







💗博主介绍:✌全网粉丝1W+,CSDN作者、博客专家、全栈领域优质创作者,博客之星、平台优质作者、专注于Java、小程序技术领域和毕业项目实战✌💗
🌟文末获取源码+数据库🌟
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
详细视频演示:
请联系我获取更详细的演示视频
具体实现截图:
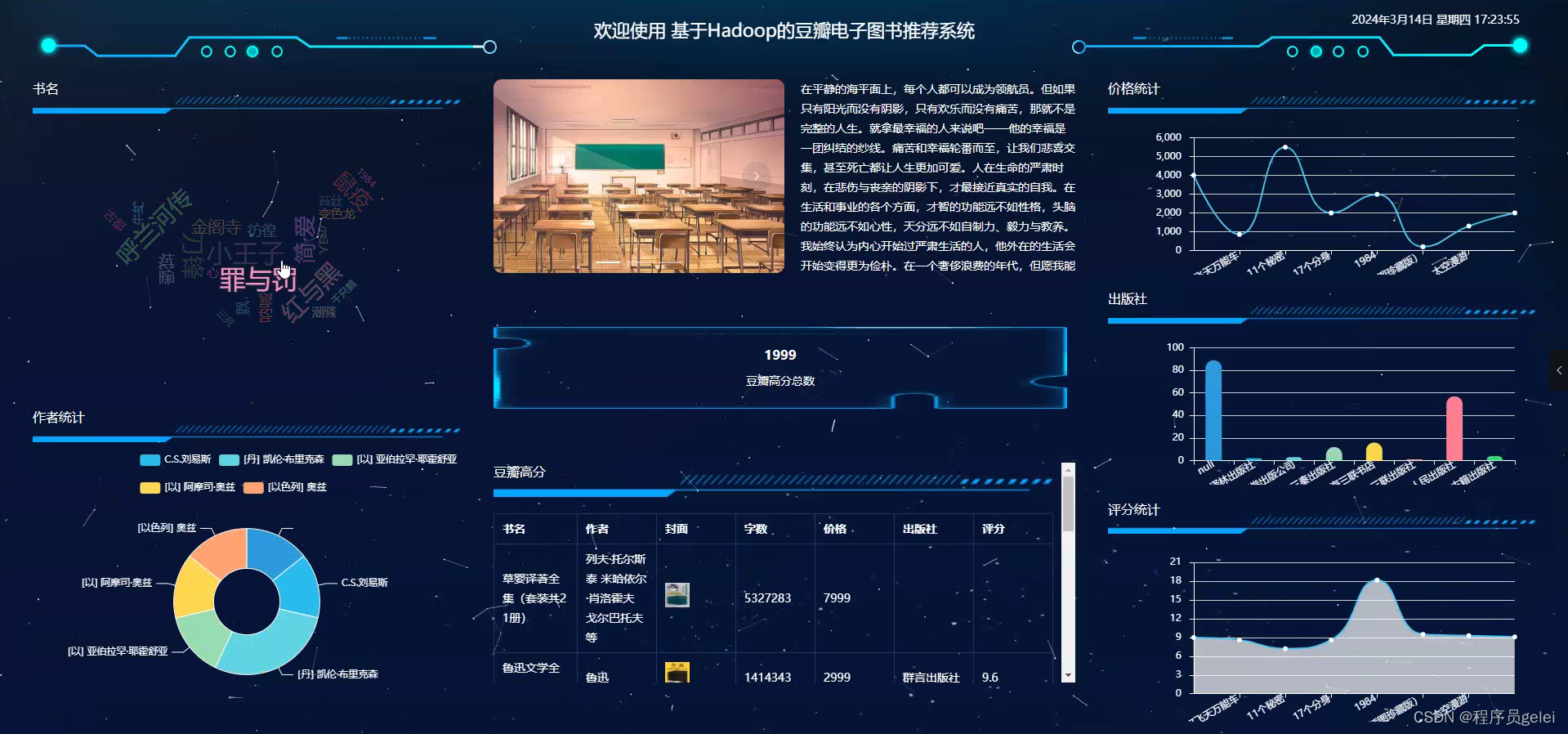
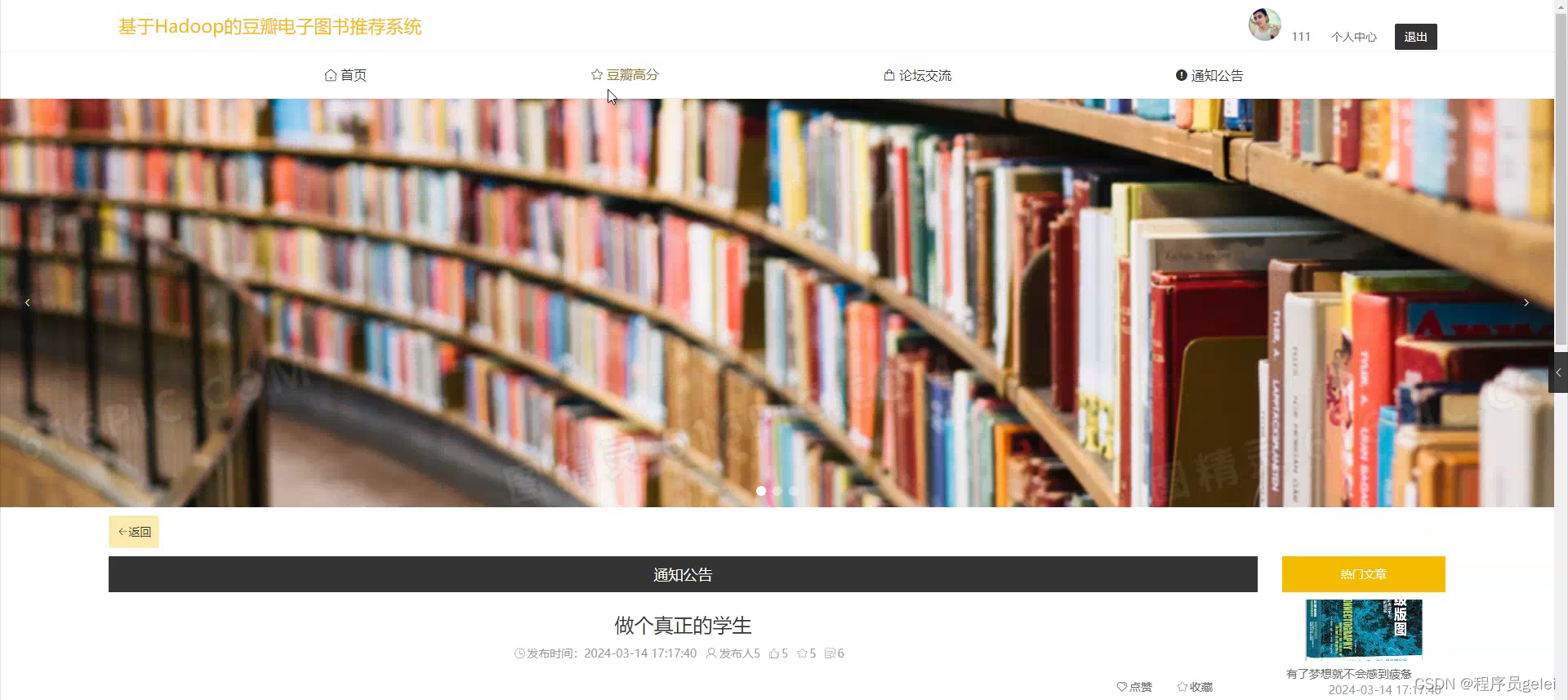
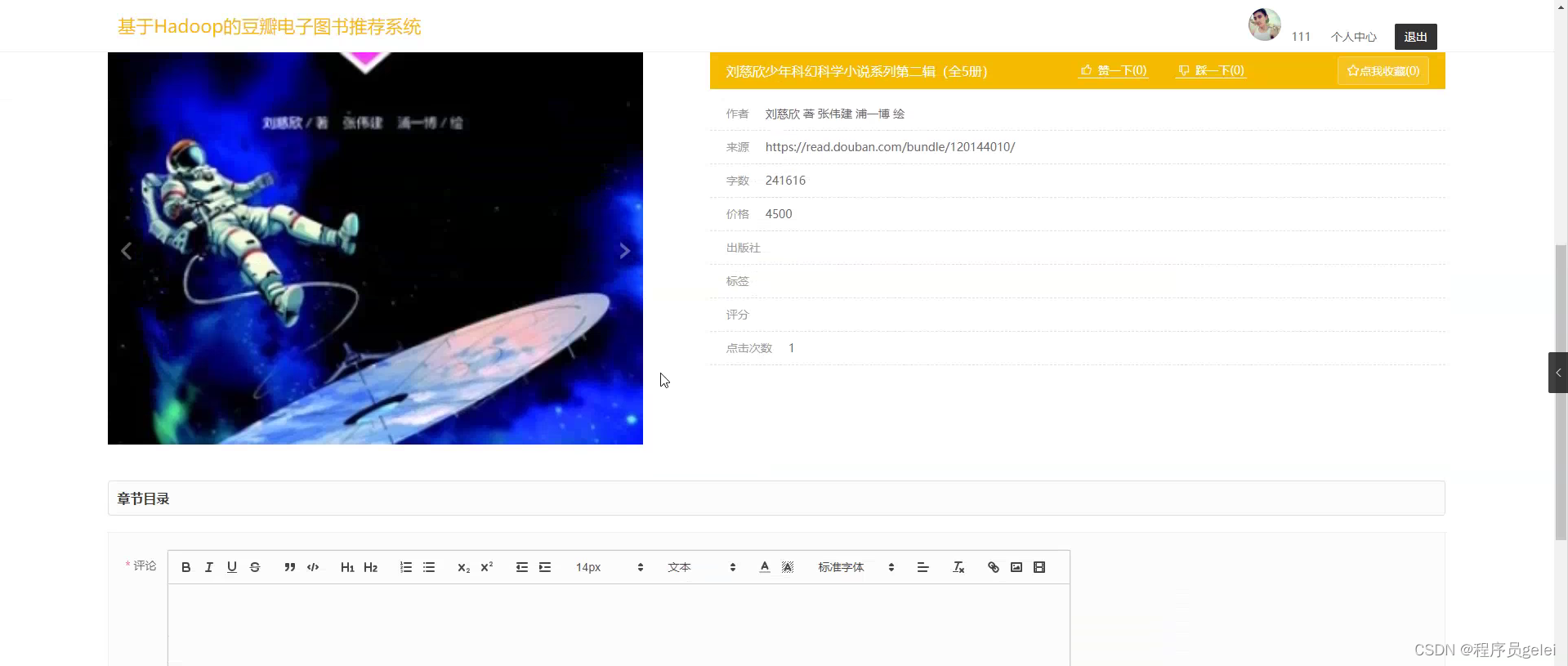
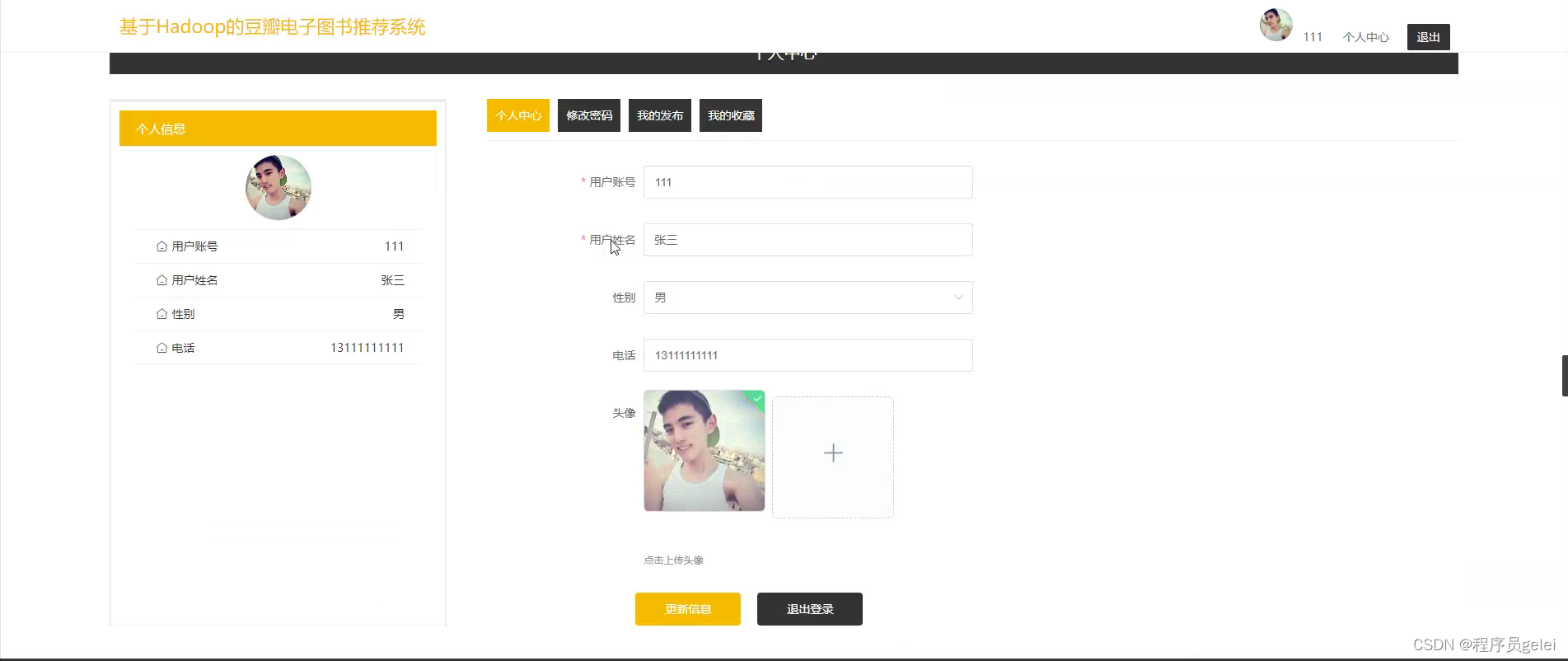
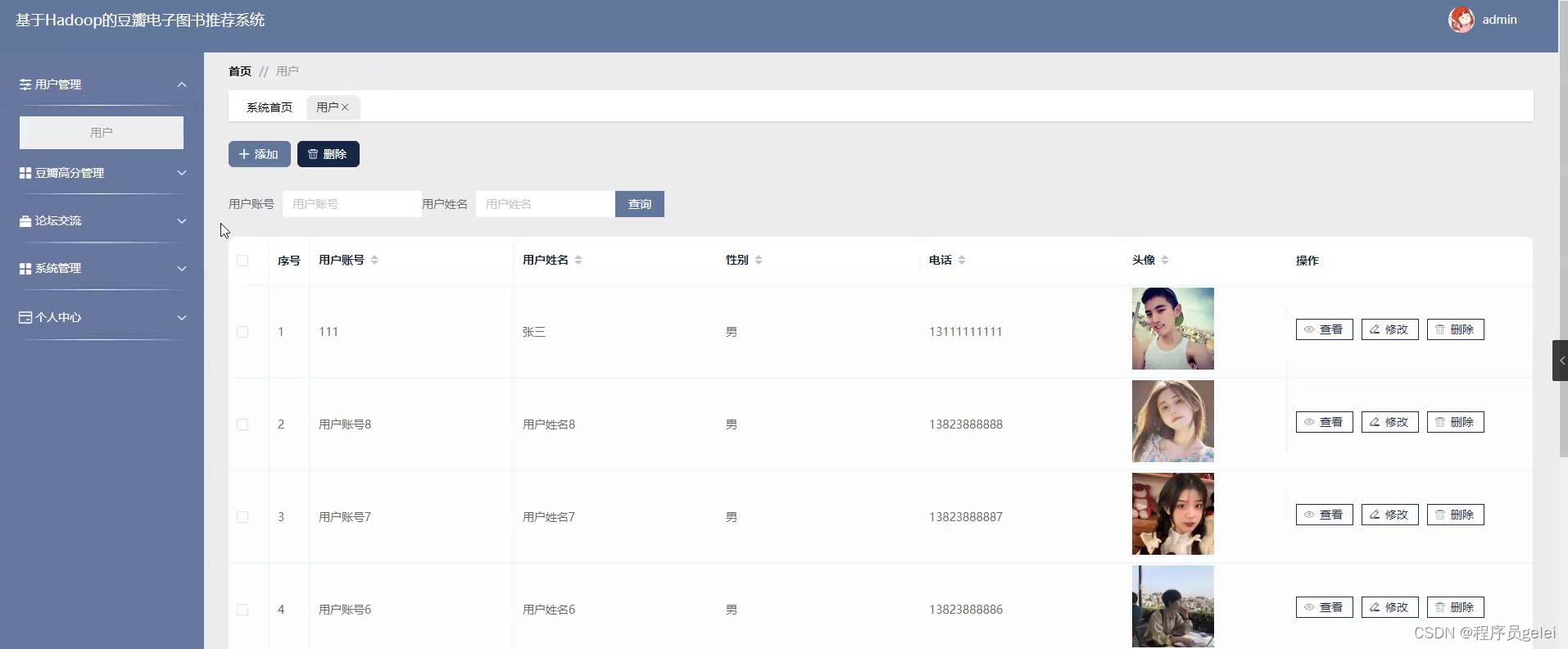

系统介绍:
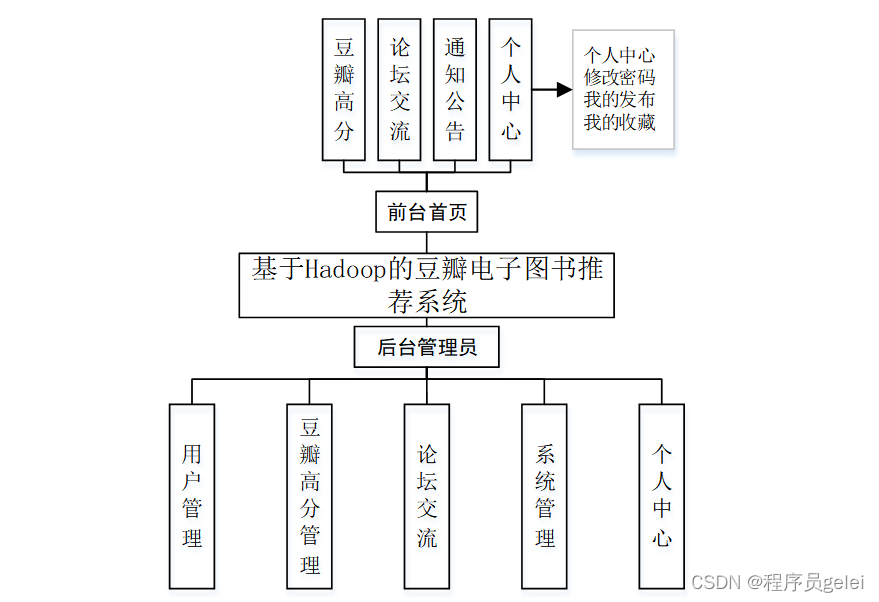
基于Hadoop的豆瓣电子图书推荐系统的研究与实现能够为用户提供更加精准和个性化的阅读推荐,从而优化用户体验,提高用户满意度和平台黏性。通过分析用户的历史阅读行为和偏好,系统可以发现用户的阅读模式,进而推荐更符合个人兴趣的书籍,帮助用户节省筛选时间,增强阅读效率。对于电子图书平台来说,一个高效的推荐系统可以促进更多优质内容的分发,增加用户流量和书籍销量,从而带动平台的经济效益。该系统的建立还有助于推动数据挖掘和机器学习技术在实际应用中的发展,为相关领域提供宝贵的实践经验和研究成果。最后,随着数据处理技术的不断进步,该研究还可以为未来电子图书推荐系统的改进提供理论基础和技术支持,具有长远的研究和应用价值。系统的功能设计是整个系统的运行基础,是一个把设计需求替换成以计算机系统的形式表示出来。通过对豆瓣电子图书推荐系统的调查、分析和研究,得出了该系统的总体规划,这是开发设计系统的初步核心。如下图所示:
部分代码参考:
# # -*- coding: utf-8 -*-
# 数据爬取文件
import scrapy
import pymysql
import pymssql
from ..items import DianzitushuItem
import time
from datetime import datetime,timedelta
import datetime as formattime
import re
import random
import platform
import json
import os
import urllib
from urllib.parse import urlparse
import requests
import emoji
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
from selenium.webdriver import ChromeOptions, ActionChains
