







第一种情况依赖于WEB服务器和操作系统是否支持,但是在做WEB应用的时候应该避免这种做法。
第二种情况的时候必须采用编码后传参,接受时解码的方式完成参数值的获取。
参数可以通过表单提交,浏览器地址栏输入,URL链接点击。
下面的这些测试是在tomcat中进行的
1,先来看通过表单post提交的方式。
html文件如下:
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=GB2312" />
<title>test encoding</title>
</head>
<body>
<form action="encode/enctest1.jsp" method="post">
<input type="text" name="param" size="50"><br>
<input type="submit" value="submit">
</form>
<br>
GB2312页面
</body>
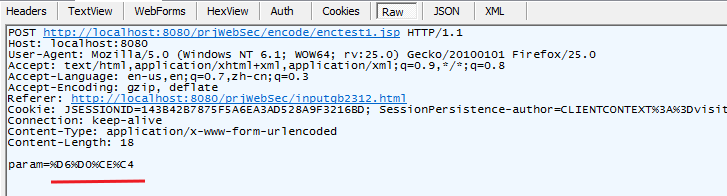
</html>通过Fiddler抓取的提交内容如下图:param=%D6%D0%CE%C4,
System.out.println(java.net.URLEncoder.encode("中文", "gb2312"));得到的结果为 %D6%D0%CE%C4
可以判断浏览器将参数编码为GB2312
在后端的代码中通过下面的代码能够得到正确的数据
request.setCharacterEncoding("GB2312");
String param = request.getParameter("param");
注意setCharacterEncoding必须在从request取数据之前执行。
如果不通过setCharacterEncoding指定编码,字符流默认以ISO-8859-1的编码,需要按照下面的方式转换。
String gbparam = new String(request.getParameter("param").getBytes("ISO-8859-1"),"GB2312");
meta的设置为<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
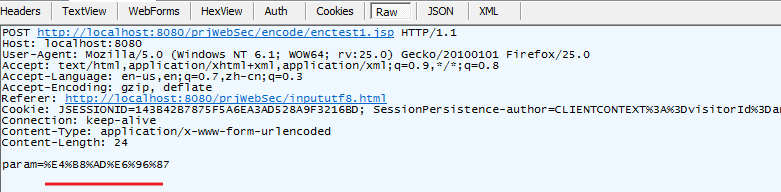
通过Fiddler抓取的提交内容如下:param=%E4%B8%AD%E6%96%87,
System.out.println(java.net.URLEncoder.encode("中文", "utf-8"));得到的结果为 %E4%B8%AD%E6%96%87
可以判断浏览器将参数编码为utf-8
在后端的代码中通过下面的代码能够得到正确的数据
request.setCharacterEncoding("utf-8");
String param = request.getParameter("param");
2,在地址栏中直接输入http://localhost:8080/prjWebSec/encode/enctest1.jsp?param=中文
通过Fiddler抓取的提交内容如下,在firefox和chrome都是用的utf-8编码。[这个可能和OS以及服务器的设置有关,在电脑上运行System.out.println(System.getProperty("file.encoding"))得到的是utf8]
如下可以看到http://localhost:8080/prjWebSec/encode/enctest1.jsp?param=%E4%B8%AD%E6%96%87

