







①、最大二叉树
给定一个不重复的整数数组
nums。 最大二叉树 可以用下面的算法从nums递归地构建:
- 创建一个根节点,其值为
nums中的最大值。- 递归地在最大值 左边 的 子数组前缀上 构建左子树。
- 递归地在最大值 右边 的 子数组后缀上 构建右子树。
返回
nums构建的 最大二叉树 。
事例:
输入:nums = [3,2,1,6,0,5] 输出:[6,3,5,null,2,0,null,null,1] 解释:递归调用如下所示: - [3,2,1,6,0,5] 中的最大值是 6 ,左边部分是 [3,2,1] ,右边部分是 [0,5] 。 - [3,2,1] 中的最大值是 3 ,左边部分是 [] ,右边部分是 [2,1] 。 - 空数组,无子节点。 - [2,1] 中的最大值是 2 ,左边部分是 [] ,右边部分是 [1] 。 - 空数组,无子节点。 - 只有一个元素,所以子节点是一个值为 1 的节点。 - [0,5] 中的最大值是 5 ,左边部分是 [0] ,右边部分是 [] 。 - 只有一个元素,所以子节点是一个值为 0 的节点。 - 空数组,无子节点。
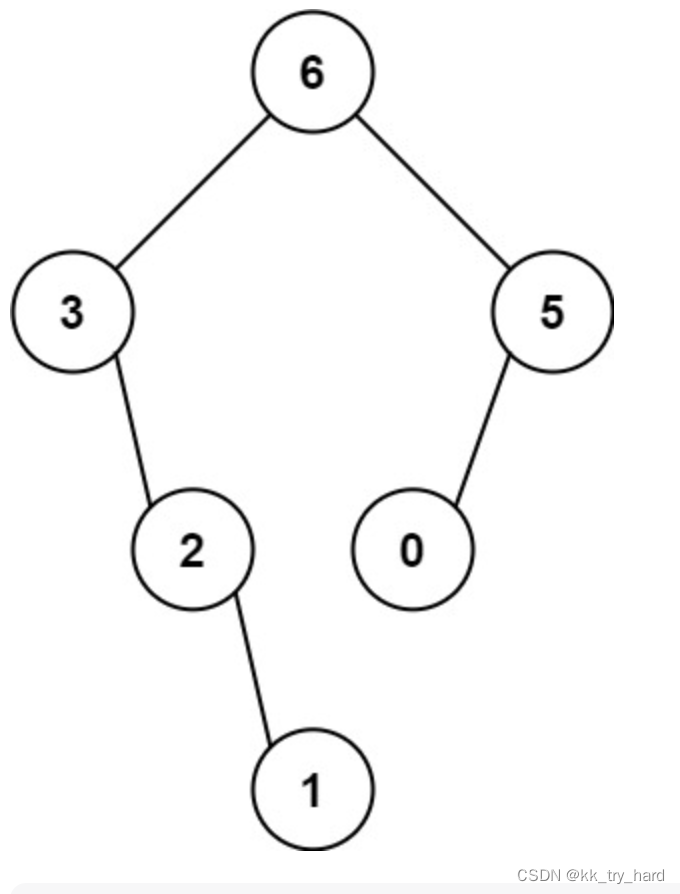
思路:
这道题以数组区间寻最大值来切割数组,然后按照切割后的左右顺序作为左右子树。与之前的后序与中序遍历构造二叉树、前序与中序遍历构造二叉树做法一致。该题可以在数组区间获得最大值,然后通过索引将数组切割,递归左部分作为左子树,递归右部分作为右子树。
代码:
Map<Integer,Integer> map = new HashMap<>();
public TreeNode constructMaximumBinaryTree(int[] nums) {
for(int i = 0;i < nums.length;i++){
map.put(nums[i],i);
}
return findMaximumBinaryNode(nums,0,nums.length);
}
public TreeNode findMaximumBinaryNode(int[] nums,int start,int end){
//使用左闭右开的原则
if(start >= end){
//没有结点
return null;
}
int max = findMaximum(nums,start,end);
int index = map.get(max);
//构造结点
TreeNode root = new TreeNode(max);
//递归构造
root.left = findMaximumBinaryNode(nums,start,index);
root.right = findMaximumBinaryNode(nums,index + 1,end);
return root;
}
public int findMaximum(int[] nums,int left,int right){
int max = Integer.MIN_VALUE;
for(int i = left;i < right;i++){
if(max < nums[i]){
max = nums[i];
}
}
return max;
}②、合并二叉树
给你两棵二叉树:
root1和root2。想象一下,当你将其中一棵覆盖到另一棵之上时,两棵树上的一些节点将会重叠(而另一些不会)。你需要将这两棵树合并成一棵新二叉树。合并的规则是:如果两个节点重叠,那么将这两个节点的值相加作为合并后节点的新值;否则,不为 null 的节点将直接作为新二叉树的节点。
返回合并后的二叉树。
注意: 合并过程必须从两个树的根节点开始。
事例:
输入:root1 = [1,3,2,5], root2 = [2,1,3,null,4,null,7] 输出:[3,4,5,5,4,null,7]
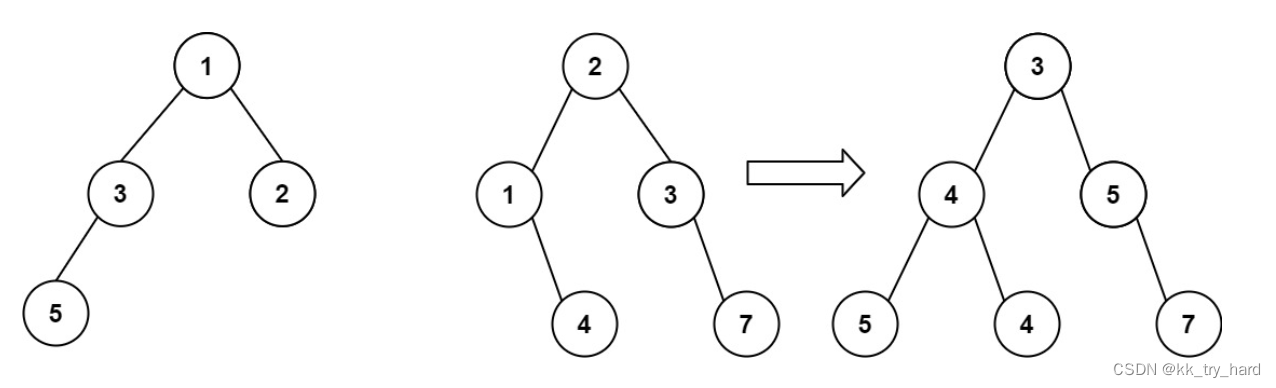
思路:
将两颗树依次按照前序遍历,依次构造两结点值和的结点然后返回。
递归终止条件:当两个结点都为null时,返回null,当一个为空时,返回不为空的结点。
递归返回结果为TreeNode结点,方便利用返回结果构造二叉树 如:root.left = function(root1.left,root2.left)
