






在《层次数据的存储与访问(一)》中,介绍了两种使用比较频繁的层次数据的存储与访问模式。这两种方法虽然可以解决大多数层次数据的处理问题,但往往不适合存取效率要求高的场合。本篇继续探讨其它两种存储访问模式:编码模式与改进的前序遍历模式。
三、编码模式:
使用特殊编码方法,将层次数据平面化到数据库表,而在节点的标识字段编码中包含父节点的层次信息,即编码模式。
编码也可以有多种选择,当然最简便的是位编码了,在下面的讨论中,先了解一下编码方法。这里使用32位整数来编码,因为整数有一个符号位,所以可用的位数只有31位,即31(3+4+4+4+4+4+4+4),这样可以表示8层,第一层用3位表示,可以表示8个节点,第二层及以下,每层用4位表示,分别可以表示16个节点。实际应用中根据需要可自由设定。
首先观察下面的一组数据。
A: 101 0000 0000 0000 0000 0000 0000 0000 (1342177280)
B: 101 0001 0000 0000 0000 0000 0000 0000 (1358954496)
C: 101 0010 0000 0000 0000 0000 0000 0000 (1375731712)
D: 101 0010 0001 0000 0000 0000 0000 0000 (1376780288)
很容易看出:
1、B、C、D都是A的子节点
2、A是B、C的父节点,C是D的父节点
3、B是A的第一个子节点,C是A的第二个子节点
4、A属于第二层,B、C属于第二层,D属于第三层
现在先给出相关编码公式,可对照研究,并理解之。
1、 编码的总位数:
N=N1+N2+N3+…+Ni 其中Ni表示第i层的位数
例:31=3+4+4+4+4+4+4+4
2、 编码方法:
节点的编码=父节点的编码+2^(N-(N1+N2+…+Ni))*j
其中i表示当前的层次,j表示当前层的第j个分类
例:上面D的编码
13757317112+2^(31-(3+4+4))*1=1376780288
3、 层的特征码:2^N-2^(N-(N1+N2+…+Ni))
对于任何一个节点的编码,同父节点的特征码做“与运算”,其结果为父节点的编码
例,求B节点的父节点:
先求B节点上层的特征码:2^31-2^(31-3)=1879048192
B节点的编码(1358954496)101 0001 0000 0000 0000 0000 0000 0000
与
上层的特征码(1879048192)111 0000 0000 0000 0000 0000 0000 0000
=
父节点的编码 (1342177280) 101 0000 0000 0000 0000 0000 0000 0000
4、 节点的子节点的最大值:2^(N-(N1+N2+…+Ni))-1 同节点编码作“或运算”
例,求D节点下子节点的最大值
1376780288 | 2^(31-(3+4+4))-1=1377828863
现在了解了编码方法,那么回到上篇中提出的问题,形成的数据库表如下图所示。(table1)
|
Id |
Title |
Layer |
|
001 0000 0000 0000 0000 0000 0000 0000 -268435456 |
电器 |
1 |
|
010 0000 0000 0000 0000 0000 0000 0000 -536870912 |
服装 |
1 |
|
001 0001 0000 0000 0000 0000 0000 0000 -285212672 |
电视 |
2 |
|
001 0010 0000 0000 0000 0000 0000 0000 -301989888 |
冰箱 |
2 |
|
001 0011 0000 0000 0000 0000 0000 0000 -318767104 |
空调 |
2 |
|
010 0001 0000 0000 0000 0000 0000 0000 -553648128 |
成人 |
2 |
|
010 0010 0000 0000 0000 0000 0000 0000 -570425344 |
儿童 |
2 |
|
001 0011 0001 0000 0000 0000 0000 0000 -319815680 |
柜式 |
3 |
|
001 0011 0010 0000 0000 0000 0000 0000 -320864256 |
窗式 |
3 |
|
010 0001 0001 0000 0000 0000 0000 0000 -554696704 |
上衣 |
3 |
在表中ID字段实际是整型数据,表中Layer字段也不是必须的,增加可方便有些查询。数据操作举例:
1、 在“成人”节点下,增加新的子节点“长裤”:
Insert into table1(Id,Title,Layer) values(2^(31-(3+4+4))*2+553648128,”长裤”,3)
2、 删除“服装”节点:
A、 求“服装”节点的下级子节点最大值:
(2^(31-3)-1)| 36870912=805306367
B、 删除“服装”节点及其下子节点:
Delete from table1 where d>=536870912 And Id<=805306367
3、 获得“柜式”节点的路径:
第一层特征码:2^31-2^(31-3)=1879048192
第二层特征码:2^31-2^(31-(3+4))=2130706432
第三层特征码:2^31-2^(31-(3+4+4))=2146435072
Select Id & 1879048192,Id & 2130706432,Id & 2146435072 from table1 where Id=319815680
4、 求“电器”节点的所有子节点:
Select * from table1 where Id>268435456 and Id<=(268435456 | (2^(31-3))-1)
遍历及打印树,上篇已给了几个例子,就不写了。
5、 求“电器”节点下的直接子节点:
Select * from table1 where Id>268435456 and Id<=(268435456 | (2^(31-3))-1) and Layer=2
使用编码模式,只要理解了编码的方法以后,也不难理解,其查询算法丰富,在数据库操作中不需要使用“递归”,效率很高。其次缺点是,由于层次的限制,无法做到无限级分类。
四、改进的前序遍历模式:
所谓改进的前序遍历模式,是按照前序遍历的次序,沿着层次树的边沿遍历整个树,给每个节点按次序赋予左值和右值,将节点关联起来,从而把树平面化。
请仔细观察是如何遍历树的以及怎样各节点编号的。
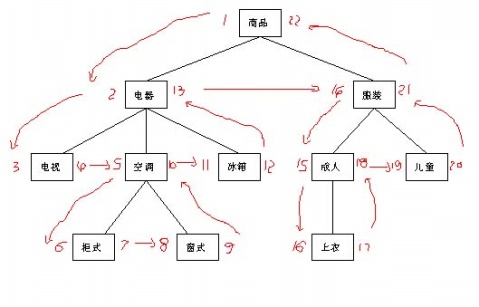
注意箭头的顺序,是沿着树的边缘漫游的。上面得到的数字称为节点的左值与右值,这些数值表达了节点的顺序关系,通过这些值,可以观察得出面的一些规律:
1、 子节点的左值总是大于父节点的左值,而小于父节点的右值。
如图中,“空调”(5-10)的左值都大于5并且小于10.
2、 子节点的右值总是小于父节点的右值。
3、 节点的子节点总数=(节点的右值-节点的左值-1)/2
如“服装”节点的子节点个数为(21-14-1)/2=3
4、 节点的祖先(包括父节点)的左值都小于子节点,右值都大于子节点右值
如“冰箱”(11-12),其祖先“电器”(2-13),“商品”(1-22)。
以上规律都可用于数据库表的操作,图中的节点存储到数据库表中如下:
|
Title |
Lft |
Rgt |
|
商品 |
1 |
22 |
|
电器 |
2 |
13 |
|
服装 |
14 |
21 |
|
电视 |
3 |
4 |
|
空调 |
5 |
10 |
|
冰箱 |
11 |
12 |
|
成人 |
15 |
18 |
|
儿童 |
19 |
20 |
|
柜式 |
6 |
7 |
|
窗式 |
8 |
9 |
|
上衣 |
16 |
17 |
实际应用时,表中应增加一个标识字段,另外增加一个表示层数的字段亦可。
数据操作举例:
1、 获取“成人”节点的路径:
Select Title from table1 where Lft<15 And Rgt>18
2、 获取“商品”下所有子节点:
Select Title from table1 where lft Between 1 and 22 order by Lft Asc
遍历并打印略
3、 在“电视”节点下,添加一个子节点“液晶”:
在“电视”(3-4)下增加子节点,意味着先要腾出一个空间放置新节点,“电视”节点的右值要加2,“电视”节点的右边的所有节点的左值与右值都需要加2,也就是说所有左值和右值大于3的节点都应加上2
A, 腾空间:
Update table1 set Lft=Lft+2 where Lft>3
Update table1 set Rgt=Rgt+2 where Rgt>3
B,插入新节点:
Insert into table1(Title,Lft,Rgt) values(“液晶4,5)
4、 删除“空调”节点:
删除操作先删除节点及其子节点,然后节点右边的节点的,左值与右值,都得减去删除节点个数的2倍。
A、 删除:
Delete from table1 where Lft>=5 and Rgt<10
B、 清空间:
Update table1 set Lft=Lft-(10-5+1) where Lft>9
Update table1 set Rgt=Rgt-(10-5+1) where Lft>9
当熟悉了节点的左值与右值以后,改进的前序遍历方法很好理解,可以看到查询操作的效率非常高,也能很容易的实现无限级分类,个人认为此乃一个不错的层次数据存取解决办法,自己在项目中也多采用此方法,不过,在插入新数据时,表数据需要做一次更新,如果数据量大,插入效率就比较低了,所以需要频率插入和删除的应用,不建议使用。
分两次《层次数据的存储与访问》算是告一段落了,文中所述的四种方法,各有其使用场合,并没有完美的解决方案,总的来看后两种模式要好一些。具体使用哪一种,就看自己的需要了。
另外,近来没时间,文中大部分代码,只是举例,并未调试,以能看懂为目的。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