from scrapy.http import TextResponse
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
# 电子图书
class DianzitushuSpider(scrapy.Spider):
name = 'dianzitushuSpider'
spiderUrl = 'https://read.douban.com/j/kind/'
start_urls = spiderUrl.split(";")
protocol = ''
hostname = ''
realtime = False
def __init__(self,realtime=False,*args, **kwargs):
super().__init__(*args, **kwargs)
self.realtime = realtime=='true'
def start_requests(self):
plat = platform.system().lower()
if not self.realtime and (plat == 'linux' or plat == 'windows'):
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, '0n4b129m_dianzitushu') == 1:
cursor.close()
connect.close()
self.temp_data()
return
pageNum = 1 + 1
for url in self.start_urls:
if '{}' in url:
for page in range(1, pageNum):
next_link = url.format(page)
yield scrapy.Request(
url=next_link,
callback=self.parse
)
else:
yield scrapy.Request(
url=url,
callback=self.parse
)
# 列表解析
def parse(self, response):
_url = urlparse(self.spiderUrl)
self.protocol = _url.scheme
self.hostname = _url.netloc
plat = platform.system().lower()
if not self.realtime and (plat == 'linux' or plat == 'windows'):
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, '0n4b129m_dianzitushu') == 1:
cursor.close()
connect.close()
self.temp_data()