代码:
public TreeNode mergeTrees(TreeNode root1, TreeNode root2) {
return merge(root1,root2);
}
public TreeNode merge(TreeNode root1,TreeNode root2){
if(root1 == null && root2 == null) return null;
if(root1 == null) return root2;
if(root2 == null) return root1;
TreeNode tmp = new TreeNode(root1.val + root2.val);
tmp.left = merge(root1.left,root2.left);
tmp.right = merge(root1.right,root2.right);
return tmp;
}③、二叉搜索树中的搜索
给定二叉搜索树(BST)的根节点
root和一个整数值val。你需要在 BST 中找到节点值等于
val的节点。 返回以该节点为根的子树。 如果节点不存在,则返回null。
事例:
输入:root = [4,2,7,1,3], val = 2 输出:[2,1,3]
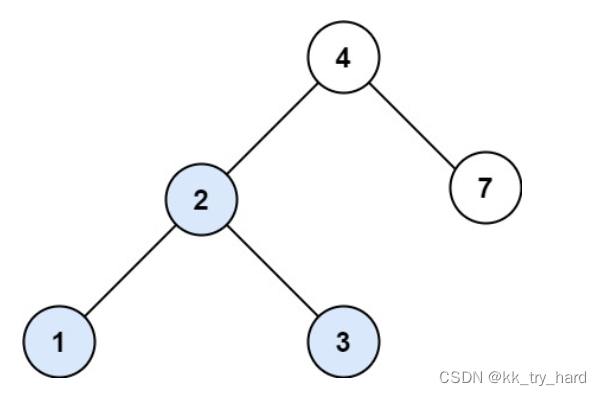
思路:
二叉搜索树的定义为:树中的所有结点都满足左孩子结点的值小于结点的值,右孩子结点的值大于结点的值。
简单来看,二叉搜索树的中序遍历(从上到下投影到平面),是递增的。
搜索过程可以看成:若当前值小于目标值,则前往右子树搜索,若当前值大于目标值则前往左子树搜索,直到所搜到为止。
代码:
public TreeNode searchBST(TreeNode root, int val) {
if(root == null) return null;
int num = root.val;
if(num < val) root = searchBST(root.right,val);
if(num > val) root = searchBST(root.left,val);
return root;
}④、验证二叉搜索树
给你一个二叉树的根节点
root,判断其是否是一个有效的二叉搜索树。有效 二叉搜索树定义如下:
- 节点的左子树只包含 小于 当前节点的数。
- 节点的右子树只包含 大于 当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
事例:
输入:root = [2,1,3] 输出:true
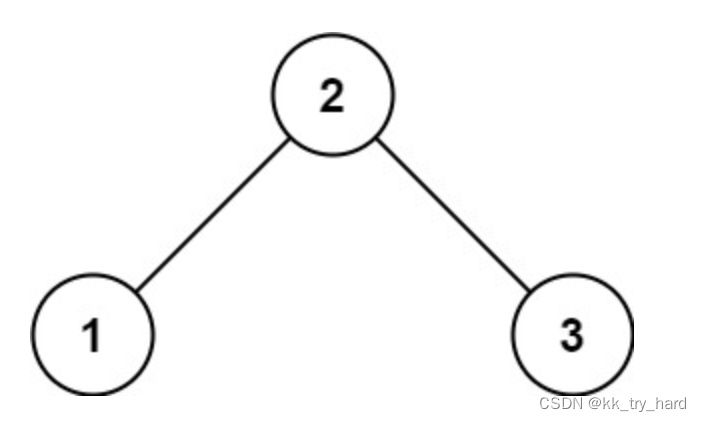
思路:
二叉搜索树的中序遍历是递增的,故我们用一个全局变量记录前一个结点,模仿中序遍历,在中间序比较前一个结点的值和当前结点的值,若当前结点的值小于等于前一个结点的值,则说明当前结点所在的子树不是二叉搜索树,若是二叉搜索树,则遍历左子树和右子树,只有左右子树同为二叉搜索树,整颗树才是二叉搜索树。
代码:
private TreeNode pre = null;
public boolean isValidBST(TreeNode root) {
return inorder(root);
}
public boolean inorder(TreeNode root){
if(root == null)return true;
boolean left = inorder(root.left); //左
if(left == false) return left;
//中间判断
if(pre != null && pre.val >= root.val) return false;
else pre = root; //记录前一个结点
boolean right = inorder(root.right); //右
if(!right) return right;
return left && right;
}














 1540
1540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









