







 本文介绍了如何处理URL中的中文编码问题,使用Python的urllib库进行URL编码和解码,并提供了解决编码错误的方法。还讲解了如何通过正则表达式抓取百度图片搜索结果中的objURL获取清晰大图。
本文介绍了如何处理URL中的中文编码问题,使用Python的urllib库进行URL编码和解码,并提供了解决编码错误的方法。还讲解了如何通过正则表达式抓取百度图片搜索结果中的objURL获取清晰大图。
目标地址: http://image.baidu.com/
输入美女
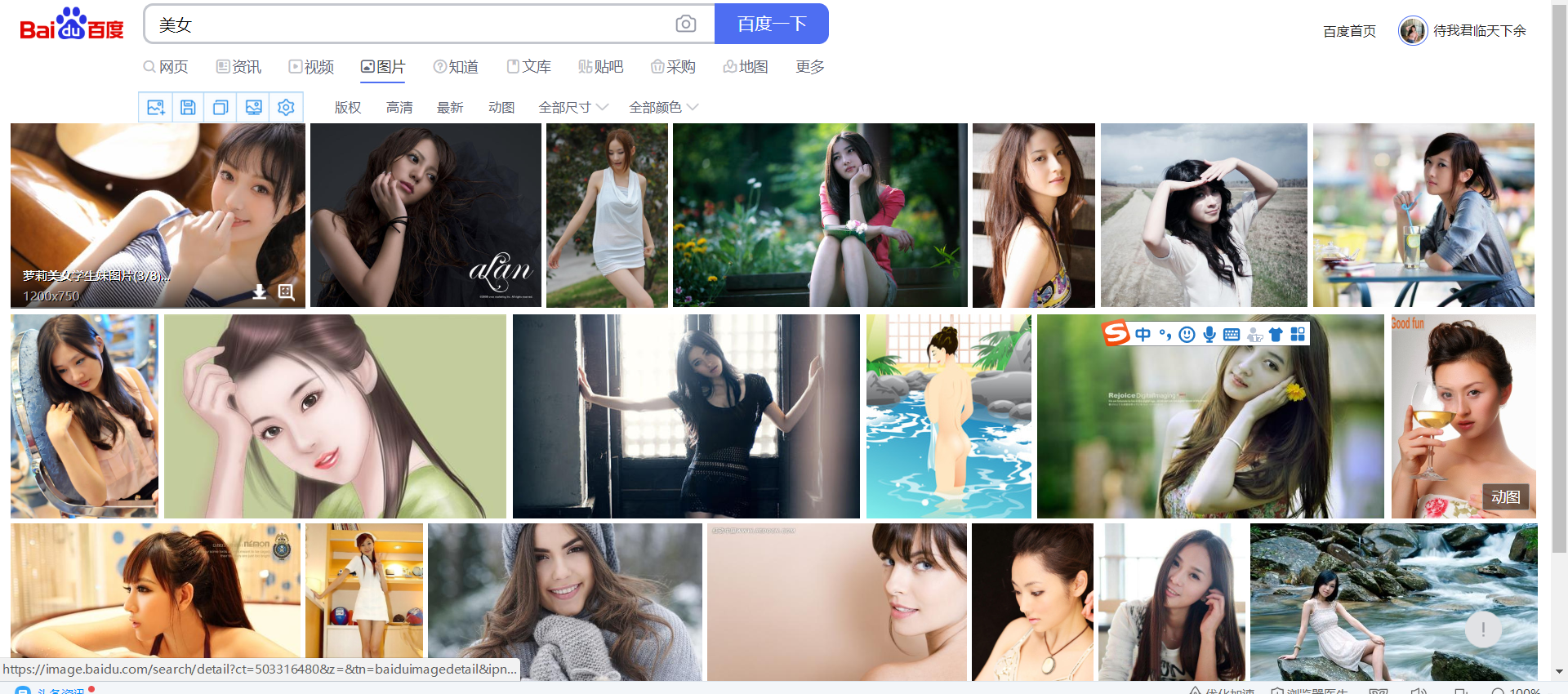
分析网址
元网址见图
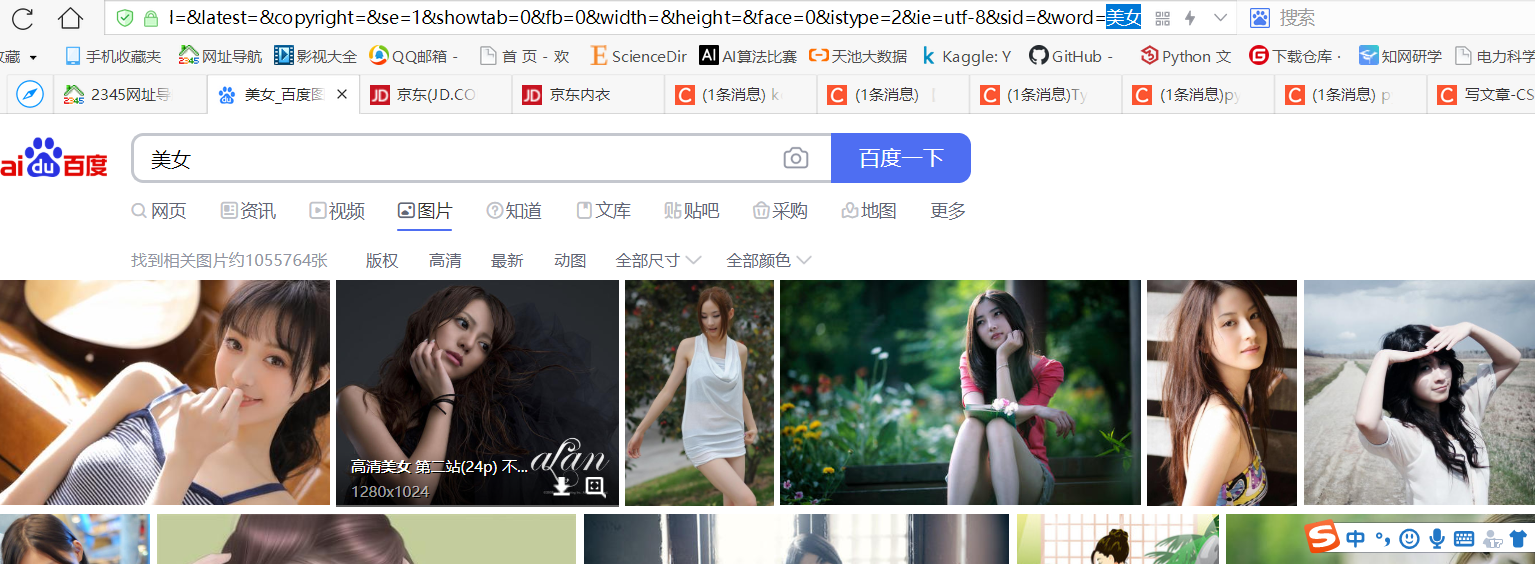
粘贴过来却如下
(在这里你会看到,明明在浏览器URL栏看到的是中文,但是复制url,粘贴到记事本或代码里面,就会变成如下这样???)