return
data = json.loads(response.body)
try:
list = data["list"]
except:
pass
for item in list:
fields = DianzitushuItem()
try:
fields["title"] = emoji.demojize(self.remove_html(str( item["title"] )))
except:
pass
try:
fields["picture"] = emoji.demojize(self.remove_html(str( item["cover"] )))
except:
pass
try:
fields["salesprice"] = float( item["salesPrice"]/100)
except:
pass
try:
fields["wordcount"] = int( item["wordCount"])
except:
pass
try:
fields["author"] = emoji.demojize(self.remove_html(str(','.join(str(i['name']) for i in item["author"]) )))
except:
pass
try:
fields["biaoqian"] = emoji.demojize(self.remove_html(str( item.get("biaoqian", "小说") )))
except:
pass
try:
fields["detailurl"] = emoji.demojize(self.remove_html(str('https://read.douban.com'+ item["url"] )))
except:
pass
detailUrlRule = item["url"]
if '["url"]'.startswith('http'):
if '{0}' in '["url"]':
detailQueryCondition = []
detailUrlRule = '["url"]'
i = 0
while i < len(detailQueryCondition):
detailUrlRule = detailUrlRule.replace('{' + str(i) + '}', str(detailQueryCondition[i]))
i += 1
else:
detailUrlRule =item["url"]
detailUrlRule ='https://read.douban.com'+ detailUrlRule
if detailUrlRule.startswith('http') or self.hostname in detailUrlRule:
pass
else:
detailUrlRule = self.protocol + '://' + self.hostname + detailUrlRule
