







一、arcpy操作字段
1、删除字段函数:arcpy.DeleteField_management
语法:DeleteField_management (in_table,drop_field)
|
参数
|
说明
|
数据类型
|
|
in_table
|
包含要删除字段的表。将修改现有输入表。
|
Mosaic Layer; Raster Layer; Table View
|
|
drop_field
[drop_field,...]
|
要从输入表中删除的字段。必填字段不能删除。
|
Field
|
要删除“省级行政区域.shp”的AREA、PERIMETER两个字段。
①对于已加载的图层(比如本例)第1参可以直接使用图层名“省级行政区域”;
②要删除多个字段,第2参用‘字段名1;字段名2;…’
Ps: string类型外包是“双引号”,还是‘单引号’都可以,python都认!
2、增加字段
语法:AddFields_management (in_table,field_description)
|
参数
|
说明
|
数据类型
|
|
in_table
|
要添加指定字段的输入表。该字段将被添加到现有输入表,并且不会创建新的输出表。
可将字段添加到 ArcSDE 的要素类、文件或个人地理数据库的要素类、coverage、shapefile、栅格目录、独立表、带属性表的栅格和/或图层。
|
Mosaic Layer;
Raster Catalog Layer;
Raster Layer;
Table View
|
|
field_name
|
要添加到输入表的字段的名称。
|
String
|
|
field_type
|
在创建新字段时所使用的字段类型。
· TEXT —名称或其他文本特性。
· FLOAT —特定范围内含小数值的数值。
· DOUBLE —特定范围内含小数值的数值。
· SHORT —特定范围内不含小数值的数值;编码值。
· LONG —特定范围内不含小数值的数值。
· DATE —日期和/或时间。
· BLOB —影像或其他多媒体。
· RASTER —栅格影像。
· GUID —GUID 值
|
String
|
|
field_precision
(
可选
)
|
描述可存储在字段中的位数。所有位都将被计算在内,而无论其处于小数点的哪一侧。
如果输入表是个人或文件地理数据库,则将忽略字段精度值。
|
Long
|
|
field_scale
(
可选
)
|
设置可存储在字段中的小数位数。此参数仅可用于浮点型和双精度数据字段类型。
如果输入表是个人或文件地理数据库,则将忽略字段小数位数值。
|
Long
|
|
field_length
(
可选
)
|
要添加的字段的长度。它为字段的每条记录设置最大允许字符数。此选项仅适用于文本或 blob 类型的字段。
|
Long
|
|
field_alias
(
可选
)
|
指定给字段名称的备用名称。此名称用于为含义隐晦的的字段名称指定更具描述性的名称。字段别名参数仅适用于地理数据库和 coverage。
|
String
|
|
field_is_nullable
(
可选
)
|
不存在关联属性信息的地理要素。它们与零或空字段不同,仅支持地理数据库中的字段。
· NON_NULLABLE —字段不允许空值。
· NULLABLE —字段允许空值。这是默认设置。
|
Boolean
|
|
field_is_required
(
可选
)
|
指定要创建的字段是否是表的必填字段;仅支持地理数据库中的字段。
· NON_REQUIRED —字段不是必填字段。这是默认设置。
· REQUIRED —此字段是必填字段。必填字段具有永久性,不能删除。
|
Boolean
|
|
field_domain
(
可选
)
|
用于约束地理数据库中的表、要素类或子类型的任何特定属性的允许值。必须指定现有属性域的名称才能将其应用于字段。
|
String
|
例:
要对“省级行政区域”增加一个名为“Area”,类型是“Text”,长度是100的字段。
①第1参“输入表”与第2参“字段名”是必选参数;
②其他参数为字段描述,可选,最好使用具名参数,如field_length=100。
3、字段列表函数:arcpy.ListFields
语法:ListFields (dataset, {wild_card},{field_type})
|
参数
|
说明
|
数据类型
|
|
dataset
|
指定的要素类或表(其字段将被返回)。
|
String
|
|
wild_card
|
wild_card 可限制返回的结果。如果未指定任何 wild_card,则会返回所有值。
(默认值为 None)
|
String
|
|
field_type
|
要返回的指定字段类型。有效字段类型为:
(默认值为 All)
|
String
|
例:打印出“省级行政区域”的所有字段名
① arcpy.ListFields返回字段对象列表;
②本例只循环打印出字段的name属性。
4、批量删除字段例:批量删除“省级行政区域”除“FID”、“Shape”、“Area”之外的字段
①用到arcpy.ListFields与arcpy.DeleteField_management两个函数;
②用if语句判断字段名,不是要保留的就删除。
5、批量添加字段例:给“省级行政区域”添加“A、B、C、D”4个字段。
①用Excel制作出字段及其描述表;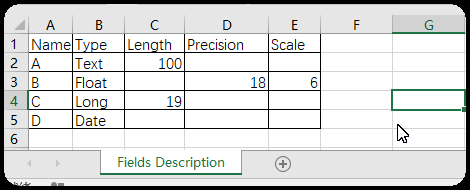
②复制除标题行以为的内容,粘贴到txt文档,替换空格为“,”(英文符号,);
③arcpy批量添加字段,导入“Fields Description.txt”描述,每一行line是1个字段信息,故将每行信息用“,”拆分装入列表lineList;新建字段各属性描述使用“具名参数=列表各索引值指示数据”的方式传入;
④使用该脚本时只需要改动“Fields Description.txt”描述文件路径与待处理的要素名即可。
6、根据字段拆分(批量分析工具-筛选功能)
①该脚本实现把“省级行政区域”按“NAME”拆分成多个图层;
②该脚本只需要在变量声明时修改注释中写明的3个参数。
函数:arcpy.Select_analysis
语法:Select_analysis (in_features,out_feature_class, {where_clause})
|
参数
|
说明
|
数据类型
|
|
in_features
|
从中选择要素的输入要素类或图层。
|
Feature Layer
|
|
out_feature_class
|
要创建的输出要素类。如果不使用任何表达式,则其中将包含所有输入要素。
|
Feature Class
|
|
where_clause
(可选)
|
用于选择要素子集的 SQL 表达式。有关 SQL 语法的详细信息,请参阅帮助主题
在查询表达式中使用的元素的 SQL 参考。
|
SQL Expression
|
Ps:ArcGis10.5以上版本有函数:SplitByAttributes_analysis (Input_Table, Target_Workspace,Split_Fields)















 3354
3354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









