







概要:类加载过程、对象创建过程、异常、servlet生命周期、集合、线程、分库分表、HTTP请求过程,数据库优化
1.基本数据类型(原生类型):byte,short,int,long,float,double,char,boolean
自动类型转换:小范围的数转为大范围的
自动装箱:Integer a=123; 拆箱再装箱 a=a+3;
2.重载:一个类,函数同名,参数个数、类型、顺序不同,与返回值修饰符无关
重写:子父类,函数同名,参数相同,返回值相容,子访问权限>=父类权限
3.构造函数的初始化顺序:父类静态、子类静态、父类变量或代码块、父类构造函数、子类变量或代码块、子类构造函数
4.接口与抽象类的区别:都不能被实例化,但都可以声明;
接口无构造函数,抽象类可以有;
接口可以被多实现,接口可以继承多个接口,抽象类只能被单继承;
5.面向对象:将以前过程的执行者变成了指挥者,万物皆对象,即“让谁来做?”
面向过程:用函数把步骤一个个实现,使用时再一个个调用,即“我该怎么做”
类:对事物的描述,是封装对象行为和属性的载体
对象:实实在在的个体,实体,封装多个数据
封装:隐藏对象的属性和实现细节,仅仅对外提供访问方式。
继承:子类继承父类的属性和方法
多态:父类引用指向自己子类的对象,体现在重载和复写
类的加载过程:
当使用 java 命令运行 java 程序时,此时 JVM 启动,并去方法区下找 java 命令后面跟的类是否存在,如果不存在,则把类加载到方法区下在类加载到方法区时,会分为两部分:先加载非静态内容到方法区下的非静态区域内,再加载静态内容到方法区下的静态区域内
当非静态内容载完成之后,就会加载所有的静态内容到方法区下的静态区域内
3.1 先把所有的静态内容加载到静态区域下
3.2 所有静态内容加载完之后,对所有的静态成员变量进行默认初始化
3.3 当所有的静态成员变量默认初始化完成之后,再对所有的静态成员变量显式初始化
4,当所有的静态成员变量显式初始化完成之后,JVM 自动执行静态代码块(静态代码块在栈中执行)[如
果有多个静态代码,执行的顺序是按照代码书写的先后顺序执行]
5,所有的静态代码块执行完成之后,此时类的加载完成
对象的创建过程:
当在 main 方法中创建对象时,JVM 会先去方法区下找有没有所创建对象的类存在,有就可以创建对象了,没有则把该类加载到方法区在创建类的对象时,首先会先去堆内存中开辟一块空间,开辟完后分配该空间(指定地址)
当空间分配完后,加载对象中所有的非静态成员变量到该空间下
所有的非静态成员变量加载完成之后,对所有的非静态成员进行默认初始化
所有的非静态成员默认初始化完成之后,调用相应的构造方法到栈中
在栈中执行构造函数时,先执行隐式,再执行构造方法中书写的代码
当整个构造方法全部执行完,此对象创建完成,并把堆内存中分配的空间地址赋给对象名。
6.异常:throwable–Error 系统出错
–Exception–otherException 必须处理,否则编译不通过
–RuntimeExcepton 不需要捕获,可以不处理,也可以捕获,Java编译器不会检查它
7.serlet的生命周期:
加载:容器通过类加载器使用servlet类对应的文件加载servlet
创建:通过调用servlet的构造函数来创建一个servlet实例
初始化:调用servlet 的init()方法
处理客户端请求:当有新的请求时,web容器都会创建一个新的线程来处理,接着调用service方法
卸载:容器在servlet之前调用destory()释放占用的资源
8.集合
集合长度是可变的,只存储引用类型的数据,存储的对象可以是不同类型
数组长度是不可变的
list 有序可重复 --ArrayList 底层数组 ,查询快增删慢,初始容量10,按原数组的50%延长
--LinkedList 底层链表,增删快查询慢
--vector 底层数组,按原来100%延长,同步
set 无序不可重复 --hashset 底层hash表,保证元素的唯一性通过hashcode和equals完成
--TreeSet 底层二叉树,对元素进行指定顺序的排序(实现Comparable接口,复写compareTo)
map --HashMap 底层哈希表,存null键null值,默认长度16,长度必须是2的次幂(尽量分布均匀的hash函数)
--HashTable 底层哈希表,同步,不可以存null键null值
--TreeMap 底层二叉树,对map键进行指定顺序的排序
--weakhashMap 存null键null值,键是弱键,entry可能被gc自动删除,适用于缓存
--ConcurrentHashMap 底层采用分段的数组+链表实现,线程安全.Hashtable中采用的锁机制是一次锁住整个hash表,从而在同一时刻只 能由一个线程对其进行操作;而ConcurrentHashMap中则是一次锁住一个桶
锁分段技术:首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问.