fields["laiyuan"] = detailUrlRule
yield scrapy.Request(url=detailUrlRule, meta={'fields': fields}, callback=self.detail_parse)
# 详情解析
def detail_parse(self, response):
fields = response.meta['fields']
try:
if '(.*?)' in '''span[itemprop="genre"]::text''':
fields["genre"] = str( re.findall(r'''span[itemprop="genre"]::text''', response.text, re.S)[0].strip())
else:
if 'genre' != 'xiangqing' and 'genre' != 'detail' and 'genre' != 'pinglun' and 'genre' != 'zuofa':
fields["genre"] = str( self.remove_html(response.css('''span[itemprop="genre"]::text''').extract_first()))
else:
try:
fields["genre"] = str( emoji.demojize(response.css('''span[itemprop="genre"]::text''').extract_first()))
except:
pass
except:
pass
try:
fields["chubanshe"] = str( response.xpath('''//span[text()="出版社"]/../span[@class="labeled-text"]/span[1]/text()''').extract()[0].strip())
except:
pass
try:
fields["cbsj"] = str( response.xpath('''//span[text()="出版社"]/../span[@class="labeled-text"]/span[2]/text()''').extract()[0].strip())
except:
pass
try:
if '(.*?)' in '''a[itemprop="provider"]::text''':
fields["provider"] = str( re.findall(r'''a[itemprop="provider"]::text''', response.text, re.S)[0].strip())
else:
if 'provider' != 'xiangqing' and 'provider' != 'detail' and 'provider' != 'pinglun' and 'provider' != 'zuofa':