https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1610771025434_R&pv=&ic=&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&sid=&word=%E7%BE%8E%E5%A5%B3
在很多网站的URL中对一些get的参数或关键字进行编码,所以我们复制出来的时候,会出现问题。
URL的编码和解码
import urllib
from urllib import parse
import urllib.request
data = {'word': '美女'}
# Python3的urlencode需要从parse中调用,可以看到urlencode()接受的是一个字典
print(urllib.parse.urlencode(data))
# 通过urllib.request.unquote()方法,把URL编码字符串,转换回原先字符串
print(urllib.request.unquote('word=%E7%BE%8E%E5%A5%B3'))
分析源代码
F12或者页面上右键审查元素。打开以后,定位到图片的位置
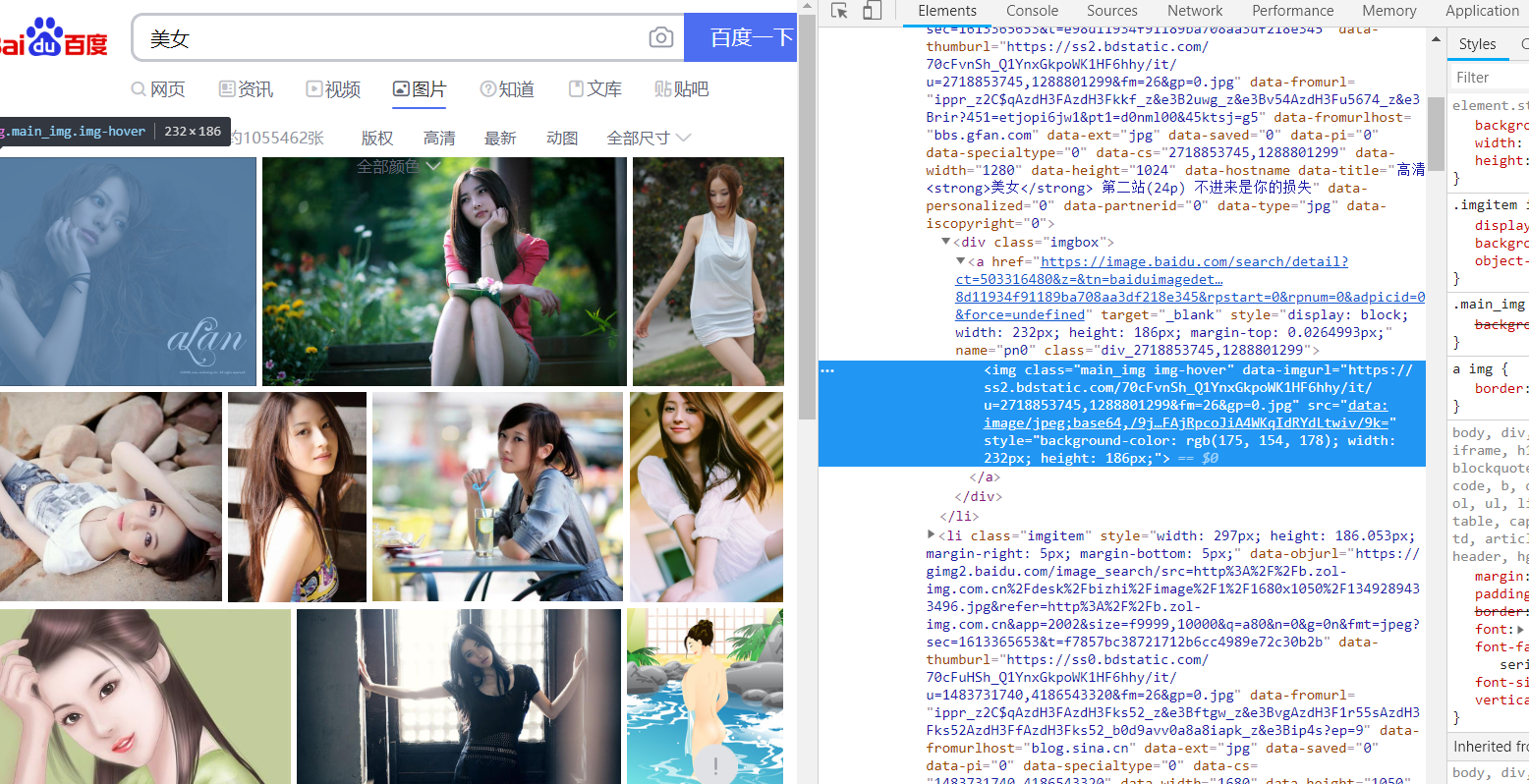
复制下面这个网址
注意有转义字符
imgurl="https:\/\/ss0.bdstatic.com\/70cFvHSh_Q1YnxGkpoWK1HF6hhy\/it\/u=2718853745,1288801299&fm=214&gp=0.jpg"
然后在当前网页的空白地方右键:查看网页源代码
使用快捷键CTRl+F
查找(我这里 输入 gp=0.jpg 通过输入图片网址最后几个字符来定位图片)

这个图片怎么有很多地址,到底用哪个呢?可以看到有thumbURL,objURL等等。
