







初识Hadoop
Hadoop主要由两个部分构成:
- HDFS分布式文件系统
- MapReduce分布式数据分析处理系统
HDFS
解决大数据时代单磁盘存储数据过大,读取缓慢问题。
适用场景
- 一次写入,多次读取(查询)。不支持并发写入、修改。
- 运行在普通硬件上
- 适用于高吞吐量应用,不适用于低时间延迟(几十毫秒内)应用
不适用于大量小文件,文件系统所能存储的文件总数受限于namenode的内存容量。小文件也占用一个块,小文件越多(1000个1k文件)数据块越多,nameNode压力越大。(HDFS中小于一个块大小的文件不会占据整个块的空间)??
数据块
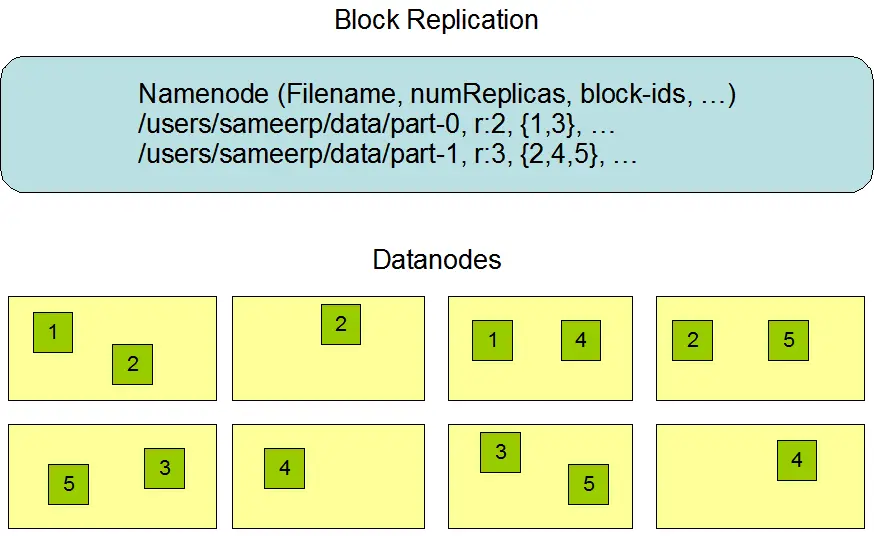
数据块是存储的最小单位,HDFS的块(block)默认为64MB。文件被划分为块大小的多个块分别存储在多个任意节点磁盘上。
namenode 和 datanode
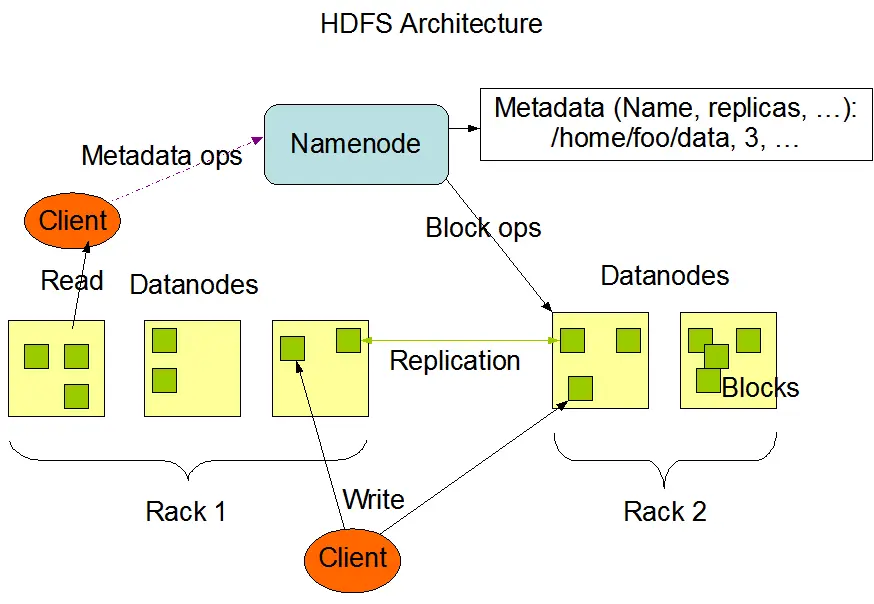
HDFS集群有两类节点 以 namenode(管理者:一个)-datanode(工作者:多个) 模式运行,上图反映了NameNode和DataNode的交互过程。
namenode
用于管理所有文件和目录树(文件系统命名空间)与块的映射,并通过命名空间镜像文件和编辑日志文件在磁盘保存。同时通过记录每个文件的块与应节点映射信息保存在内存中,每次集群启动时由数据结点重新创建。
datanode
为工作结点,负责存储、检索数据块,受namenode调度并定期向namenode发送存储块的列表(a Heartbeat(心跳) and a Blockreport )。
namenode节点容错机制 (两种)
第一种机制,配置namenode在多个系统节点保存元数据持久状态。各节点实时同步(原子操作)
第二种机制,备用namenode,有滞后性会丢失数据。
联邦HDFS
2.X版本以后支持联邦HDFS解决内存横向扩展限制,允许添加多个namenode,分别管理各自的目录、文件、数据块的数据块池。每个namenode相互独立互不影响。
高可用性(HA)支持 活动-备用(active-standby)namenode
用于实现一个namenode失效快速恢复,当一个活动namenode失效,备用namenode会接替它的工作。
- 故障切换与规避
权限模式
Hadoop权限模式分为三种:只读权限(r)、写入权限(w)、可执行权限(x)
每个文件和目录都有所属用户(owner)、所属组别(group)、模式(mode)。
权限检查
超级用户不需要权限检查
命令行操作接口
Hadoop文件系统
JAVA API
I/O操作
数据完整性
MapReduce
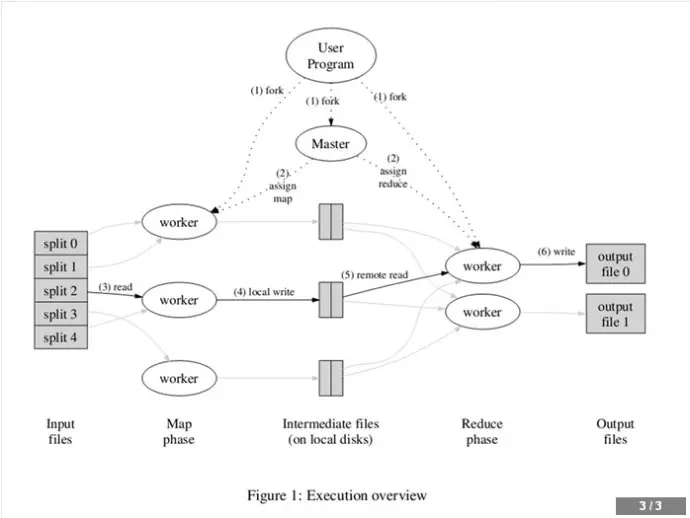
MapReduce工作原理
- 从HDFS存储中获取输入数据,输入数据会被划分为n份(n由用户定义),如[图1],被划分为0~4个split(分片)















 1479
1479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









