







网友发来一个SQL,说他们公司的一个SQL要优化帮忙看一下,执行计划如下:
-------------------------------------SELECT * FROM (SELECT * FROM TXS C WHERE C.A ISNULL OR C.A = '' ORDER BY ID_TXS DESC) WHERE ROWNUM<=100---------------------------------------------------------------------------------------------------| Id | Operatistartupon | Name | E-Rows |E-Bytes| Cost (%CPU)| E-Time | OMem | 1Mem | O/1/M |---------------------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | | | 584K(100) | | | | ||* 1 | COUNT STOPKEY | | | | | | | | || 2 | VIEW | | 2 | 1292 | 584K (1) | 01:56:49 | | | ||* 3 | SORT ORDER BY STOPKEY| | 2 | 334 | 584K (1) | 01:56:49 | 2048 | 2048 | 13/0/0||* 4 | TABLE ACCESS FULL | TXS | 2 | 334 | 584K (1) | 01:56:49 | | | |---------------------------------------------------------------------------------------------------
SQL 比较简单,就是一个单表查询。对于oracle 的单表查询,执行计划无外乎走全表扫描和走索引两种大的方向。这是一个使用全表扫描操作( ID =4,执行计划中的 TABLE ACCESS FULL)。即使 A列上存在简单索引,也不可能走索引。原因单列字段的索引不会存储NULL值,NULL 值会被忽略。表大小TXS有10多G,执行超过 150 秒。
先说结论解决办法是:创建包含 NULL 值的索引。也就是创建一个复合索引,其中一个值是带有 NULL 的列,另一个值只是一个常量的复合索引 。
create index idx_01 t on TXS(A,0) ONLINE;------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes |Cost (%CPU)| Time |------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 2 | 1292 | 4 (25)| 00:00:01 ||* 1 | COUNT STOPKEY | | | | | || 2 | VIEW | | 2 | 1292 | 4 (25)| 00:00:01 ||* 3 | SORT ORDER BY STOPKEY | | 2 | 334 | 4 (25)| 00:00:01 || 4 | TABLE ACCESS BY INDEX ROWID| TXS | 2 | 334 | 3 (0) | 00:00:01 ||* 5 | INDEX RANGE SCAN | idx_01 | 2 | | 2 (0) | 00:00:01 |------------------------------------------------------------------------------
创建完索引后,执行计划变成索引访问扫描,该sql 只要0.25s。这相当于创建索引来查找具有空值的记录(一般返回少量记录才会走索引),可是Oracle 不会为具有空值的列建立索引。于是通过向索引添加额外的字符 (1或者0),Oracle 就可为空的值建立索引。
如果一张表里面假设A 字段Null值很多并且A上创建了索引,如果查询 A is NULL的结果,这样子走全表扫描也是更高效的方式。如果A is NULL 的的结果很少,走全表扫描就非常糟糕。
案例是这么个简单的案例。下面详细把这里面的原理说清楚。假设一个组合索引有(A,B)两列组成。则有下面三种情况。
情况1-》(A非空,NULL) --》索引中有此行记录
情况2-》(NULL,B非空) --》索引中有此行记录
情况3-》(NULL,NULL) --》索引中无此行记录
组合索引,所有索引列的值都为NULL时,表中的该行将不在索引中存储。所以通过复合索引和至少一个非空列属性,Oracle 可以保证所有其他列的每个空值都包含在索引中,如果是IS NULL的查询可能用到此索引。
下面看例子:查询 PCT_FREE IS NULL是全面扫描
SQL> CREATE TABLE test_nulls AS SELECT * FROM dba_tables;Table created.SQL> CREATE INDEX idx_PCT_FREE ON test_nulls(pct_free);Index created.SQL> exec DBMS_STATS.GATHER_TABLE_STATS(ownname=>'TEST', tabname=>'TEST_NULLS')PL/SQL procedure successfully completed.SQL> SELECT * FROM test_nulls WHERE pct_free IS NULL;72 rows selected.Execution Plan----------------------------------------------------------Plan hash value: 4225836326--------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |--------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 72 | 17280 | 31 (0)| 00:00:01 ||* 1 | TABLE ACCESS FULL| TEST_NULLS | 72 | 17280 | 31 (0)| 00:00:01 |--------------------------------------------------------------------------------