fields["provider"] = str( self.remove_html(response.css('''a[itemprop="provider"]::text''').extract_first()))
else:
try:
fields["provider"] = str( emoji.demojize(response.css('''a[itemprop="provider"]::text''').extract_first()))
except:
pass
except:
pass
try:
if '(.*?)' in '''span.score::text''':
fields["score"] = float( re.findall(r'''span.score::text''', response.text, re.S)[0].strip())
else:
if 'score' != 'xiangqing' and 'score' != 'detail' and 'score' != 'pinglun' and 'score' != 'zuofa':
fields["score"] = float( self.remove_html(response.css('''span.score::text''').extract_first()))
else:
try:
fields["score"] = float( emoji.demojize(response.css('''span.score::text''').extract_first()))
except:
pass
except:
pass
try:
if '(.*?)' in '''span.amount::text''':
fields["pingjiashu"] = int( re.findall(r'''span.amount::text''', response.text, re.S)[0].strip().replace('评价',''))
else:
if 'pingjiashu' != 'xiangqing' and 'pingjiashu' != 'detail' and 'pingjiashu' != 'pinglun' and 'pingjiashu' != 'zuofa':
fields["pingjiashu"] = int( self.remove_html(response.css('''span.amount::text''').extract_first()).replace('评价',''))
else:
try:
fields["pingjiashu"] = int( emoji.demojize(response.css('''span.amount::text''').extract_first()).replace('评价',''))