遍历通过map.keySet()和map.entrySet()
hashmap的底层原理:利用key的hashCode重新hash计算出当前对象的元素在数组中的下标存储时,如果出现hash值相同的key,此时有两种情况。(1)如果key相同,则覆盖原始值;(2)如果key不同(出现冲突),则将当前的key-value放入链表中,获取时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。理解了以上过程就不难明白HashMap是如何解决hash冲突的问题,核心就是使用了数组的存储方式,然后将冲突的key的对象放入链表中,一旦发现冲突就在链表中做进一步的对比。
9.线程
进程:正在进行中的程序
线程:进程中的程序执行控制单元
同步:指发送一个请求,需要等待返回,然后才能够发送下一个请求,有个等待过程
异步:指发送一个请求,不需要等待返回,随时可以再发送下一个请求,即不需要等待
并发:应用能够交替执行不同的任务;两个或多个事件在同一时间间隔发生
并行:指应用能够同时执行不同的任务;指两个或者多个事件在同一时刻发生
线程池:jdbc connection,线程thread,对象,这些东西的创建和销毁都是很消耗时间的,所以我们一般都是提前创建好很多这种创建消耗高的东西,用的时候直接去用就行。
线程生命周期:
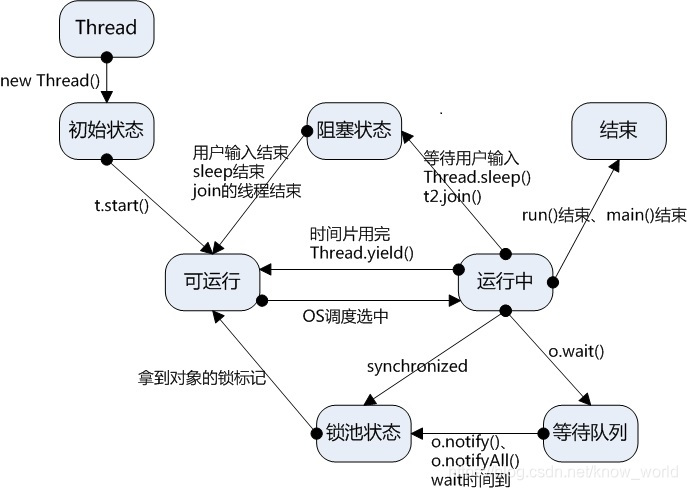 新建状态:创建线程对象后,三种创建方式:实现Callable 接口,并实现 call()方法;实现runnable 接口,并重写该接口的 run()方法;继承Thread 类,并重写该类的 run 方法。
新建状态:创建线程对象后,三种创建方式:实现Callable 接口,并实现 call()方法;实现runnable 接口,并重写该接口的 run()方法;继承Thread 类,并重写该类的 run 方法。
就绪状态:调用线程对象的start()方法,随时等待cpu调度
运行状态:cpu调度处于就绪态的线程
阻塞状态:暂时放弃CPU的使用权,停止执行进入阻塞(锁被占用,调用wait、sleep或join方法)
死亡状态:执行完run方法或因为异常退出
ThreadLocal 保证不同线程拥有不同实例,相同线程一定拥有相同的实例,即为每一个使用该
变量的线程提供一个该变量值的副本,每一个线程都可以独立改变自己的副本,而不是与其它线程
的副本冲突。
优势:提供了线程安全的共享对象
与其它同步机制的区别:同步机制是为了同步多个线程对相同资源的并发访问,是为了多个线程之
间进行通信;而 ThreadLocal 是隔离多个线程的数据共享,从根本上就不在多个线程之间共享资源
,这样当然不需要多个线程进行同步了
volatile 修饰的成员变量在每次被线程访问时,都强迫从共享内存中重读该成员变量的值。而且,当成员变量发生变化时,强迫 线程将变化值回写到共享内存。
优势:这样在任何时刻,两个不同的线程总是看到某个成员变量的同一个值。
10.MySQL分库分表
分库分表有垂直切分和水平切分两种。
垂直切分:即将表按照功能模块、关系密切程度划分出来,部署到不同的库上。例如,我们会建立定义数据库 workDB、商品数据库 payDB、用户数据库 userDB、日志数据库 logDB 等,分别用于存储项目数据定义表、商品定义表、用户数据表、日志数据表等。