在我的测试中,如果是jsp文件post提交,不管meta的content设置的是gb2312还是utf-8,
提交的参数都是以utf-8编码的。[这个可能和OS以及服务器的设置有关,通过在电脑上运行System.out.println(System.getProperty("file.encoding"))得到的是utf8]
3,在link中对参数进行encode如下
<a href="encode/enctest2.jsp?param=<%=URLEncoder.encode("中文","utf-8")%>">中文encoded</a><br>
浏览器中源码如下:中文被utf-8编码
<a href="encode/enctest2.jsp?param=%E4%B8%AD%E6%96%87">中文encoded</a><br>
点击链接后浏览器地址栏变成如下,浏览器显示URL在地址栏中的时候做了一次自动解码。 http://localhost:8080/prjWebSec/encode/enctest2.jsp?param=中文,
提交和传输到服务器端的是%E4%B8%AD%E6%96%87。
后端取到参数后和post的处理原则一致。
4,在link中对参数进行两次encode如下
<a href="encode/enctest2.jsp?param=<%=URLEncoder.encode
(URLEncoder.encode("中文","utf-8"),"UTF-8")%>">
浏览器中源码如下:第一次中文被utf-8编码成%E4%B8%AD%E6%96%87,第二次将%再编码成%25,最后的结果如下
<a href="encode/enctest2.jsp?param=%25E4%25B8%25AD%25E6%2596%2587">中文double encoded</a>
点击链接后浏览器地址栏和源码中的形式一致,浏览器只会对%xx自动解码,对%xxxx不会自动解码。
http://localhost:8080/prjWebSec/encode/enctest2.jsp?param=%25E4%25B8%25AD%25E6%2596%2587
后端取到参数后需要做一次utf-8的decode,request的编码则无所谓,通过request.getParameter("param")
得到的值总是%E4%B8%AD%E6%96%87,下面的代码能得到"中文"这个值.
String decodedparam = URLDecoder.decode(request.getParameter("param"),"UTF-8");
对于编码的处理,如果处理多字节的字符,一般来讲最好将提交和接收端都设置成utf-8.
接收端编码设置要在从request拿数据之前。在链接中一般也没有必要对参数做两次encoding。
参数提交和读取的过程应该是浏览器对参数进行编码,
编码后的参数传给web服务器,到达服务器后,服务器会将得到的内容以一种编码来表示。
以tomcat为例,这时候发生了(UTF-8 -->ISO-8859-1),这时候参数值是ISO-8859-1表示的。
在request.setCharacterEncoding("utf-8");
然后request.getParameter("param")的时候又转回了utf-8。
如果直接通过stream的方式取到字节流,内容如下
112 97 114 97 109 61 37 69 52 37 66 56 37 65 68 37 69 54 37 57 54 37 56 55
正好对应 param=%E4%B8%AD%E6%96%87,所以发生解码的时候是在 request.getParameter的时候。
如果在这之前setCharacterEncoding设置了编码,则用设置的编码来解码。否则用servlet服务器的
默认编码来解码。取字节流的代码如下
ServletInputStream input = request.getInputStream();
System.out.println(input);
byte[] readBytes = new byte[10];
while (true) {
if (input.available() >= 10) {
input.read(readBytes);
for (byte b : readBytes) {
System.out.print(b + " ");
}
} else {
int readByte = 0;
while((readByte = input.read()) !=-1){
System.out.print(readByte + " ");
}
break;
}
}<filter>
<filter-name>encodingFilter</filter-name>
<filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>UTF8</param-value>
</init-param>
<init-param>
<param-name>forceEncoding</param-name>
<param-value>true</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>encodingFilter</filter-name>
<url-pattern>*.html</url-pattern>
</filter-mapping>
<filter-mapping>
<filter-name>encodingFilter</filter-name>
<url-pattern>*.jsp</url-pattern>
</filter-mapping> ISO-8859-1是单字节编码,它只是将字节流一个字节一个字节的读入,然后转成ISO-8859-1编码的字符,
编码范围0-255(x00-xFF),和其他所有编码的单个字节的编码范围一样,
因为是单字节的操作,所以不会对字节流的内容做改变。
如果将一个多字节编码的文件以ISO-8859-1读入,转成了ISO-8859-1的字符串,
然后又以ISO-8859-1编码输出成另外一个文件,保存的文件内容(二进制)并没有变化。
ASCII也是单字节的编码,但是由于其编码范围0-127不能包含其他编码的单字节,超过127的
字节被ascii转成了?(x3F)字符,字节的内容就变成了x3F。
多字节之间如果用错,则会发生错位,如GB2312的每个汉字用两个字节表示,utf-8用3个字节表示。
如果以GB2312去读取一个utf8编码的文件,以"中文"的utf-8为例(%E4%B8%AD%E6%96%87),
GB2312会将%E4%B8作为一个字符,可能在gb231编码中是别的字符,这时候字节内容没有被改变, 将%AD%E6作为一个字符,可能找不到对应的字符,如果找不到,则变成了?字符,字节内容也变了,%96%87同理。
%E4%B8%AD%E6%96%87对应到gb2312为"涓??".再保存则变成了%E4%B8%3F%3F了。
下面的代码不会"破坏"文件的内容。
public static void ioiso88591file(String fileName,String outfileName) throws Exception {
File file = new File(fileName);
FileInputStream fis = new FileInputStream(file);
InputStreamReader fr = new InputStreamReader(fis,"iso-8859-1");
BufferedReader br = new BufferedReader(fr);
File outfile = new File(outfileName);
FileOutputStream fos = new FileOutputStream(outfile);
OutputStreamWriter ofr = new OutputStreamWriter(fos,"iso-8859-1");
BufferedWriter bwr = new BufferedWriter(ofr);
String line;
while ((line=br.readLine()) != null){
System.out.println(line);
bwr.write(line);
}
br.close();
fr.close();
fis.close();
bwr.close();
ofr.close();
fos.close();
}gb2312.txt和gb2312iso88591.txt的二进制内容也是一模一样的。
ioiso88591file("C:/D/charset/utf8.txt","C:/D/charset/utf8iso88591.txt");
ioiso88591file("C:/D/charset/gb2312.txt","C:/D/charset/gb2312iso88591.txt");















 4398
4398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