通过分析可以知道,前面两个是缩小的版本,hover是鼠标移动过后显示的版本,objURL对应的那个地址,应该是我们需要的,不信可以打开这几个网址看看,发现obj那个最大最清晰。

编写正则表达式或者XPath表达式
pic_url = re.findall(’“objURL”:"(.*?)",’,html,re.S)
objurl后面的,全匹配
找到本机电脑网络的headers
有的时候,我们无法爬取一些网页,会出现403错误,因为这些网页为了防止别人恶意采集信息所以进行了一些反爬虫的设置。
我们可以设置一些Headers信息,模拟成浏览器去访问这些网站,就能解决这个问题。
首先,单击网页中的百度一下,即让网页发生一个动作,下方窗口出现了很多数据,如图。
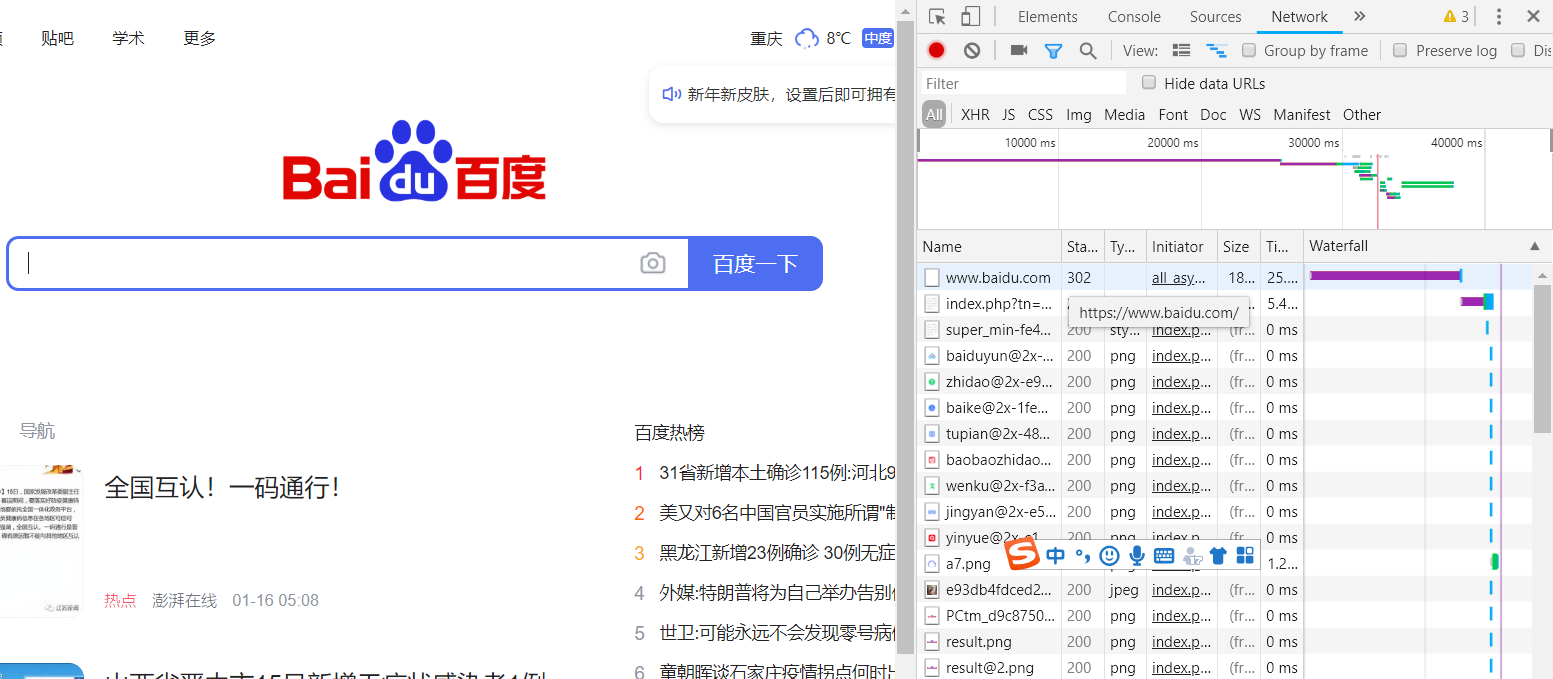
此时单击图中的www.baidu.com,出现如图
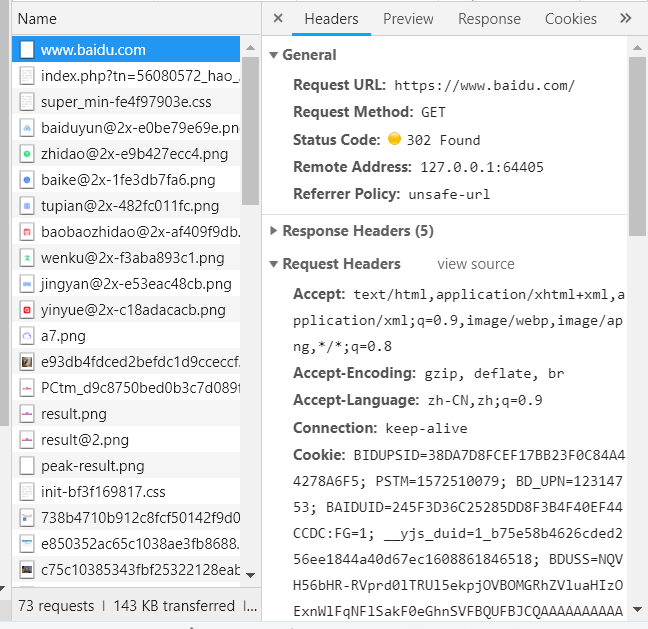
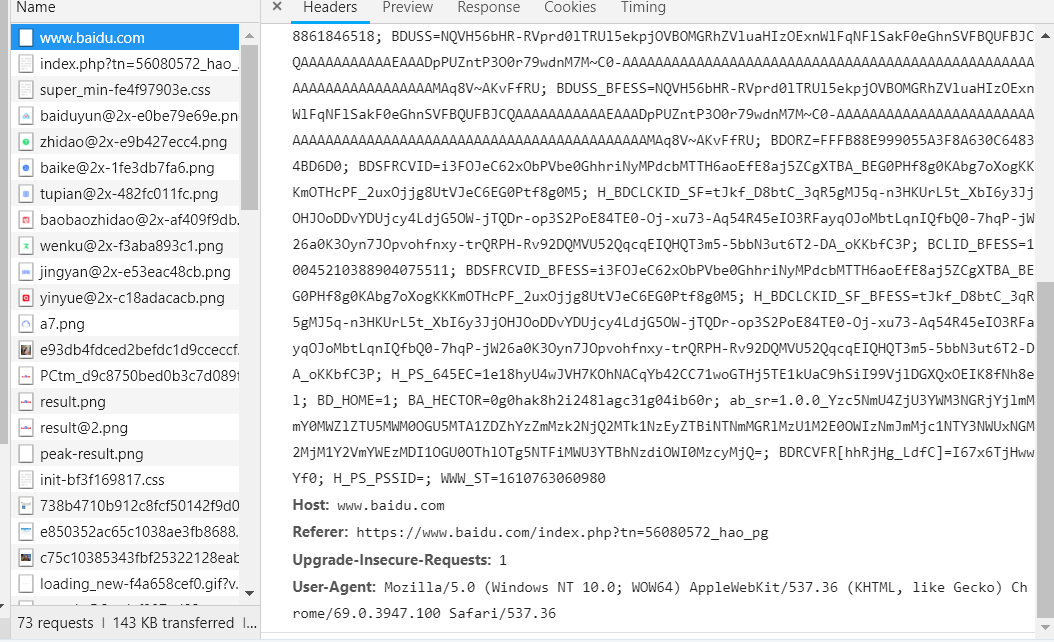
在Headers,往下拖动,找到User-agent
这一串信息就是我们下面模拟浏览器用到的信息,复制出来。
所有代码
语言python
from urllib.parse import quote
import string
import re
from urllib import request
import urllib.request
word = input('关键词:')
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + word + '&ct=201326592&v=flip'
url = quote(url, safe=string.printable)# # 解决ascii编码报错问题,不报错则可以注释掉
#模拟成浏览器