except:
pass
except:
pass
return fields
# 数据清洗
def pandas_filter(self):
engine = create_engine('mysql+pymysql://root:123456@localhost/spider0n4b129m?charset=UTF8MB4')
df = pd.read_sql('select * from dianzitushu limit 50', con = engine)
# 重复数据过滤
df.duplicated()
df.drop_duplicates()
#空数据过滤
df.isnull()
df.dropna()
# 填充空数据
df.fillna(value = '暂无')
# 异常值过滤
# 滤出 大于800 和 小于 100 的
a = np.random.randint(0, 1000, size = 200)
cond = (a<=800) & (a>=100)
a[cond]
# 过滤正态分布的异常值
b = np.random.randn(100000)
# 3σ过滤异常值,σ即是标准差
cond = np.abs(b) > 3 * 1
b[cond]
# 正态分布数据
df2 = pd.DataFrame(data = np.random.randn(10000,3))
# 3σ过滤异常值,σ即是标准差
cond = (df2 > 3*df2.std()).any(axis = 1)
# 不满⾜条件的⾏索引
index = df2[cond].index
# 根据⾏索引,进⾏数据删除
df2.drop(labels=index,axis = 0)
# 去除多余html标签
def remove_html(self, html):
if html == None:
return ''
pattern = re.compile(r'<[^>]+>', re.S)
return pattern.sub('', html).strip()
# 数据库连接
def db_connect(self):
type = self.settings.get('TYPE', 'mysql')
host = self.settings.get('HOST', 'localhost')
port = int(self.settings.get('PORT', 3306))
user = self.settings.get('USER', 'root')
password = self.settings.get('PASSWORD', '123456')
try:
database = self.databaseName
except:
database = self.settings.get('DATABASE', '')
if type == 'mysql':