甚至用hint都无法强制走索引
SQL> SELECT /*+ INDEX(tn, IDX_PCT_FREE) */ * FROM test_nulls tn WHERE pct_free IS NULL;72 rows selected.Execution Plan----------------------------------------------------------Plan hash value: 4225836326--------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |--------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 72 | 17280 | 31 (0)| 00:00:01 ||* 1 | TABLE ACCESS FULL| TEST_NULLS | 72 | 17280 | 31 (0)| 00:00:01 |--------------------------------------------------------------------------------
创建组合索引 (pct_free, owner) ,执行计划开始走索引
SQL> CREATE INDEX IDX_PCT_FREE2 ON test_nulls(pct_free, owner) ;Index created.SQL> SELECT * FROM test_nulls WHERE pct_free IS NULL;72 rows selected.Execution Plan----------------------------------------------------------Plan hash value: 2881765546---------------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |---------------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 72 | 17280 | 8 (0)| 00:00:01 || 1 | TABLE ACCESS BY INDEX ROWID| TEST_NULLS | 72 | 17280 | 8 (0)| 00:00:01 ||* 2 | INDEX RANGE SCAN | IDX_PCT_FREE2 | 72 | | 2 (0)| 00:00:01 |---------------------------------------------------------------------------------------------
创建另外一个组合索引(pct_free, ' ')
SQL> CREATE INDEX IDX_PCT_FREE3 ON test_nulls(pct_free, ' ');Index created.SQL> SELECT * FROM test_nulls WHERE pct_free IS NULL;no rows selectedExecution Plan----------------------------------------------------------Plan hash value: 3683813840---------------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |---------------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 72 | 17280 | 6 (0)| 00:00:01 || 1 | TABLE ACCESS BY INDEX ROWID| TEST_NULLS | 72 | 17280 | 6 (0)| 00:00:01 ||* 2 | INDEX RANGE SCAN | IDX_PCT_FREE3 | 72 | | 2 (0)| 00:00:01 |---------------------------------------------------------------------------------------------
可以看到走了代价更低的IDX_PCT_FREE3。这是因为IDX_PCT_FREE3索引比IDX_PCT_FREE2索引更加小。(pct_free, ' ')的空格字符占用一个字节,索引中的列长度占用一个额外字节,每个索引条目总共需要 2 个字节的开销。开销越小,CBO就越可能选
现在表的索引情况:
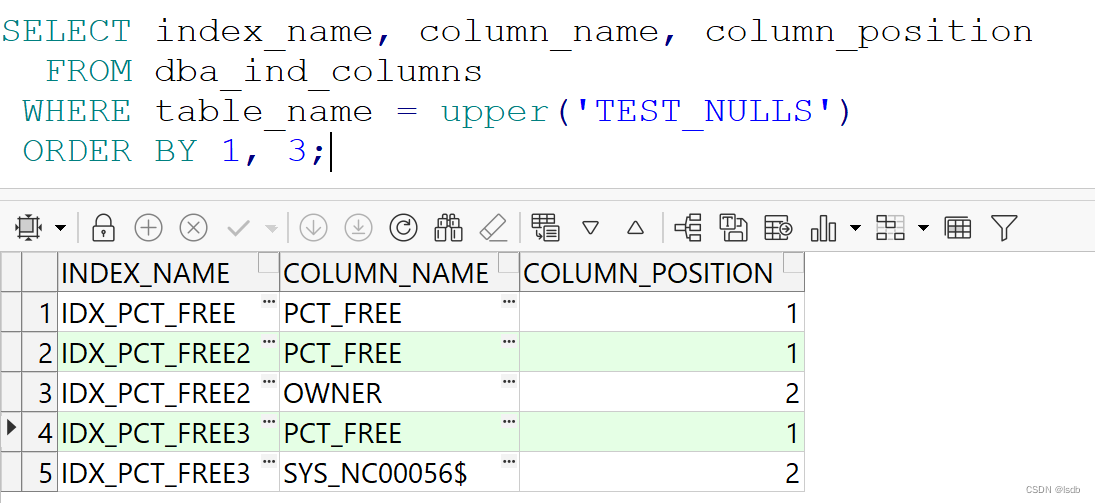
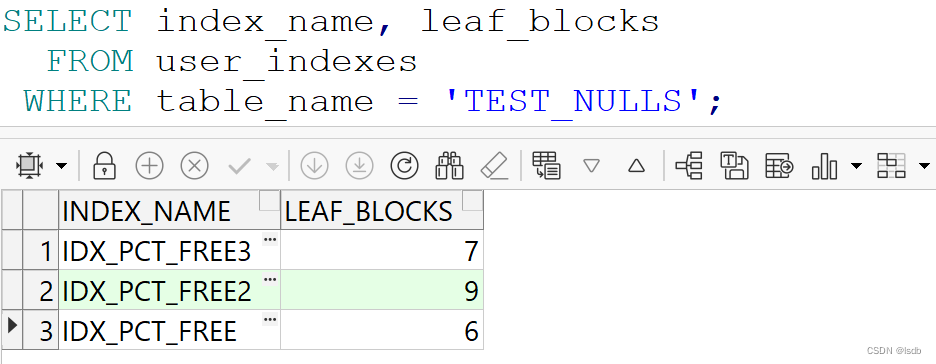
IDX_PCT_FREE3 --》(pct_free, ' ') --》7 --》明显要比用owner的组合索引要小
IDX_PCT_FREE2 --》(pct_free, owner)--》9
IDX_PCT_FREE --》(pct_free)--》6
dump索引块看看
SQL> select object_id from dba_objects where object_name=upper('IDX_PCT_FREE3');OBJECT_ID----------88896SQL> alter session set events 'immediate trace name treedump level &object_id_index';Enter value for object_id_index: 88896old 1: alter session set events 'immediate trace name treedump level &object_id_index'new 1: alter session set events 'immediate trace name treedump level 88896'Session altered.SQL>