headers=("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36")
opener=urllib.request.build_opener()
opener.addheaders=[headers]
#将opener安装为全局
urllib.request.install_opener(opener)
#读取网页
url_request=request.Request(url)
url_response = request.urlopen(url_request,timeout=10) # 请求数据,可以和上一句合并.表示一次http访问请求的时间最多10秒,一旦超过,本次请求中断,但是不进入下一条,而是继续重复请求这一条
html = url_response.read().decode('utf-8') # 加编码,重要!转换为字符串编码,read()得到的是byte格式的。
jpglist = re.findall('"thumbURL":"(.*?)",',html,re.S) #re.S将字符串作为整体,在整体中进行匹配。,thumbURL可以匹配其他格式的图
print(len(jpglist))
n = 1
for each in jpglist:
print(each)
try:
request.urlretrieve(each,'D:\\deeplearn\\xuexicaogao\\图片\\%s.jpg' %n) #爬下载的图片放置在提前建好的文件夹里
except Exception as e:
print(e)
finally:
print('下载完成。')
n+=1
if n==90:
break
print('结束')
代码解析
爬虫报错UnicodeEncodeError: ‘ascii’ codec can’t encode characters in position 45-47: ordinal not…
原因 python 默认的编码是ascii,当程序中出现非ascii编码时,python的处理常常会报这样的错UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0x?? in position 1: ordinal not in range(128),python没办法处理非ascii编码的,此时需要自己设置将python的默认编码,一般设置为utf8的编码格式。
使用urllib.parse.quote进行转换。
结果文件夹
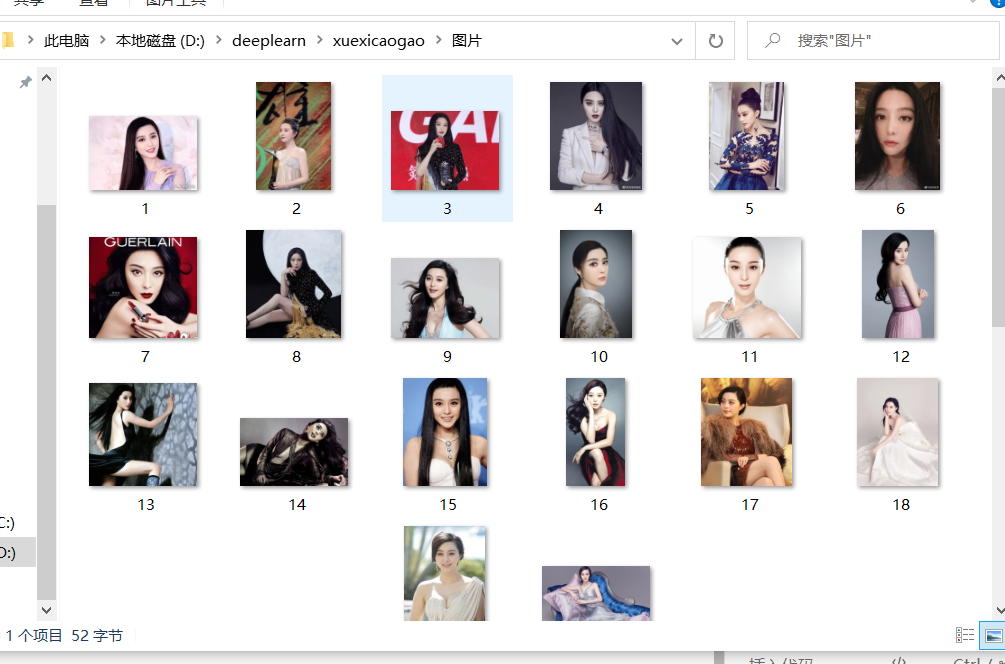
代码版本2
语言python
import urllib
import urllib.request
from urllib.parse import quote
import re
import os
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36",
"referer": "https://image.baidu.com"
}
print("****************************************************************************************")
keyword = input("请输入要下载的图片:")
last_dir = "C://Users//Shineion//Desktop//爬虫图"
dir = "C://Users//Shineion//Desktop//爬虫图//" + keyword
if os.path.exists(last_dir):
if os.path.exists(dir):
print("文件夹已经存在")
else:
os.mkdir(dir)
print(dir + "已经创建成功")
else:
os.mkdir(last_dir)