connect = pymysql.connect(host=host, port=port, db=database, user=user, passwd=password, charset='utf8')
else:
connect = pymssql.connect(host=host, user=user, password=password, database=database)
return connect
# 断表是否存在
def table_exists(self, cursor, table_name):
cursor.execute("show tables;")
tables = [cursor.fetchall()]
table_list = re.findall('(\'.*?\')',str(tables))
table_list = [re.sub("'",'',each) for each in table_list]
if table_name in table_list:
return 1
else:
return 0
# 数据缓存源
def temp_data(self):
connect = self.db_connect()
cursor = connect.cursor()
sql = '''
insert into `dianzitushu`(
id
,title
,picture
,salesprice
,wordcount
,author
,biaoqian
,detailurl
,genre
,chubanshe
,cbsj
,provider
,score
,pingjiashu
)
select
id
,title
,picture
,salesprice
,wordcount
,author
,biaoqian
,detailurl
,genre
,chubanshe
,cbsj
,provider
,score
,pingjiashu
from `0n4b129m_dianzitushu`
where(not exists (select
id
,title
,picture
,salesprice
,wordcount
,author
,biaoqian
,detailurl
,genre
,chubanshe
,cbsj
,provider
,score
,pingjiashu
from `dianzitushu` where
`dianzitushu`.id=`0n4b129m_dianzitushu`.id
))
order by rand()
limit 50;
'''
cursor.execute(sql)
connect.commit()
connect.close()论文参考: 

源码获取:
文章下方名片联系我即可~
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