----- begin tree dump
branch: 0x1083593 17315219 (0: nrow: 7, level: 1) ---root节点
leaf: 0x1083594 17315220 (-1: nrow: 462 rrow: 462) --7个叶子块
leaf: 0x1083595 17315221 (0: nrow: 448 rrow: 448)--每个叶子块448行记录
leaf: 0x1083596 17315222 (1: nrow: 448 rrow: 448)
leaf: 0x1083597 17315223 (2: nrow: 448 rrow: 448)
leaf: 0x1083598 17315224 (3: nrow: 448 rrow: 448)
leaf: 0x1083599 17315225 (4: nrow: 448 rrow: 448)
leaf: 0x108359a 17315226 (5: nrow: 169 rrow: 169)
----- end tree dump
dump一个索引叶子块
SQL> @get_dba.sqlEnter value for rdbanex: 0x1083596old 1: SELECT dbms_utility.DATA_BLoCK_ADDRESS_FILE(to_number(REPLACE('&rdbanex',new 1: SELECT dbms_utility.DATA_BLoCK_ADDRESS_FILE(to_number(REPLACE('0x1083596',Enter value for rdba_hex: 0x1083596old 5: dbms_utility.DATA_BLoCK_ADDRESS_BLocK(to_number(REPLACE('&rdba_hex',new 5: dbms_utility.DATA_BLoCK_ADDRESS_BLocK(to_number(REPLACE('0x1083596',FI1E_NO B1OCK_NO---------- ----------4 538006SQL> alter system dump datafile &file_id block █Enter value for file_id: 4Enter value for block: 538006old 1: alter system dump datafile &file_id block &blocknew 1: alter system dump datafile 4 block 538006System altered.SQL>
--叶子节点保存的是索引的值和rowid的值
KDXCOLEV Flags = - - -
kdxcolok 0
kdxcoopc 0x80: opcode=0: iot flags=--- is converted=Y
kdxconco 3
kdxcosdc 0
kdxconro 448
kdxcofbo 932=0x3a4
kdxcofeo 1760=0x6e0
kdxcoavs 828
kdxlespl 0
kdxlende 0
kdxlenxt 17315223=0x1083597
kdxleprv 17315221=0x1083595
kdxledsz 0
kdxlebksz 8032
row#0[8018] flag: ------, lock: 0, len=14
col 0; len 2; (2): c1 0b
col 1; len 1; (1): 20 --》可以看到空格存储到数据块里面就是16进制的20
col 2; len 6; (6): 01 08 35 1d 00 15 --》rowid信息
row#1[8004] flag: ------, lock: 0, len=14
col 0; len 2; (2): c1 0b
col 1; len 1; (1): 20
col 2; len 6; (6): 01 08 35 1d 00 16
row#2[7990] flag: ------, lock: 0, len=14
col 0; len 2; (2): c1 0b
col 1; len 1; (1): 20
col 2; len 6; (6): 01 08 35 1d 00 17
row#3[7976] flag: ------, lock: 0, len=14
col 0; len 2; (2): c1 0b
col 1; len 1; (1): 20
col 2; len 6; (6): 01 08 35 1d 00 18
row#4[7962] flag: ------, lock: 0, len=14
col 0; len 2; (2): c1 0b
col 1; len 1; (1): 20
col 2; len 6; (6): 01 08 35 1d 00 19
SQL> SELECT dump(0,16), dump(' ',16), dump(1,16) FROM dual;
DUMP(0,16) DUMP(' ',16) DUMP(1,16)
--------------- ---------------- -----------------
Typ=2 Len=1: 80 Typ=96 Len=1: 20 Typ=2 Len=2: c1,2
值0的空格的长度和空格的长度都是1,索引更加小。但是数字的话长度是2,查看dba_ind_expressions视图可以显示索引中的表达式.

总结:Oracle 索引默认情况下不能包含空值。这是因为在 B 树索引结构中,空值无法唯一标识索引的位置,这会导致索引的不确定性和性能问题。因此,Oracle 索引在设计上排除了空值。但是可以通过创建函数索引或者在列上创建复合索引的方式绕过这一限制。也就是说SQL优化很多时候先从原理出发,理解为什么不保存空值。因为这是Oracle 算法决定了。那么思路就变成了,怎么样能使算法生效。本质也就是理论和实践的相结合,而不是凭空想象。无中生有。
欢迎关注和转发本公众号,你的支持是我继续写作的动力

















 780
780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