水平切分:当一个表中的数据量过大时,我们可以把该表的数据按照某种规则,例如 userID 散列,进行划分,然后存储到多个结构相同的表,和不同的库上。例如,我们的 userDB 中的用户数据表中,每一个表的数据量都很大,就可以把 userDB 切分为结构相同的多个 userDB:part0DB、part1DB 等,再将 userDB 上的用户数据表 userTable,切分为很多 userTable:userTable0、userTable1 等,然后将这些表按照一定的规则存储到多个 userDB 上
mysql 读写分离:
在实际的应用中,绝大部分情况都是读远大于写。Mysql 提供了读写分离的机制,所有的写操作都必须对应到 Master,读操作可以在 Master 和 Slave 机器上进行, Slave 与 Master 的结构完全一样,一个 Master 可以有多个 Slave,甚至 Slave 下还可以挂 Slave,通过此方式可以有效的提高 DB 集群的每秒查询率. 所有的写操作都是先在 Master 上操作,然后同步更新到 Slave 上,所以从 Master 同步到 Slave 机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave 机器数量的增加也会使这个问题更加严重。此外,可以看出 Master 是集群的瓶颈,当写操作过多,会严重影响到 Master 的稳定性,如果 Master 挂掉,整个集群都将不能正常工作。所以,1. 当读压力很大的时候,可以考虑添加 Slave 机器的分式解决,但是当 Slave 机器达到一定的数量就得考虑分库了。 2. 当写压力很大的时候,就必须得进行分库操作。
11.一次http请求过程:域名解析 --> 发起TCP的3次握手 --> 建立TCP连接后发起http请求 --> 服务器响应http请求,浏览器得到html代码 --> 浏览器解析html代码,并请求html代码中的资源(如js、css、图片等) --> 浏览器对页面进行渲染呈现给用户
12.数据库优化
库设计:读写分离,分表分库,使用连接池
建表:varchar代替char,默认值不要为null;大数据的字段的剥离出单独的表;表设置主键,建索引;
建索引:频繁写(增删改)的字段和数据唯一性差的字段不要建索引;where和orderby中常用的字段建索引;索引会占用磁盘空间影响增删改效率;建多个索引要遵循最左原则
查询优化:尽量避免*,!=,<>,null,or,in,对字段进行表达式或函数操作;使用连接代替子查询。
13.事务
事务特性:原子一致隔离持久
数据库隔离级别:read uncommitted(A能读到B),read committed提交读(A能读到B提交的数据),repeatable read可重复读,serializable可串行化
spring事务:本质上使用数据库事务,数据库事务本质上使用数据库锁,开启spring事务意味着使用数据库锁。隔离级别通过锁机制实现
所谓spring事务的传播属性,就是定义在存在多个事务同时存在的时候,spring应该如何处理这些事务的行为
使用事务时必看(转载):https://blog.csdn.net/codingtu/article/details/78046104















 324
324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