if os.path.exists(dir):
print("文件夹已经存在")
else:
os.mkdir(dir)
print(dir + "已经创建成功")
keyword1 = quote(keyword, encoding="utf-8")
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + keyword1 + '&ct=201326592&v=flip'
req = urllib.request.Request(url, headers=headers)
f = urllib.request.urlopen(req).read().decode("utf-8")
key = r'thumbURL":"(.+?)"'
key1 = re.compile(key)
num = 0
for string in re.findall(key1, f):
print("正在下载" + string)
f_req = urllib.request.Request(string, headers=headers)
f_url = urllib.request.urlopen(f_req).read()
fs = open(dir + "/" + keyword + str(num) + ".jpg", "wb+")
fs.write(f_url)
fs.close()
num += 1
print(string + "已下载成功")
input("按任意键结束程序:")

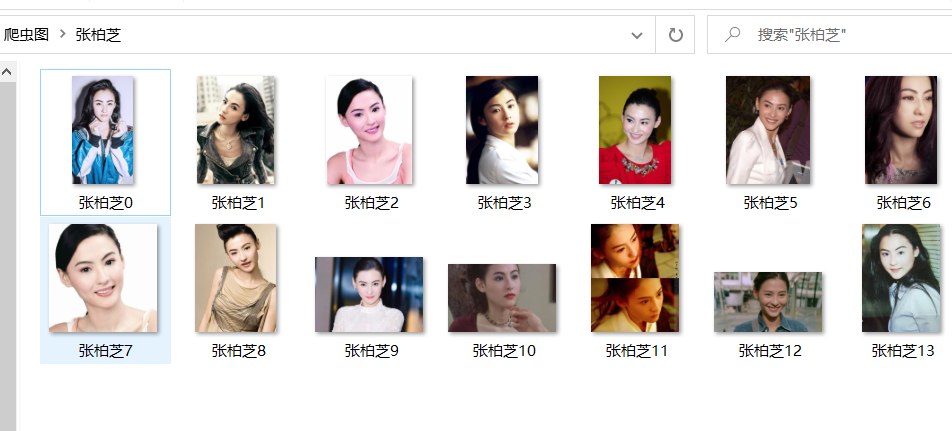
注意问题:代码容易卡住,在获取某一图片时卡住

作者:电气-余登武



















 1018
1018

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











