inner join b on b.id=a.bid
inner join c on c.id=a.cid再看上图,深红色的为a表,a表先和b表连接,生成大量数据,b表再键查找过滤条件。
现在的优化目标是: a表是先过滤条件(返回只有1行记录),再与b进行关联。
有3种处理方案:
1 . 强制使用嵌套(哈希、合并)连接
2. 使用左连接
3. 更改索引
测试:
1 . 强制使用嵌套(哈希、合并)连接
在测试这种方案时,是用了另一个测试环境,不过执行计划一样。
可以使用loop、hash、merge 连接。hash、merge消耗内存较多,所以使用了loop。
select * from a
inner loop join b on b.id=a.bid
inner join c on c.id=a.cid
where a.way=1 and a.num='10000'2. 使用左连接。因为只有一条记录,不改变查询结果,可以用。
select * from a
left join b on b.id=a.bid
left join c on c.id=a.cid
where a.way=1 and a.num='10000'3. 更改索引
当前a表的索引为 ix_a(id,bid) , ix_a_num(num)
连接时,肯定首先连接的索引 ix_a(id,bid),该索引并未包括查询条件中的列。
可以重建新的索引如:ix_a(id,bid,num,way)
最后使用了第二种方法。前2种方法执行都3秒以下或不到一秒。第3种方法要改索引,就不必了。
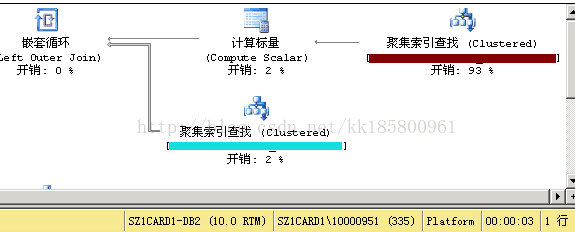
执行结果如下图:深红色的a表可以先过滤条件再关联其他表了!















 315
315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









